 詳解谷歌最強NLP模型BERT
詳解谷歌最強NLP模型BERT
作者:李理,環信人工智能研發中心vp,十多年自然語言處理和人工智能研發經驗。主持研發過多款智能硬件的問答和對話系統,負責環信中文語義分析開放平臺和環信智能機器人的設計與研發。
本文是作者正在編寫的《深度學習理論與實戰》的部分內容。
導語
Google BERT 模型最近橫掃了各大評測任務,在多項任務中取得了最好的結果,而且很多任務比之前最好的系統都提高了非常多,可以說是深度學習最近幾年在 NLP的一大突破。但它并不是憑空出現的,最近一年大家都非常關注的 UnsupervisedSentence Embedding 取得了很大的進展,包括 ELMo 和 OpenAI GPT 等模型都取得了很好的結果。而 BERT 在它們的基礎上改進了語言模型單向信息流的問題,并且借助 Google 強大的工程能力和計算資源的優勢,從而取得了巨大的突破。
本文從理論和編程實戰角度詳細的介紹 BERT 和它之前的相關的模型,包括
Transformer 模型。希望讀者閱讀本文之后既能理解模型的原理,同時又能很快的把模型用于解決實際問題。本文假設讀者了解基本的深度學習知識包括 RNN/LSTM、Encoder-Decoder 和 Attention 等。
Sentence Embedding 簡介
前面我們介紹了 Word Embedding,怎么把一個詞表示成一個稠密的向量。Embedding幾乎是在 NLP 任務使用深度學習的標準步驟。我們可以通過 Word2Vec、GloVe 等從未標注數據無監督的學習到詞的 Embedding,然后把它用到不同的特定任務中。這種方法得到的 Embedding 叫作預訓練的 (pretrained)Embedding。如果特定任務訓練數據較多,那么我們可以用預訓練的 Embedding 來初始化模型的 Embedding,然后用特定任務的監督數據來 fine-tuning。如果監督數據較少,我們可以固定 (fix)Embedding,只讓模型學習其它的參數。這也可以看成一種 Transfer Learning。
但是 NLP 任務的輸入通常是句子,比如情感分類,輸入是一個句子,輸出是正向或者負向的情感。我們需要一種機制表示一個句子,最常見的方法是使用 CNN 或者 RNN 對句子進行編碼。用來編碼的模塊叫作編碼器 (Encoder),編碼的輸出是一個向量。和詞向量一樣,我們期望這個向量能夠很好的把一個句子映射到一個語義空間,相似的句子映射到相近的地方。編碼句子比編碼詞更加復雜,因為詞組成句子是有結構的 (我們之前的 Paring 其實就是尋找這種結構),兩個句子即使詞完全相同但是詞的順序不同,語義也可能相差很大。
傳統的編碼器都是用特定任務的監督數據訓練出來的,它編碼的目的是為了優化具體這個任務。因此它編碼出的向量是適合這個任務的——如果這個任務很關注詞序,那么它在編碼的使用也會關注詞序;如果這個任務關注構詞法,那么學到的編碼器也需要關注構詞法。
但是監督數據總是很少的,獲取的成本也極高。因此最近 (2018 年上半年),無監督的通用 (universal) 的句子編碼器成為熱點并且有了一些進展。無監督的意思是可以使用未標注的原始數據來學習編碼器 (的參數),而通用的意思是學習到的編碼器不需要 (太多的)fine-tuning 就可以直接用到所有 (只是是很多) 不同的任務中,并且能得到很好的效果。
評測工具
在介紹 Unsupervised Sentence Embedding 的具體算法之前我們先介紹兩個評測工具(平臺)。
SentEval
簡介
Sentence Embedding(包括 Word Embedding) 通常有兩類評價方法:intrinsic 和 ex-trinsic。前者只評價 Embedding 本身,比如讓人來主觀評價。而后者通過下游 (Downstream) 的任務間接的來評價 Embedding 的好壞。前一種方法耗費人力,而且我們學習 Embedding 的目的也是為了解決后面的真實問題,因此 extrinsic 的評價更加重要。但是下游的任務通常很復雜,Embedding 只是其中的一個環節,因此很難說明最終效果的提高就是由于 Embedding 帶來的,也許只是某個預處理或者超參數的調節帶來的提高,但是卻可能被作者認為是 Embedding 的功勞。另外下游任務很多,很多文章的結果也很難比較。
為了解決這些問題,Facebook 做了 SentEval 這個工具。這是一個用于評估Universal Sentence Representation 的工具,所謂的 Universal Sentence Representation是指與特定任務無關的通用的句子表示 (Embedding) 方法。為了保證公平公正,這個工具只評價句子的 Embedding,對于具體的任務,大家都使用相同的預處理,網絡結構和后處理,從而能夠保證比較公平的評測。
SentEval 任務分類
SentEval 任務分為如下類別:
分類問題 (包括二分類和多分類)
Natural Language Inference
語義相似度計算
圖像檢索 (Image Retrieval)

圖 17.1: SentEval 的分類任務
分類很簡單,輸入是一個字符串 (一個句子或者文章),輸出是一個分類標簽。所以任務如圖17.1所示。包括情感分類、句子類型分類等等任務。
Natural Language Inference(NLI) 任務也叫 recognizing textual entailment(RTE),它的輸入是兩個句子,需要機器判斷第一個句子和第二個句子的關系。它們的關系通常有 3 種:矛盾 (contradiction)、無關 (neutral) 和蘊含 (entailment)。
SNLI(https://nlp.stanford.edu/projects/snli/) 是很常用的 NLI 數據集,示例是來自這個數據集的例子。比如下面的兩個句子是矛盾的:
A man inspects the uniform of a figure in some East Asian country.
The man is sleeping.
一個人不能同時在觀察和睡覺。而下面兩個句子的關系是無關的:
A smiling costumed woman is holding an umbrella.
A happy woman in a fairy costume holds an umbrella.
而下面兩個的第一個句子蘊含了第二個句子:
A soccer game with multiple males playing.
Some men are playing a sport.
語義相似度計算的輸入是兩個句子,輸出是它們的相似度,一般相似度會分為幾個程度,所以輸出也是標簽。當然最簡單的是分成兩類——相似與不相似,比如MRPC 就是這樣的任務,這個任務又叫 Paraphrase Detection,判斷兩個句子是否同義復寫。
Image Retrieval 的輸入是一幅圖片和一段文字,如果文字能很好的描述圖片的內容,那么輸出一個高的分值,否則輸出低分。
SentEval 包括的 NLI 和圖像檢索任務如圖17.2所示。

圖 17.2: SentEval 的 NLI 和 Image Retrieval 任務
SentEval 的用法
SentEval 依賴 NumPy/SciPy、PyTorch(>=0.4.0) 和 scikit-learn(>=0.18.0)。
然后從https://github.com/facebookresearch/SentEval.git clone 代碼。SentEval 提供了一些baseline 系統,包括 bow、infersent 和 skipthought 等等。讀者如果實現了一種新的Sentence Embedding 算法,那么可以參考 baseline 的代碼用 SentEval 來評價算法的好壞。
我們這里只介紹最簡單的 bow 的用法,它就是把 Pretraining 的 Word Embedding加起來得到 Sentence Embedding。
我們首先下載 fasttext 的 Embedding:

然后運行:

main 函數代碼為:


首先構造 senteval.engine.SE,然后列舉需要跑的 task,最后調用 se.eval 得到結果。
構造 senteval.engine.SE 需要傳入 3 個參數,params_senteval, batcher 和 prepare。params_senteval 是控制 SentEval 模型訓練的一些超參數。比如 bow.py 里的:

而后兩個參數是函數,我們先看 prepare:

這個函數相當于初始化的回調函數,參數會傳入 params 和 samples,samples 就是所有的句子,我們需要根據這些句子來做一些初始化的工作,結果存在 params 里,后面會用到。這里我們用 samples 構造 word2id——word 到 id 的映射,另外根據word2id,從預訓練的詞向量里提取需要的詞向量 (因為預訓練的詞向量有很多詞,但是在某個具體任務中用到的詞是有限的,我們只需要提取需要的部分),另外把詞向量的維度保持到 params 里。
batcher 函數的輸入參數是前面的 params 和 batch,batch 就是句子列表,我們需要對它做 Sentence Embedding,這里的實現很簡單,就是把詞向量加起來求平均值得到句子向量。

