 基于表格的自然語言理解與生成方向的一系列工作
基于表格的自然語言理解與生成方向的一系列工作
編者按:在我們的生活中,用語音查詢天氣,用必應搜索信息,這些常見的場景都離不開一種應用廣泛的數據存儲方式——表格(table)。如果讓表格更智能一些,將是怎么樣的呢?在這篇文章中,微軟亞洲研究院自然語言計算組將為我們介紹基于表格的自然語言理解與生成方向的一系列工作。
表格(table)是一種應用廣泛的數據存儲方式,被廣泛用于存儲和展示結構化數據。由于表格數據結構清晰、易于維護、時效性強,它們通常是搜索引擎和智能對話系統的重要答案來源。例如,現代搜索引擎(如必應搜索引擎)基于互聯網表格直接生成問題對應的答案;虛擬語音助手(如微軟Cortana、亞馬遜Alexa等)結合表格和自然語言理解技術回答人們的語音請求,例如查詢天氣、預定日程等。
我們將在本文中介紹我們在基于表格的自然語言理解與生成方向的一系列工作,包括檢索(retrieval)、語義解析(semantic parsing)、問題生成(question generation)、對話(conversation)和文本生成(text generation)等五個部分。除了檢索任務,其余四個任務的目標均是在給定表格的基礎上進行自然語言理解和生成:
檢索:從表格集合中找到與輸入問題最相關的表格;
義解析:將自然語言問題轉換成可被機器理解的語義表示(meaning representation,在本文中是SQL語句),在表格中執行該表示即可獲得答案;
問題生成:可看作語義解析的逆過程,能減輕語義解析器對大量標注訓練數據的依賴;
對話:主要用于多輪對話場景的語義解析任務,需有效解決上下文中的省略和指代現象;
文本生成:使用自然語言描述表格中(如給定的一行)的內容。
讓我們用一張圖概括本文接下來所要涉及的內容。
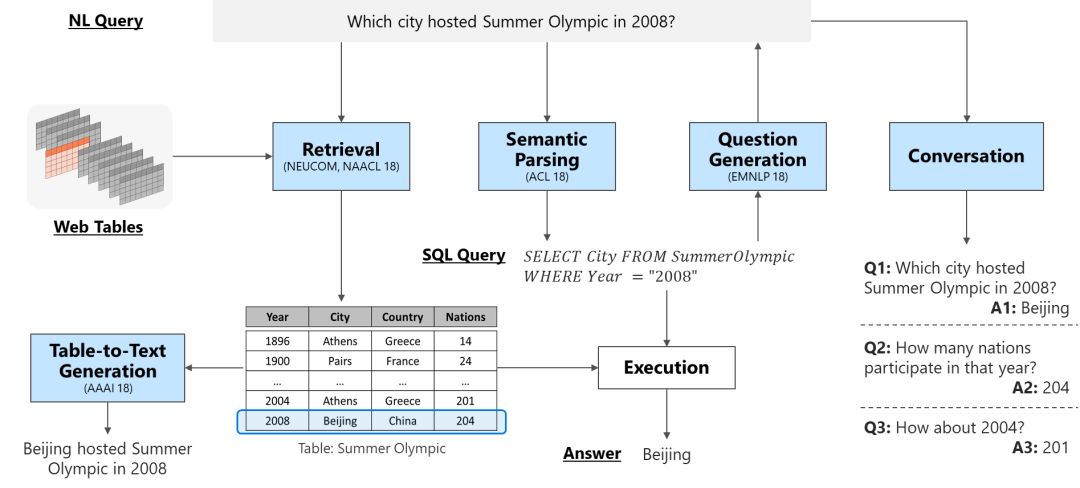
檢索 Retrieval
