 面向QoE的感知視頻編碼
面向QoE的感知視頻編碼
面向用戶體驗的感知視頻編碼即通過機器學習檢測用戶感興趣的視覺感知區域,并重新分配以更多的碼率與復雜度。本文來自北京航空航天大學副教授、博士生導師 徐邁在LiveVideoStack 線上交流分享,并由LiveVideoStack整理而成。
大家好,我是來自北京航空航天大學的徐邁。本次我將為大家分享面向QoE的感知視頻編碼。我們希望通過基于感知模型的視頻壓縮編碼技術,優化產品用戶體驗。
本次的分享將圍繞以下四個方面展開:
1.技術發展背景
用戶的需求升級推動技術的不斷前行,技術的進步也在不斷優化產品用戶體驗。
十幾年前,人們聚在一起慶祝新年,借助電話或短信噓寒問暖,一起在溫馨氛圍中為新年到來而歡呼;而現在,人們相聚在一起慶祝新年,更多的是拿出智能手機、平板電腦等移動智能終端記錄這樣一個美好的瞬間。十幾年的發展帶來的首要影響就是數據量的激增,如何穩定高效傳輸大量用戶隨時隨地采集到的音視頻數據成為我們亟待解決的問題。
數據量的激增雖然為網絡傳輸帶來了巨大挑戰,但也為人工智能等高新技術帶來了需求與發展契機。
于是在2009年,斯坦福的李飛飛等科學家一起構筑了用于測試視覺識別性能的ImageNet數據庫。初期ImageNet包含了四千多個類別的四百多萬張圖像,而到了2017年底其已包含兩萬多個類別的1400~1500萬張圖像。2009年ImageNet數據庫的建立與當時互聯網上出現的大量圖像數據密切相關,直到2018年的ImageNet中已包括了5400萬余張圖片,不得不說這加速了機器學習在視覺識別領域的運用進程。視覺識別離不開通過大量的圖片訓練增強其對相似視覺元素特性的規律總結能力,我們可以將這一思路運用在編碼壓縮領域,通過大量的視頻壓縮訓練使機器學習掌握洞悉視頻壓縮結構規律的能力,極大程度優化視頻編碼性能,提升用戶體驗。
根據統計,過去的2017年全球互聯網上有1.2萬億幅圖像產生,每一分鐘就有幾百萬張圖片被上傳至包括Facebook、Snapchat在內的各大互聯網平臺;而視頻的數據量則更為龐大,預計全球互聯網視頻數據總量將在2021年達到近2000EB。
如此龐大的數據量無疑會為圖像識別與通訊網絡的發展帶來巨大挑戰,受限于通訊資源,我們的實際傳輸帶寬資源遠沒有視頻數據量所要求的那么充裕;若想借助有限的帶寬資源快速穩定傳輸大量的圖像與視頻數據,則離不開高效的視頻編碼解決方案。
講到這里,我想我們需要回顧一下視頻編碼的發展歷程。早期視頻編碼變革較快:四年間MPEG-1發展到MPEG-2,所帶來的碼率節省約為50%,編碼效率翻倍,復雜度增長為5%左右;而H.264(AVC)發展到H.265(HEVC),雖然編碼效率仍有部分提高,但其背后復雜度增長卻十分顯著達到了二至十倍,實測可能更高。復雜度增長是現在編碼發展的一個明顯趨勢,而從右側數據中我們可以看出,隨著編碼標準的演進,編碼增益的成長也十分顯著:從初期AVC的9個Modes發展到HEVC的35個Modes;除此之外,早期的MPEG-1與MPEG-2是基于8x8的DCT變換,而發展到了AVC則實現了4x4與8x8的DCT,HEVC更是實現了4x4~32x32 DCT與4x4 DST;至于H.266還引入了預測模式,60多種預測模式使得相關參數復雜程度進一步提升。從中我們不難看出,視頻壓縮一直基于信號處理技術并不斷進行演進,而信號處理技術發展到現在已經很難再產生顛覆性革新。隨著技術的發展,邊際效應愈發明顯,技術突破愈發困難,因此我們迫切需要一種編碼壓縮的新思路。
這種新思路就是結合用戶感知對編碼過程進行優化。用戶感知與QoE緊密相關,人類視網膜大約擁有十億視覺細胞,這使得人眼成為一臺十億像素的高清相機;大腦皮層會識別分析處理這些視覺信號,但連接人眼與大腦皮層的神經細胞僅有一萬個左右,這就像一個資源十分有限的窄帶帶寬,那么人眼是如何利用這樣一個窄帶帶寬傳輸像素高達十億的高清視覺信號呢?這就是人作為高級動物的智慧所在:研究人的視覺感知模型我們可以發現,在人眼可感知的視角內,真正會引起大腦皮層明顯興奮的區域僅為2~3度;換句話說,人的視覺會將感知重點放在感興趣的目標區域。由此啟發,我們可通過降低感知冗余進一步提升視頻壓縮效率。