GLUE
Facebook 搞了個標準,Google 也要來一個,所以就有了 GLUE(https://gluebenchmark.com/)。GLUE 是 General Language Understanding Evaluation 的縮寫。它們之間很多的任務都是一樣的,我們這里就不詳細介紹了,感興趣的讀者可以參考論文”GLUE: A Multi-Task Benchmark and Analysis Platform for Natural LanguageUnderstanding”。
Transformer
簡介
Transformer 模型來自與論文 Attention Is All You Need(https://arxiv.org/abs/1706.03762)。
這個模型最初是為了提高機器翻譯的效率,它的 Self-Attention 機制和 Position Encoding 可以替代 RNN。因為 RNN 是順序執行的,t 時刻沒有處理完成就不能處理 t+1 時刻,因此很難并行。但是后來發現 Self-Attention 效果很好,在很多其它的地方也可以是 Transformer 模型。
圖解
我們首先通過圖的方式直觀的解釋 Transformer 模型的基本原理,這部分內容主要來自文章The Illustrated Transformer(http://jalammar.github.io/illustratedtransformer/)。
模型概覽
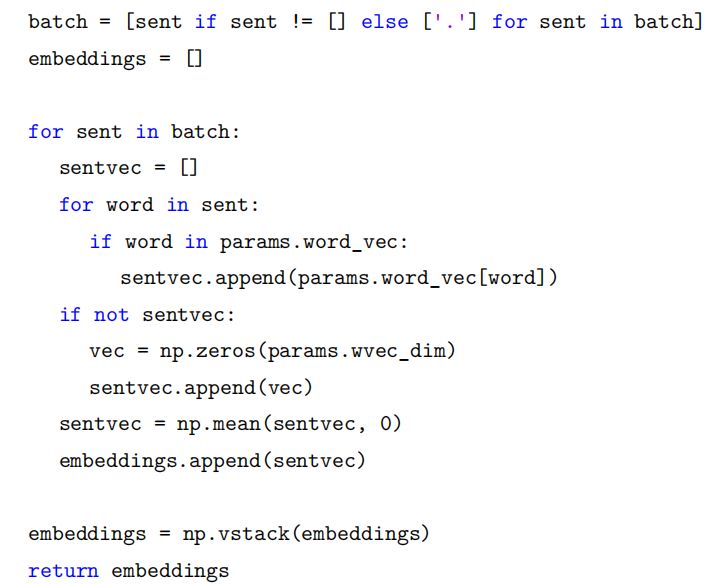
我們首先把模型看成一個黑盒子,如圖15.51所示,對于機器翻譯來說,它的輸入是源語言 (法語) 的句子,輸出是目標語言 (英語) 的句子。
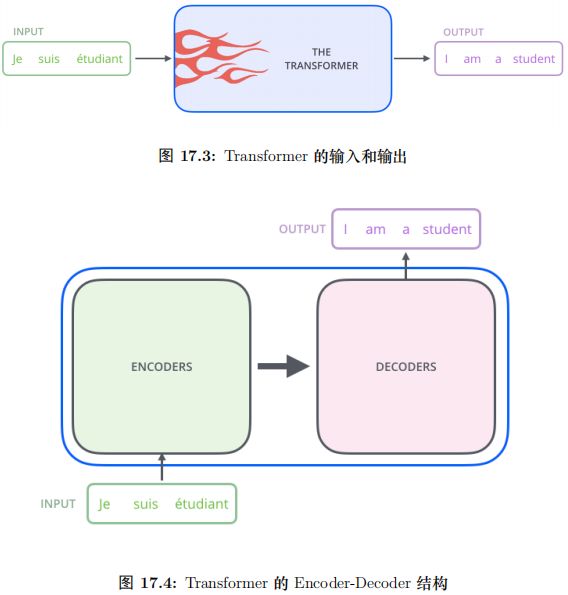
把黑盒子稍微打開一點,Transformer(或者任何的 NMT 系統) 都可以分成
Encoder 和 Decoder 兩個部分,如圖15.52所示。
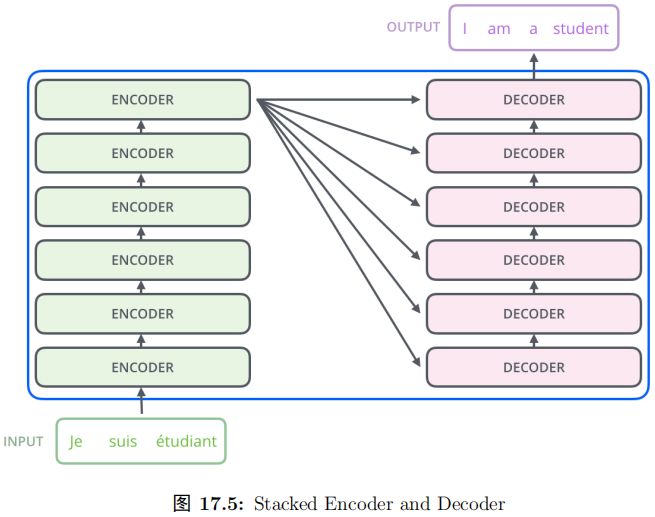
再展開一點,Encoder 由很多 (6 個) 結構一樣的 Encoder 堆疊 (stack) 而成,Decoder 也是一樣。如圖15.53所示。注意:每一個 Encoder 的輸入是下一層 Encoder輸出,最底層 Encoder 的輸入是原始的輸入 (法語句子);Decoder 也是類似,但是最后一層 Encoder 的輸出會輸入給每一個 Decoder 層,這是 Attention 機制的要求。
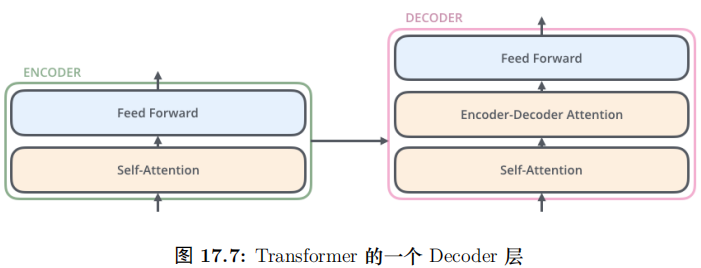
每一層的 Encoder 都是相同的結構,它有一個 Self-Attention 層和一個前饋網絡(全連接網絡) 組成,15.54如圖所示。每一層的 Decoder 也是相同的結果,它除了 Self-Attention 層和全連接層之外還多了一個普通的 Attention 層,這個 Attention 層使得 Decoder 在解碼時會考慮最后一層 Encoder 所有時刻的輸出。它的結構如圖17.3所示。
加入 Tensor
前面的圖示只是說明了 Transformer 的模塊,接下來我們加入 Tensor,了解這些模塊是怎么串聯起來的。
輸入的句子是一個詞 (ID) 的序列,我們首先通過 Embedding 把它變成一個連續稠密的向量,如圖17.4所示。
Embedding 之后的序列會輸入 Encoder,首先經過 Self-Attention 層然后再經過全連接層,如圖17.5所示。
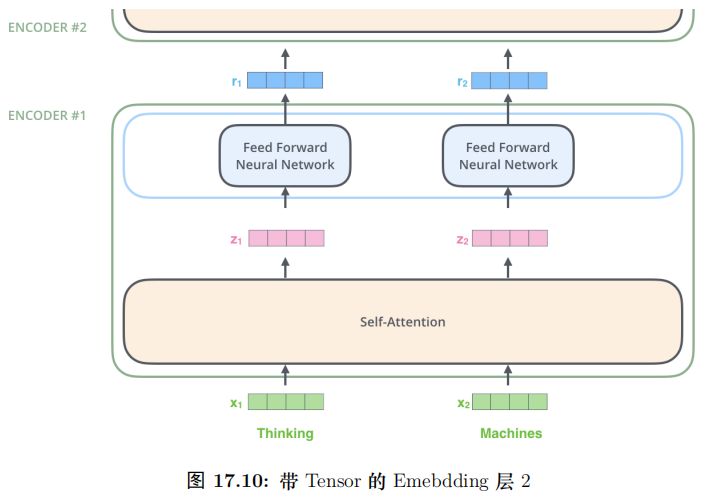
我們在計算 zi 是需要依賴所有時刻的輸入 x1, ..., xn,不過我們可以用矩陣運算一下子把所有的 zi 計算出來 (后面介紹)。而全連接網絡的計算則完全是獨立的,計算 i 時刻的輸出只需要輸入 zi 就足夠了,因此很容易并行計算。
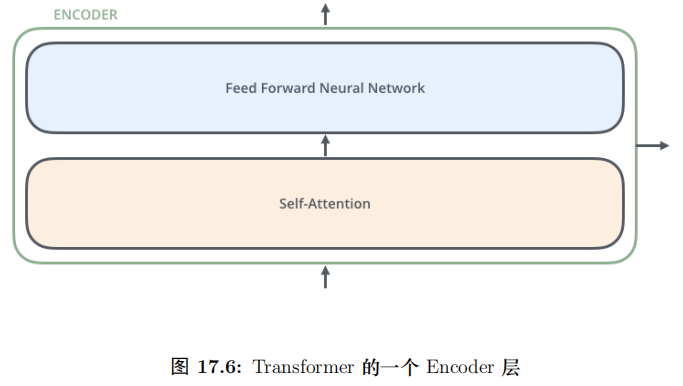
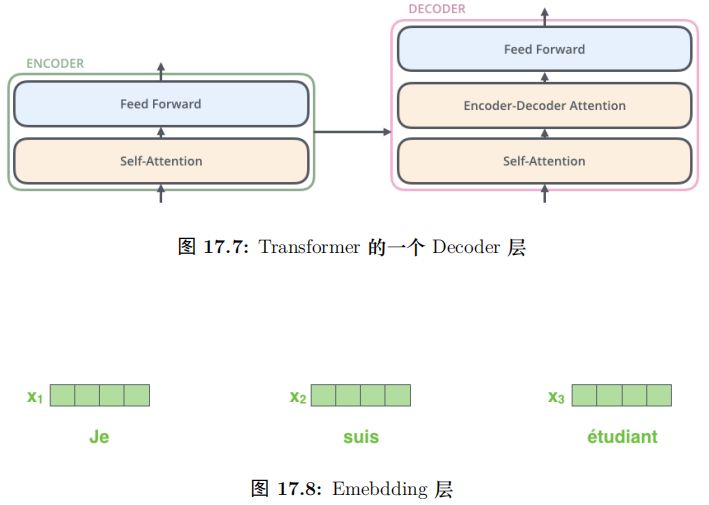
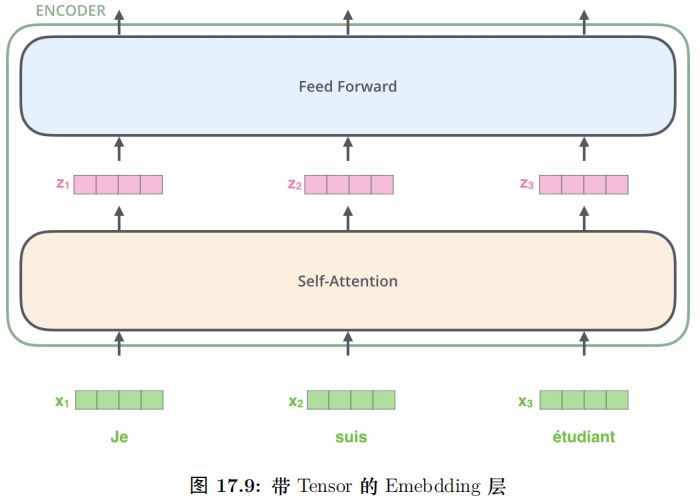
圖17.6更加明確的表達了這一點。圖中 Self-Attention 層是一個大的方框,表示它的輸入是所有的 x1, ..., xn,輸出是 z1, ..., zn。而全連接層每個時刻是一個方框,表示計算 ri 只需要 zi。此外,前一層的輸出 r1, ...,rn 直接輸入到下一層。
Self-Attention 簡介
比如我們要翻譯如下句子”The animal didn’t cross the street because it was tootired”(這個動物無法穿越馬路,因為它太類了)。這里的 it 到底指代什么呢,是animal 還是 street?要知道具體的指代,我們需要在理解 it 的時候同時關注所有的單詞,重點是 animal、street 和 tired,然后根據知識 (常識) 我們知道只有 animal 才能tired,而 stree 是不能 tired 的。Self-Attention 運行 Encoder 在編碼一個詞的時候考慮句子中所有其它的詞,從而確定怎么編碼當前詞。如果把 tired 換成 narrow,那么it 就指代的是 street 了。
而 LSTM(即使是雙向的) 是無法實現上面的邏輯的。為什么呢?比如前向的
LSTM,我們在編碼 it 的時候根本沒有看到后面是 tired 還是 narrow,所有它無法把it 編碼成哪個詞。而后向的 LSTM 呢?當然它看到了 tired,但是到 it 的時候它還沒有看到 animal 和 street 這兩個單詞,當然就更無法編碼 it 的內容了。
當然多層的 LSTM 理論上是可以編碼這個語義的,它需要下層的 LSTM 同時編碼了 animal 和 street 以及 tired 三個詞的語義,然后由更高層的 LSTM 來把 it 編碼成 animal 的語義。但是這樣模型更加復雜。
下圖17.7是模型的最上一層 (下標 0 是第一層,5 是第六層)Encoder 的Attention可視化圖。這是 tensor2tensor 這個工具輸出的內容。我們可以看到,在編碼 it 的時候有一個 Attention Head(后面會講到) 注意到了Animal,因此編碼后的 it 有 Animal的語義。
Self-Attention 詳細介紹
下面我們詳細的介紹 Self-Attention 是怎么計算的,首先介紹向量的形式逐個時刻計算,這便于理解,接下來我們把它寫出矩陣的形式一次計算所有時刻的結果。
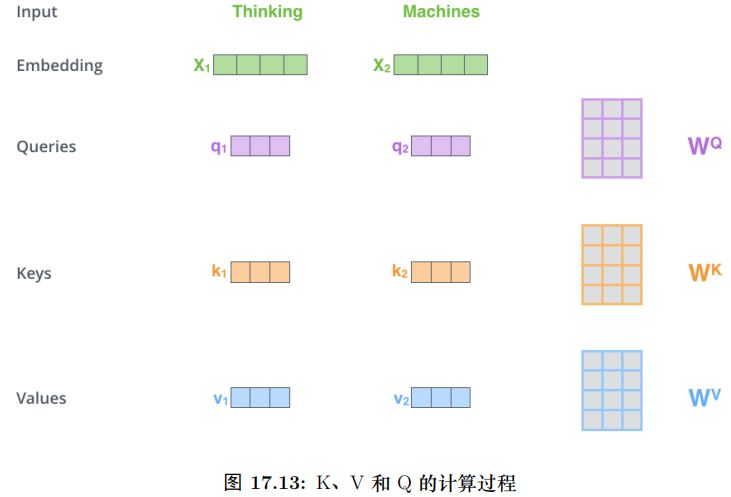
對于輸入的每一個向量 (第一層是詞的 Embedding,其它層是前一層的輸出),我們首先需要生成 3 個新的向量 Q、K 和 V,分別代表查詢 (Query) 向量、Key 向量和 Value 向量。Q 表示為了編碼當前詞,需要去注意 (attend to) 其它 (其實也包括它自己) 的詞,我們需要有一個查詢向量。而 Key 向量可以任務是這個詞的關鍵的用于被檢索的信息,而 Value 向量是真正的內容。
我們對比一些普通的 Attention(Luong 2015),使用內積計算 energy 的情況。如圖17.8所示,在這里,每個向量的 Key 和 Value 向量都是它本身,而 Q 是當前隱狀態 ht,計算 energy etj 的時候我們計算 Q(ht) 和Key(barhj)。然后用 softmax 變成概率,最后把所有的 barhj 加權平均得到 context 向量。
而 Self-Attention 里的 Query 不是隱狀態,并且來自當前輸入向量本身,因此叫作 Self-Attention。另外 Key 和 Value 都不是輸入向量,而是輸入向量做了一下線性變換。
當然理論上這個線性變換矩陣可以是 Identity 矩陣,也就是使得Key=Value=輸入向量。因此可以認為普通的 Attention 是這里的特例。這樣做的好處是系統可以學習的,這樣它可以根據數據從輸入向量中提取最適合作為 Key(可以看成一種索引)和 Value 的部分。類似的,Query 也是對輸入向量做一下線性變換,它讓系統可以根據任務學習出最適合的 Query,從而可以注意到 (attend to) 特定的內容。
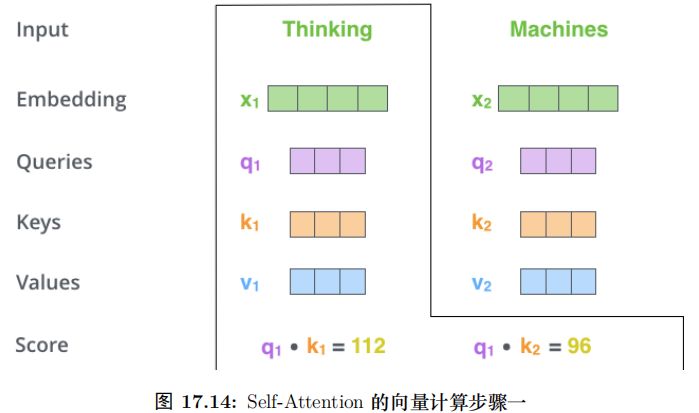
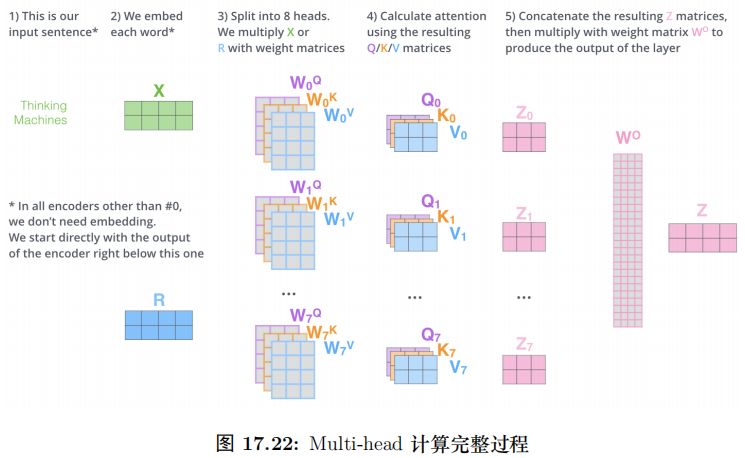
具體的計算過程如圖17.9所示。比如圖中的輸入是兩個詞”thinking” 和”machines”,我們對它們進行Embedding(這是第一層,如果是后面的層,直接輸入就是向量了),得到向量 x1, x2。接著我們用 3 個矩陣分別對它們進行變換,得到向量 q1, k1, v1 和q2, k2, v2。比如 q1 = x1WQ,圖中 x1 的 shape 是 1x4,WQ 是 4x3,得到的 q1 是 1x3。其它的計算也是類似的,為了能夠使得 Key 和 Query 可以內積,我們要求 WK 和WQ 的 shape 是一樣的,但是并不要求 WV 和它們一定一樣 (雖然實際論文實現是一樣的)。每個時刻 t 都計算出 Qt, Kt, Vt 之后,我們就可以來計算 Self-Attention 了。以第一個時刻為了,我們首先計算 q1 和 k1, k2 的內積,得到 score,過程如圖17.10所示。
接下來使用 softmax 把得分變成概率,注意這里把得分除以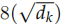 之后再計算的 softmax,根據論文的說法,這樣計算梯度時會更加文檔 (stable)。計算過程如圖17.11所示。
之后再計算的 softmax,根據論文的說法,這樣計算梯度時會更加文檔 (stable)。計算過程如圖17.11所示。