對于給定的自然語言q和給定的表格全集T={T1, T2, .., Tn},表格檢索任務的目的是從T中找到與q內容最相關的表格,如下圖所示。每個表格通常由三部分構成:表頭/列名(table header)、表格單元(table cell)和表格標題(table caption)。
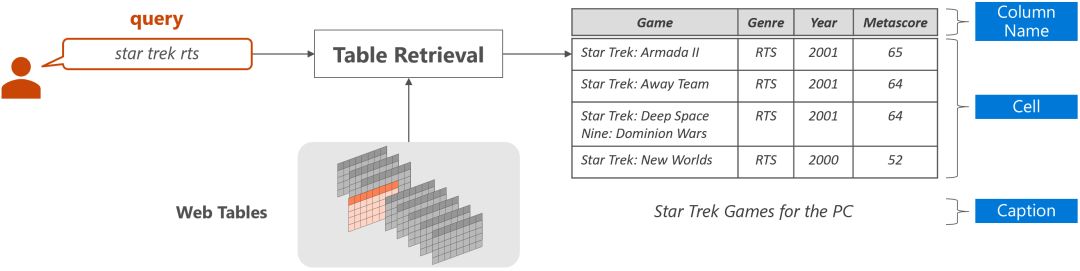
表格檢索的關鍵在于衡量自然語言問題和表格之間的語義相關程度。一個基本的做法是把表格看做文檔,使用文本檢索中常用的字符串相似度計算方法(如BM25)計算自然語言問題和表格之間的相似度。也有學者使用更多樣的特征,如表格的行數、列數、問題和表格標題的匹配程度等。
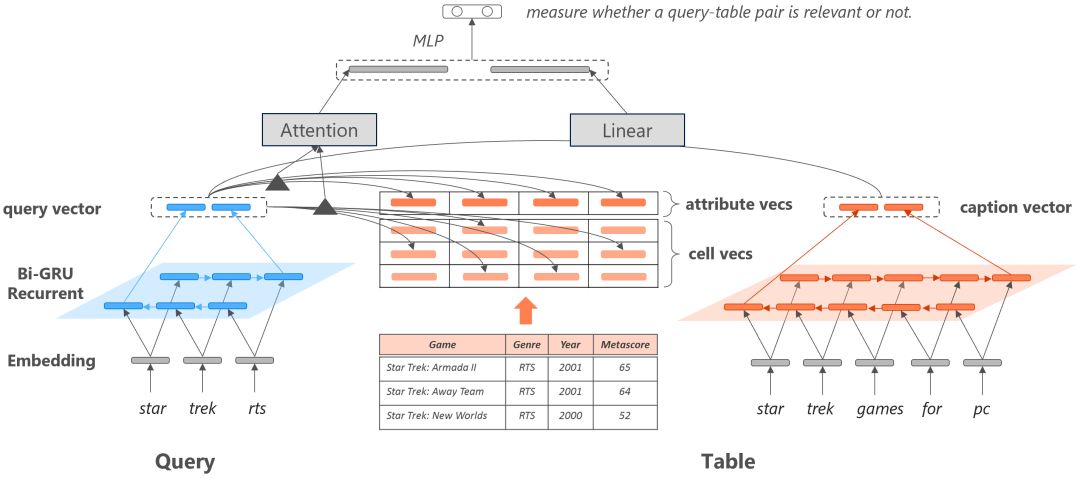
為了更好地融入表格的結構信息,我們提出了一個基于神經網絡的表格檢索模型,在語義向量空間內分別計算問題和表頭、問題和列名、問題和表格單元的匹配程度,如下圖所示。由于問題和表格標題都是詞序列,我們均使用雙向GRU把二者分別表示為向量表示,最終使用線性層計算二者的相關度。由于表頭和表格單元不存在序列關系,任意交換表格的兩列或兩行應保證具有相同的語義表示,所以我們使用Attention計算問題和表頭以及問題和表格單元的相關度。
由于目前表格檢索的公開數據集有限,因此我們構建了一個包含21,113個自然語言問題和273,816個表格的數據集。在該數據集上,我們對比了基于BM25的系統、基于手工定義特征的系統以及基于神經網絡的系統,結果如下表所示。
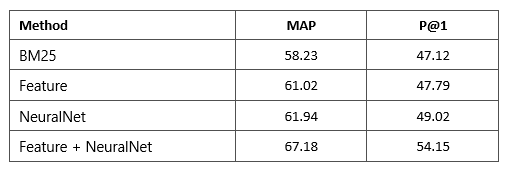
可以看出基于神經網絡的算法與手工設計的特征性能相近,二者相結合可以進一步提高系統的性能。
更多細節請參照論文:
Yibo Sun, Zhao Yan, Duyu Tang, Nan Duan, Bing Qin.Content-Based Table Retrieval for Web Queries. 2018. Neurocomputing.
