 基于計算機視覺的自動搜索圖像語義分割架構
基于計算機視覺的自動搜索圖像語義分割架構
近日,斯坦福大學李飛飛組的研究者提出了 Auto-DeepLab,其在圖像語義分割問題上超越了很多業內最佳模型,甚至可以在未經過預訓練的情況下達到預訓練模型的表現。Auto-DeepLab 開發出與分層架構搜索空間完全匹配的離散架構的連續松弛,顯著提高架構搜索的效率,降低算力需求。
深度神經網絡已經在很多人工智能任務上取得了成功,包括圖像識別、語音識別、機器翻譯等。雖然更好的優化器 [36] 和歸一化技術 [32, 79] 在其中起了重要作用,但很多進步要歸功于神經網絡架構的設計。在計算機視覺中,這適用于圖像分類和密集圖像預測。
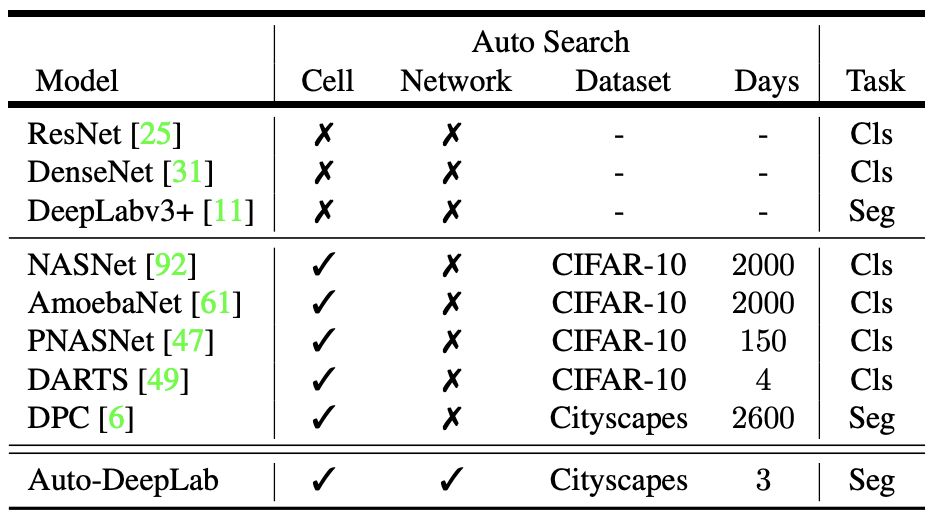
表 1:本研究提出的模型 Auto-DeepLab 和其它雙層 CNN 架構的對比。主要區別有:(1) Auto-DeepLab 直接搜索用于語義分割的 CNN 架構;(2) Auto-DeepLab 搜索網絡級架構和單元級架構;(3) Auto-DeepLab 的高效搜索在一個 P100 GPU 上僅需 3 天。
最近,在AutoML和 AI 民主化的影響下,人們對自動化設計神經網絡架構產生了極大興趣,自動化設計神經網絡無需嚴重依賴專家經驗和知識。更重要的是,去年神經架構搜索(NAS)成功找到了在大規模圖像分類任務上超越人類設計架構的網絡架構 [92, 47, 61]。
圖像分類對 NAS 來說是一個很好的起點,因為它是最基礎且研究最深入的高級識別任務。此外,該研究領域存在具有規模相對較小的基準數據集(如 CIFAR-10),從而減少了計算量并加快了訓練速度。然而,圖像分類不應該是 NAS 的終點,現下的成功表明它可以擴展至要求更高的領域。在本文中,作者研究了用于語義圖像分割的神經架構搜索。這是一項重要的計算機視覺任務,它為輸入圖像的每個像素分配標簽,如「人」或「自行車」。
簡單地移植圖像分類的方法不足以進行語義分割。在圖像分類中,NAS 通常使用從低分辨率圖像到高分辨率圖像的遷移學習 [92],而語義分割的最佳架構必須在高分辨率圖像上運行。這表明,本研究需要:(1) 更松弛、更通用的搜索空間,以捕捉更高分辨率導致的架構變體;(2) 更高效的架構搜索技術,因為高分辨率需要的計算量更大。
作者注意到,現代 CNN 設計通常遵循兩級分層結構,其中外層網絡控制空間分辨率的變化,內層單元級架構管理特定的分層計算。目前關于 NAS 的絕大多數研究都遵循這個兩級分層設計,但只自動化搜索內層網絡,而手動設計外層網絡。這種有限的搜索空間對密集圖像預測來說是一個問題,密集圖像預測對空間分辨率變化很敏感。因此在本研究中,作者提出了一種格子狀的網絡級搜索空間,該搜索空間可以增強 [92] 首次提出的常用單元級搜索空間,以形成分層架構搜索空間。本研究的目標是聯合學習可重復單元結構和網絡結構的良好組合,用于語義圖像分割。
