") 北大語言計算與機(jī)器學(xué)習(xí)研究組推出一套全新中文分詞工具包pkuseg
北大語言計算與機(jī)器學(xué)習(xí)研究組推出一套全新中文分詞工具包pkuseg
日前,北京大學(xué)語言計算與機(jī)器學(xué)習(xí)研究組研制推出一套全新中文分詞工具包 pkuseg,這一工具包有如下三個特點(diǎn):
高分詞準(zhǔn)確率。相比于其他的分詞工具包,當(dāng)使用相同的訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù),pkuseg 可以取得更高的分詞準(zhǔn)確率。
多領(lǐng)域分詞。不同于以往的通用中文分詞工具,此工具包同時致力于為不同領(lǐng)域的數(shù)據(jù)提供個性化的預(yù)訓(xùn)練模型。根據(jù)待分詞文本的領(lǐng)域特點(diǎn),用戶可以自由地選擇不同的模型。而其他現(xiàn)有分詞工具包,一般僅提供通用領(lǐng)域模型。
支持用戶自訓(xùn)練模型。支持用戶使用全新的標(biāo)注數(shù)據(jù)進(jìn)行訓(xùn)練。
各項性能對比如下:
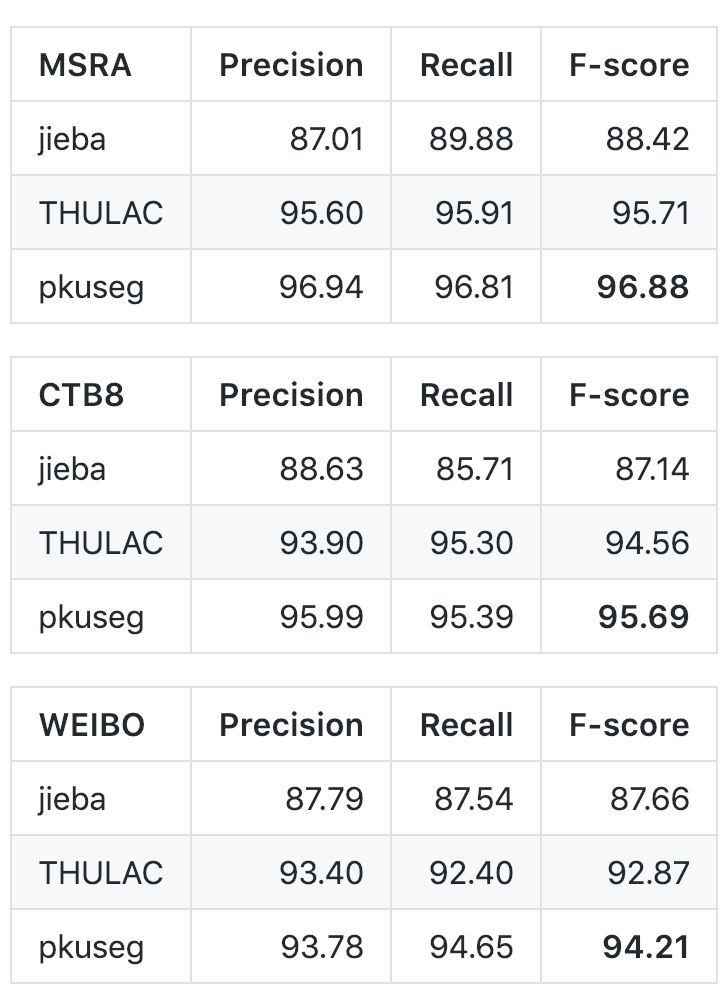
與 jieba、THULAC 等國內(nèi)代表分詞工具包進(jìn)行性能比較:
考慮到 jieba 分詞和 THULAC 工具包等并沒有提供細(xì)領(lǐng)域的預(yù)訓(xùn)練模型,為了便于比較,開發(fā)團(tuán)隊重新使用它們提供的訓(xùn)練接口在細(xì)領(lǐng)域的數(shù)據(jù)集上進(jìn)行訓(xùn)練,用訓(xùn)練得到的模型進(jìn)行中文分詞。他們選擇 Linux 作為測試環(huán)境,在新聞數(shù)據(jù)(MSRA)、混合型文本(CTB8)、網(wǎng)絡(luò)文本(WEIBO)數(shù)據(jù)上對不同工具包進(jìn)行了準(zhǔn)確率測試。在此過程中,他們使用第二屆國際漢語分詞評測比賽提供的分詞評價腳本,其中 MSRA 與 WEIBO 使用標(biāo)準(zhǔn)訓(xùn)練集測試集劃分,CTB8 采用隨機(jī)劃分。對于不同的分詞工具包,訓(xùn)練測試數(shù)據(jù)的劃分都是一致的;即所有的分詞工具包都在相同的訓(xùn)練集上訓(xùn)練,在相同的測試集上測試。
以下是在不同數(shù)據(jù)集上的對比結(jié)果:
同時,為了比較細(xì)領(lǐng)域分詞的優(yōu)勢,開發(fā)團(tuán)隊比較了他們的方法和通用分詞模型的效果對比。其中 jieba 和 THULAC 均使用了軟件包提供的、默認(rèn)的分詞模型:
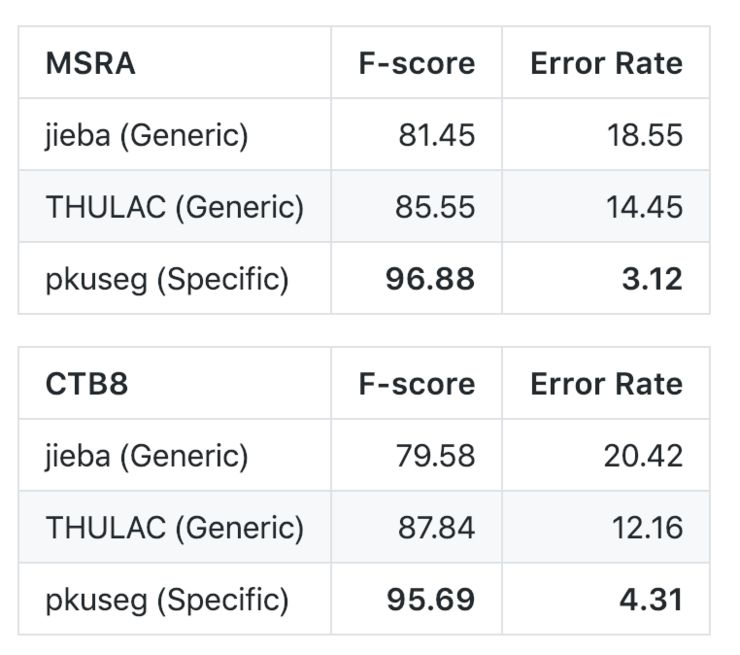
從結(jié)果上來看,當(dāng)用戶了解待分詞文本的領(lǐng)域時,細(xì)領(lǐng)域分詞可以取得更好的效果。然而 jieba 和 THULAC 等分詞工具包僅提供了通用領(lǐng)域模型。
目前,該工具包已經(jīng)在 GitHub 開源,編譯、安裝和使用說明如下。
編譯和安裝
pip install pkuseg之后通過 import pkuseg 來引用
2. 從 github 下載(需要下載模型文件,見預(yù)訓(xùn)練模型)
將 pkuseg 文件放到目錄下,通過 import pkuseg 使用模型需要下載或自己訓(xùn)練。
使用方式
1. 代碼示例