語義解析 Semantic Parsing
給定一張網絡表格,或一個關系數據庫表,或一個關于表的自然語言問句,語義解析的輸出是機器可以理解并執行的規范語義表示(formal meaning representation),在本小節我們使用SQL語句作為規范語義表示,執行該SQL語句即可從表中得到問題的答案。
目前,生成任務比較流行的方法是基于序列到序列(sequence to sequence)架構的神經模型,一般由一個編碼器(encoder)和一個解碼器(decoder)組成。編碼器負責建模句子表示,解碼器則根據編碼器得到的問句表示來逐個從詞表中挑選出一個個符號進行生成。
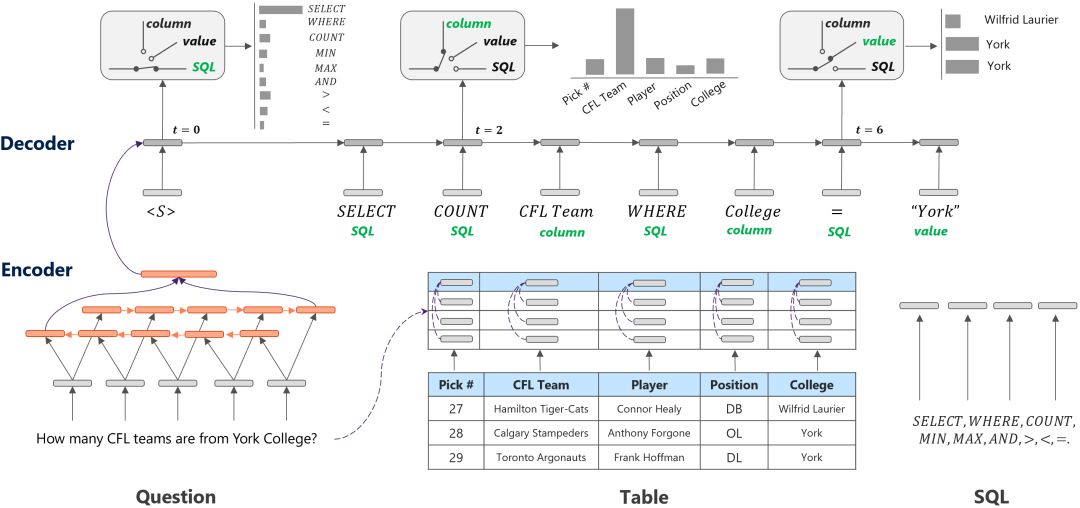
然而, SQL語句遵循一定的語法規則,一條SQL查詢語句通常由3種類型的元素組成,即SQL關鍵詞(如SELECT, WHERE, >, < 等)、表格的列名和WHERE語句中的條件值(通常為數字或表格單元)。因此,我們在解碼器端融入SQL的語法信息,具體由一個門單元和三個頻道組成。門單元負責判斷該時刻即將輸出符號的類型,三個頻道分別為Column、value、SQL頻道,在每個頻道中分別預測表中列名稱、表中單元格名稱和SQL語法關鍵字。該算法在WikiSQL數據集上性能優于多個強對比算法。
更多細節可以參考論文:
Yibo Sun, Duyu Tang, Nan Duan, Jianshu Ji, Guihong Cao, Xiaocheng Feng, Bing Qin, Ting Liu and Ming Zhou. Semantic Parsing with Syntax- and Table-Aware SQL Generation. 2018. ACL.
