 用于衡量CPU的繁忙程度的正確指標
用于衡量CPU的繁忙程度的正確指標
1. 引言
可能你認為的 90% CPU 利用率意味著這樣的情形:

而實際卻可能是這樣的:

CPU 并非 90% 的時間都在忙著,很大一部分時間在等待,或者說“停頓(Stalled)”了。這種情況表示處理器流水線停頓,一般由資源競爭、數據依賴等原因造成。多數情況下表現為等待訪存操作,其中又以讀操作為主。在停頓周期內,不能執行指令,這意味著你的程序不往前走。值得注意的是,圖中 “Stalled” 狀態所占的比例是作者依據生產環境中的典型場景計算而來,具有普遍現實意義。因此,大多時候 CPU 處于停頓狀態,而你卻不知道,因為 CPU 利用率這個指標沒有告訴你真相。通過進一步分析 CPU 停頓的原因,可以指導代碼優化,提高執行效率,這是我們深入理解CPU微架構的動力之一。
2. CPU 利用率的真實含義是什么?
我們通常所說的CPU利用率是指 “non-idle time”:即CPU不執行 idle thread 的時間。操作系統內核會在上下文切換時記錄CPU的運行時間。假設一個 non-idle thread 開始運行,100ms 后結束,內核會認為這段時間內 CPU 利用率為 100%。這種度量方式源于分時復用系統。早在阿波羅登月艙的導航計算機中,idle thread 當時被叫做 “DUMMY JOB”,工程師通過比對運行 “DUMMY JOB” 和 “實際任務” 的時間來衡量導航系統的利用率。
那么這個所謂“利用率”的問題在哪兒呢?
當今時代,CPU 執行速度遠遠大于內存訪問速度,等待訪存的時間成為占用 CPU 時間的主要部分。當你在 top 中看到很高的 “%CPU”,你可能認為處理器是瓶頸,但實際上卻是內存。在過去很長一段時間內,CPU 頻率增長的速度大于 DRAM 訪存延時降低的速度(CPU DRAM gap),直到2005年前后,處理器廠商們才開始放棄“頻率路線”,轉向多核、超線程技術,再加上多處理器架構,這些都導致訪存需求急劇上升。盡管廠商通過增大 cache 容量、優化 cache 策略、提升總線帶寬來試圖緩解訪存瓶頸,但我們的程序仍深受 CPU stall 困擾。
3. 如何真正辨別 CPU 在做些什么?
在 PMC(Performance Monitoring Counters) 的幫助下,我們能看到更多的 CPU 運行狀態信息。下圖中,perf采集了10秒內全部 CPU 的運行狀態。

