 如何在TensorFlow中訓練嵌入
如何在TensorFlow中訓練嵌入
今天的文章介紹了嵌入這一概念,并且舉了一個簡單的例子來說明如何在 TensorFlow 中訓練嵌入,此外還說明了如何使用 TensorBoard Embedding Projector 查看嵌入(真實示例http://projector.tensorflow.org/?hl=zh-CN)。前兩部分適合機器學習或 TensorFlow 新手,而 Embedding Projector 指南適合各個層次的用戶。
有關這些概念的另一個教程,請參閱《機器學習速成課程》的 “嵌入” 部分(https://developers.google.cn/machine-learning/crash-course/embeddings/video-lecture?hl=zh-CN)。
嵌入是從離散對象(例如字詞)到實數向量的映射。例如,英語字詞的 300 維嵌入可能包括:
blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259)blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158)orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213)oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976)
這些向量中的各個維度通常沒有固有含義,機器學習所利用的是向量的位置和相互之間的距離這些整體模式。
嵌入對于機器學習的輸入非常重要。分類器(更籠統地說是神經網絡)適用于實數向量。它們訓練密集向量時效果最佳,其中所有值都有助于定義對象。不過,機器學習的很多重要輸入(例如文本的字詞)沒有自然的向量表示。嵌入函數是將此類離散輸入對象轉換為有用連續向量的標準和有效方法。
嵌入作為機器學習的輸出也很有價值。由于嵌入將對象映射到向量,因此應用可以將向量空間中的相似性(例如歐幾里德距離或向量之間的角度)用作一項強大而靈活的標準來衡量對象相似性。一個常見用途是找到最近的鄰點。例如,下面是采用與上述相同的字詞嵌入后,每個字詞的三個最近鄰點和相應角度:
blue: (red, 47.6°), (yellow, 51.9°), (purple, 52.4°)blues: (jazz, 53.3°), (folk, 59.1°), (bluegrass, 60.6°)orange: (yellow, 53.5°), (colored, 58.0°), (bright, 59.9°)oranges: (apples, 45.3°), (lemons, 48.3°), (mangoes, 50.4°)
這樣應用就會知道,在某種程度上,蘋果和橙子(相距 45.3°)的相似度高于檸檬和橙子(相距 48.3°)。
TensorFlow 中的嵌入
要在 TensorFlow 中創建字詞嵌入,我們首先將文本拆分成字詞,然后為詞匯表中的每個字詞分配一個整數。我們假設已經完成了這一步,并且word_ids是這些整數的向量。例如,可以將 “I have a cat.” 這個句子拆分成[“I”, “have”, “a”, “cat”, “.”],那么相應word_ids張量的形狀將是[5],并且包含 5 個整數。為了將這些字詞 ID 映射到向量,我們需要創建嵌入變量并使用tf.nn.embedding_lookup函數,如下所示:
word_embeddings = tf.get_variable(“word_embeddings”, [vocabulary_size, embedding_size])embedded_word_ids = tf.nn.embedding_lookup(word_embeddings, word_ids)
