 數據科學高效工具:feature-selector,幫你快速完成特征選擇
數據科學高效工具:feature-selector,幫你快速完成特征選擇
▍前言
本篇主要介紹一個基礎的特征選擇工具feature-selector,feature-selector是由Feature Labs的一名數據科學家williamkoehrsen寫的特征選擇庫。feature-selector主要對以下類型的特征進行選擇:
具有高missing-values百分比的特征
具有高相關性的特征
對模型預測結果無貢獻的特征(即zero importance)
對模型預測結果只有很小貢獻的特征(即low importance)
具有單個值的特征(即數據集中該特征取值的集合只有一個元素)
從上面可以看出feature-selector確實是非常基礎的特征選擇工具,正因為非常的基礎,所以才非常的常用(這也是為什么williamkoehrsen要寫這個特征選擇庫的原因),在拿到一個數據集的時候,往往都需要將上述類型的特征從數據集中剔除掉。針對上面五種類型的特征,feature-selector分別提供以下五個函數來對此處理:
identify_missing(*)
identify_collinear(*)
identify_zero_importance(*)
identify_low_importance(*)
identify_single_unique(*)
▍數據集選擇
在這里使用kaggle上的訓練數據集。原訓練數據集稍微有點大,30+萬行(150+MB),pandas導入數據都花了一點時間,為此我從原數據集中采樣了1萬+行數據作為此次練習的數據集。數據集采樣代碼如下:
https://www.kaggle.com/c/home-credit-default-risk/data
importpandasaspddata=pd.read_csv('./appliation_train.csv')#從原數據中采樣5%的數據sample=data.sample(frac=0.05)#重新創建索引sample.reset_index(drop=True)#將采樣數據存到'application_train_sample.csv'文件中sample.to_csv('./application_train_sample.csv')
▍feature-selector用法
導入數據并創建feaure-selector實例
importpandasaspd#注意:#作者并沒有把feature-selector發布到pypi上,所以不能使用pip和conda進行安裝,只能手動#從github下載下來,然后把feature_selector.py文件放到當前工作目錄,然后再進行import操作。fromfeature_selectorimportFeatureSelectordata=pd.read_csv('./application_train_sample.csv',index_col=0)#數據集中TARGET字段為對應樣本的labeltrain_labels=data.TARGET#獲取allfeaturestrain_features=data.drop(columns='TARGET')#創建feature-selector實例,并傳入features和labelsfs=FeatureSelector(data=train_features,lables=train_labels)1