基于人類智慧我們提出了感知視頻壓縮并努力降低感知冗余。首先我們明確了如何察覺到視頻感知冗余的出現,解決方案是借助機器學習與計算機視覺檢測出視頻畫面里用戶會重點關注的部分;當監測到感知冗余出現之后,我們嘗試減少感知冗余與其影響,解決方案是重新分配資源,將更多碼率與復雜度分配到用戶感興趣的視覺感知區域;接下來我們嘗試將視頻感知冗余的優化運用在全景視頻之上,使得視頻壓縮更加契合人類的視覺習慣,也就是我們所說的面向QoE的感知視頻編碼。
2.基于數據驅動實現視頻顯著性檢測
視頻顯著性檢測是指通過計算機視覺技術推斷用戶觀看視頻時視覺感知重點集中的區域,主要借助基于機器學習的CV。其大致步驟為建庫、分析與建模;我們的建庫工作開始于2015年,初期主要依靠眼動儀檢測志愿者觀看視頻時視覺關注重點的變化從而生成熱點圖數據庫;建庫之后我們對熱點數據進行了特征分析,隨后依據特征分析結果建立深度學習模型從而初步實現了視頻顯著性檢測。

現在我們針對視頻已建立三個包括八百多個視頻的數據庫,共積累七百多萬個關注點。
在完成數據庫的建立之后,我們對數據庫進行分析,并對顯著性進行可視化。上圖展示的就是多位志愿者觀看視頻時視覺重點關注的位置變化數據,借助此數據可生成視覺熱點圖,偏向紅色的區域代表視覺關注重點而偏向藍色的區域則代表視覺關注程度較少,沒有顏色則代表不被關注。通過上圖展示的實驗數據我們可以發現,人在觀看視頻時視覺感知系統不會過多關注視頻畫面的背景部分而會重點關注目標元素尤其是運動的人與物。
為了找到能夠支撐上述結論的有力依據,我們嘗試通過深度學習模型預測視覺關注重點。首先我們基于對目標物體的檢測來構建網絡,接下來針對容易吸引視覺關注的運動物體我們構建了Motion Subnet用以優化對運動物體的檢測識別;在分別準確識別了物體與其運動狀態之后,我們借助借助Cross-net mask實現綜合分析二者數據得到運動物體的動態參數,并通過經歷多次迭代的深度學習得出具備預測視覺關注重點的深度學習網絡。初期此網絡檢測精度依舊有限只能檢測識別整個運動的物體,但經過多達150K代的迭代以后,現已可實現對物體局部的某一運動部分(如汽車正在旋轉的車輪)進行準確識別檢測。
完成了CNN網絡的構建,隨后我們又將CNN網絡特征輸入進SS-ConvLSTM從而使得系統能夠準確推測幀與幀間視覺關注重點的相關性。為了實現這樣的功能,我們提出了Center-bias Dropout ,其依據在于人眼更容易將畫面的中心區域作為視覺關注重點,除了人類遺傳導致人的視覺系統會將視覺中央附近的物體作為感知重點之外,主要的原因還有攝影師拍攝畫面時自然會把拍攝主體放在畫面中央。這就使得即使系統不對視頻進行內容分析,也能大致確定某視頻用戶的視覺關注重點會分布在畫面中央附近。
除此之外我們也提出了Sparsity-weighted loss(稀疏加權損失函數),主要用于對目標物體與關注重點區域的定量分析,下圖展示的是我們的定量結果,可以看到性能好于其他多種算法。
通過測試上述的分析流程我們得到了上圖展示的測試數據:以人臉檢測為例,“Human”行代表人類視覺實際的重點關注區域,“Ours”行代表計算機預測的視覺顯著性結果,可以看到與真實區域基本重疊,而相對于下面幾行代表的傳統方法在準確度上優勢明顯。
下圖展示的是我們在此研究上主要發表的論文。

3.面向一般視頻的感知視頻壓縮編碼
接下來將重點介紹有關感知視頻編碼在一般視頻場景中的應用。
3.1 編碼優化
編碼優化是必不可少的優化思路。
速率失真優化
首先我們進行了速率失真優化,也就是在控制一定碼率的同時盡可能降低失真或在控制失真的同時盡可能降低碼率。速率失真優化主要包括借助基于感知模型的碼率控制實現指標優化與基于機器學習預測壓縮失真的位置與特性實現質量增強。
復雜度失真優化