完成此操作后,示例中張量embedded_word_ids的形狀將是[5, embedding_size],并且包含全部 5 個字詞的嵌入(密集向量)。在訓練結束時,word_embeddings將包含詞匯表中所有字詞的嵌入。
嵌入可以通過很多網絡類型進行訓練,并具有各種損失函數和數據集。例如,對于大型句子語料庫,可以使用遞歸神經網絡根據上一個字詞預測下一個字詞,還可以訓練兩個網絡來進行多語言翻譯。字詞的向量表示教程中介紹了這些方法。
直觀顯示嵌入
TensorBoard 包括Embedding Projector,這是一款可讓您以交互的方式直觀顯示嵌入的工具。此工具可以讀取模型中的嵌入,并以二維或三維方式渲染這些嵌入。
Embedding Projector 具有三個面板:
數據面板:位于左上方,您可以在其中選擇運行、嵌入變量和數據列,以對點進行著色和標記
投影面板:位于左下方,您可以在其中選擇投影類型
檢查工具面板:位于右側,您可以在其中搜索特定點并查看最近鄰點的列表
投影
Embedding Projector 提供三種方法來降低數據集的維度。
t-SNE:一種非線性不確定性算法(T 分布式隨機鄰點嵌入),它會嘗試保留數據中的局部鄰點,通常以扭曲全局結構為代價。您可以選擇是計算二維還是三維投影。
PCA:一種線性確定性算法(主成分分析),它嘗試用盡可能少的維度捕獲盡可能多的數據可變性。PCA 會突出數據中的大規模結構,但可能會扭曲本地鄰點。Embedding Projector 會計算前 10 個主成分,您可以從中選擇兩三個進行查看。
自定義:線性投影到您使用數據中的標簽指定的水平軸和垂直軸上。例如,您可以通過為 “左” 和 “右” 指定文本格式來定義水平軸。Embedding Projector 會查找標簽與 “左” 格式相匹配的所有點,并計算這些點的形心;“右” 格式與此類似。穿過這兩個形心的線定義了水平軸。同樣地,計算與 “上” 和 “下” 文本格式相匹配的點的形心可定義垂直軸。
要查看其他實用文章,請參閱如何有效使用 t-SNE和直觀介紹主成分分析。
探索
您可以使用自然的點擊并拖動手勢來縮放、旋轉和平移,從而進行直觀探索。將鼠標懸停在某個點上即可看到該點的所有元數據。您還可以檢查最近的鄰點子集。點擊某個點以后,右窗格中會列出最近的領點,以及到當前點的距離。投影中還會突出顯示最近的鄰點。
有時,將視圖限制為點的子集并僅投影這些點非常有用。要執行此操作,您可以通過多種方式選擇點:
點擊某個點之后,其最近的鄰點也會處于選中狀態
搜索之后,與查詢匹配的點會處于選中狀態
啟用選擇,點擊某個點并拖動可定義選擇范圍
然后,點擊右側檢查工具窗格頂部的 “隔離 nnn 個點” 按鈕。下圖顯示已選擇 101 個點,因此用戶可以點擊 “隔離 101 個點”:
在字詞嵌入數據集中選擇 “重要” 一詞的最近鄰點
高級技巧:使用自定義投影進行過濾可能會非常有用。我們在下圖中濾出了 “政治” 一詞的 100 個最近鄰點,并將它們投影到 “最差” - “最優” 向量上作為 x 軸。y 軸是隨機的。這樣一來,我們可以發現 “想法”、“科學”、“視角”、“新聞” 這些字詞位于右側,而 “危機”、“暴力” 和 “沖突” 這些字詞位于左側。
自定義投影控件。 “政治” 的鄰點到 “最優” - “最差” 向量的自定義投影
要分享您的發現,可以使用右下角的書簽面板并將當前狀態(包括任何投影的計算坐標)保存為小文件。接著可以將 Projector 指向一個包含一個或多個這些文件的集合,從而生成下面的面板。然后,其他用戶就可以查看一系列書簽。
元數據
如果您使用嵌入,則可能需要向數據點附加標簽/圖片。您可以通過生成一個元數據文件(其中包含每個點的標簽),并在 Embedding Projector 的數據面板中點擊 “加載數據” 來完成此操作。
元數據可以是標簽,也可以是圖片,它們存儲在單獨的文件中。如果是標簽,則格式應該是TSV 文件(制表符顯示為紅色),其中第一行包含列標題(以粗體顯示),而后續行包含元數據值。例如:
Word FrequencyAirplane 345Car 241...
