 重讀Youtube深度學習推薦系統論文不同體驗和收獲
重讀Youtube深度學習推薦系統論文不同體驗和收獲
這里是王喆的機器學習筆記,每隔一到兩周我會站在算法工程師的角度講解一些計算廣告、推薦系統相關的文章。選擇文章必須滿足一下三個條件:
一是工程導向的;
二是阿里、Facebook、Google 等一線互聯網公司出品的;
三是前沿或者經典的。
這周我們一起討論一下 *** 的深度推薦系統論文《Deep Neural Networks for YouTube Recommendations》,這是 2016 年的論文,按照今天的標準來看,已經沒有什么新穎的地方,我也是兩年前讀過這篇文章之后就放下了,但前幾天重讀這篇文章,竟讓發現了諸多亮點,幾乎處處是套路,處處是經驗,不由驚為神文。這篇神文給我留下的深刻印象有兩點:
這毫無疑問是工業界論文的典范,是我非常推崇的工程導向的,算法工程師必讀的文章;
我以為毫不起眼的地方,也藏著 *** 工程師寶貴的工程經驗,相比上周介紹的阿里的深度興趣網絡 DIN,最重要的價值就在于 Attention 機制,這篇文章你應該精確到句子來體會,這是我驚為神文的原因。
廢話不多說,下面就跟大家分享一下兩次拜讀這篇論文的不同體驗和收獲。
第一遍讀這篇論文的時候,我想所有人都是沖著算法的架構去的,在深度學習推薦系統已經成為各大公司“基本操作”的今天,*** 在算法架構上并無驚奇之處,我們來快速介紹一下文章中的深度學習推薦系統的算法架構。
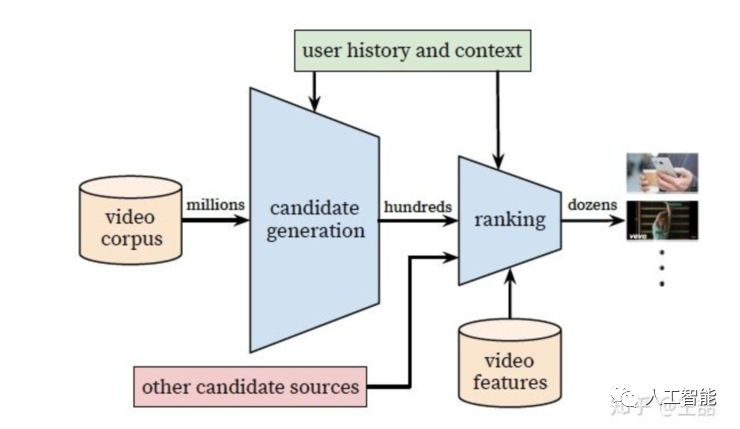
*** 的用戶推薦場景自不必多說,作為全球最大的 UGC 的視頻網站,需要在百萬量級的視頻規模下進行個性化推薦。由于候選視頻集合過大,考慮 online 系統延遲問題,不宜用復雜網絡直接進行推薦,所以 *** 采取了兩層深度網絡完成整個推薦過程:
第一層是Candidate Generation Model完成候選視頻的快速篩選,這一步候選視頻集合由百萬降低到了百的量級。
第二層是用Ranking Model完成幾百個候選視頻的精排。
首先介紹 candidate generation 模型的架構。
*** Candidate Generation Model
我們自底而上看這個網絡,最底層的輸入是用戶觀看過的 video 的 embedding 向量,以及搜索詞的 embedding 向量。至于這個 embedding 向量是怎么生成的,作者的原話是這樣的:
Inspired by continuous bag of words language models, we learn high dimensional embeddings for each video in a xed vocabulary and feed these embeddings into a feedforward neural network
所以作者是先用 word2vec 方法對 video 和 search token 做了 embedding 之后再作為輸入的,這也是做 embedding 的“基本操作”,不用過多介紹;當然,除此之外另一種大家應該也比較熟悉,就是通過加一個 embedding 層跟上面的 DNN 一起訓練,兩種方法孰優孰劣,有什么適用場合,大家可以討論一下。
特征向量里面還包括了用戶的地理位置的 embedding,年齡,性別等。然后把所有這些特征 concatenate 起來,喂給上層的 ReLU 神經網絡。
三層神經網絡過后,我們看到了 softmax 函數。這里 *** 的同學們把這個問題看作為用戶推薦 next watch 的問題,所以輸出應該是一個在所有 candidate video 上的概率分布,自然是一個多分類問題。
好了,這一套深度學習的“基本操作”下來,就構成了 *** 的 candidate generation 網絡,看似平淡無奇,其實還是隱藏著一些問題的,比如:
架構圖的左上角,為什么在 online serving 的時候不直接用這套網絡進行預測而要使用 nearest neighbor search 的方法?
多分類問題中,*** 的 candidate video 有百萬之巨,意味著有幾百萬個分類,這必然會影響訓練效果和速度,如何改進?
這些問題在讀第一遍的時候我也沒有深想深看,但卻是工程實現中必然會遇到的問題,我們隨后再深入介紹論文中的解決方法。
既然得到了幾百個候選集合,下一步就是利用 ranking 模型進行精排序,下面是 ranking 深度學習網絡的架構圖。

