 一些關于機器學習工具在學習過程中所犯錯誤的問題
一些關于機器學習工具在學習過程中所犯錯誤的問題
在學習過程中,機器學習會出錯。運用機器學習的人需要預見到這一點——并且要注意不要因IT和業務的人為錯誤而使事情變得更糟。
一般來說,學習的過程通常意味著先犯錯誤以及選擇錯誤的道路,然后再想明白如何在將來避免這些陷阱。機器學習也不例外。
當你在你的企業中運用機器學習時,要小心:一些技術營銷可能會告訴你機器學習的過程是又快又好的,但這是一種對技術的不切實際的期望。事實是,機器學習過程中必定會出現錯誤。而且至少在相當一段時間內,這些錯誤會被編碼到業務流程中。結果就是,這些錯誤現在大規模地發生,并且通常不受人的直接控制。
SPR咨詢公司的首席數據科學家雷·約翰遜說:“只有盲目冒進的渴望而缺乏應有的務實和勤奮會導致機器學習帶來的好處幾乎淪為無用。”
檢測機器學習過程中的錯誤并處理它們將有助于你在技術方面取得更大成功,以及滿足你對機器學習的期望。
以下是一些關于機器學習工具在學習過程中所犯錯誤的問題,這些問題可能會使錯誤數量增加并延長犯錯的時間——機器學習工具自身可能永遠無法識別并糾正這些錯誤教訓。
缺乏對問題的業務理解而使機器學習失敗
一些使用機器學習模型的數據工作者并不真正理解機器學習正在試圖解決的業務問題,而這可能會給流程引入錯誤。
金融服務網站LendingTree的副總裁兼戰略分析主管Akshay Tandon表示,當他的團隊使用機器學習工具時,他鼓勵它從假設聲明開始。該聲明應該詢問你要解決的問題是什么,以及你要構建哪些模型來解決該問題。
Tandon說,從統計學方面來看,今天可用的機器學習工具都非常強大。這樣一來正確地使用它就成為更重大的責任,因為這些強大的工具,如果不仔細使用,可能導致錯誤決定而影響深遠。如果數據分析團隊不小心,他們最終得到的模型可能會不符合團隊正在嘗試學習的特定數據。快速惡化的結果,他說,就是事情可能很快就會出現重大事故。
此外,許多商業用戶都不明白,從投入生產的那一刻起,模型的質量就會有一定程度的下降,Tandon說。認識到這一點后,就像汽車或任何其他機器一樣,用戶需要持續不斷地監控它并注意它如何對決策產生影響。
數據質量差可能導致機器學習錯誤
垃圾進,垃圾出。如果數據質量不達標,機器學習將受到消極影響。數據質量差是數據管理員最憂心的問題之一。不管數據科學家和其他從事信息工作的專業人員原本的意圖有多好,數據質量差都可能危及大數據分析工作并使他們的努力毀于一旦。它完全可以使機器學習模式一片混亂。
各界組織機構經常高估機器學習算法的韌性,卻低估不良數據的影響。約翰遜說,糟糕的數據質量會導致糟糕的數據結果,進而導致組織做出不明智的商業決策。這些決策的結果將損害業務績效,并使未來的計劃難以獲得支持。
根據過去和現在的經驗,你可以從機器學習得出的結果中發現低質量數據的存在,因為這些數據結果看起來就是講不通。
約翰遜說,探索性數據分析(EDA)是一個解決這一問題的主動方法。EDA可以識別基本數據質量問題,例如野值,空缺值和不一致的域值。您還可以使用統計抽樣等技術來確定是否有足夠的數據點實例來充分反映總體分布,并定義有關數據質量補救的規則和策略。
對機器學習的不正確使用
咨詢公司Cambridge Consultants的專家級機器學習工程師Sally Epstein說:“我們仍然從公司看到的最常見的問題是,公司渴望運用機器學習沒有其他原因,僅僅因為時髦而已。” 但她說,必須正確地使用該工具才能取得成功。而傳統的工程方法可能更快地提供解決方案并且成本低很多。
約翰遜說,當機器學習可能不是解決問題的最佳選擇而且用例并沒有被完全理解時,可能會導致解決錯誤的問題。
此外,解決錯誤的問題將導致失去機會,因為組織正在努力將其用例定制為特定的,不合適的模型。這包括為了獲得成果而在人員和基礎設施方面部署的資源浪費,但這個成果本可以用更簡單的替代方法來得到。
為避免對機器學習的錯誤使用,請考慮所需的業務成果,問題的復雜性,數據量和屬性數量。約翰遜說,相對簡單的問題,如分類,聚類和使用少量屬性的少量數據的關聯規則,可以通過視覺化或統計分析來處理。在這些情況下,采用機器學習可能需要更多的時間和資源。
當數據量變得龐大時,機器學習可能更合適。但是,先通過了一個機器學習練習,然后才發現業務結果尚未明確定義并導致解決了錯的問題的情況并不罕見。
機器學習模型可能存在偏差
