 scikit-learn K近鄰法類庫使用的經驗總結
scikit-learn K近鄰法類庫使用的經驗總結
本文對scikit-learn中KNN相關的類庫使用做了一個總結,主要關注于類庫調參時的一個經驗總結,且該文非常詳細地介紹了類的參數含義,這是小編見過最詳細的KNN類庫參數介紹 。
目錄
scikit-learn 中KNN相關的類庫概述
K近鄰法和限定半徑最近鄰法類庫參數小結
使用KNeighborsClassifier做分類的實例
1. scikit-learn中KNN相關的類庫概述
在scikit-learn 中,與近鄰法這一大類相關的類庫都在sklearn.neighbors包之中。KNN分類樹的類是KNeighborsClassifier,KNN回歸樹的類是KNeighborsRegressor。除此之外,還有KNN的擴展,即限定半徑最近鄰分類樹的類RadiusNeighborsClassifier和限定半徑最近鄰回歸樹的類RadiusNeighborsRegressor, 以及最近質心分類算法NearestCentroid。
在這些算法中,KNN分類和回歸的類參數完全一樣。限定半徑最近鄰法分類和回歸的類的主要參數也和KNN基本一樣。
比較特別是的最近質心分類算法,由于它是直接選擇最近質心來分類,所以僅有兩個參數,距離度量和特征選擇距離閾值,比較簡單,因此后面就不再專門講述最近質心分類算法的參數。
另外幾個在sklearn.neighbors包中但不是做分類回歸預測的類也值得關注。kneighbors_graph類返回用KNN時和每個樣本最近的K個訓練集樣本的位置。radius_neighbors_graph返回用限定半徑最近鄰法時和每個樣本在限定半徑內的訓練集樣本的位置。NearestNeighbors是個大雜燴,它即可以返回用KNN時和每個樣本最近的K個訓練集樣本的位置,也可以返回用限定半徑最近鄰法時和每個樣本最近的訓練集樣本的位置,常常用在聚類模型中。
2.K近鄰法和限定半徑最近鄰法類庫參數小結
本節對K近鄰法和限定半徑最近鄰法類庫參數做一個總結。包括KNN分類樹的類KNeighborsClassifier,KNN回歸樹的類KNeighborsRegressor, 限定半徑最近鄰分類樹的類RadiusNeighborsClassifier和限定半徑最近鄰回歸樹的類RadiusNeighborsRegressor。這些類的重要參數基本相同,因此我們放到一起講:




3. 使用KNeighborsClassifier做分類的實例
完整代碼見github:
https://github.com/ljpzzz/machinelearning/blob/master/classic-machine-learning/knn_classifier.ipynb
3.1 生成隨機數據
首先,我們生成我們分類的數據,代碼如下:
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import make_classification # X為樣本特征,Y為樣本類別輸出, 共1000個樣本,每個樣本2個特征,輸出有3個類別,沒有冗余特征,每個類別一個簇 X, Y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, n_classes=3)plt.scatter(X[:, 0], X[:, 1], marker='o', c=Y)plt.show()
先看看我們生成的數據圖如下。由于是隨機生成,如果你也跑這段代碼,生成的隨機數據分布會不一樣。下面是我某次跑出的原始數據圖。
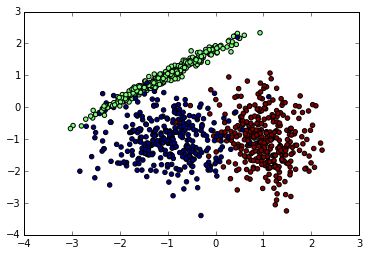
接著我們用KNN來擬合模型,我們選擇K=15,權重為距離遠近。代碼如下:
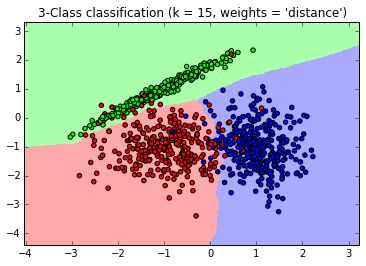
from matplotlib.colors import ListedColormap cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF']) #確認訓練集的邊界 x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 #生成隨機數據來做測試集然后預測 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # 畫出測試集數據 Z = Z.reshape(xx.shape)plt.figure()plt.pcolormesh(xx, yy, Z, cmap=cmap_light) # 也畫出所有的訓練集數據 plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=cmap_bold)plt.xlim(xx.min(), xx.max())plt.ylim(yy.min(), yy.max())plt.title("3-Class classification (k = 15, weights = 'distance')" )生成的圖如下,可以看到大多數數據擬合不錯,僅有少量的異常點不在范圍內。
-
函數
+關注
關注
3文章
4304瀏覽量
62427 -
KNN
+關注
關注
0文章
22瀏覽量
10796 -
分類算法
+關注
關注
0文章
29瀏覽量
9930
原文標題:scikit-learn K近鄰法類庫使用小結
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Python機器學習庫談Scikit-learn技術
在PyODPS DataFrame自定義函數中使用pandas、scipy和scikit-learn

Python機器學習庫和深度學習庫總結

基于Python的scikit-learn編程實例
詳細解析scikit-learn進行文本分類






 工商網監
工商網監
評論