特征選取方法
(1)identify_missing
該方法用于選擇missing value 百分比大于指定值(通過missing_threshold指定百分比)的feature。該方法能應用于監督學習和非監督學習的特征選擇。
#選擇出missingvalue百分比大于60%的特征fs.identify_missing(missing_threshold=0.6)#查看選擇出的特征fs.ops['missing']#繪制所有特征missingvalue百分比的直方圖fs.plot_missing()
圖1. 所有特征missing value百分比的直方圖
該方法內部使用pandas 統計數據集中所有feature的missing value 的百分比,然后選擇出百分比大于閾值的特征,詳見feature-selector.py的114-136行。
https://github.com/WillKoehrsen/feature-selector/blob/master/feature_selector/feature_selector.py#L114-L136
(2) identify_collinear
該方法用于選擇相關性大于指定值(通過correlation_threshold指定值)的feature。該方法同樣適用于監督學習和非監督學習。
#不對feature進行one-hotencoding(默認為False),然后選擇出相關性大于98%的feature,fs.identify_collinear(correlation_threshold=0.98,one_hot=False)#查看選擇的featurefs.ops['collinear']#繪制選擇的特征的相關性heatmapfs.plot_collinear()#繪制所有特征的相關性heatmap
圖2. 選擇的特征的相關矩陣圖
圖3. 所有特征相關矩陣圖
該方法內部主要執行步驟如下:
1.根據參數'one_hot'對數據集特征進行one-hot encoding(調用pd.get_dummies方法)。如果'one_hot=True'則對特征將進行one-hot encoding,并將編碼的特征與原數據集整合起來組成新的數據集,如果'one_hot=False'則什么不做,進入下一步;
2.計算步驟1得出數據集的相關矩陣C(通過DataFrame.corr(),注意 C也為一個DateFrame),并取相關矩陣的上三角部分得到 C_upper;
3.遍歷C_upper的每一列(即每一個特征),如果該列的任何一個相關值大于correlation_threshold,則取出該列,并放到一個列表中(該列表中的feature,即具有high 相關性的特征,之后會從數據集去除);
4.到這一步,做什么呢?回到源碼看一波就知道了;
具體請見feature-selector.py的157-227行。
(3) identify_zero_importance