問題生成 Question Generation
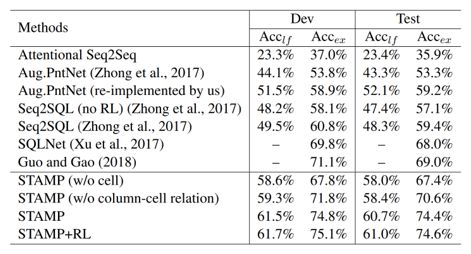
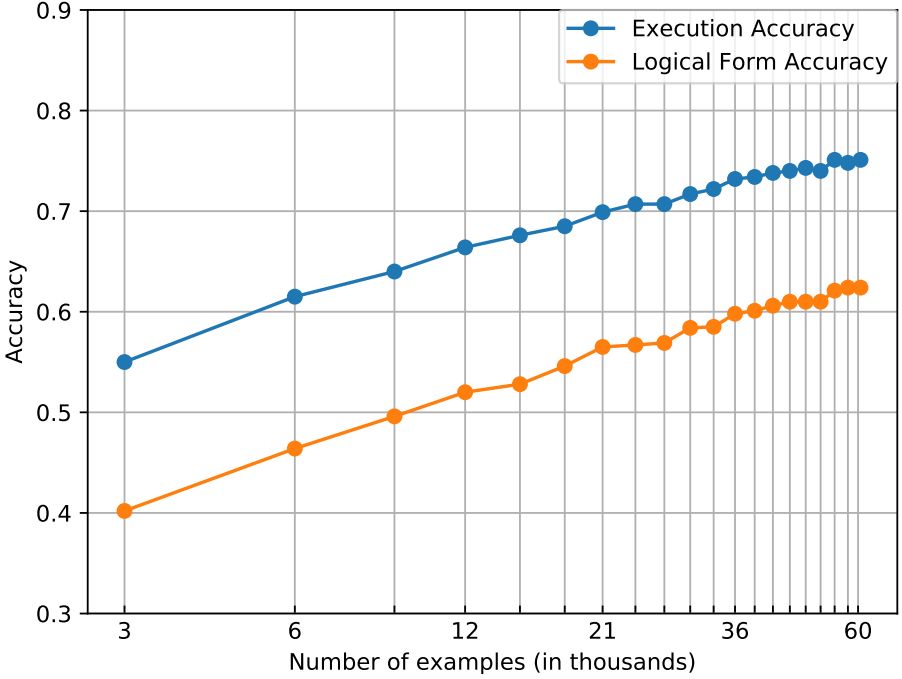
統計機器學習算法的性能通常受有指導訓練數據量的影響。例如,我們使用上一小節提出的語義解析算法,在有不同指導訓練數據的條件下觀察模型的性能(這里的有指導訓練數據指的是人工標注的“問題-SQL”對)。下表中x軸是log scale的訓練數據量,可以發現語義解析的準確率與訓練數據量之間存在Log的關系。
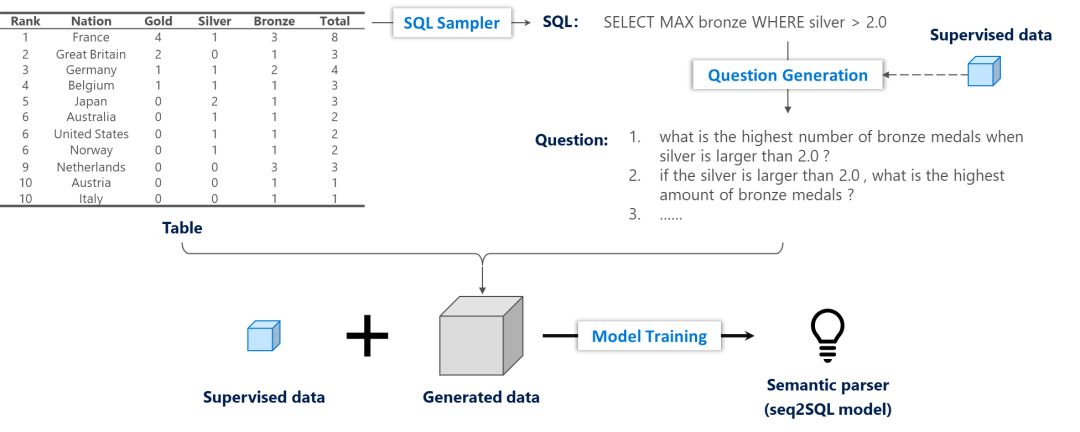
基于上述觀察,我們希望使用少量的有指導訓練數據,達到同樣的語義分析準確率。為此,我們提出了一個基于問題生成的語義分析訓練框架,如下圖所示。給定一個表格,我們首先使用一個基于規則的SQL采樣器生成SQL語句,隨后用一個在小規模有指導數據上訓練的問題生成模型生成多個高置信度的問題,將新生成的數據與小規模的有指導數據結合,共同訓練語義分析模型。另外,問題生成模型是基于Seq2Seq模型,為了增加生成問題的多樣性我們在解碼器端加入了隱含變量。
更多細節可以參考論文:
Daya Guo, Yibo Sun, Duyu Tang, Nan Duan, Jian Yin, Hong Chi, James Cao, Peng Chen and Ming Zhou. Question Generation from SQL Queries Improves Neural Semantic Parsing. 2018. EMNLP.
