") 用圖解的方式,生動(dòng)易懂地講解了BERT和ELMo等模型
用圖解的方式,生動(dòng)易懂地講解了BERT和ELMo等模型
谷歌推出BERT模型被認(rèn)為是NLP新時(shí)代的開始,NLP終于找到了一種方法,可以像計(jì)算機(jī)視覺那樣進(jìn)行遷移學(xué)習(xí)。本文用圖解的方式,生動(dòng)易懂地講解了BERT和ELMo等模型。
2018年已經(jīng)成為自然語言處理機(jī)器學(xué)習(xí)模型的轉(zhuǎn)折點(diǎn)。我們對(duì)如何以最能捕捉潛在意義和關(guān)系的方式、最準(zhǔn)確地表示單詞和句子的理解正在迅速發(fā)展。
此外,NLP社區(qū)開發(fā)了一些非常強(qiáng)大的組件,你可以免費(fèi)下載并在自己的模型和pipeline中使用。
ULM-FiT跟甜餅怪沒有任何關(guān)系,但我想不出其它的了...
最新的一個(gè)里程碑是BERT的發(fā)布,這一事件被描述為NLP新時(shí)代的開始。BERT是一個(gè)NLP模型,在幾個(gè)語言處理任務(wù)中打破了記錄。在描述模型的論文發(fā)布后不久,該團(tuán)隊(duì)還公開了模型的源代碼,并提供了已經(jīng)在大量數(shù)據(jù)集上預(yù)訓(xùn)練過的下載版本。
這是一個(gè)重大的進(jìn)展,因?yàn)槿魏涡枰獦?gòu)建語言處理模型的人都可以將這個(gè)強(qiáng)大的預(yù)訓(xùn)練模型作為現(xiàn)成的組件使用,從而節(jié)省了從頭開始訓(xùn)練模型所需的時(shí)間、精力、知識(shí)和資源。
圖示的兩個(gè)步驟顯示了BERT是如何運(yùn)作的。你可以下載步驟1中預(yù)訓(xùn)練的模型(在未經(jīng)注釋的數(shù)據(jù)上訓(xùn)練),然后只需在步驟2中對(duì)其進(jìn)行微調(diào)。
BERT建立在最近NLP領(lǐng)域涌現(xiàn)的許多聰明方法之上——包括但不限于半監(jiān)督序列學(xué)習(xí)(作者是Andrew Dai和Quoc Le)、ELMo(作者是Matthew Peters和來自AI2和UW CSE的研究人員)、ULMFiT(作者是fast.ai創(chuàng)始人Jeremy Howard和Sebastian Ruder),OpenAI transformer(作者是OpenAI研究員Radford、Narasimhan、Salimans和Sutskever),以及Transformer(作者是Vaswani et al .)。
要正確理解BERT是什么,我們需要了解一些概念。讓我們先看看如何使用BERT,然后再看模型本身涉及的概念。
例子:句子分類
最直接的使用BERT的方法就是使用它來對(duì)單個(gè)文本進(jìn)行分類。這個(gè)模型看起來是這樣的:
要訓(xùn)練一個(gè)這樣的模型,主要需要訓(xùn)練分類器,在訓(xùn)練階段對(duì)BERT模型的更改非常小。這種訓(xùn)練過程稱為微調(diào)(Fine-Tuning),并且具有半監(jiān)督序列學(xué)習(xí)(Semi-supervised Sequence Learning)和ULMFiT的根源。