就架構搜索方法而言,強化學習和進化算法往往是計算密集型的——即便在低分辨率數據集 CIFAR-10 上,因此它們不太適合語義圖像分割任務。受 NAS 可微分公式 [68, 49] 的啟發,本研究開發出與分層架構搜索空間完全匹配的離散架構的連續松弛。分層架構搜索通過隨機梯度下降實施。當搜索終止時,最好的單元架構會被貪婪解碼,而最好的網絡架構會通過維特比算法得到有效解碼。作者在從 Cityscapes 數據集中裁剪的 321×321 圖像上直接搜索架構。搜索非常高效,在一個 P100 GPU 上僅需 3 天。
作者在多個語義分割基準數據集上進行了實驗,包括 Cityscapes、PASCAL VOC 2012 和 ADE20K。在未經 ImageNet 預訓練的情況下,最佳 Auto-DeepLab 模型在 Cityscapes 測試集上的結果超過 FRRN-B 8.6%,超過 GridNet 10.9%。在利用 Cityscapes 粗糙標注數據的實驗中,Auto-DeepLab 與一些經過 ImageNet 預訓練的當前最優模型的性能相近。值得注意的是,本研究的最佳模型(未經過預訓練)與 DeepLab v3+(有預訓練)的表現相近,但在 MultiAdds 中前者的速度是后者的 2.23 倍。另外,Auto-DeepLab 的輕量級模型性能僅比 DeepLab v3+ 低 1.2%,而參數量需求卻少了 76.7%,在 MultiAdds 中的速度是 DeepLab v3+ 的 4.65 倍。在 PASCAL VOC 2012 和 ADE29K 上,Auto-DeepLab 最優模型在使用極少數據進行預訓練的情況下,性能優于很多當前最優模型。
本論文主要貢獻如下:
這是首次將 NAS 從圖像分類任務擴展到密集圖像預測任務的嘗試之一。
該研究提出了一個網絡級架構搜索空間,它增強和補充了已經得到深入研究的單元級架構搜索,并對網絡級和單元級架構進行更具挑戰性的聯合搜索。
本研究提出了一種可微的連續方式,保證高效運行兩級分層架構搜索,在一個 GPU 上僅需 3 天。
在未經 ImageNet 預訓練的情況下,Auto-DeepLab 模型在 Cityscapes 數據集上的性能顯著優于 FRRN-B 和 GridNet,同時也和 ImageNet 預訓練當前最佳模型性能相當。在 PASCAL VOC 2012 和 ADE20K 數據集上,最好的 Auto-DeepLab 模型優于多個當前最優模型。
論文:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation

論文地址:https://arxiv.org/pdf/1901.02985v1.pdf
