") 谷歌DeepMind圍棋吊打世界冠軍
谷歌DeepMind圍棋吊打世界冠軍
作為 AlphaGo 的最新迭代,DeepMind 又在 11 月 6 日發(fā)表的《科學(xué)》(Science)論文中,隆重介紹了 AlphaZero 。作為谷歌母公司 Alphabet 旗下的英國人工智能子公司,DeepMind 多年來一直致力于改進(jìn) Go AI 。2017 年的時(shí)候,前 AI 冠軍 AlphaGo 正式退休,但在進(jìn)一步修補(bǔ)之后,AlphaZero 又達(dá)到了新的頂峰。
AlphaZero 是一款能夠從頭學(xué)習(xí)圍棋、象棋等棋子游戲的新型人工智能平臺。在三款棋類比賽中,AlphaZero 將三款 AI 都挑落下馬。
● Stockfish:國際象棋 AI 世界冠軍;
● elmo:2017 年度世界計(jì)算機(jī)將棋錦標(biāo)賽冠軍;
● AlphaGo Zero:DeepMind 自家的圍棋 AI,被譽(yù)為史上最強(qiáng)選手。
在僅僅獲知有關(guān)游戲基本規(guī)則的情況下,AlphaZero 在成為人工智能大師之前,會先自己機(jī)型數(shù)百萬場的對抗練習(xí)。
該 AI 初期會實(shí)施隨機(jī)戰(zhàn)術(shù)來取得勝利,但后續(xù)會通過‘強(qiáng)化學(xué)習(xí)’來試錯(cuò),以逐步了解哪些策略是最有效的。
實(shí)測國際象棋需要 9 小時(shí)、將棋 12 小時(shí)、圍棋 13 天,涉及 5000 個(gè)張量處理單元(TPU)。
作為參考,一套 TPU 每天可以處理超過 Google Photos 中的 1 億+照片,所以 AlphaZero 對硬件處理性能的要求還是比較高的。
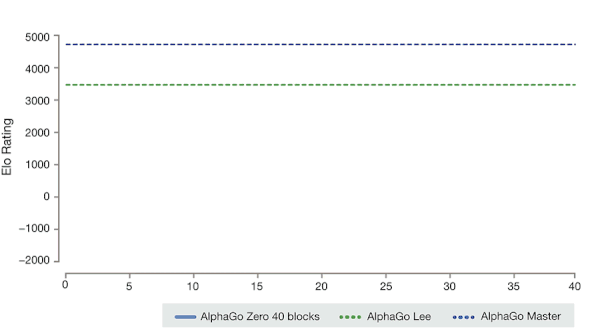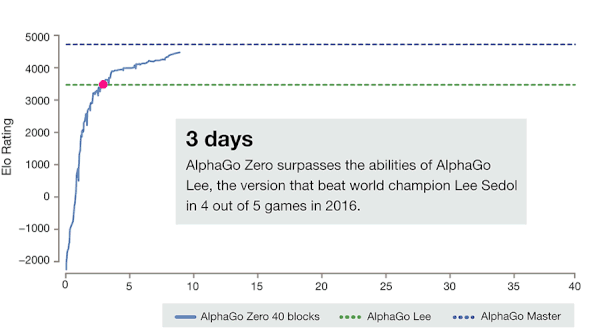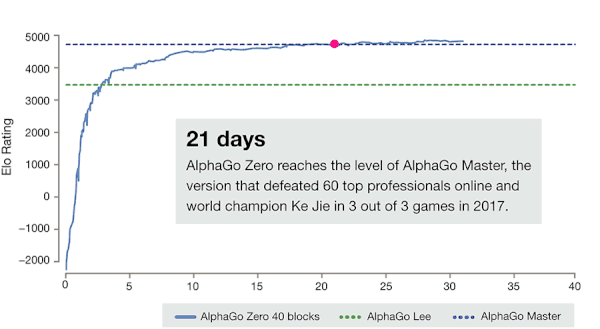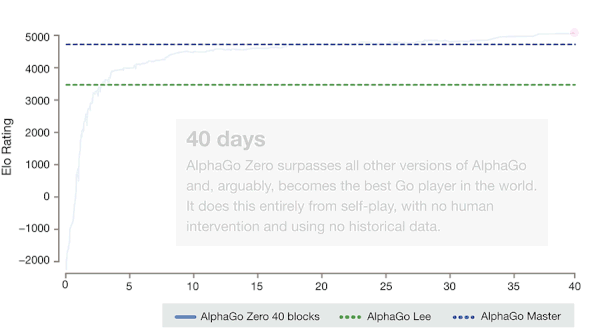
閉關(guān)學(xué)習(xí)結(jié)束后,AlphaZero 就可以大殺四方了
這項(xiàng)研究的獨(dú)特之處在于,研究團(tuán)隊(duì)將機(jī)器學(xué)習(xí)算法、與蒙特卡羅樹(MCTS)的“搜索方法”結(jié)合到了一塊。
這是 Go 圍棋 AI 決定下一步行動所采用的方式,這次 DeepMind 團(tuán)隊(duì)在國際象棋和將棋 AI 上也套用了同樣的機(jī)制,首次展示了該方法適用于其它復(fù)雜的游戲測試。
對于人類國際象棋選手來說,AlphaZero 是極具吸引力的。你可以在與機(jī)器對戰(zhàn)時(shí),見識到此前從未遇到過的策略、以及一些新穎的想法。
其咄咄逼人的風(fēng)格、以及高度動態(tài)的應(yīng)變策略,足以讓 Matthew Sadler 之類的國際象棋大師感到驚訝(其在 DeepMind 博客上有所表述)。
有關(guān)這項(xiàng)研究的詳情,已經(jīng)發(fā)表在近日出版的《科學(xué)》(Science)期刊上。原標(biāo)題為:《A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play》《一種通用的強(qiáng)化學(xué)習(xí)算法,可自學(xué)成為國際象棋、將棋、圍棋大師》。
-
谷歌
+關(guān)注
關(guān)注
27文章
6142瀏覽量
105100 -
DeepMind
+關(guān)注
關(guān)注
0文章
129瀏覽量
10819
原文標(biāo)題:GGAI 前沿 | 谷歌DeepMind超級進(jìn)化:國際象棋、圍棋吊打世界冠軍
文章出處:【微信號:ggservicerobot,微信公眾號:高工智能未來】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
谷歌DeepMind被曝抄襲開源成果,論文還中了頂流會議

谷歌DeepMind發(fā)布人工智能模型AlphaFold最新版本
谷歌DeepMind推出新一代藥物研發(fā)AI模型AlphaFold 3
谷歌DeepMind推出SIMI通用AI智能體
谷歌發(fā)布全新AI基礎(chǔ)世界模型Genie
谷歌模型軟件有哪些功能
谷歌發(fā)布基礎(chǔ)世界模型Genie,世界模型領(lǐng)域競爭升溫
谷歌DeepMind重磅發(fā)布了基礎(chǔ)世界模型:Genie(精靈)

谷歌公布基礎(chǔ)模型Genie,主攻2D平臺類游戲及機(jī)器人應(yīng)用

谷歌DeepMind推新AI模型Genie,能生成2D游戲平臺
谷歌DeepMind資深A(yù)I研究員創(chuàng)辦AI Agent創(chuàng)企
谷歌DeepMind科學(xué)家欲建AI初創(chuàng)公司
谷歌AlphaGeometry系統(tǒng)已接近頂尖學(xué)生水平
再登Nature!DeepMind大模型突破60年數(shù)學(xué)難題,解法超出人類已有認(rèn)知






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論