具體來說,由于我們討論的是分類器,這屬于機(jī)器學(xué)習(xí)的監(jiān)督學(xué)習(xí)范疇。這意味著我們需要一個(gè)標(biāo)記數(shù)據(jù)集來訓(xùn)練模型。比如說,對(duì)于一個(gè)垃圾郵件分類器,標(biāo)記數(shù)據(jù)集是一個(gè)電子郵件列表及其標(biāo)簽(將每封電子郵件標(biāo)記為“垃圾郵件”或“非垃圾郵件”)。
模型架構(gòu)
現(xiàn)在,你已經(jīng)有了一個(gè)如何使用BERT的示例用例,接下來讓我們進(jìn)一步了解它是如何工作的。
論文中提供了兩種尺寸的BERT模型:
BERT BASE - 大小與OpenAI Transformer相當(dāng)
BERT LARGE - 一個(gè)非常龐大的模型,實(shí)現(xiàn)了最先進(jìn)的結(jié)果
BERT基本上是一個(gè)訓(xùn)練好的Transformer Encoder堆棧。Transformer模型是BERT的一個(gè)基本概念,我們將在下文中討論。
這兩種BERT模型都有大量的編碼器層(論文中稱之為Transformer Blocks)—— Base 版本有12層,Large版本有24層。它們也比初始論文里的Transformer的默認(rèn)配置(6個(gè)編碼器層,512個(gè)隱藏單元,8個(gè)attention heads)有更大的前饋網(wǎng)絡(luò)(分別為768個(gè)和1024個(gè)隱藏單元), attention heads(分別為12個(gè)和16個(gè))。
模型輸入
第一個(gè)輸入token是一個(gè)特殊的[CLS]token,這里的CLS代表分類。
就像transformer的普通編碼器一樣,BERT以一串單詞作為輸入。每一層應(yīng)用self-attention,并通過前饋網(wǎng)絡(luò)傳遞其結(jié)果,然后將結(jié)果傳遞給下一個(gè)編碼器。
在架構(gòu)方面,到目前為止,這與Transformer完全相同(除了大小之外,不過大小是我們可以設(shè)置的配置)。在輸出端,我們才開始看到兩者的區(qū)別。
模型輸出
每個(gè)位置輸出大小為hidden_size的向量(BERT Base中為768)。對(duì)于上面看到的句子分類示例,我們只關(guān)注第一個(gè)位置的輸出(我們將那個(gè)特殊的[CLS]標(biāo)記傳遞給它)。
這個(gè)向量可以作為我們選擇的分類器的輸入。論文中利用單層神經(jīng)網(wǎng)絡(luò)作為分類器,取得了很好的分類效果。
如果你有更多的標(biāo)簽(例如,如果是電子郵件,你可以將郵件標(biāo)記為“垃圾郵件”、“非垃圾郵件”、“社交”和“促銷”),只需調(diào)整分類器網(wǎng)絡(luò),使其有更多的輸出神經(jīng)元,然后通過softmax。
與卷積網(wǎng)絡(luò)的相似之處
對(duì)于具有計(jì)算機(jī)視覺背景的人來說,這種向量傳遞的方式很容易讓人聯(lián)想到VGGNet之類的網(wǎng)絡(luò)的卷積部分與網(wǎng)絡(luò)末端完全連接的分類部分之間的事情。
嵌入的新時(shí)代
這些新進(jìn)展帶來了詞匯編碼方式的新變化。詞匯嵌入一直是領(lǐng)先的NLP模型處理語言的主要能力。Word2Vec、Glove等方法已廣泛應(yīng)用于此類任務(wù)。讓我們先回顧一下如何使用它們。
詞匯嵌入的回顧