*** Ranking Model
乍一看上面的 ranking model 似乎與 candidate generation 模型沒有什么區別,模型架構還是深度學習的“基本操作”,唯一的區別就是特征工程,那么我們就講講特征工程。
事實上原文也明確說明了,引入另一套 DNN 作為 ranking model 的目的就是引入更多描述視頻、用戶以及二者之間關系的特征,達到對候選視頻集合準確排序的目的。
During ranking, we have access to many more features describing the video and the user's relationship to the video because only a few hundred videos are being scored rather than the millions scored in candidate generation.
具體一點,從左至右的特征依次是:
impression video ID embedding:當前要計算的 video 的 embedding
watched video IDs average embedding:用戶觀看過的最后 N 個視頻 embedding 的 average pooling
language embedding:用戶語言的 embedding 和當前視頻語言的 embedding
time since last watch:自上次觀看同 channel 視頻的時間
#previous impressions:該視頻已經被曝光給該用戶的次數
上面五個特征中,我想重點談談第 4 個和第 5 個。因為這兩個很好的引入了對用戶行為的觀察。
第 4 個特征背后的思想是:
We observe that the most important signals are those that describe a user's previous interaction with the item itself and other similar items.
有一些引入 attention 的意思,這里是用了 time since last watch 這個特征來反映用戶看同類視頻的間隔時間。從用戶的角度想一想,假如我們剛看過“DOTA 經典回顧”這個 channel 的視頻,我們很大概率是會繼續看這個 channel 的視頻的,那么該特征就很好的捕捉到了這一用戶行為。
第 5 個特征#previous impressions則一定程度上引入了 exploration 的思想,避免同一個視頻持續對同一用戶進行無效曝光,盡量增加用戶沒看過的新視頻的曝光可能性。
至此,我的第一遍論文閱讀就結束了,對 *** 的算法框架有了概念,但總覺得不過如此,沒什么太多新穎的地方。
但如果真這么想,還是太 naive 了,與上一篇阿里的深度興趣網絡 DIN 不同的是,你讀懂了 DIN 的 attention 機制,你就抓住了其論文 70% 的價值,但這篇文章,如果你只讀懂了 *** 的推薦系統架構,你只抓住了 30% 的價值。那么剩下的 70% 的價值在哪里呢?
在重讀這篇文章的時候,我從一個工程師的角度,始終繃著“如何實現”這根弦,發現這篇論文的工程價值之前被我大大忽略了。下面我列出十個文中解決的非常有價值的問題:
文中把推薦問題轉換成多分類問題,在 next watch 的場景下,每一個備選 video 都會是一個分類,因此總共的分類有數百萬之巨,這在使用 softmax 訓練時無疑是低效的,這個問題 *** 是如何解決的?
在 candidate generation model 的 serving 過程中,*** 為什么不直接采用訓練時的model進行預測,而是采用了一種最近鄰搜索的方法?
*** 的用戶對新視頻有偏好,那么在模型構建的過程中如何引入這個 feature?
在對訓練集的預處理過程中,*** 沒有采用原始的用戶日志,而是對每個用戶提取等數量的訓練樣本,這是為什么?
*** 為什么不采取類似 RNN 的 Sequence model,而是完全摒棄了用戶觀看歷史的時序特征,把用戶最近的瀏覽歷史等同看待,這不會損失有效信息嗎?
在處理測試集的時候,*** 為什么不采用經典的隨機留一法(random holdout),而是一定要把用戶最近的一次觀看行為作為測試集?
在確定優化目標的時候,*** 為什么不采用經典的 CTR,或者播放率(Play Rate),而是采用了每次曝光預期播放時間(expected watch time per impression)作為優化目標?
在進行 video embedding 的時候,為什么要直接把大量長尾的 video 直接用 0 向量代替?
針對某些特征,比如 #previous impressions,為什么要進行開方和平方處理后,當作三個特征輸入模型?
為什么 ranking model 不采用經典的 logistic regression 當作輸出層,而是采用了 weighted logistic regression?
因為我也是在視頻推薦領域工作,所以可以很負責任的說以上的十個問題都是非常有價值的。
-
機器學習
+關注
關注
66文章
8377瀏覽量
132409 -
深度學習
+關注
關注
73文章
5492瀏覽量
120977
原文標題:重讀 Youtube 深度學習推薦系統論文,字字珠璣,驚為神文
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ICLR 2019論文解讀:深度學習應用于復雜系統控制

嵌入式系統論文 (幾十篇)
深度強化學習給推薦系統以及CTR預估工業界帶來的最新進展

嵌入式系統論文總結






 工商網監
工商網監
評論