 數據并行化對神經網絡訓練有何影響?谷歌大腦進行了實證研究
數據并行化對神經網絡訓練有何影響?谷歌大腦進行了實證研究
近期的硬件發展實現了前所未有的數據并行化,從而加速神經網絡訓練。利用下一代加速器的最簡單方法是增加標準小批量神經網絡訓練算法中的批大小。最近谷歌大腦發表了一篇論文,旨在通過實驗確定在訓練階段增加批大小的作用,評價指標是得到目標樣本外誤差所需的訓練步數。最后,批大小增加到一定量將不再減少所需訓練步數,但批大小和訓練步數之間的確切關系對從業者、研究者和硬件設計人員來說非常重要。谷歌大腦研究不同訓練算法、模型和數據集中批大小和訓練步數之間關系的變化,以及工作負載之間的最大變化。該研究還解決了批大小是否影響模型質量這一問題。
神經網絡在解決大量預測任務時非常高效。在較大數據集上訓練的大型模型是神經網絡近期成功的原因之一,我們期望在更多數據上訓練的模型可以持續取得預測性能改進。盡管當下的 GPU 和自定義神經網絡加速器可以使我們以前所未有的速度訓練當前最優模型,但訓練時間仍然限制著這些模型的預測性能及應用范圍。很多重要問題的最佳模型在訓練結束時仍然在提升性能,這是因為研究者無法一次訓練很多天或好幾周。在極端案例中,訓練必須在完成一次數據遍歷之前終止。減少訓練時間的一種方式是提高數據處理速度。這可以極大地促進模型質量的提升,因為它使得訓練過程能夠處理更多數據,同時還能降低實驗迭代時間,使研究者能夠更快速地嘗試新想法和新配置條件。更快的訓練還使得神經網絡能夠部署到需要頻繁更新模型的應用中,比如訓練數據定期增刪的情況就需要生成新模型。
數據并行化是一種直接且常用的訓練加速方法。本研究中的數據并行化指將訓練樣本分配到多個處理器來計算梯度更新(或更高階的導數信息),然后對這些局部計算的梯度更新求和。只要訓練目標函數可分解為在訓練樣本上的和,則數據并行化可以適用于任意模型,應用到任意神經網絡架構。而模型并行化(對于相同的訓練樣本,將參數和計算分配到不同處理器)的最大程度則依賴于模型大小和結構。盡管數據并行化易于實現,但大規模系統應該考慮所有類型的并行化。這篇論文主要研究在同步訓練設置下數據并行化的成本和收益。
神經網絡訓練硬件具備越來越強大的數據并行化處理能力。基于 GPU 或定制 ASIC 的專門系統輔以高性能互連技術使得能夠處理的數據并行化規模前所未有地大,而數據并行化的成本和收益尚未得到深入研究。一方面,如果數據并行化能夠顯著加速目前的系統,我們應該構建更大的系統。另一方面,如果額外的數據并行化收益小、成本高,則我們在設計系統時或許需要考慮最大化串行執行速度、利用其他并行化類型,甚至優先考慮能量使用、成本。