對(duì)于要由機(jī)器學(xué)習(xí)模型處理的單詞,它們需要以某種數(shù)字形式表示,以便模型可以在其計(jì)算中使用。Word2Vec表明我們可以用一個(gè)向量(一個(gè)數(shù)字列表)以捕捉語義或意義關(guān)系(如判斷單詞的近義、反義關(guān)系)、以及語法或語法關(guān)系(例如, “had”和“has” 、“was” and “is”有同樣的語法關(guān)系)的方式恰當(dāng)?shù)乇硎締卧~。
研究人員很快發(fā)現(xiàn),使用經(jīng)過大量文本數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練的嵌入(embeddings)是一個(gè)好主意,而不是與小數(shù)據(jù)集的模型一起訓(xùn)練。因此,通過使用Word2Vec或GloVe進(jìn)行預(yù)訓(xùn)練,可以下載單詞列表及其嵌入。如下圖是單詞“stick”的GloVe 嵌入示例(嵌入向量大小為200)
單詞“stick”的GloVe嵌入
因?yàn)檫@些向量很大,并且數(shù)字很多,所以本文后面用下面這個(gè)基本圖形來表示向量:
ELMo: 上下文很重要
如果我們使用GloVe表示,那么不管上下文是什么,“stick”這個(gè)詞都會(huì)由這個(gè)向量表示。很多研究人員就發(fā)現(xiàn)不對(duì)勁了。“stick”“有多種含義,取決于它的上下文是什么。那么,為什么不根據(jù)它的上下文給它一個(gè)嵌入呢——既要捕捉該上下文中的單詞含義,又要捕捉其他上下文信息?因此,語境化的詞嵌入(contextualized word-embeddings)就出現(xiàn)了。
語境化詞嵌入可以根據(jù)單詞在句子的上下文中表示的不同含義,給它們不同的表征
ELMo不是對(duì)每個(gè)單詞使用固定的嵌入,而是在為每個(gè)單詞分配嵌入之前查看整個(gè)句子。它使用針對(duì)特定任務(wù)的雙向LSTM來創(chuàng)建嵌入。
ELMo為NLP中的預(yù)訓(xùn)練提供了重要的一步。ELMo LSTM在大型數(shù)據(jù)集上進(jìn)行訓(xùn)練,然后我們可以將其用作所處理語言的其他模型中的組件使用。
ELMo的秘訣是什么?
ELMo通過訓(xùn)練預(yù)測(cè)單詞序列中的下一個(gè)單詞來獲得語言理解能力——這項(xiàng)任務(wù)被稱為語言建模。這很方便,因?yàn)槲覀冇写罅康奈谋緮?shù)據(jù),這樣的模型可以從這些數(shù)據(jù)中學(xué)習(xí),不需要標(biāo)簽。
ELMo預(yù)訓(xùn)練的一個(gè)步驟
我們可以看到每個(gè)展開的LSTM步驟的隱藏狀態(tài)從ELMo的頭部后面突出來。這些在預(yù)訓(xùn)練結(jié)束后的嵌入過程中會(huì)派上用場(chǎng)。
ELMo實(shí)際上更進(jìn)一步,訓(xùn)練了雙向LSTM——這樣它的語言模型不僅考慮下一個(gè)單詞,而且考慮前一個(gè)單詞。
ELMo通過將隱藏狀態(tài)(和初始嵌入)以某種方式組合在一起(連接后加權(quán)求和),提出語境化詞嵌入。
ULM-FiT:NLP中的遷移學(xué)習(xí)
ULM-FiT引入了一些方法來有效地利用模型在預(yù)訓(xùn)練期間學(xué)到的知識(shí)——不僅是嵌入,也不僅是語境化嵌入。ULM-FiT提出了一個(gè)語言模型和一個(gè)流程(process),以便針對(duì)各種任務(wù)有效地優(yōu)化該語言模型。