代碼示例1 使用默認(rèn)模型及默認(rèn)詞典分詞import pkusegseg = pkuseg.pkuseg() #以默認(rèn)配置加載模型text = seg.cut('我愛北京***') #進(jìn)行分詞print(text)
代碼示例2 設(shè)置用戶自定義詞典import pkuseglexicon = ['北京大學(xué)', '北京***'] #希望分詞時用戶詞典中的詞固定不分開seg = pkuseg.pkuseg(user_dict=lexicon) #加載模型,給定用戶詞典text = seg.cut('我愛北京***') #進(jìn)行分詞print(text)
代碼示例3import pkusegseg = pkuseg.pkuseg(model_name='./ctb8') #假設(shè)用戶已經(jīng)下載好了ctb8的模型并放在了'./ctb8'目錄下,通過設(shè)置model_name加載該模型text = seg.cut('我愛北京***') #進(jìn)行分詞print(text)
代碼示例4import pkusegpkuseg.test('input.txt', 'output.txt', nthread=20) #對input.txt的文件分詞輸出到output.txt中,使用默認(rèn)模型和詞典,開20個進(jìn)程
代碼示例5import pkusegpkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', './models', nthread=20) #訓(xùn)練文件為'msr_training.utf8',測試文件為'msr_test_gold.utf8',模型存到'./models'目錄下,開20個進(jìn)程訓(xùn)練模型
2. 參數(shù)說明
pkuseg.pkuseg(model_name='ctb8', user_dict=[])model_name 模型路徑。默認(rèn)是'ctb8'表示我們預(yù)訓(xùn)練好的模型(僅對pip下載的用戶)。用戶可以填自己下載或訓(xùn)練的模型所在的路徑如model_name='./models'。user_dict 設(shè)置用戶詞典。默認(rèn)不使用詞典。填'safe_lexicon'表示我們提供的一個中文詞典(僅pip)。用戶可以傳入一個包含若干自定義單詞的迭代器。
pkuseg.test(readFile, outputFile, model_name='ctb8', user_dict=[], nthread=10)readFile 輸入文件路徑outputFile 輸出文件路徑model_name 同pkuseg.pkuseguser_dict 同pkuseg.pkusegnthread 測試時開的進(jìn)程數(shù)
pkuseg.train(trainFile, testFile, savedir, nthread=10)trainFile 訓(xùn)練文件路徑testFile 測試文件路徑savedir 訓(xùn)練模型的保存路徑nthread 訓(xùn)練時開的進(jìn)程數(shù)
預(yù)訓(xùn)練模型
分詞模式下,用戶需要加載預(yù)訓(xùn)練好的模型。開發(fā)團(tuán)隊提供了三種在不同類型數(shù)據(jù)上訓(xùn)練得到的模型,根據(jù)具體需要,用戶可以選擇不同的預(yù)訓(xùn)練模型。以下是對預(yù)訓(xùn)練模型的說明:
MSRA: 在MSRA(新聞?wù)Z料)上訓(xùn)練的模型。新版本代碼采用的是此模型。