摘要:近期,在圖像分類問題上神經架構搜索(NAS)確定的神經網絡架構能力超越人類設計的網絡。本論文將研究用于語義圖像分割的 NAS,語義圖像分割是將語義標簽分配給圖像中每個像素的重要計算機視覺任務。現有的研究通常關注搜索可重復的單元結構,對控制空間分辨率變化的外部網絡結構進行人工設計。這種做法簡化了搜索空間,但對于具備大量網絡級架構變體的密集圖像預測而言,該方法帶來的問題很多。因此,該研究提出在搜索單元結構之外還要搜索網絡級架構,從而形成一個分層架構搜索空間。本研究提出一種包含多種流行網絡設計的網絡級搜索空間,并提出一個公式來進行基于梯度的高效架構搜索(在 Cityscapes 圖像上使用 1 個 P100 GPU 僅需 3 天)。本研究展示了該方法在較難的 Cityscapes、PASCAL VOC 2012 和 ADE20K 數據集上的效果。在不經任何 ImageNet 預訓練的情況下,本研究提出的專用于語義圖像分割的架構獲得了當前最優性能。
4 方法
這部分首先介紹了精確匹配上述分層架構搜索的離散架構的連續松弛,然后討論了如何通過優化執行架構搜索,以及如何在搜索終止后解碼離散架構。
4.2 優化
連續松弛的作用在于控制不同隱藏狀態之間連接強度的標量現在也是可微計算圖的一部分。因此可以使用梯度下降對其進行高效優化。作者采用了 [49] 中的一階近似,將訓練數據分割成兩個單獨的數據集 trainA 和 trainB。優化在以下二者之間交替進行:
1. 用 ?_w L_trainA(w, α, β) 更新網絡權重 w;
2. 用 ?_(α,β) L_trainB(w, α, β) 更新架構 α, β。
其中損失函數 L 是在語義分割小批量上計算的交叉熵。
4.3 解碼離散架構
單元架構
和 [49] 一樣,本研究首先保留每個構造塊的兩個最強前任者(predecessor),然后使用 argmax 函數選擇最可能的 operator,從而解碼離散單元架構。
網絡架構
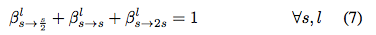
公式 7 本質上表明圖 1 中每個藍色節點處的「outgoing 概率」的總和為 1。事實上,β 可被理解為不同「時間步」(層數)中不同「狀態」(空間分辨率)之間的「transition 概率」。本研究的目標是從頭開始找到具備「最大概率」的的路徑。在實現中,作者可以使用經典維特比算法高效解碼該路徑。
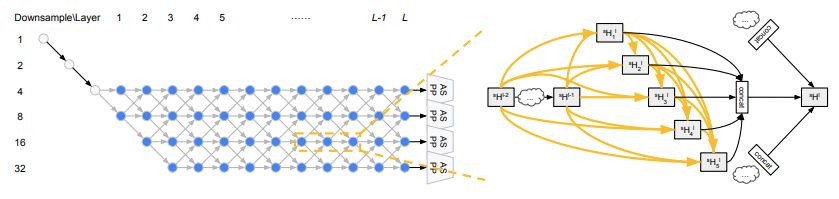
圖 1:左圖是 L = 12 時的網絡級搜索空間。灰色節點表示固定的「stem」層,沿著藍色節點形成的路徑表示候選網絡級架構。右圖展示了搜索過程中,每個單元是一個密集連接的結構。
5 實驗結果
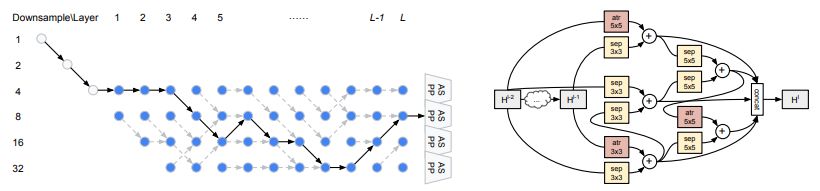
圖 3:使用本研究提出的分層神經架構搜索方法找到的最優網絡架構和單元架構。灰色虛線箭頭表示每個節點處具備最大 β 值的連接。atr 指空洞卷積(atrous convolution),sep 指深度可分離卷積(depthwise-separable convolution)。
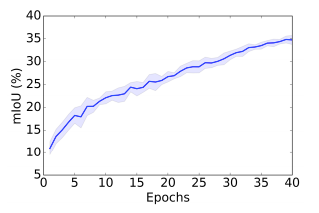
圖 4:在 10 次隨機試驗中,40 個 epoch 中架構搜索優化的驗證準確率。
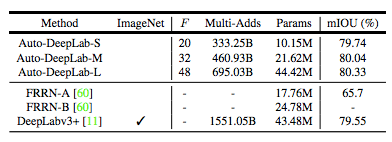