復雜度失真優化主要包括以下兩方面工作:首先是在保證質量的同時盡可能降低復雜度,其次是將復雜度控制在目標值之下并確保失真盡可能少。
進一步落實優化算法,我們期待通過算法盡可能減少失真與其帶來的影響。
1)針對HEVC感知視頻編碼的閉型質量優化
根據上圖展示的公式我們可以看到算法的原理是盡可能(減少第n塊的碼率分配)并引入Wn(Predicted Saliency)顯著性預測,將其作為權重加入失真優化當中,顯著性越高失真影響越大那么系統對其優化越明顯。如果不引入Wn僅依賴(it模型),經過多次迭代之后客觀情況下可達到5%的碼率節省而在主觀情況下基本可達到一半左右的碼率節省。
例如上圖中下半部分展示的視頻畫面中左側熱力圖表示觀眾對人臉的關注重點發布,但可以比較明顯地看到人物眼睛與嘴巴的位置較為模糊,嚴重影響觀看體驗;此時我們就會著重對眼睛與嘴巴區域的畫面進行優化,將更多碼率調整至人臉部位尤其眼睛和嘴巴的位置從而盡可能降低眼睛與嘴巴所在畫面位置的失真。這種碼率調整會將更多碼率資源用在人臉的眼睛與嘴巴等視覺重點區域,也會同時降低背景部分的碼率,這種主觀保證視覺重點區域編碼質量的方案可使編碼效率與性能提升一倍。
2)針對視頻壓縮的多幀質量提升
接下來我們需要將此技術用于提升多幀畫面的編碼質量。通過實驗我們發現,幾乎所有的編碼標準都會使視頻質量出現明顯波動,尤其HEVC編碼會導致幀與幀之間的編碼質量差異過大。體現在畫面上的結果可能是第50、61幀質量較高畫面較為清晰而到了第87幀則被遭到丟棄使其難以恢復原有質量。此時我們需要依賴87幀前后質量較高幀的幫助,進一步還原提升87幀的質量,這就是多幀質量提升操作。進行多幀質量提升之前,我們需要借助SVM對每一幀進行質量評估并選取其中質量不一的幀構造其特征并分類:ln=1代表高質量幀ln=0代表低質量幀。
在確定高質量幀與低質量幀后,系統會在處理視頻的同時將低質量目標幀與其前后相鄰高質量幀一并輸入神經網絡,借助運動補全方法使得目標幀與其前后相鄰兩幀像素內容一致,編碼近似,憑借機器學習得到的優化算法處理這三幀從而顯著提高其壓縮質量。如畫面當中球所在的區域,畫面質量較高。
上圖展示的是我們測試得到的主觀指標,Ave一行代表平均測試結果。可以看到我們MFQE的質量提升平均值達到了0.5102dB,領先于前者多種算法。下圖展示的是直觀帶來的優化體驗,可以看到畫面中籃球所在畫面區域的質量重建提升十分明顯。
3.2 復雜度降低
大家知道,H.265、H.266的最大貢獻是CTU分割,并且H.266引入了二叉樹與三叉樹,其背后復雜程度十分驚人。例如在CU分割時,由于無法準確預判分割塊的編碼性能優劣,只能通過預編碼也就是對RDO進行全局搜索的形式確定分割塊的編碼性能;由此導致的編譯次數增多會使其復雜度占總體高達80%。
為了進一步降低復雜程度,我們可借助內容分析推測合適的CU分割策略。對于單幀可通過CNN挖掘其在空間上的相關性;
而對于多個相連幀可通過CNN+LSTM分析得出其在分割上的相關性與一致性。
之后我們的探索主要分為三步完成:首先是建立一個包括115個視頻與兩千多幅圖像的數據庫,接下來我們運用特征分析方法構建結構性輸出,最后利用卷積神經網絡預測塊分割策略。
上圖展示的是降低復雜度帶來的性能提升。在幀間模式上我們的復雜度可降低約54%,與此同時BDBR增加約1.459%,BDPSNR損失約0.046%;對于幀內模式而言同時測試圖像與視頻,無論是視頻還是圖像其復雜度都會降低約60%,與此同時BDBR增加約2%。下圖展示的是我們與此技術相關的部分技術專利。
4.面向全景視頻的感知視頻壓縮編碼
接下來將為大家介紹我們針對全景視頻進行的感知壓縮編碼優化。
全景視頻的感知壓縮編碼主要分為以下三個步驟:第一步進行的Model預測主要是用于判斷用戶觀看全景視頻時人眼視野關注到的畫面區域;第二步進行全景視頻質量評估。最后進行視頻編碼優化。
4.1 Model預測