NLP終于找到了一種方法,可以像計(jì)算機(jī)視覺那樣進(jìn)行遷移學(xué)習(xí)。
Transformer:超越LSTM
Transformer的論文和代碼的發(fā)布,以及它在機(jī)器翻譯等任務(wù)上取得的成果,開始使一些業(yè)內(nèi)人士認(rèn)為Transformers是LSTM的替代品。而且,Transformer在處理長(zhǎng)期以來性方便比LSTM更好。
Transformer的編碼器-解碼器結(jié)構(gòu)使其非常適合于機(jī)器翻譯。但是如何使用它來進(jìn)行句子分類呢?如何使用它來預(yù)訓(xùn)練可以針對(duì)其他任務(wù)進(jìn)行微調(diào)的語言模型(在NLP領(lǐng)域,使用預(yù)訓(xùn)練模型或組件的監(jiān)督學(xué)習(xí)任務(wù)被稱為下游任務(wù))。
OpenAI Transformer:為語言建模預(yù)訓(xùn)練Transformer解碼器
事實(shí)證明,我們不需要一個(gè)完整的Transformer來采用遷移學(xué)習(xí),也不需要為NLP任務(wù)采用一個(gè)可微調(diào)的語言模型。我們只需要Transformer的解碼器。解碼器是一個(gè)很好的選擇,因?yàn)樗钦Z言建模(預(yù)測(cè)下一個(gè)單詞)的首選,因?yàn)樗菫槠帘挝磥淼膖oken而構(gòu)建的——在逐字生成翻譯時(shí),這是一個(gè)有用的特性。
OpenAI Transformer由Transformer的解碼器堆棧組成
模型堆疊了12個(gè)解碼器層。由于在這種設(shè)置中沒有編碼器,這些解碼器層將不會(huì)有普通transformer解碼器層所具有的編碼器-解碼器注意力子層。但是,它仍具有自注意層。
通過這個(gè)結(jié)構(gòu),我們可以繼續(xù)在相同的語言建模任務(wù)上訓(xùn)練模型:使用大量(未標(biāo)記的)數(shù)據(jù)集預(yù)測(cè)下一個(gè)單詞。只是,我們可以把足足7000本書的文本扔給它,讓它學(xué)習(xí)!書籍非常適合這類任務(wù),因?yàn)樗试S模型學(xué)習(xí)相關(guān)信息,即使它們被大量文本分隔——假如使用推特或文章進(jìn)行訓(xùn)練,就無法獲得這些信息。
OpenAI Transformer用由7000本書組成的數(shù)據(jù)集進(jìn)行訓(xùn)練,以預(yù)測(cè)下一個(gè)單詞。
將學(xué)習(xí)轉(zhuǎn)移到下游任務(wù)
既然OpenAI transformer已經(jīng)經(jīng)過了預(yù)訓(xùn)練,并且它的層已經(jīng)被調(diào)優(yōu)以合理地處理語言,那么我們就可以開始將其用于下游任務(wù)。讓我們先來看看句子分類(將郵件分為“垃圾郵件”或“非垃圾郵件”):
如何使用預(yù)訓(xùn)練的OpenAI transformer來進(jìn)行句子分割
OpenAI論文中概述了一些用于處理不同類型任務(wù)輸入的輸入轉(zhuǎn)換。下圖描繪了模型的結(jié)構(gòu)和執(zhí)行不同任務(wù)的輸入轉(zhuǎn)換。
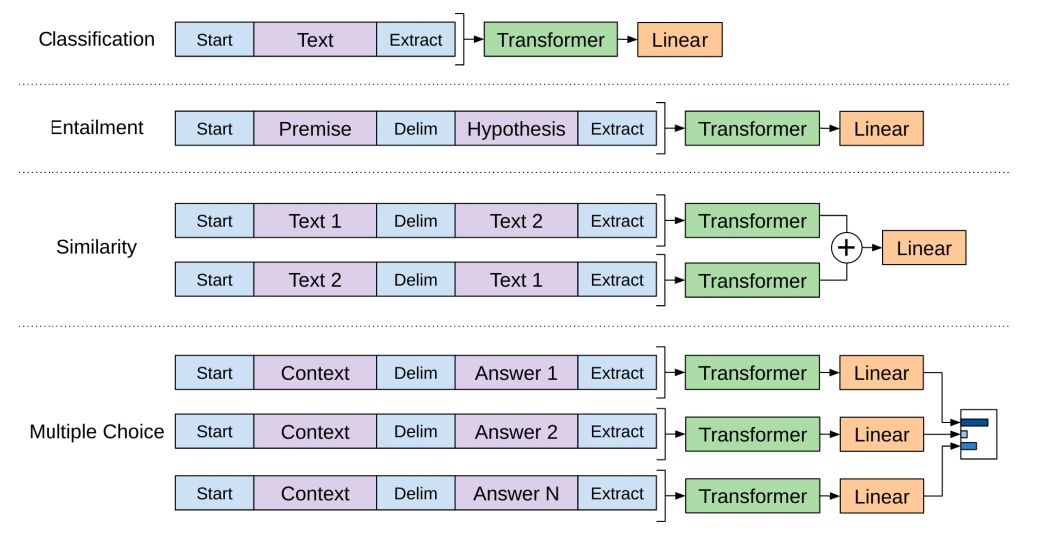
這是不很是聰明?