該方法用于選擇對模型預測結果毫無貢獻的feature(即zero importance,從數據集中去除或者保留該feature對模型的結果不會有任何影響)。
該方法以及之后的identify_low_importance都只適用于監督學習(即需要label,這也是為什么實例化feature-selector時需要傳入labels參數的原因)。feature-selector通過用數據集訓練一個梯度提升機(Gradient Boosting machine, GBM),然后由GBM得到每一個feature的重要性分數,對所有特征的重要性分數進行歸一化處理,選擇出重要性分數等于零的feature。
為了使計算得到的feature重要性分數具有很小的方差,identify_zero_importance內部會對GBM訓練多次,取多次訓練的平均值,得到最終的feature重要性分數。同時為了防止過擬合,identify_zero_importance內部從數據集中抽取一部分作為驗證集,在訓練GBM的時候,計算GBM在驗證集上的某一metric,當metric滿足一定條件時,停止GBM的訓練。
#選擇zeroimportance的feature,##參數說明:#task:'classification'/'regression',如果數據的模型是分類模型選擇'classificaiton',#否則選擇'regression'#eval_metric:判斷提前停止的metric.forexample,'auc'forclassification,and'l2'forregressionproblem#n_iteration:訓練的次數#early_stopping:True/False,是否需要提前停止fs.identify_zero_importance(task='classification',eval_metric='auc',n_iteration=10,early_stopping=True)#查看選擇出的zeroimportancefeaturefs.ops['zero_importance']#繪制featureimportance關系圖#參數說明:#plot_n:指定繪制前plot_n個最重要的feature的歸一化importance條形圖,如圖4所示#threshold:指定importance分數累積和的閾值,用于指定圖4中的藍色虛線.#藍色虛線指定了importance累積和達到threshold時,所需要的feature個數。#注意:在計算importance累積和之前,對feature列表安裝featureimportance的大小#進行了降序排序fs.plot_feature_importances(threshold=0.99,plot_n=12)
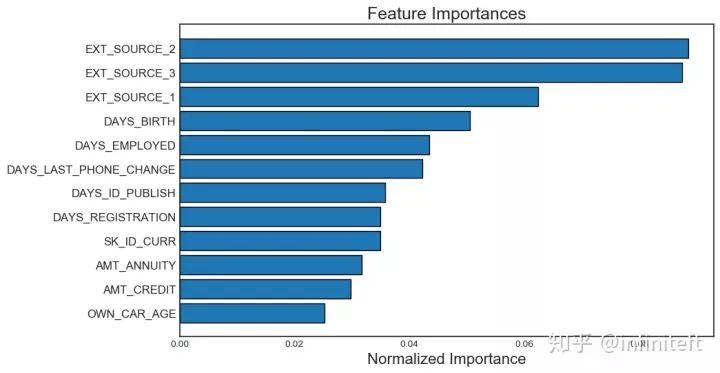
圖4. 前12個最重要的feature歸一化后的importance分數的條形圖
圖5. feature 個數與feature importance累積和的關系圖
需要注意GBM訓練過程是隨機的,所以每次運行identify_zero_importance得到feature importance分數都會發生變化,但按照importance排序之后,至少前幾個最重要的feature順序不會變化。