這里我們重點關注的核心度量指標是 IPC(instructions per cycle),它表示平均每個 CPU cycle 執行的指令數量,很顯然該數值越大性能越好。上圖中IPC 為 0.78,看起來還不錯,是不是 78% busy 呢?現代處理器一般有多條流水線,運行perf的那臺機器,IPC 的理論值可達到 4.0。如果我們從 IPC的角度來看,這臺機器只運行到其處理器最高速度的 19.5%(0.78 / 4.0)。幸運的是,在處理器內部,有很多 PMU event,可用來幫助我們分析造成 CPU stall 的原因。用好 PMU 需要我們熟悉處理器微架構,可以參考 Intel SDM。
4. 最佳實踐是什么?
如果 IPC < 1.0, 很可能是 Memory stall 占主導,可從軟件和硬件兩個方面考慮這個問題。軟件方面:減少不必要的訪存操作,提升 cache 命中率,盡量訪問本地節點內存;硬件方面:增加 cache 容量,加快訪存速度,提升總線帶寬。
如果IPC > 1.0, 很可能是計算密集型的程序。可以試圖減少執行指令的數量:消除不必要的工作。火焰圖CPU flame graphs,非常適用于分析這類問題。硬件方面:嘗試超頻、使用更多的 core 或 hyperthread。作者根據PMU相關的工作經驗,設定了1.0這個閾值,用于區分訪存密集型(memory-bound)和計算密集型(cpu-bound)程序。讀者可以根據自己的實際工作平臺,合理調整這個閾值。
5. 性能工具應該告訴我們什么?
作者認為,性能工具中使用 %CPU 時都應該附帶上 IPC,或者將 %CPU 拆分為指令執行消耗 cycle(%INS) 和 stalled 的 cycle(%STL)。對應到top,在 Linux 系統有一個能夠顯示每個處理器 IPC 的工具tiptop:
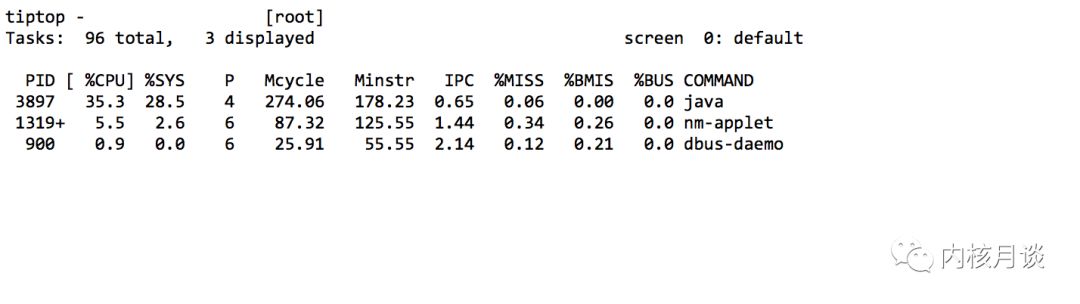
6. 其他可能讓 CPU 利用率引起誤解的因素
除了訪存導致的 stall 容易讓人誤解 CPU 利用率外,還有其他一些因素:
溫度原因導致處理器 stall;
Turboboost 干擾了時鐘速率;
內核使得時鐘速率加快;
平均帶來的問題:1分鐘利用率平均 80%,掩蓋了中間 100% 部分;
自旋鎖: CPU 一直在被使用,同時 IPC 也很高,但是應用邏輯上并沒有任何進展。
7. 更新:CPU 利用率真的錯了嗎?
這篇文章引起了大量留言:
http://www.brendangregg.com/blog/2017-05-09/cpu-utilization-is-wrong.html的留言欄;
https://news.ycombinator.com/item?id=14301739
https://www.reddit.com/r/programming/comments/6a6v8g/cpu_utilization_is_wrong/
總結下作者的回答是:這里討論的并不是 iowait (那是磁盤IO),而且如果你已經確認是訪存密集型,是有些處理辦法(參考上面)。
那么 CPU 利用率指標是確確實實錯誤的,還是只是容易誤導?如作者前面所說,他認為許多人把高 CPU 利用率理解為瓶頸在 CPU 上,這一行為才是錯誤的;其實單看 CPU 利用率并不清楚瓶頸在何處,很多時候瓶頸是在外部。這個指標技術上看是否正確?如果 CPU stall 的周期并不能被其他地方使用,它們是不是也就因此是“忙于等待“(聽起來有點矛盾)?在有些情況,確實如此,你可以說 CPU 利用率作為操作系統級別的指標技術上看是對的,但是容易產生誤導。從另一個角度來說,有超線程的情況下,那些 stalled 的周期是可以被其他線程使用的,這時 “%CPU” 可能會將可用的周期統計為正在使用,這種情況是錯誤的。這篇文章作者想關注的是解釋清楚這個問題,并給出解決方法建議,但沒錯,CPU 利用率這個指標本身也是存在一些問題的。
當你可能會說利用率作為一個指標已經不對,Andrian Cockcroft之前討論已經指出過 (http://www.hpts.ws/papers/2007/Cockcroft_HPTS-Useless.pdf)。
8. 結論
CPU 利用率已經開始成為一個容易誤導的指標:它包含訪存導致的等待周期,這樣會影響一些新應用。也許 “%CPU” 應該重命名為 “%CYC”(cycles的縮寫)。要清楚知道 “%CPU” 的含義,需要使用其他指標進行輔助,其中就包括每周期指令數(IPC)。IPC < 1.0 多半意味著訪存密集型,IPC > 1.0 多半意味著計算密集型。作者之前的文章中涵蓋有 IPC 說明,以及用于測量 IPC 的 Performance Monitoring Counters(PMCs)的介紹。
所有的性能監控產品如果展示 “%CPU”,都應該同時展示 PMC 指標用于解釋其真實意義,不要誤導用戶。比如,可以把 “%CPU” 和 “IPC” 一起放,或者說指令執行消耗周期和 stalled 周期。有這些指標之后,開發者和操作者就能夠知道該如何更好地對應用和系統進行調優。
-
cpu
+關注
關注
68文章
10825瀏覽量
211146 -
IPC
+關注
關注
3文章
345瀏覽量
51823
原文標題:震驚,用了這么多年的 CPU 利用率,其實是錯的
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ADC直流分辨率衡量指標問題
衡量電能質量的指標
PUE指標能準確衡量數據中心能效嗎?
通過哪些指標衡量開關電源的優劣
如何衡量IT運營的成功和指標?

衡量CDN服務質量的指標有哪些

Aigtek:衡量基準電壓源的技術指標有哪些






 工商網監
工商網監
評論