 有人開源PyTorch實現極慢視頻 突破人類極限
有人開源PyTorch實現極慢視頻 突破人類極限
英偉達團隊CVPR-18論文Super SloMo使用深度學習,能將任意視頻變為“高清慢速播放”模式,從此不再錯過任何細節。今天有人開源了PyTorch實現,趕緊來試試吧!
總有那么一些細節,你瞪大雙眼拼了命想看清卻依然奈不了何,比如下面這個:
跟得上球嗎?要看清男子羽毛球比賽的細節實在不容易
有時候想盯住飛來飛去的羽毛球,非常吃力,這就是人類肉眼的極限。
你或許會說,好解決啊,用慢速回放功能就行了。
確實可以回放,但慢速回放的前提,是攝像機一開始就捕捉到了這些細節。如今,一些大型體育賽事已經用上了工業高速攝像頭,為的就是在裁判的裁決引發爭議時,可以用慢鏡頭回放來判定結果。
但是,沒有專業的高速攝像頭怎么辦?
像我們用智能手機拍的視頻,記錄下生活中很多美好,隨風飄逝的晚霞,又或者池塘濺起的漣漪,還有孩子們在泳池里潑水嬉戲,如果都能夠放慢了觀看,必將帶來全新的感受。
正因如此,當今年計算機視覺頂會CVPR舉行時,英偉達團隊的一篇能讓手機拍攝的視頻也“高清慢速播放”的論文,在業界引發了很大的反響。

這項被稱為Super SloMo的工作,使用深度神經網絡,對視頻中缺失的幀進行預測并補全,從而生成連續慢速回放的效果。
更贊的是,他們提出的方法,能夠排除原視頻幀當中被遮擋的像素,從而避免在生成的內插中間幀里產生模糊的偽像(artifact)。
值得一提,這篇論文的第一作者,是本碩畢業于西安交通大學、現在馬薩諸塞大學阿默斯特分校讀博四的Huaizu Jiang。第二作者Deqing Sun是英偉達學習與感知研究小組的高級研究員,本科畢業于哈工大,碩士讀的港中文,在布朗大學取得博士學位后,在哈佛Hanspeter Pfister教授的視覺研究小組做過博士后。
感受一下Super-SloMo生成的“慢速回放”效果:
注意,左右兩邊都是Super SloMo生成的視頻。左邊是原始慢速視頻,右邊是將這個結果再放慢4倍的效果,如果不告訴你中間的細節(幀)是神經網絡生成的,你會不會把它們當做真的慢速回放?來源:Huaizu Jiang個人主頁
實際用手機拍攝的畫面是這樣的,對比后,意識到Super SloMo補充多少細節了嗎?
論文作者稱,他們能將30FPS(畫面每秒幀數)的視頻變為480FPS,也即每秒幀數增加了16倍。
根據Super SloMo項目主頁,作者表示,使用他們未經優化的PyTorch代碼,在單個NVIDIA GTX 1080Ti 和 Tesla V100 GPU上,生成7個分辨率為1280*720的中間幀,分別只需要0.97秒和0.79秒。(補充說明:從標準序列30-fps生成240-fps視頻,一般需要在兩個連續幀內插入7個中間幀。)
效果當然稱得上驚艷。然而,令很多人失望的是,論文發布時并沒有將代碼和數據集公開,盡管作者表示可以聯系 Huaizu Jiang 獲取部分原始資料。