該方法內部主要執行了以下步驟:
1.對各個feature進行one-hot encoding,然后將one-hot encoding的feature和原數據集合并成新的數據集(使用pd.get_dummies完成);
2.根據參數 task 的取值,實例化lightgbm.LGBMClassifier, 或者實例化 lightgbm.LGBMRegressor model;
3.根據early_stopping的取值選擇是否需要提前停止訓練,并向model.fit傳入相應的參數,然后開始訓練model;
4.根據model得到該次訓練的feature importance;
5.執行n_iterations次步驟1-4;
6.取多次訓練的feature importance的平均值,得到最終的feature importance;
7.選擇出feature importance等于0的feature;
8.到這一步,主要步驟完成了,其他部分請查看源碼。
具體請見feature-selector.py的229-342行。
(4) identify_low_importance
該方法是使用identify_zero_importance計算的結果,選擇出對importance累積和達到指定閾值沒有貢獻的feature(這樣說有點拗口),即圖5中藍色虛線之后的feature。該方法只適用于監督學習。identify_low_importance有點類似于PCA中留下主要分量去除不重要的分量。
#選擇出對importance累積和達到99%沒有貢獻的featurefs.identify_low_importance(cumulative_importance=0.99)#查看選擇出的featurefs.ops['low_importance']
該方法選擇出的feature其實包含了zero importance的feature。內部實現沒什么可說的,具體請見feature-selector.py的344-378行。
(5) identify_single_unique
該方法用于選擇只有單個取值的feature,單個值的feature的方差為0,對于模型的訓練不會有任何作用(從信息熵的角度看,該feature的熵為0)。該方法可應用于監督學習和非監督學習。
#選擇出只有單個值的featurefs.identify_single_unique()#查看選擇出的featurefs.ops['single_unique']#繪制所有featureuniquevalue的直方圖fs.plot_unique()
圖6. 所有feature unique value的直方圖
該方法內部的內部實現很簡單,只是通過DataFrame.nunique方法統計了每個feature取值的個數,然后選擇出nunique==1等于1的feature。具體請見feature-selector.py的138-155行。
從數據集去除選擇的特征
上面介紹了feature-selector提供的特征選擇方法,這些方法從數據集中識別了feature,但并沒有從數據集中將這些feature去除。feature-selector中提供了remove方法將選擇的特征從數據集中去除,并返回去除特征之后的數據集。