接下來用 softmax 得到的概率對所有時刻的 V 求加權平均,這樣就可以認為得到的向量根據 Self-Attention 的概率綜合考慮了所有時刻的輸入信息,計算過程如圖17.12所示。
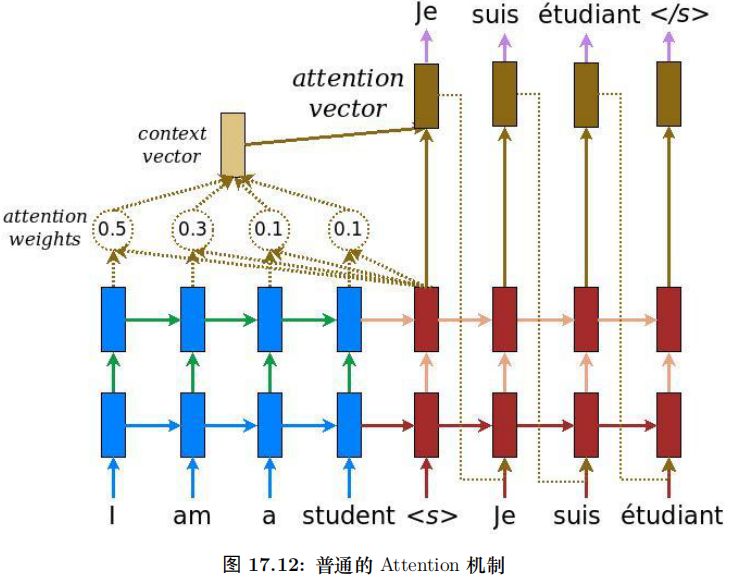
這里只是演示了計算第一個時刻的過程,計算其它時刻的過程是完全一樣的。
矩陣計算
前面介紹的方法需要一個循環遍歷所有的時刻 t 計算得到 zt,我們可以把上面的向量計算變成矩陣的形式,從而一次計算出所有時刻的輸出,這樣的矩陣運算可以充分利用硬件資源 (包括一些軟件的優化),從而效率更高。
第一步還是計算 Q、K 和 V,不過不是計算某個時刻的 qt, kt, vt 了,而是一次計算所有時刻的 Q、K 和 V。
計算過程如圖17.13所示。這里的輸入是一個矩陣,矩陣的第 i 行表示第 i 個時刻的輸入 xi。
接下來就是計算 Q 和 K 得到 score,然后除以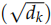 ,然后再 softmax,最后加權平均得到輸出。全過程如圖17.14所示。
,然后再 softmax,最后加權平均得到輸出。全過程如圖17.14所示。
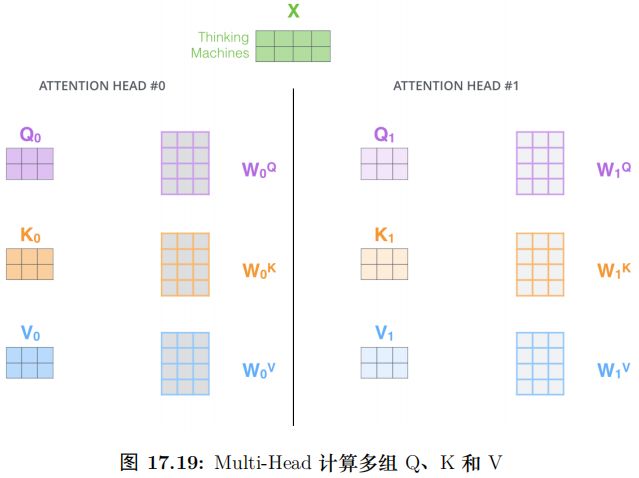
Multi-Head Attention
這篇論文還提出了 Multi-Head Attention 的概念。其實很簡單,前面定義的一組 Q、K 和 V 可以讓一個詞 attend to 相關的詞,我們可以定義多組 Q、K 和 V,它們分別可以關注不同的上下文。
計算 Q、K 和 V 的過程還是一樣,這不過現在變換矩陣從一組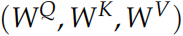
變成了多組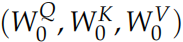 ,
,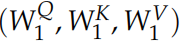 ,...。如圖所示。
,...。如圖所示。
對于輸入矩陣 (time_step, num_input),每一組 Q、K 和 V 都可以得到一個輸
出矩陣 Z(time_step, num_features)。如圖17.16所示。
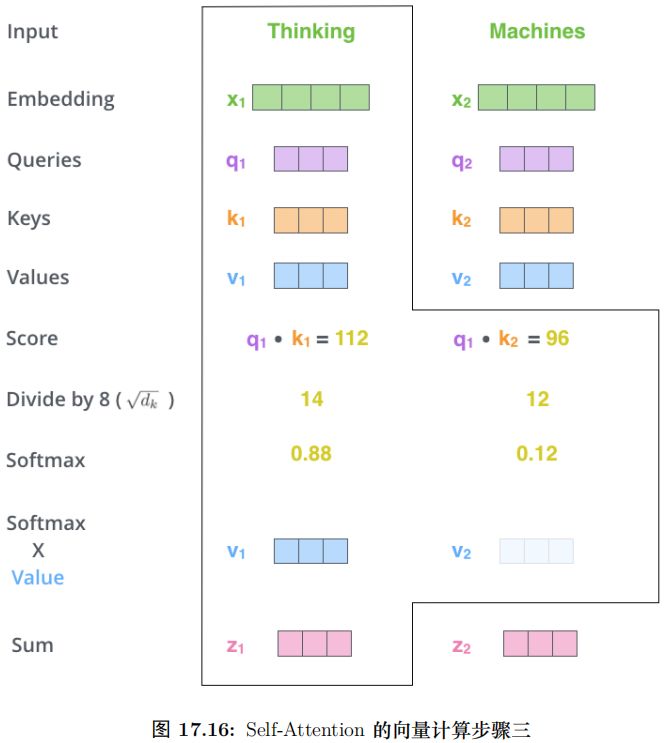
但是后面的全連接網絡需要的輸入是一個矩陣而不是多個矩陣,因此我們可以
把多個 head 輸出的 Z 按照第二個維度拼接起來,但是這樣的特征有一些多,因此Transformer 又用了一個線性變換 (矩陣 WO) 對它進行了壓縮。這個過程如圖17.17所示。
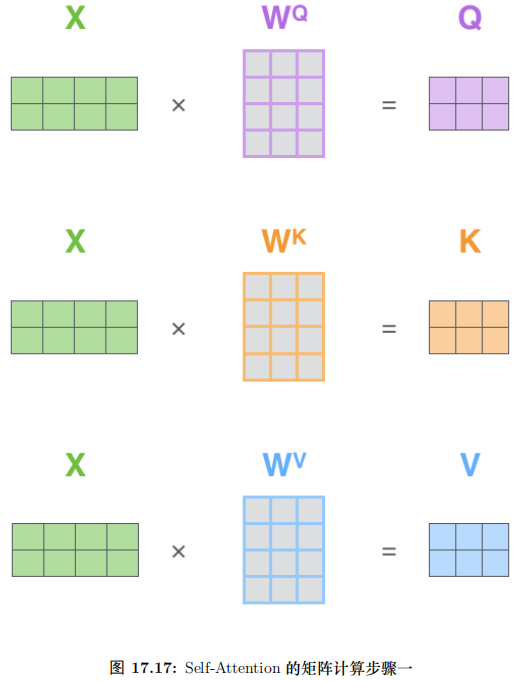
上面的步驟涉及很多步驟和矩陣運算,我們用一張大圖把整個過程表示出來,如圖17.18所示。我們已經學習過來 Transformer 的 Self-Attention 機制,下面我們通過一個具體的例子來看看不同的 Attention Head 到底學習到了什么樣的語義。
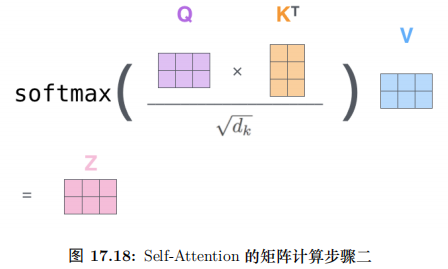
圖17.19是一個 Attention Head 學習到的語義,我們可以看到對于 it 一個 Head會注意到”the animal” 而另外一個 Head 會注意到”tired”。
如果把所有的 Head 混在一起,如圖17.20所示,那么就很難理解它到底注意的是什么內容。從上面兩圖的對比也能看出使用多個 Head 的好處——每個 Head(在數據的驅動下) 學習到不同的語義。
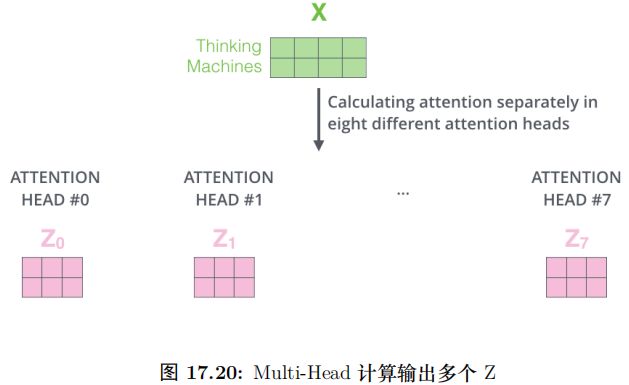
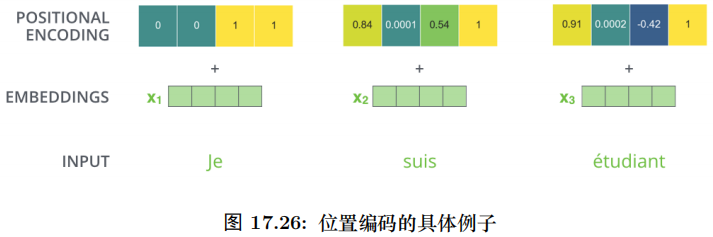
位置編碼 (Positional Encoding)
注意:這是原始論文使用的位置編碼方法,而在 BERT 模型里,使用的是簡單的可以學習的 Embedding,和 Word Embedding 一樣,只不過輸入是位置而不是詞而已。
我們的目的是用 Self-Attention 替代 RNN,RNN 能夠記住過去的信息,這可以通過 Self-Attention“實時”的注意相關的任何詞來實現等價 (甚至更好) 的效果。RNN還有一個特定就是能考慮詞的順序 (位置) 關系,一個句子即使詞完全是相同的但是語義可能完全不同,比如” 北京到上海的機票” 與” 上海到北京的機票”,它們的語義就有很大的差別。我們上面的介紹的 Self-Attention 是不考慮詞的順序的,如果模型參數固定了,上面兩個句子的北京都會被編碼成相同的向量。但是實際上我們可以期望這兩個北京編碼的結果不同,前者可能需要編碼出發城市的語義,而后者需要包含目的城市的語義。而 RNN 是可以 (至少是可能) 學到這一點的。當然 RNN 為了實現這一點的代價就是順序處理,很難并行。
為了解決這個問題,我們需要引入位置編碼,也就是 t 時刻的輸入,除了Embedding 之外 (這是與位置無關的),我們還引入一個向量,這個向量是與 t 有關的,我們把 Embedding 和位置編碼向量加起來作為模型的輸入。這樣的話如果兩個詞在不同的位置出現了,雖然它們的 Embedding 是相同的,但是由于位置編碼不同,最終得到的向量也是不同的。
位置編碼有很多方法,其中需要考慮的一個重要因素就是需要它編碼的是相對位置的關系。比如兩個句子:” 北京到上海的機票” 和” 你好,我們要一張北京到上海的機票”。顯然加入位置編碼之后,兩個北京的向量是不同的了,兩個上海的向量也是不同的了,但是我們期望 Query(北京 1)*Key(上海 1) 卻是等于 Query(北京 2)*Key(上海 2) 的。具體的編碼算法我們在代碼部分再介紹。
位置編碼加入模型如圖17.21所示。