該研究嘗試對數據并行化對神經網絡訓練的影響進行大量嚴謹的實驗研究。為了實現該目標,研究者考慮目前數據并行化局限條件下的實際工作負載,嘗試避免假設批大小函數對最優元參數的影響。該研究主要關注小批量隨機梯度下降(SGD)的變體,它們是神經網絡訓練中的主要算法。該研究的貢獻如下:
1. 該研究展示了批大小和達到樣本外誤差所需訓練步數之間的關系在六個不同的神經網絡家族、三種訓練算法和七個不同數據集上具備同樣的特征。
具體來說,對于每個工作負載(模型、訓練算法和數據集),增加批大小最初都會導致訓練步數的下降,但最終增加批大小將無法減少訓練步數。該研究首次通過實驗驗證不同模型、訓練算法和數據集上批大小與訓練步數的關系,其分別調整每個批大小的學習率、動量和學習率調度器。
2. 該研究證明最大有用批大小因工作負載而異,且依賴于模型、訓練算法和數據集的特性。具體而言,
帶動量(和 Nesterov 動量)的 SGD 能夠比普通的 SGD 更好地利用較大的批大小,未來可以研究其他算法的批大小擴展特性。
一些模型在允許訓練擴展至更大的批大小方面優于其他模型。研究者將實驗數據和不同模型特性與最大有用批大小之間的關系結合起來,表明該關系與之前研究中表達的不同(如更寬的模型未必能夠更好地擴展至更大的批大小)。
數據集對最大有用批大小的影響不如模型和訓練算法的影響,但該影響并非一貫依賴于數據集規模。
3. 訓練元參數的最優值(如學習率)并非一直遵循與批大小的簡單關系,盡管目前有大量啟發式方法可以調整元參數。學習率啟發式方法無法處理所有問題或所有批大小。假設簡單的啟發式方法(如隨著批大小的變化對學習率進行線性擴展)可能導致最差解或對規模遠遠小于基礎批大小的批量進行離散訓練。
4. 該研究回顧了之前研究中使用的實驗方案,部分解決了增加批大小是否降低模型質量這一問題。研究人員假設不同批大小對應的計算預算和元參數選擇能夠解釋文獻中的諸多分歧,然后發現沒有證據能夠證明批大小與模型質量下降存在必然關系,但是額外的正則化方法在批量較大的情況下變得更加重要。
實驗
實驗所用數據集如下所示:
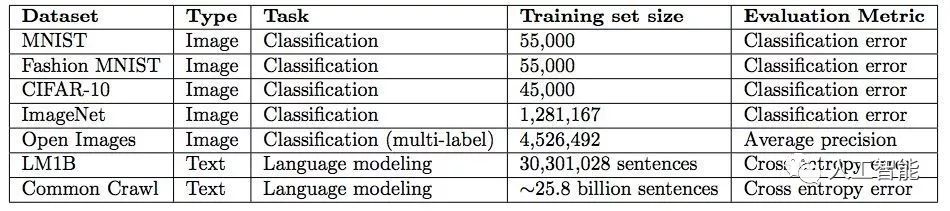
實驗所用模型:
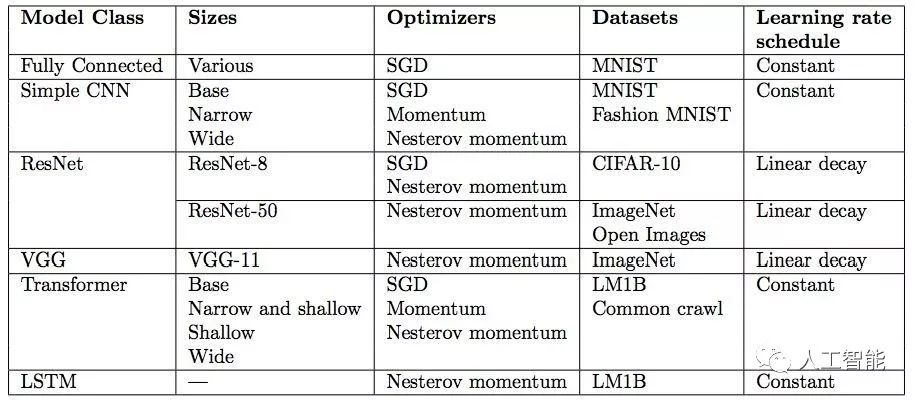
實驗依賴大量元參數調整,如學習率、動量和學習率調度器。在每次實驗中,研究者檢查最佳試驗與元參數搜索空間邊界是否太過接近,從而驗證元參數搜索空間。