假設元數據文件中的行順序與嵌入變量中的向量順序相匹配,但標題除外。那么,元數據文件中的第 (i+1) 行對應于嵌入變量的第 i 行。如果 TSV 元數據文件僅有一列,那么不會有標題行,并且假設每行都是嵌入的標簽。我們之所以包含此例外情況,是因為它與常用的“詞匯表文件”格式相匹配。
要將圖片用作元數據,您必須生成一個sprite 圖片,其中包含小縮略圖,嵌入中的每個向量都有一個小縮略圖。sprite 應該按照行在前的順序存儲縮略圖:將第一個數據點放置在左上方,最后一個數據點放在右下方,但是最后一行不必填充,如下所示。
點擊 此鏈接 可查看 Embedding Projector 中的一個有趣縮略圖示例(https://tensorflow.google.cn/images/embedding-mnist.mp4?hl=zh-CN)。
迷你版常見問題解答
“嵌入” 是一種操作還是一種事物?都是。人們一直說的是在向量空間中嵌入字詞(操作),以及生成字詞嵌入(事物)。兩者的共同點在于嵌入這一概念,即從離散對象到向量的映射。創建或應用該映射是一種操作,但映射本身是一種事物。
嵌入是高維度還是低維度?視情況而定。例如,與可包含數百萬個字詞和短語的向量空間相比,一個 300 維的字詞和短語向量空間通常被視為低維度(且密集)空間。但從數學角度上來講,它是高維度空間,顯示的很多屬性與人類直覺了解的二維和三維空間大相徑庭。
嵌入與嵌入層是否相同?不同。嵌入層是神經網絡的一部分,而嵌入則是一個更寬泛的概念。
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100542 -
機器學習
+關注
關注
66文章
8378瀏覽量
132415 -
tensorflow
+關注
關注
13文章
329瀏覽量
60499
原文標題:如何在 TensorFlow 中訓練嵌入
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何在Raspberry Pi上安裝TensorFlow
【大聯大世平Intel?神經計算棒NCS2試用體驗】訓練模型軟件 tensorflow 的艱難安裝
情地使用Tensorflow吧!
TensorFlow是什么
淺談深度學習之TensorFlow
TensorFlow優化器種類及其用法詳解
如何在WINDOWS系統下使用tensorflow來下圍棋呢
如何使用TensorFlow將神經網絡模型部署到移動或嵌入式設備上
TensorFlow Lite是TensorFlow針對移動和嵌入式設備的輕量級解決方案
基于tensorflow.js設計、訓練面向web的神經網絡模型的經驗
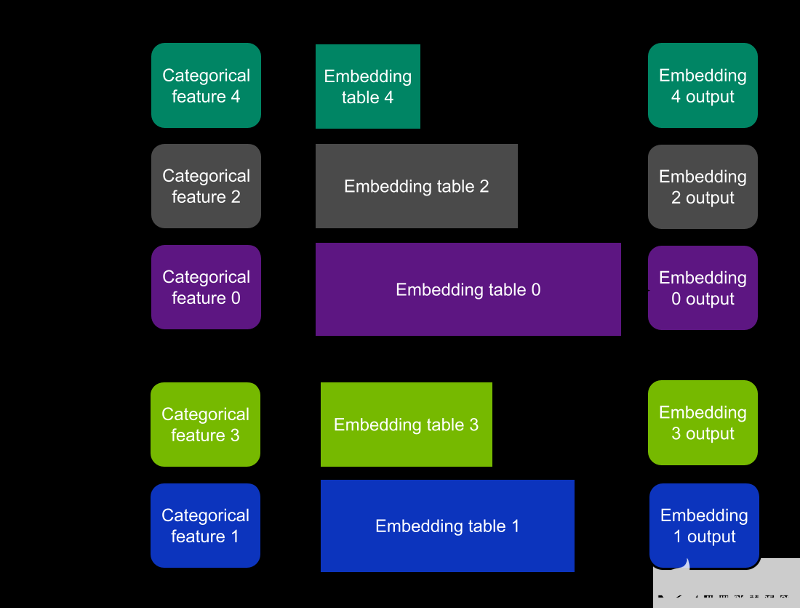
如何在TensorFlow2中高效培訓1130億參數推薦系統





 工商網監
工商網監
評論