BERT:從解碼器到編碼器
OpenAI transformer為我們提供了一個(gè)基于Transformer的可微調(diào)預(yù)訓(xùn)練模型。但是在從LSTM到Transformer的轉(zhuǎn)換過程中缺少了一些東西。ELMo的語言模型是雙向的,而OpenAI Transformer只訓(xùn)練一個(gè)正向語言模型。我們能否建立一個(gè)基于transformer的模型,它的語言模型既考慮前向又考慮后向(用技術(shù)術(shù)語來說,“同時(shí)受左右上下文的制約”)?
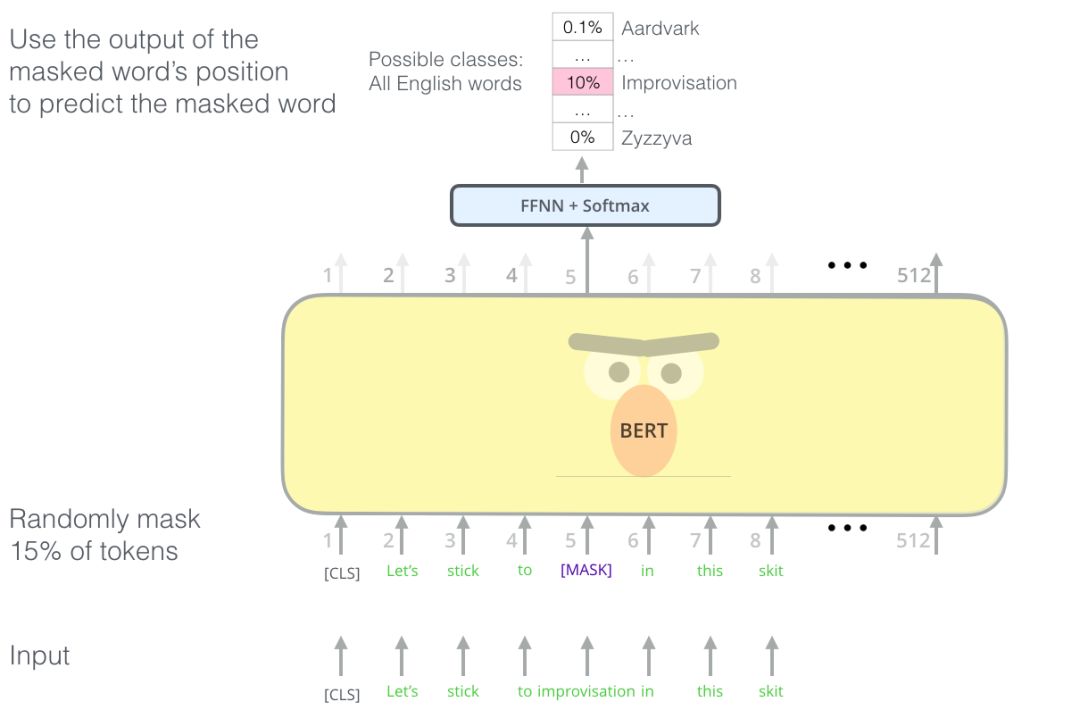
BERT聰明的語言建模任務(wù)遮蓋了輸入中15%的單詞,并要求模型預(yù)測(cè)丟失的單詞。
找到合適的任務(wù)來訓(xùn)練Transformer的編碼器堆棧不容易,BERT采用了“masked language model”的概念(文獻(xiàn)中也成為完形填空任務(wù))來解決這個(gè)問題。
除了遮蓋15%的輸入,BERT還混入了一些東西,以改進(jìn)模型后來的微調(diào)方式。有時(shí)它會(huì)隨機(jī)地將一個(gè)單詞替換成另一個(gè)單詞,并要求模型預(yù)測(cè)該位置的正確單詞。
兩句話任務(wù)
如果你回顧OpenAI transformer處理不同任務(wù)時(shí)所做的輸入轉(zhuǎn)換,你會(huì)注意到一些任務(wù)需要模型說出關(guān)于兩個(gè)句子的一些信息(例如,它們是否只是同件事情的相互轉(zhuǎn)述?假設(shè)一個(gè)維基百科條目作為輸入,一個(gè)關(guān)于這個(gè)條目的問題作為另一個(gè)輸入,我們能回答這個(gè)問題嗎?)