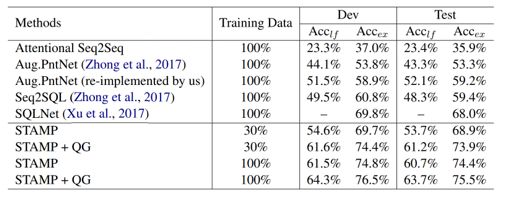
我們在WikiSQL數據集上進行實驗,使用上一章中所介紹的算法(STAMP)作為基本模型。從下表可以看出,融合問題生成模型的訓練算法可以在30%訓練數據的條件下達到傳統訓練算法100%訓練數據的性能。使用該算法,在100%訓練數據的條件下會進一步提升模型的性能。
對話 Conversational Semantic Parsing
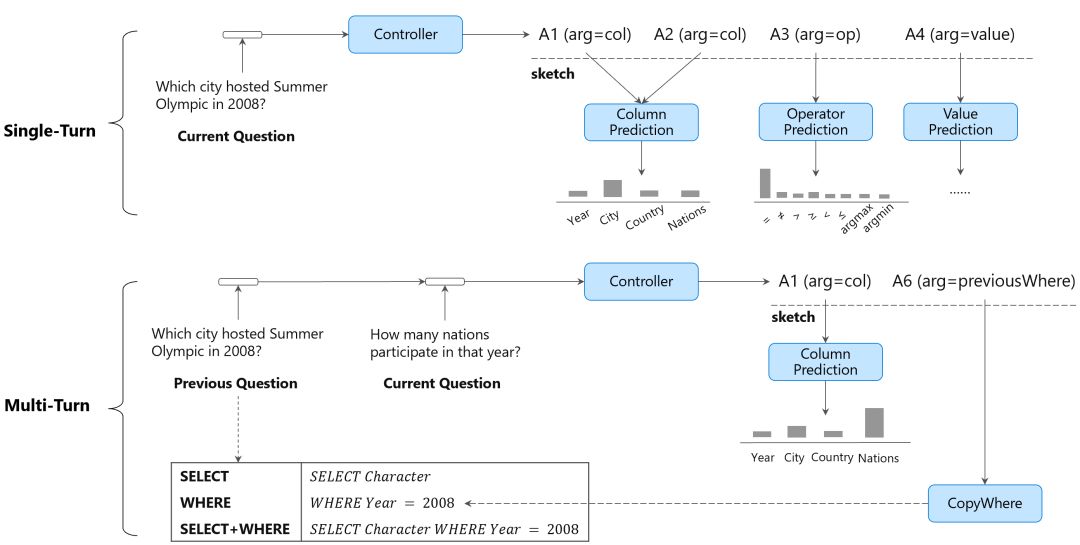
前面我們介紹的語義解析算法針對的都是單輪問答場景,即用戶針對一個表格每次問一個獨立的問題。而在對話場景下,人們會在前一個問題的基礎上繼續提問,通常人們會使用指代或省略使對話更加簡潔和連貫。例如,在下圖的例子中,第2個問句中的”that year”指代第一個問句中提及的年份;第3個問題更是直接省略了問題的意圖。

針對多輪對話場景下的語義分析,我們以Sequence-to-Action的形式生成問題的語義表示,在該模式下生成一個語義表示等價于一個動作序列,Sequence-to-Action在單輪和多輪語義分析任務中均被驗證是非常有效的方法。