人類視覺系統對全景視頻的感知與普通視頻存在明顯區別:用戶在觀看全景視頻時視覺不會受到畫幅的限制,但人眼110度的視覺角度只占全景視頻180度甚至360度廣幅畫面中的一部分,而人眼真正關注的視覺重點可能最多在60度左右;通俗來說用戶在觀看全景視頻時畫面中的很多內容是無法感知的。這就是我們在實現全景視頻的感知壓縮編碼時首要解決的問題:哪些區域是用戶視覺重點關注的?全景視頻的視角變化與用戶頭部運動的狀態有關,我們可從用戶頭部運動入手,借助機器學習對用戶頭部運動與設備的交互所決策的視野角度進行強化學習訓練;而人類頭部的運動狀態與交互行為是根據全景視頻內容展現的環境而改變的;這種根據環境變化得到的頭部運動狀態與交互反饋信息能讓我們準確得到經優化構造而成的最優回報函數(Reward),讓用戶在自己最為感興趣的目標畫面上得到最佳的用戶體驗;最后我們通過深度學習進一步優化此回報函數得出其最佳策略,再將此策略運用于對用戶頭部運動狀態的預測判斷;擁有了用戶頭部運動狀態的預測信息,我們就可以預測推斷用戶視野的變化并將其用于視頻畫面的感知壓縮編碼。
圖中上半部分展示的是我們通過多人實驗得到的可用于全景識別感知預測的DRL Network模型的架構。根據圖中下半部分展示的測試結果,我們能從中得出視覺熱點圖。
下圖同樣展示了我們的定量測試結果。
4.2 全景識別與質量評估
為了實現質量評估,我們首先構建了有包括60個無失真的基準視頻在內的600個全景視頻的全景識別數據庫。其中的基準視頻采用了ERP、RCMP、TSP三種映射模式并使用27、37、42三種QP規格的壓縮方式。我們請大約221個觀測對象為多個全景視頻集評分并使每個全景視頻擁有約20個評分數據;評分同時我們也會收集被測對象頭部的運動狀態、視野位置、眼部運動狀態等關鍵數據。
整理分析這些信息我們可得到多項結論:
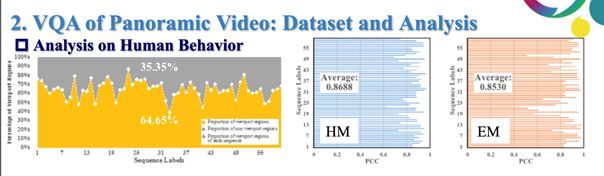
1)左側圖線代表是人們視野不關注的比例變化,平均有35%的區域是用戶從未關注到的;側圖線代表頭部與眼睛運動的一致性,縱坐標代表視頻而橫坐標代表相關系數,可以看到頭部運動狀態與眼部運動狀態相關性保持較高,由此我們可得出結論:用戶觀看全景視頻時的行為習慣相似,畫面中有約30%的內容被視覺系統忽視。
2)用戶行為與全景視頻質量的關系:畫面中用戶看不到或者不愿意觀看的非重點部分的質量變化對用戶觀看體驗的影響微乎其微;將用戶頭部運動狀態、視野變化、眼動狀態與PSNR相結合可大幅度提升PSNR性能,即可推斷出頭部運動狀態、眼動狀態等用戶行為可被用于提升全景視頻質量評估性能。
基于以上研究,我們可針對全景視頻提出基于深度學習的質量預測方法,也就是將頭部運動狀態檢測與眼動狀態檢測得到的數據用于評估不同優化模型得出的全景視頻質量并將輸出的質量分數與其相關性進行比較。如傳統方法得到的PCC模型預測值約為0.78,而SRCC模型則可達到0.81,從而進一步提升全景視頻質量評估結果。
下圖展示的是與此項研究相關的一些References。

5.總結
最后總結一下,首先我們的這些技術離不開數據的澎湃力量;其次全新的感知模型擁有非凡的編碼優化潛力,最后是未來層出不窮的創新媒體渠道與應用模式離不開技術的強大力量。
-
編碼技術
+關注
關注
1文章
35瀏覽量
11043 -
機器學習
+關注
關注
66文章
8377瀏覽量
132406
原文標題:編碼壓縮新思路:面向QoE的感知視頻編碼
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
處理圖像和視頻編碼中,基于感知視頻編碼優化框架
面向頻譜感知的傳感器網絡設計
Agilent N2X IPTV QoE Test Solu
基于PCI的視頻編碼卡的設計與實現
淺析移動通信網絡中的QoE
HSDPA系統中一種感知用戶終端緩存狀態的QoE保障調度算法
字典學習的壓縮感知視頻編解碼模型
AI視頻編碼技術創新 探索極致視覺體驗
面向機器視覺的視頻編碼將成為5G和后5G時代的主要增量流量來源之一
什么是視頻編碼 常見的視頻編碼格式有哪些
實時互動下視頻QoE端到端輕量化網絡建模






 工商網監
工商網監
評論