一個具體的位置編碼的例子如圖17.22所示。
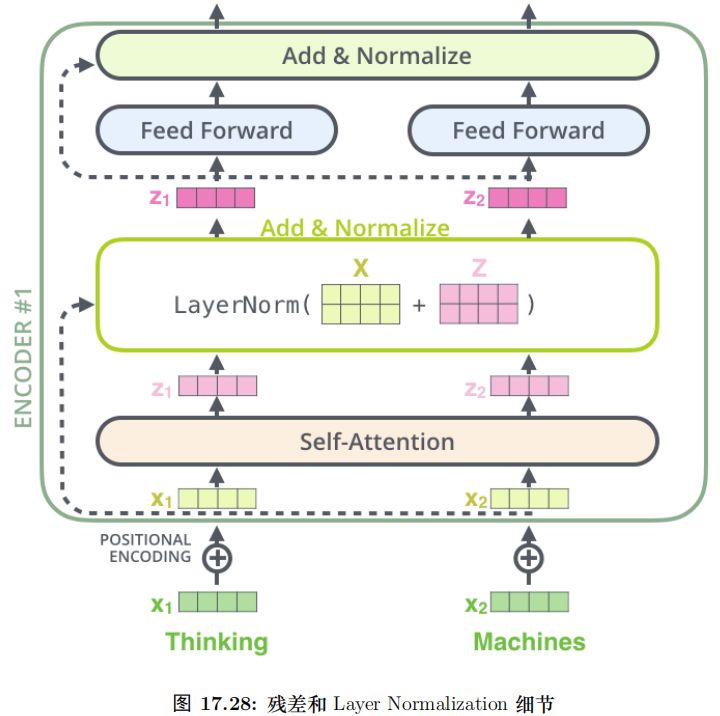
殘差連接
每個 Self-Attention 層都會加一個殘差連接,然后是一個 LayerNorm 層,如圖17.23所示。