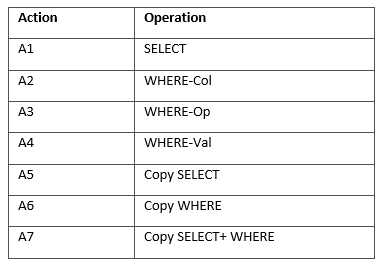
具體地,我們在Mohit Iyyer等人發表在ACL 2017上的研究Search-based Neural Structured Learning for Sequential Question Answering的基礎上定義了如下表的動作集合,作為我們Sequence-to-Action模型的語法基礎。A1-A4的目的是根據當前語句的內容預測SELECT語句中的列名、WHERE語句中的列名、WHERE語句中的操作符(如=, >, <)和WHERE語句中的條件值;A5-A7的目的是從上一句的歷史語義表示中復制部分內容到當前語句的語義表示中。
我們以下圖為例介紹模型的工作原理。輸入歷史問題和當前問題,該模型首先使用Controller模塊預測當前問句的動作序列骨架(即未實例化的動作序列),隨后使用特定的模型(如基于Attention的column prediction模塊)去實例化骨架中的每個單元。當模型預測A5-A7(如下圖中所展示的A6),模型實現了復制歷史語義表示的功能。
更多細節請參考論文:
Yibo Sun, Duyu Tang, Nan Duan, Jingjing Xu, Xiaocheng Feng, Bing Qin. Knowledge-Aware Conversational Semantic Parsing Over Web Tables. 2018. Arxiv.