表 2:不同 Auto-DeepLab 模型變體在 Cityscapes 驗證集上的結果。F:控制模型容量的 filter multiplier。所有 Auto-DeepLab 模型都是從頭開始訓練,且在推斷過程中使用單尺度輸入。
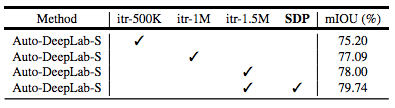
表 3:Cityscapes 驗證集結果。研究采用不同的訓練迭代次數(50 萬、100 萬與 150 萬次迭代)和 SDP(Scheduled Drop Path)方法進行實驗。所有模型都是從頭訓練的。
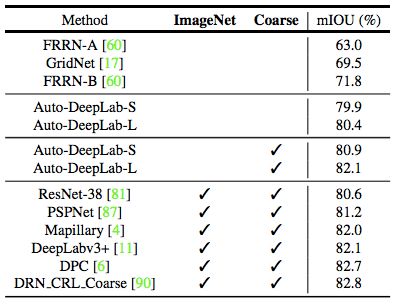
表 4:模型在推斷過程中使用多尺度輸入時在 Cityscapes 測試集上的結果。ImageNet:在 ImageNet 上預訓練的模型。Coarse:利用粗糙注釋的模型。
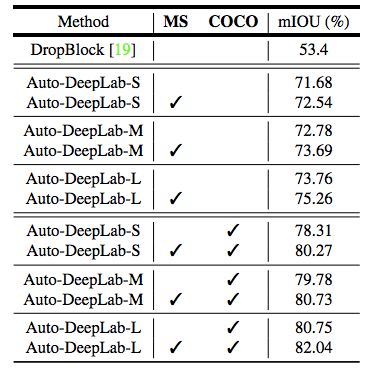
表 5:PASCAL VOC 2012 驗證集結果。本研究采用多尺度推理(MS,multi-scale inference)和 COCO 預訓練檢查點(COCO)進行實驗。在未經任何預訓練的情況下,本研究提出的最佳模型(Auto-DeepLab-L)超越了 DropBlock 20.36%。所有的模型都沒有使用 ImageNet 圖像做預訓練。
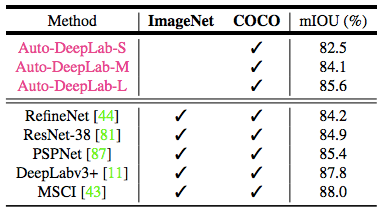
表 6:PASCAL VOC 2012 測試集結果。本研究提出的 AutoDeepLab-L 取得了可與眾多在 ImageNet 和 COCO 數據集上預訓練的頂級模型相媲美的結果。
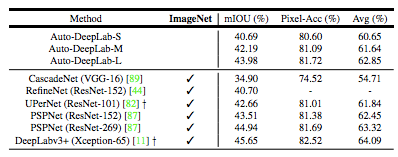
表 7:ADE20K 驗證集結果。在推斷過程中使用多尺度輸入。? 表示結果分別是從他們最新的模型 zoo 網站獲得的。ImageNet:在 ImageNet 上預訓練的模型。Avg:mIOU 和像素準確率的均值。
圖 5:在 Cityscapes 驗證集上的可視化結果。最后一行展示了本研究提出方法的故障模式,模型將一些較難的語義類別混淆了,如人和騎車的人。
圖 6:在 ADE20K 驗證集上的可視化結果。最后一行展示了本研究提出方法的故障模式,模型無法分割非常細粒度的對象(如椅子腿),且將較難的語義類別混淆了(如地板和地毯)
-
人工智能
+關注
關注
1791文章
46845瀏覽量
237535 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927
原文標題:李飛飛等人提出Auto-DeepLab:自動搜索圖像語義分割架構
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度解析計算機視覺的圖像分割技術

李飛飛等人提出Auto-DeepLab:自動搜索圖像語義分割架構

跨圖像關系型KD方法語義分割任務-CIRKD







 工商網監
工商網監
評論