#去除所有類型的特征#參數說明:#methods:#desc:需要去除哪些類型的特征#type:string/list-likeobject#values:'all'或者是['missing','single_unique','collinear','zero_importance','low_importance']#中多個方法名的組合#keep_one_hot:#desc:是否需要保留one-hotencoding的特征#type:boolean#values:True/False#default:Truetrain_removed=fs.remove(methods='all',keep_one_hot=False)
注意:調用remove函數的時候,必須先調用特征選擇函數,即identify_*函數。
該方法的實現代碼在feature-selector.py的430-510行。
一次性選擇所有類型的特征
feature-selector除了能每次運行一個identify_*函數來選擇一種類型特征外,還可以使用identify_all函數一次性選擇5種類型的特征選。
#注意:#少了下面任何一個參數都會報錯,raiseValueErrorfs.identify_all(selection_params= {'missing_threshold':0.6,'correlation_threshold':0.98,'task':'classification','eval_metric':'auc','cumulative_importance':0.99})
▍總結
feature-selector屬于非常基礎的特征選擇工具,它提供了五種特征的選擇函數,每個函數負責選擇一種類型的特征。一般情況下,在對某一數據集構建模型之前,都需要考慮從數據集中去除這五種類型的特征,所以feature-selector幫你省去data-science生活中一部分重復性的代碼工作。
如果有興趣和充足的時間,建議閱讀一下feature-selector的代碼,代碼量很少,七百多行,相信看了之后對feature-selector各個函數的實現思路以及相應代碼實現有一定認識,有心者還可以貢獻一下自己的代碼。
-
函數
+關注
關注
3文章
4306瀏覽量
62431 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:一款非常棒的特征選擇工具:feature-selector
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
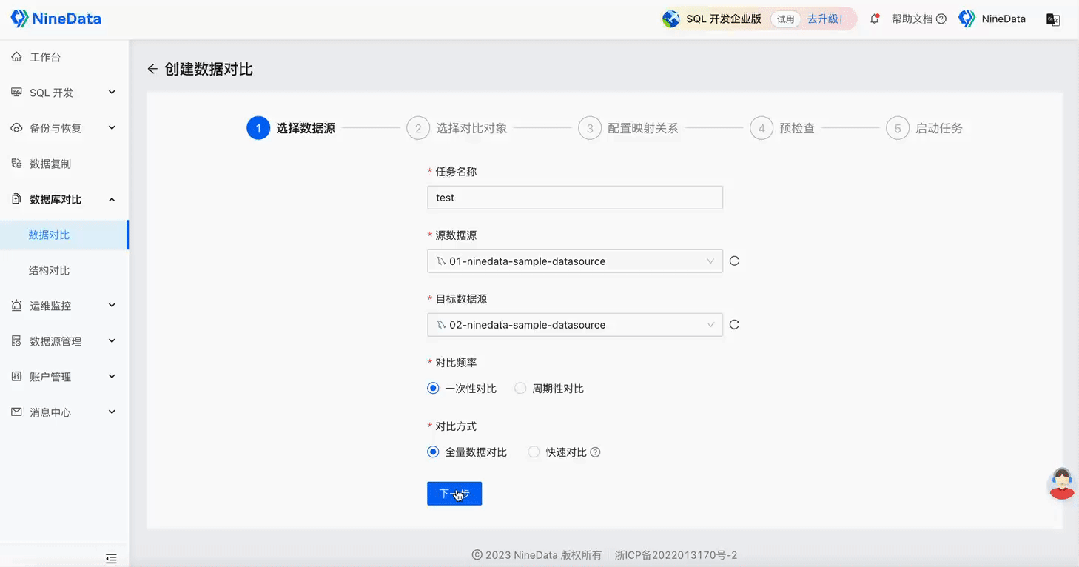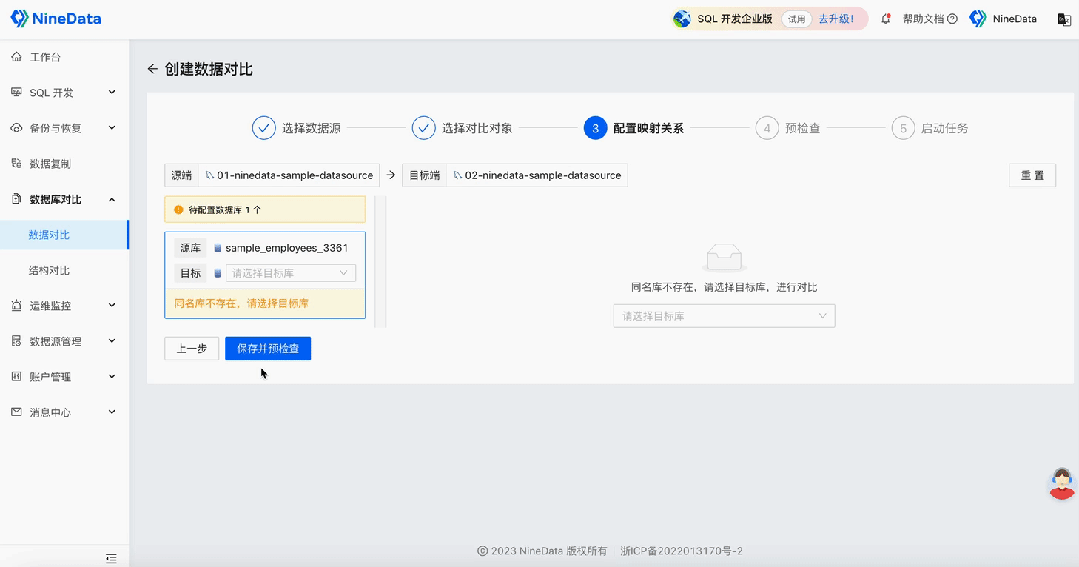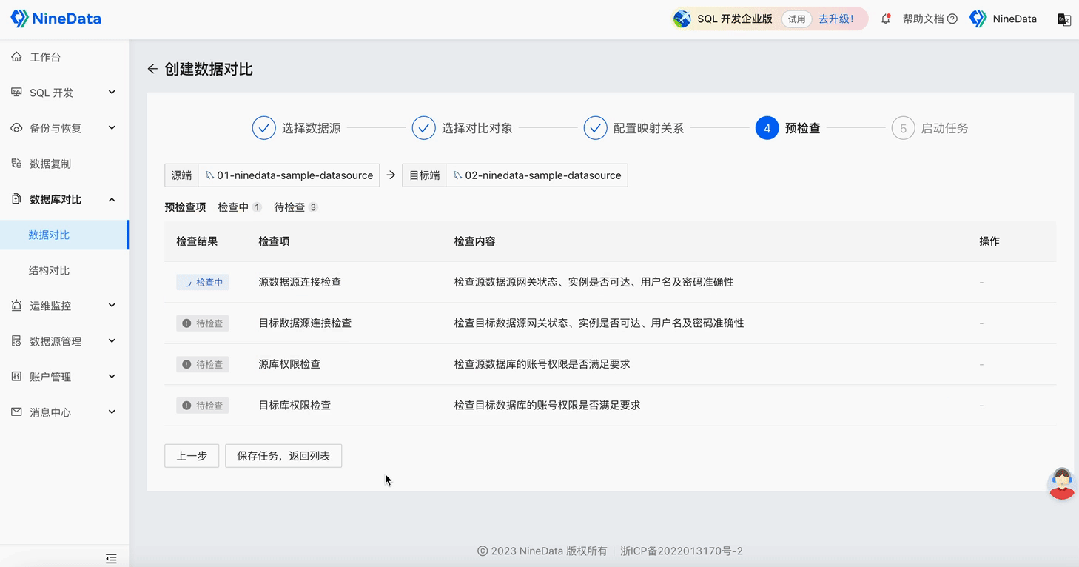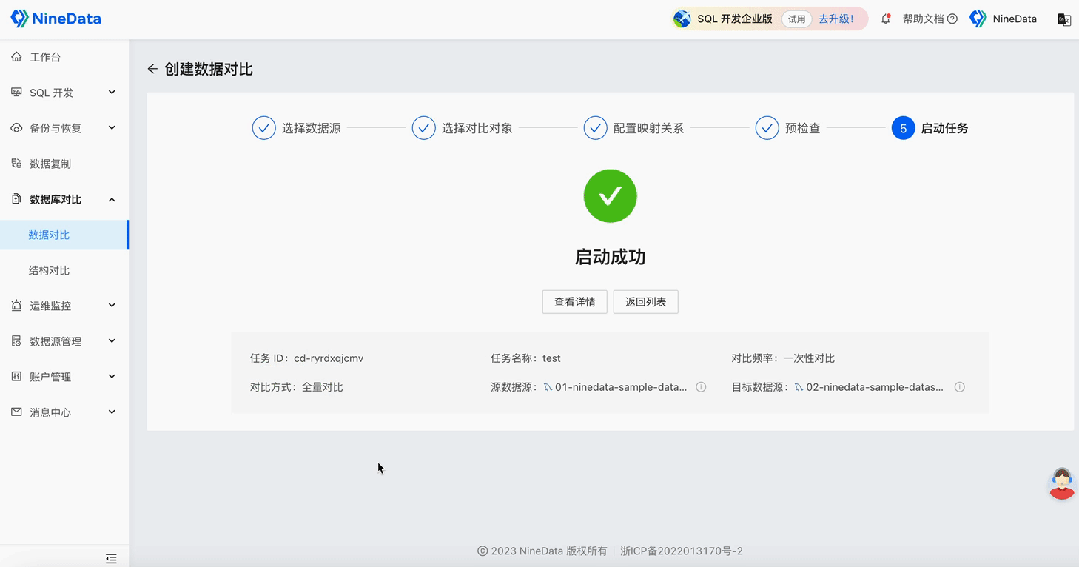
使用NineData快速完成MySQL數據的差異對比!
機器視覺的Gabor Feature特征表達

十大機器學習工具及數據科學工具
數據科學的工具數不勝數——你應該選擇哪一個?