使用質量差的數據集可能會導致誤導性的結論。它不僅會引入不準確性和缺失數據,還會引入偏差。人類肯定是可能會有偏見的,所以由人們創造或啟發得出的模型也可能包含偏見。
Epstein說,每種機器學習算法對不平衡的類或分布都有不同的敏感性。如果沒有解決這些問題,你最終可能會得到的結果會是,比如說,對膚色有依賴性的面部識別工具,或具有性別偏見的模型。事實上,這種情況已經多次在商業服務中發生過了。
結論的準確性——無論是經由算法還是人類得出的——都取決于被處理信息的廣度和質量。咨詢公司Deloitte咨詢分析服務領域的負責人Vic Katyal表示,組織和個人面臨的算法偏見帶來的的財務,法律和聲譽風險就是為什么任何使用機器學習的公司應該將道德規范作為組織要求的一個例子。
Katyal說,算法偏差的跡象已經被充分記錄在了信用評分,教育課程,招聘和刑事司法判決等公共領域。收集,策劃或應用不當的數據甚至可能在最精心設計和周密計劃的機器學習應用程序中引入偏差。
他說,固有偏見的機器學習系統可能會使部分客戶群體或社會利益相關者處于劣勢,并可能造成或延續不公平的結果。
咨詢公司麥肯錫在2017年的一份報告中指出,算法偏差是機器學習的最大風險之一,因為它會影響機器學習的實際目的。該公司表示,這是一個經常被忽視的缺陷,可以引發代價高昂的錯誤,如果不加以控制,可能會使項目和組織往完全錯誤的方向發展。
麥肯錫表示,如果在一開始就能有效地解決這個問題,將會獲得豐厚回報,從而最大限度地實現機器學習的真正潛力。
資源不足,無法做好機器學習
在啟動機器學習計劃時,一個組織很容易低估自身在人員和基礎架構方面所需的資源。機器學習可能對基礎設施有大量的要求,尤其是在圖像,視頻和音頻處理方面。
約翰遜說,如果沒有所需的處理能力,而又要及時開發基于機器學習的解決方案,往好了說是困難的,往壞了說壓根就是不可能的。
還存在部署和消費問題。如果沒有先決條件基礎設施來允許其部署和用戶對結果的消費,那么開發機器學習解決方案有什么用呢?
部署可擴展的基礎架構以支持機器學習可能既昂貴又難以維護。然而,有幾種云服務可以提供可擴展的機器學習平臺,可以按需配置。約翰遜說,云方法可以大規模地進行機器學習,而不會受到物理硬件采集,配置和部署的束縛。
一些組織希望將他們的基礎設施內部化。如果是這種情況,云服務可以作為踏腳石和教育體驗,從而這些組織可以在進行大量投資之前從基礎架構的角度了解機器學習需要什么。
從人員角度來看,缺乏知識淵博的資源,如數據科學家和機器學習工程師,可能會使機器學習的開發和部署脫離正軌。擁有了解機器學習概念及其應用和解讀的人才,以確定是否實現了特定的業務成果,這一點至關重要。
約翰遜說,不能低估擁有豐富的機器學習技能的重要性。知識淵博的人可以幫助識別數據質量問題,確保正確使用和部署機器學習工具,并幫助建立最佳實踐和管理策略。
糟糕的計劃和管理的缺乏會破壞機器學習
對機器學習的努力可能會以熱情開始,但隨后失去動力并陷入停頓。這表明計劃不周,缺乏管理。
如果不采取適當的指導方針和限制,機器學習工作將無限期地繼續存在,可能導致巨大的資源支出而不會取得任何好處,約翰遜說。
組織們需要記住,機器學習是一個迭代過程,模型的修改可能會隨著時間的推移而不斷發生,以支持不斷變化的需求。結果就是,從事機器學習的人可能對完成工作缺乏興趣,這可能導致不良結果。項目發起人可能會轉向其他工作,機器學習工作最終會停滯不前。
約翰遜說,需要定期監控機器學習工作,以確保事情順利進行。如果進度開始放緩,可能是時候休息一下并重新審視這個項目了。
-
模型
+關注
關注
1文章
3172瀏覽量
48713 -
機器學習
+關注
關注
66文章
8377瀏覽量
132407
原文標題:機器學習失敗的 6 種原因,你中招了嗎?
文章出處:【微信號:mcuworld,微信公眾號:嵌入式資訊精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
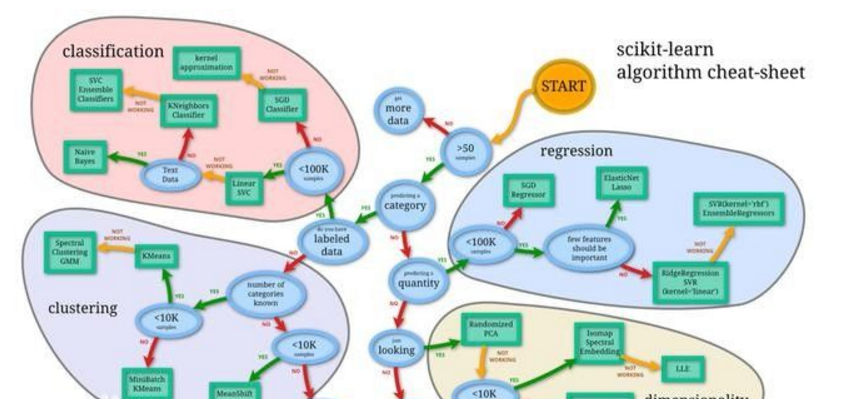
在學習PROTEL99過程中容易出現的一些問題:
你是否在學習STM32的過程中很迷茫
學習Linux內核過程中的心得總結
學習DSP編程過程中經常遇到的問題匯總(1)
機器學習新手常犯的錯誤怎么避免?

關于學習Linux的一些建議
電子設計過程中所要接觸的一些基本概念





 工商網監
工商網監
評論