自然語言生成Table-to-Text Generation
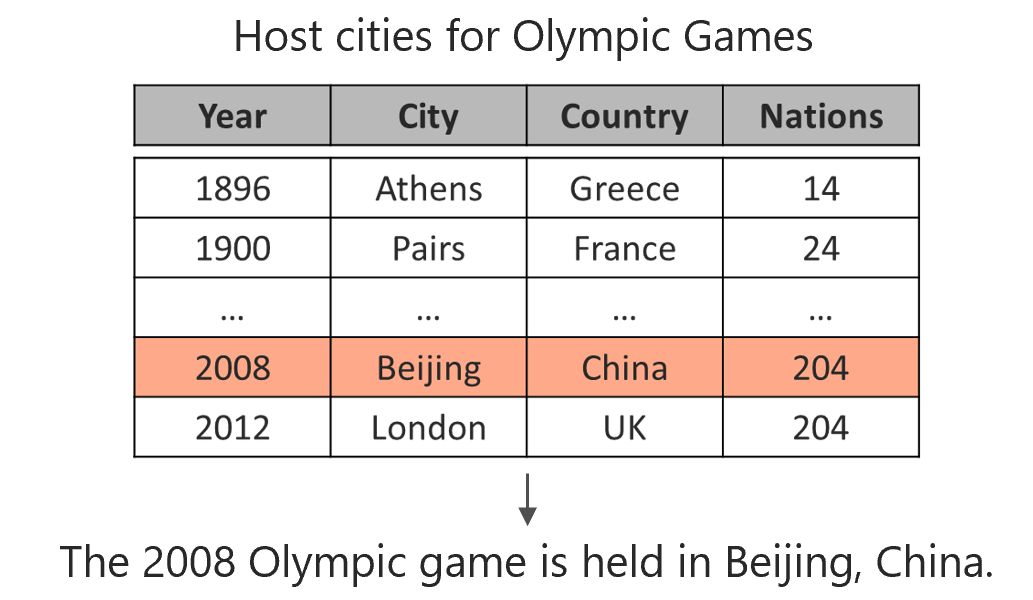
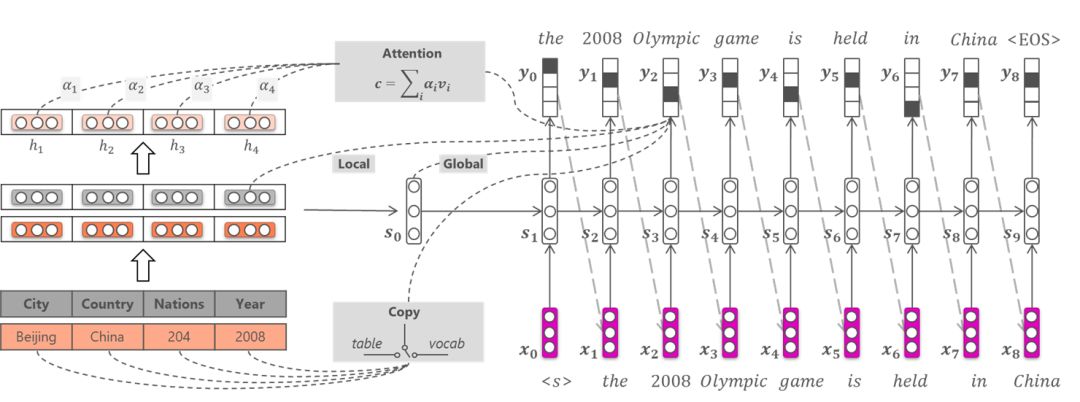
很多場景都需要用自然語言形式呈現答案。因此我們基于表格的文本生成工作,目的是用自然語言描述表格中(如給定的一行)的內容。以下圖為例,給定表格中的一行,輸出一句完整的描述內容。
我們的模型基于Sequence-to-Sequence框架,如下圖所示。為了考慮表格的結構性(如打亂表格的各列不改變其表示),我們在編碼器模塊沒有使用序列化的形式去建模各個列的表示;為了有效從表格中復制低頻詞到輸出序列,我們設計了基于表格結構的復制機制。
具體內容請參考論文:
Junwei Bao, Duyu Tang, Nan Duan, Zhao Yan, Yuanhua Lv, Ming Zhou, Tiejun Zhao. Table-to-Text: Describing Table Region with Natural Language. 2018. AAAI.
本文介紹了我們在基于表格的自然語言理解與生成相關的5項工作。目前,與表格相關的自然語言處理研究剛剛起步,方法尚未成熟,對應的標注數據集也相對有限,我們希望與業界研究者們一起共同探索新的方法和模型,推動該領域的進一步發展。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100539 -
數據存儲
+關注
關注
5文章
963瀏覽量
50858 -
自然語言
+關注
關注
1文章
287瀏覽量
13332
原文標題:你已經是個成熟的表格,該學會NLP了
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論