機器學習之特征提取 VS 特征選擇


合泰半導體全新發布MCU Selector App選型工具

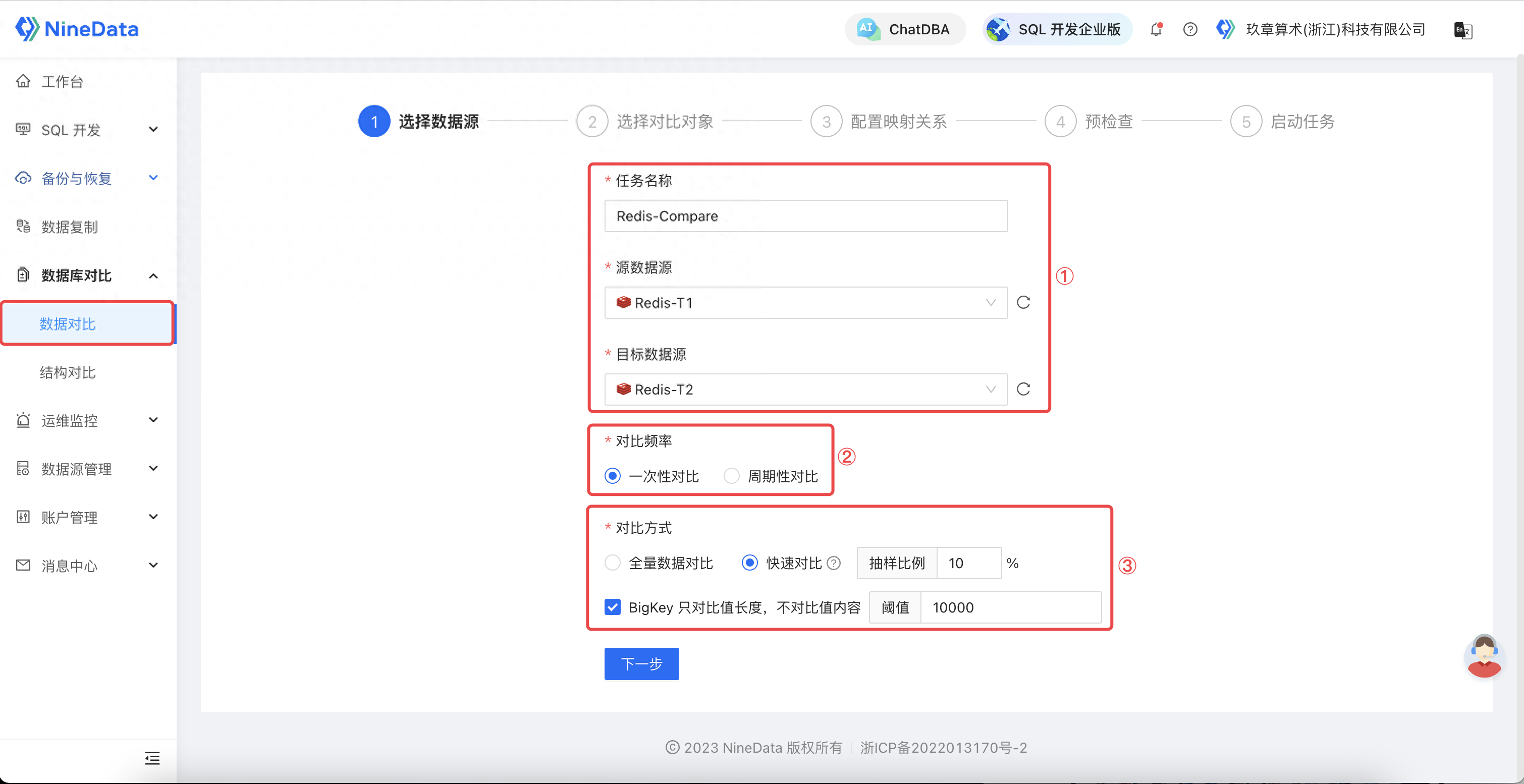
使用NineData快速、高效完成Redis差異數據對比!





 工商網監
工商網監
評論