圖 1:對于上圖中所有問題,訓練步數與批大小之間的關系具備同樣的特征。
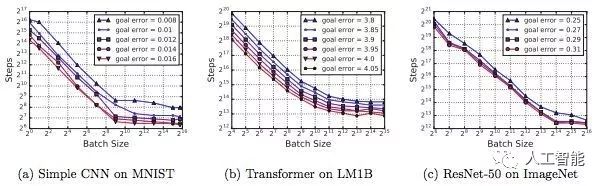
圖 2:對于不同(相近)性能目標,Steps-to-result 圖具備類似形式。
一些模型能夠更好地利用大批量
如下圖所示:
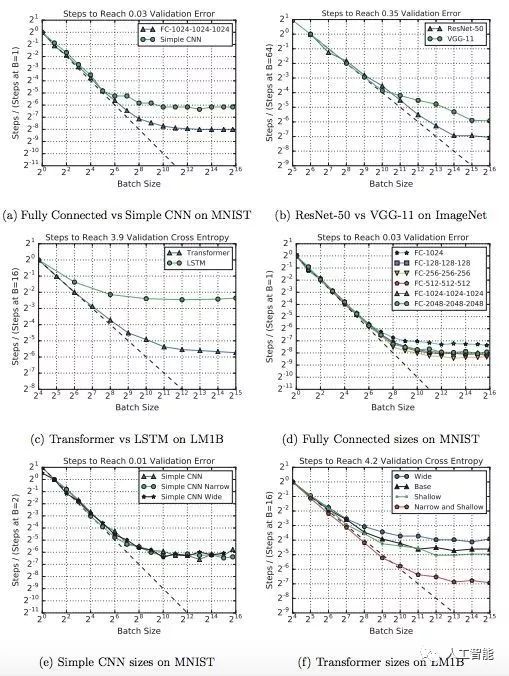
圖 3:a-c 展示了在相同數據集上,一些模型架構能夠從大批量中獲益更多。d、f 展示了寬度和深度變化會影響模型利用大批量的能力,但是該情況并不適用于所有模型架構。圖中所有的 MNIST 模型都使用了 mini-batch SGD,而其他模型使用了帶 Nesterov 動量的 SGD。每個圖的目標驗證誤差允許所有模型變體都能夠達到目標誤差。
帶動量的 SGD 可在大批量上實現完美擴展,但在小批量上能力與普通 SGD 相當。
如下圖所示:
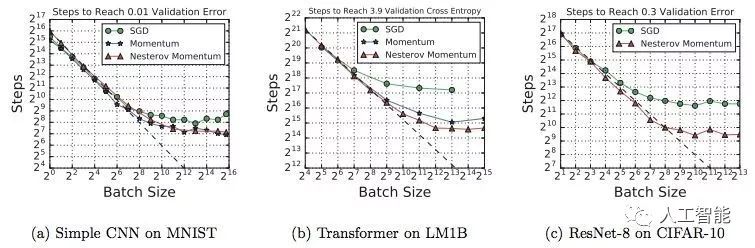
數據集對最大有用批大小有影響,但影響程度可能不如模型或優化器
圖 5:數據集對最大有用批大小有影響。
圖 6:數據集大小的影響。
正則化在某些批大小上更加有用
圖 7:上圖是 ImageNet 數據集上的 ResNet-50 模型。每個點對應不同的元參數,因此每個點的學習率、Nesterov 動量和學習率調度器都是獨立選擇的。每個批大小的訓練預算是固定的,但是不同批大小的訓練預算不同。
最佳學習率和動量隨批大小的變化而改變
圖 8:最佳學習率未必遵循線性或平方根擴展啟發式方法。
圖 9:在固定訓練數量的 epoch 中,達到目標誤差的元參數空間區域隨著批大小增加而縮小。
圖 10:在固定的訓練步數下,達到目標誤差的元參數空間區域隨著批大小增加而擴大。
解的質量更多地依賴計算預算而不是批大小
圖 12:驗證誤差更多地依賴計算預算,而非批大小。
實驗缺陷
在元參數調整時難免會有一定程度的人類判斷。研究分析沒有考慮到取得目標誤差的魯棒性。
-
加速器
+關注
關注
2文章
795瀏覽量
37773 -
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
數據集
+關注
關注
4文章
1205瀏覽量
24649
原文標題:數據并行化對神經網絡訓練有何影響?谷歌大腦進行了實證研究
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論