僅在論文中提到的數據和示例。來源:Super SloMo論文
今天,有人在 Github 上開源了他對 Super-SloMo 的 PyTorch 實現。這位ID為atplwl的Reddit用戶,在作者提供的adobe24fps數據集上預訓練的模型(下圖中pretrained mine),實現了與論文描述相差無幾的結果。
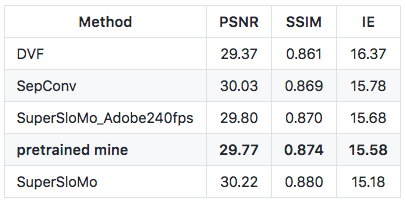
現在,這個預訓練模型,還有相關的代碼、數據集,以及實現條件,都能在GitHub上查到。
自稱新手的atplwl表示,他目前在努力完善這個GitHub庫,接下來預計添加一個PyThon腳本,將視頻轉換為更高的fps視頻,歡迎大家提供建議。
Super SloMo:將任意視頻變為“高清慢速播放”
代碼在手,再看論文——前文已經說過,從已有視頻中生成高清慢速視頻是一件非常有意義的事情。
除了專業的高速攝像機尚未普及到每個人手里,人們用手機拍攝的視頻 (一般為240FPS) 想要放慢的時刻是不可預測的,要實現這一點就不得不用標準幀速率來記錄所有視頻,但這樣做需要的內存過大,對移動設備來說耗電量也花不起。
現在,計算機視覺領域,除了將標準視頻轉換為更高的幀速率之外,還可以使用視頻插值來生成平滑的視圖轉換。在自監督學習中,這也可以作為監控信號來學習未標記視頻的光流。
不過,生成多個中間視頻幀 (intermediate video frame) 是具有挑戰性的,因為幀必須在空間和時間上是連貫的。例如,從30-fps標準序列生成240-fps視頻,需要在兩個連續幀內插入7個中間幀。
成功的解決方案不僅要正確解釋兩個輸入圖像之間的運動(隱式或顯式),還要理解遮擋 (occlusion)。 否則,就可能導致插值幀中產生嚴重的偽像,尤其是在運動邊界附近。
現有方法主要集中于單幀視頻插值,而且已經取得了不錯的進展。然而,這些方法不能直接用于生成任意高幀率視頻。
雖然遞歸地應用單幀視頻插值方法生成多個中間幀是一個很不錯的想法,但這種方法至少有兩個限制:
首先,遞歸單幀插值不能完全并行化,速度較慢,因為有些幀是在其他幀完成后才進行計算的(例如,在七幀插值中,幀2取決于0和4,而幀4取決于0和8)。
其次,它只能生成2i-1個中間幀。因此,不能使用這種方法有效生地生成1008 - fps 24幀的視頻,這需要生成41中間幀。
論文Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation提出了一種高質量的變長多幀插值方法,該方法可以在兩幀之間的任意時間步長進行插值。
其主要思想是,將輸入的兩幅圖像扭曲到特定的時間步長,然后自適應地融合這兩幅扭曲圖像,生成中間圖像,其中的運動解釋和遮擋推理在單個端到端可訓練網絡中建模。
Super SloMo效果展示:注意在放慢過渡區域對偽像的處理。
具體來說,首先使用流量計算CNN來估計兩幅輸入圖像之間的雙向光流,然后線性融合來近似所需的中間光流,從而使輸入圖像發生扭曲。這種近似方法適用于光滑區域,但不適用于運動邊界。
因此,Super SloMo 論文作者使用另一個流量插值CNN來細化流近似并預測軟可見性圖。
通過在融合之前將可見性圖應用于變形圖像,排除了被遮擋像素對內插中間幀的貢獻,從而減少了偽像。

Super SloMo網絡架構
“我們的流計算和插值網絡的參數都獨立于被插值的具體時間步長,是流插值網絡的輸入。因此,我們的方法可以并行生成任意多的中間幀。”作者在論文中寫道。
為了訓練該網絡,團隊從YouTube和手持攝像機收集了240-fps的視頻。總量有1.1K視頻剪輯,由300K個獨立視頻幀組成,典型分辨率為1080×720。
然后,團隊在其他幾個需要不同插值數量的獨立數據集上評估了訓練模型,包括Middlebury 、 UCF101 、慢流(slowflow)數據集和高幀率(high-frame-rate) MPI Sintel。
實驗結果表明,該方法明顯優于所有數據集上的現有方法。 團隊還在KITTI 2012光流基準上評估了無監督(自監督)光流結果,并獲得了比現有最近方法更好的結果。
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100542 -
開源
+關注
關注
3文章
3253瀏覽量
42408 -
pytorch
+關注
關注
2文章
803瀏覽量
13149
原文標題:干掉高速攝像頭!神經網絡生成極慢視頻,突破人類肉眼極限(PyTorch實現)
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論