下載地址:https://pan.baidu.com/s/1twci0QVBeWXUg06dK47tiA
CTB8: 在CTB8(新聞文本及網(wǎng)絡(luò)文本的混合型語料)上訓(xùn)練的模型。
下載地址:https://pan.baidu.com/s/1DCjDOxB0HD2NmP9w1jm8MA
WEIBO: 在微博(網(wǎng)絡(luò)文本語料)上訓(xùn)練的模型。
下載地址:https://pan.baidu.com/s/1QHoK2ahpZnNmX6X7Y9iCgQ
開發(fā)團(tuán)隊預(yù)訓(xùn)練好其它分詞軟件的模型可以在如下地址下載:
jieba: 待更新
THULAC: 在 MSRA、CTB8、WEIBO、PKU 語料上的預(yù)訓(xùn)練模型,下載地址:https://pan.baidu.com/s/11L95ZZtRJdpMYEHNUtPWXA,提取碼:iv82
其中 jieba 的默認(rèn)模型為統(tǒng)計模型,主要基于訓(xùn)練數(shù)據(jù)上的詞頻信息,開發(fā)團(tuán)隊在不同訓(xùn)練集上重新統(tǒng)計了詞頻信息。對于 THULAC,他們使用其提供的接口進(jìn)行訓(xùn)練(C++版本),得到了在不同領(lǐng)域的預(yù)訓(xùn)練模型。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8377瀏覽量
132405 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24641
原文標(biāo)題:學(xué)界 | 北大開源中文分詞工具包 pkuseg
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學(xué)會】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
恩智浦車規(guī)級深度學(xué)習(xí)工具包使新一代汽車應(yīng)用性能提高30倍
Facebook推出ReAgent AI強(qiáng)化學(xué)習(xí)工具包
PIC 語言工具包問題
Python人工智能學(xué)習(xí)工具包+入門與實(shí)踐資料集錦
目前常用的自然語言處理開源項目/開發(fā)包大匯總
求LabVIEW2014 機(jī)器學(xué)習(xí)工具包
中文分詞研究難點(diǎn)-詞語切分和語言規(guī)范
愛特梅爾推出全新的汽車應(yīng)用開發(fā)工具包ATAPMxx
Google Kubernetes機(jī)器學(xué)習(xí)工具包Kubeflow發(fā)布0.1版
Python網(wǎng)頁爬蟲,文本處理,科學(xué)計算,機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘工具集
北大開源了一個中文分詞工具包,名為——PKUSeg
ToolKit是一套應(yīng)用于嵌入式系統(tǒng)的通用工具包
搭建一套優(yōu)秀的嵌入式軟件框架必備的通用工具包
Microchip 推出 MPLAB? 機(jī)器學(xué)習(xí)開發(fā)工具包,助力開發(fā)人員輕松將機(jī)器學(xué)習(xí)集成到 MCU 和 MPU中
Microchip(微芯)推出MPLAB機(jī)器學(xué)習(xí)開發(fā)工具包






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論