為了讓BERT更好的處理多個(gè)句子之間的關(guān)系,預(yù)訓(xùn)練過程增加了一個(gè)額外的任務(wù):給定兩個(gè)句子(A和B), B可能是A后面的句子,還是A前面的句子?

BERT預(yù)訓(xùn)練的第二個(gè)任務(wù)是一個(gè)兩句話分類任務(wù)。
特定任務(wù)的模型
BERT的論文展示了在不同的任務(wù)中使用BERT的多種方法。
BERT用于特征提取
fine-tuning 方法并不是使用BERT的唯一方法。就像ELMo一樣,你可以使用經(jīng)過預(yù)訓(xùn)練的BERT來創(chuàng)建語境化的單詞嵌入。然后,你可以將這些嵌入提供給現(xiàn)有的模型——論文中證明了,在諸如名稱-實(shí)體識(shí)別之類的任務(wù)上,這個(gè)過程產(chǎn)生的結(jié)果與對(duì)BERT進(jìn)行微調(diào)的結(jié)果相差不遠(yuǎn)。
哪個(gè)向量最適合作為語境化化嵌入?我認(rèn)為這取決于任務(wù)。論文考察了6個(gè)選項(xiàng)(與得分96.4的fine-tuned模型相比):
結(jié)語
試用BERT的最佳方式是通過使用托管在谷歌Colab上的Cloud TPUs notebook的BERT FineTuning。如果你以前從未使用過云TPU,那么這也是一個(gè)很好的起點(diǎn),可以嘗試使用它們。BERT代碼也適用于TPU、CPU和GPU。
下一步是查看BERT repo中的代碼:
該模型是在modeling.py(BertModel類)中構(gòu)建的,與原始Transformer編碼器完全相同。
run_classifier.py是fine-tuning過程的一個(gè)示例。它還構(gòu)建了監(jiān)督模型的分類層。如果要構(gòu)建自己的分類器,請(qǐng)查看文件中的create_model()方法。
有幾個(gè)預(yù)訓(xùn)練模型可供下載。包括BERT Base和BERT Large,以及英語,中文等語言的單語言模型,以及涵蓋102種語言的多語言模型,這些語言在維基百科上訓(xùn)練。
BERT不是將單詞看作token。相反,它關(guān)注的是詞塊(WordPieces)。tokennization.py 是將單詞轉(zhuǎn)換成適合BERT的WordPieces的工具。
BERT也有PyTorch實(shí)現(xiàn)。AllenNLP library 使用這個(gè)實(shí)現(xiàn),允許在任何模型中使用BERT嵌入。
-
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45930 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8382瀏覽量
132444 -
自然語言處理
+關(guān)注
關(guān)注
1文章
614瀏覽量
13513
原文標(biāo)題:圖解2018年領(lǐng)先的兩大NLP模型:BERT和ELMo
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
elmo直線電機(jī)驅(qū)動(dòng)調(diào)試細(xì)則
【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
大模型為什么要微調(diào)?大模型微調(diào)的原理
llm模型有哪些格式
llm模型和chatGPT的區(qū)別
使用PyTorch搭建Transformer模型
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
谷歌模型怎么用PS打開文件和圖片
電機(jī)驅(qū)動(dòng)器無法識(shí)別ELMO指令
模型與人類的注意力視角下參數(shù)規(guī)模擴(kuò)大與指令微調(diào)對(duì)模型語言理解的作用

如何通俗易懂地解釋卷積?
大語言模型背后的Transformer,與CNN和RNN有何不同






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論