圖17.24展示了更多細節:輸入 x1, x2 經 self-attention 層之后變成 z1, z2,然后和殘差連接的輸入 x1, x2 加起來,然后經過 LayerNorm 層輸出給全連接層。全連接層也是有一個殘差連接和一個 LayerNorm 層,最后再輸出給上一層。
Decoder 和 Encoder 是類似的,如圖17.25所示,區別在于它多了一個EncoderDecoder Attention 層,這個層的輸入除了來自 Self-Attention 之外還有 Encoder 最后一層的所有時刻的輸出。
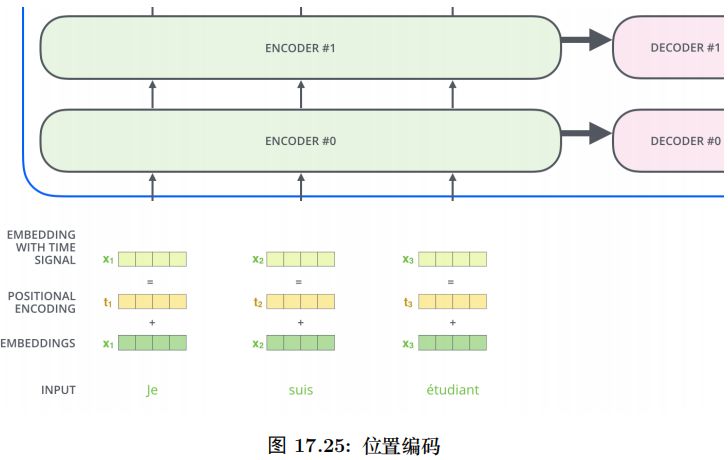
Encoder-Decoder Attention 層的 Query 來自下一層,而 Key 和 Value 則來自Encoder 的輸出。
代碼
本節內容來自
http://nlp.seas.harvard.edu/2018/04/03/attention.html。讀者可以從https://github.com/harvardnlp/annotated-transformer.git 下載代碼。這篇文章原名叫作《The Annotated Transformer》。相當于原始論文的讀書筆記,但是不同之處在于它不但詳細的解釋論文,而且還用代碼實現了論文的模型。
注意:本書并不沒有完全翻譯這篇文章,而是根據作者自己的理解來分析和閱讀其源代碼。而 Transformer 的原來在前面的圖解部分已經分析的很詳細了,因此這里關注的重點是代碼。網上有很多 Transformer 的源代碼,也有一些比較大的庫包含了Transformer 的實現,比如 Tensor2Tensor 和 OpenNMT 等等。作者選擇這個實現的原因是它是一個單獨的 ipynb 文件,如果我們要實際使用非常簡單,復制粘貼代碼就行了。而 Tensor2Tensor 或者 OpenNMT 包含了太多其它的東西,做了過多的抽象。
雖然代碼質量和重用性更好,但是對于理解論文來說這是不必要的,并且增加了理解的難度。
運行
這里的代碼需要 PyTorch-0.3.0,所以建議讀者使用 virtualenv 安裝。另外為了在Jupyter notebook 里使用這個 virtualenv,需要執行如下命令:

背景介紹
前面提到過 RNN 等模型的缺點是需要順序計算,從而很難并行。因此出現了Extended Neural GPU、ByteNet 和 ConvS2S 等網絡模型。這些模型都是以 CNN 為基礎,這比較容易并行。但是和 RNN 相比,它較難學習到長距離的依賴關系。
本文的 Transformer 使用了 Self-Attention 機制,它在編碼每一詞的時候都能夠注意 (attend to) 整個句子,從而可以解決長距離依賴的問題,同時計算 Self-Attention可以用矩陣乘法一次計算所有的時刻,因此可以充分利用計算資源 (CPU/GPU 上的矩陣運算都是充分優化和高度并行的)。
模型結構
目前的主流神經序列轉換 (neural sequence transduction) 模型都是基于 EncoderDecoder 結構的。所謂的序列轉換模型就是把一個輸入序列轉換成另外一個輸出序列,它們的長度很可能是不同的。比如基于神經網絡的機器翻譯,輸入是法語句子,輸出是英語句子,這就是一個序列轉換模型。類似的包括文本摘要、對話等問題都可以看成序列轉換問題。我們這里主要關注機器翻譯,但是任何輸入是一個序列輸出是另外一個序列的問題都可以考慮使用 Encoder-Decoder 模型。
Encoder 講輸入序列 (x1, ..., xn) 映射 (編碼) 成一個連續的序列 z = (z1, ..., zn)。而Decoder 根據 z 來解碼得到輸出序列 y1, ..., ym。Decoder 是自回歸的 (auto-regressive)——它會把前一個時刻的輸出作為當前時刻的輸入。
Encoder-Decoder 結構模型的代碼如下:


EncoderDecoder 定義了一種通用的 Encoder-Decoder 架構,具體的 Encoder、Decoder、src_embed、target_embed 和 generator 都是構造函數傳入的參數。這樣我們做實驗更換不同的組件就會更加方便。

注意:Generator 返回的是 softmax 的 log 值。在 PyTorch 里為了計算交叉熵損失,有兩種方法。第一種方法是使用 nn.CrossEntropyLoss(),一種是使用 NLLLoss()。第一種方法更加容易懂,但是在很多開源代碼里第二種更常見,原因可能是它后來才有,大家都習慣了使用 NLLLoss。
我們先看 CrossEntropyLoss,它就是計算交叉熵損失函數,比如:

比如上面的代碼,假設是 5 分類問題,x 表示模型的輸出 logits(batch=1),而 y 是真實分類的下標 (0-4)。
實際的計算過程為:
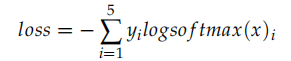
比如 logits 是 [0,1,2,3,4],真實分類是 3,那么上式就是:
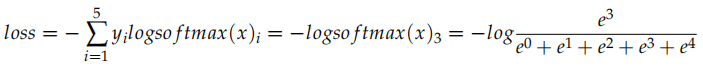
因此我們也可以使用 NLLLoss() 配合 F.log_softmax 函數 (或者nn.LogSoftmax,這不是一個函數而是一個 Module 了) 來實現一樣的效果:

NLLLoss(Negative Log Likelihood Loss) 是計算負 log 似然損失。它輸入的 x 是log_softmax 之后的結果 (長度為 5 的數組),y 是真實分類 (0-4),輸出就是 x[y]。因此上面的代碼
Transformer 模型也是遵循上面的架構,只不過它的 Encoder 是 N(6) 個 EncoderLayer 組成,每個 EncoderLayer 包含一個 Self-Attention SubLayer 層和一個全連接SubLayer 層。而它的 Decoder 也是 N(6) 個 DecoderLayer 組成,每個 DecoderLayer包含一個 Self-Attention SubLayer 層、Attention SubLayer 層和全連接 SubLayer 層。如圖17.26所示。
Encoder 和 Decoder Stack
前面說了 Encoder 和 Decoder 都是由 N 個相同結構的 Layer 堆積 (stack) 而成。因此我們首先定義 clones 函數,用于克隆相同的 SubLayer。

這里使用了 nn.ModuleList,ModuleList 就像一個普通的 Python 的 List,我們可以使用下標來訪問它,它的好處是傳入的 ModuleList 的所有 Module 都會注冊的PyTorch 里,這樣 Optimizer 就能找到這里面的參數,從而能夠用梯度下降更新這些參數。但是 nn.ModuleList 并不是 Module(的子類),因此它沒有 forward 等方法,我們通常把它放到某個 Module 里。
接下來我們定義 Encoder:
class Encoder(nn.Module):
"Encoder是N個EncoderLayer的stack"
def __init__(self, layer, N):
super(Encoder, self).__init__()
# layer是一個SubLayer,我們clone N個
self.layers = clones(layer, N)
# 再加一個LayerNorm層
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"逐層進行處理"
for layer in self.layers:
x = layer(x, mask)
# 最后進行LayerNorm,后面會解釋為什么最后還有一個LayerNorm。
return self.norm(x)
Encoder 就是 N 個 SubLayer 的 stack,最后加上一個 LayerNorm。我們來看 Layer-Norm:
classLayerNorm(nn.Module):
def__init__(self, features, eps=1e-6):
super(LayerNorm,self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
defforward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
returnself.a_2 * (x - mean) / (std + self.eps) + self.b_2
LayerNorm 我們以前介紹過,代碼也很簡單,這里就不詳細介紹了。注意 LayerNormalization 不是 Batch Normalization。
如圖17.26所示,原始論文的模型為:
x -> attention(x) -> x+self-attention(x) -> layernorm(x+self-attention(x))
=> y
y -> dense(y) -> y+dense(y) -> layernorm(y+dense(y)) => z(輸入下一層)
這里稍微做了一點修改,在 self-attention 和 dense 之后加了一個 dropout 層。另外一個不同支持就是把 layernorm 層放到前面了。這里的模型為:
x -> layernorm(x) -> attention(layernorm(x)) -> x + attention(layernorm(x))=> y
y -> layernorm(y) -> dense(layernorm(y)) -> y+dense(layernorm(y))
原始論文的 layernorm 放在最后;而這里把它放在最前面并且在 Encoder 的最后一層再加了一個 layernorm,因此這里的實現和論文的實現基本是一致的,只是給最底層的輸入 x 多做了一個 layernorm,而原始論文是沒有的。下面是 Encoder 的forward 方法,這樣對比讀者可能會比較清楚為什么 N 個EncoderLayer 處理完成之后還需要一個 LayerNorm。
def forward(self, x, mask):
"逐層進行處理"
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
不管是 Self-Attention 還是全連接層,都首先是 LayerNorm,然后是 Self-Attention/Dense,然后是 Dropout,最好是殘差連接。這里面有很多可以重用的代碼,我們把它封裝成 SublayerConnection。
class SublayerConnection(nn.Module):
"""
LayerNorm + sublayer(Self-Attenion/Dense) + dropout + 殘差連接
為了簡單,把LayerNorm放到了前面,這和原始論文稍有不同,原始論文LayerNorm在最后。
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"sublayer是傳入的參數,參考DecoderLayer,它可以當成函數調用,這個函數的有一個輸入參數"
return x + self.dropout(sublayer(self.norm(x)))
這個類會構造 LayerNorm 和 Dropout,但是 Self-Attention 或者 Dense 并不在這里構造,還是放在了 EncoderLayer 里,在 forward 的時候由 EncoderLayer 傳入。這樣的好處是更加通用,比如 Decoder 也是類似的需要在 Self-Attention、Attention 或者 Dense 前面后加上 LayerNorm 和 Dropout 以及殘差連接,我們就可以復用代碼。但是這里要求傳入的 sublayer 可以使用一個參數來調用的函數 (或者有 __call__)。
有了這些代碼之后,EncoderLayer 就很簡單了:
class EncoderLayer(nn.Module):
"EncoderLayer由self-attn和feed forward組成"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
為了復用,這里的 self_attn 層和 feed_forward 層也是傳入的參數,這里只構造兩個 SublayerConnection。forward 調用 sublayer[0](SublayerConnection) 的 __call__方法,最終會調到它的 forward 方法,而這個方法需要兩個參數,一個是輸入 Tensor,一個是一個 callable,并且這個 callable 可以用一個參數來調用。而 self_attn 函數需要 4 個參數 (Query 的輸入,Key 的輸入,Value 的輸入和 Mask),因此這里我們使用lambda 的技巧把它變成一個參數 x 的函數 (mask 可以看成已知的數)。因為 lambda的形參也叫 x,讀者可能難以理解,我們改寫一下:
def forward(self, x, mask):
z = lambda y: self.self_attn(y, y, y, mask)
x = self.sublayer[0](x, z)
return self.sublayer[1](x, self.feed_forward)
self_attn 有 4 個參數,但是我們知道在 Encoder 里,前三個參數都是輸入 y,第四個參數是 mask。這里 mask 是已知的,因此我們可以用 lambda 的技巧它變成一個參數的函數 z = lambda y: self.self_attn(y, y, y, mask),這個函數的輸入是 y。
self.sublayer[0] 是個 callable,self.sublayer[0](x, z) 會調用 self.sublayer[0].__call__(x,z),然后會調用 SublayerConnection.forward(x, z),然后會調用 sublayer(self.norm(x)),sublayer 就是傳入的參數 z,因此就是 z(self.norm(x))。z 是一個 lambda,我們可以先簡單的看成一個函數,顯然這里要求函數 z 的輸入是一個參數。
理解了 Encoder 之后,Decoder 就很簡單了。
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
Decoder 也是 N 個 DecoderLayer 的 stack,參數 layer 是 DecoderLayer,它也是一個callable,最終 __call__ 會調用 DecoderLayer.forward 方法,這個方法 (后面會介紹)需要 4 個參數,輸入 x,Encoder 層的輸出 memory,輸入 Encoder 的 Mask(src_mask)和輸入 Decoder 的 Mask(tgt_mask)。所有這里的 Decoder 的 forward 也需要這 4 個參數。
class DecoderLayer(nn.Module):
"Decoder包括self-attn, src-attn, 和feed forward "
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
DecoderLayer 比 EncoderLayer 多了一個 src-attn 層,這是 Decoder 時 attend toEncoder 的輸出 (memory)。src-attn 和 self-attn 的實現是一樣的,只不過使用的Query,Key 和 Value 的輸入不同。普通的 Attention(src-attn) 的 Query 是下層輸入進來的 (來自 self-attn 的輸出),Key 和 Value 是 Encoder 最后一層的輸出 memory;而 Self-Attention 的 Query,Key 和 Value 都是來自下層輸入進來的。
Decoder 和 Encoder 有一個關鍵的不同:Decoder 在解碼第 t 個時刻的時候只能使用 1...t 時刻的輸入,而不能使用 t+1 時刻及其之后的輸入。因此我們需要一個函數來產生一個 Mask 矩陣,代碼如下:
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
我們閱讀代碼之前先看它的輸出:
print(subsequent_mask(5))
# 輸出
1 0 0 0 0
1 1 0 0 0
1 1 1 0 0
1 1 1 1 0
1 1 1 1 1
我們發現它輸出的是一個方陣,對角線和下面都是 1。第一行只有第一列是 1,它的意思是時刻 1 只能 attend to 輸入 1,第三行說明時刻 3 可以 attend to 1,2,3 而不能attend to4,5 的輸入,因為在真正 Decoder 的時候這是屬于 Future 的信息。知道了這個函數的用途之后,上面的代碼就很容易理解了。代碼首先使用 triu 產生一個上三角陣:
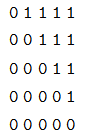
然后需要把 0 變成 1,把 1 變成 0,這可以使用 matrix == 0 來實現。
###MultiHeadedAttention
Attention(包括 Self-Attention 和普通的 Attention) 可以看成一個函數,它的輸入是Query,Key,Value 和 Mask,輸出是一個 Tensor。其中輸出是 Value 的加權平均,而權重來自 Query 和 Key 的計算。
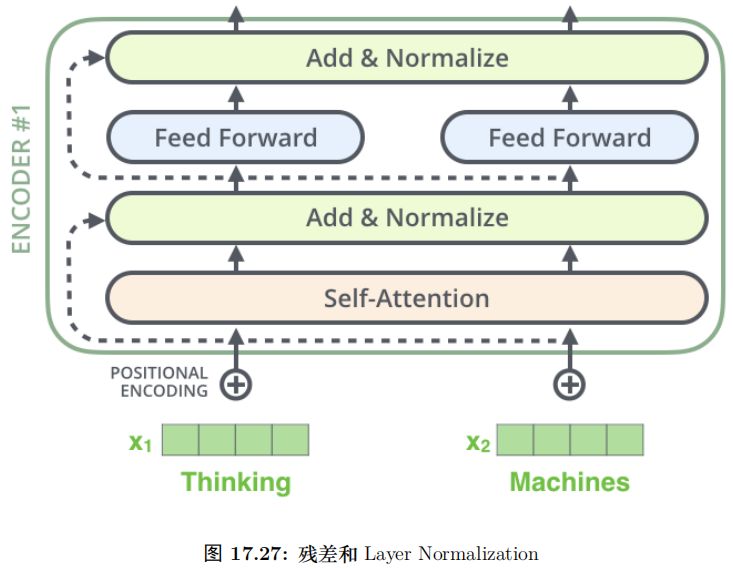
具體的計算如圖17.27所示,計算公式為:
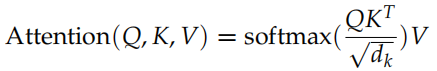
代碼為:
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
我們使用一個實際的例子跟蹤一些不同 Tensor 的 shape,然后對照公式就很容易理解。比如 Q 是 (30,8,33,64),其中 30 是 batch,8 是 head 個數,33 是序列長度,64 是每個時刻的特征數。K 和 Q 的 shape 必須相同的,而 V 可以不同,但是這里的實現 shape 也是相同的。
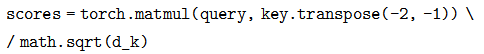
上面的代碼實現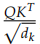 ,和公式里稍微不同的是,這里的 Q 和 K 都是 4d 的 Tensor,包括 batch 和 head 維度。matmul 會把 query 和 key 的最后兩維進行矩陣乘法,這樣效率更高,如果我們要用標準的矩陣 (二維 Tensor) 乘法來實現,那么需要遍歷 batch維和 head 維:
,和公式里稍微不同的是,這里的 Q 和 K 都是 4d 的 Tensor,包括 batch 和 head 維度。matmul 會把 query 和 key 的最后兩維進行矩陣乘法,這樣效率更高,如果我們要用標準的矩陣 (二維 Tensor) 乘法來實現,那么需要遍歷 batch維和 head 維:

而上面的寫法一次完成所有這些循環,效率更高。輸出的 score 是 (30, 8, 33, 33),前面兩維不看,那么是一個 (33, 33) 的 attention 矩陣 a,aij 表示時刻 i attend to j 的得分 (還沒有經過 softmax 變成概率)。
接下來是 scores.masked_fill(mask == 0, -1e9),用于把 mask 是 0 的變成一個很小的數,這樣后面經過 softmax 之后的概率就很接近零 (但是理論上還是用來很少一點點未來的信息)。
這里 mask 是 (30, 1, 1, 33) 的 tensor,因為 8 個 head 的 mask 都是一樣的,所有第二維是 1,masked_fill 時使用 broadcasting 就可以了。這里是 self-attention 的mask,所以每個時刻都可以 attend 到所有其它時刻,所有第三維也是 1,也使用broadcasting。如果是普通的 mask,那么 mask 的 shape 是 (30, 1, 33, 33)。這樣講有點抽象,我們可以舉一個例子,為了簡單,我們假設 batch=2, head=8。
第一個序列長度為 3,第二個為 4,那么 self-attention 的 mask 為 (2, 1, 1, 4),我們可以用兩個向量表示:
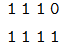
它的意思是在 self-attention 里,第一個序列的任一時刻可以 attend to 前 3 個時刻(因為第 4 個時刻是 padding 的);而第二個序列的可以 attend to 所有時刻的輸入。而 Decoder 的 src-attention 的 mask 為 (2, 1, 4, 4),我們需要用 2 個矩陣表示:
第一個序列的mask矩陣
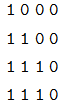
第二個序列的mask矩陣
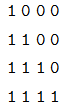
接下來對 score 求 softmax,把得分變成概率 p_attn,如果有 dropout 還對p_attn 進行 Dropout(這也是原始論文沒有的)。最后把 p_attn 和 value 相乘。p_attn是 (30, 8, 33, 33),value 是 (30, 8, 33, 64),我們只看后兩維,(33x33) x (33x64) 最終得到 33x64。
接下來就是輸入怎么變成 Q,K 和 V 了,我們之前介紹過,對于每一個 Head,都使用三個矩陣 WQ, WK, WV 把輸入轉換成 Q,K 和 V。然后分別用每一個 Head 進行 Self-Attention 的計算,最后把 N 個 Head 的輸出拼接起來,最后用一個矩陣 WO把輸出壓縮一下。具體計算過程為:
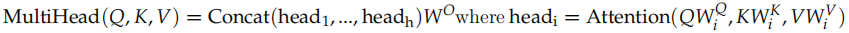
其中,
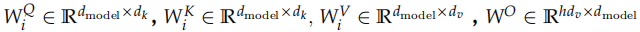
在這里,我們的 Head 個數 h=8,dk = dv = dmodel/h = 64。
詳細結構如圖17.28所示,輸入 Q,K 和 V 經過多個線性變換后得到 N(8) 組Query,Key 和 Value,然后使用 Self-Attention 計算得到 N 個向量,然后拼接起來,最后使用一個線性變換進行降維。
代碼如下:
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
# 所有h個head的mask都是相同的
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1)
首先使用線性變換,然后把d_model分配給h個Head,每個head為d_k=d_model/h
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x
in zip(self.linears, (query, key, value))]
# 2) 使用attention函數計算
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3)
把8個head的64維向量拼接成一個512的向量。然后再使用一個線性變換(512,521),shape不變。
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
我們先看構造函數,這里 d_model(512) 是 Multi-Head 的輸出大小,因為有 h(8)個 head,因此每個 head 的 d_k=512/8=64。接著我們構造 4 個 (d_model x d_model)的矩陣,后面我們會看到它的用處。最后是構造一個 Dropout 層。
然后我們來看 forward 方法。輸入的 mask 是 (batch, 1, time) 的,因為每個 head的 mask 都是一樣的,所以先用 unsqueeze(1) 變成 (batch, 1, 1, time),mask 我們前面已經詳細分析過了。
接下來是根據輸入 query,key 和 value 計算變換后的 Multi-Head 的 query,key和 value。這是通過下面的語句來實現的:
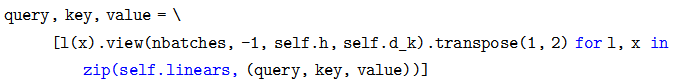
zip(self.linears, (query, key, value)) 是把(self.linears[0],self.linears[1],self.linears[2])和 (query, key, value) 放到一起然后遍歷。
我們只看一個 self.linears[0](query)。根據構造函數的定義self.linears[0] 是一個 (512, 512) 的矩陣,而 query 是 (batch, time,512),相乘之后得到的新 query 還是 512(d_model) 維的向量,然后用 view 把它變成(batch, time, 8, 64)。然后 transponse 成 (batch, 8,time,64),這是 attention 函數要求的 shape。分別對應 8 個 Head,每個 Head 的 Query 都是 64 維。
Key 和 Value 的運算完全相同,因此我們也分別得到 8 個 Head 的 64 維的 Key和 64 維的 Value。
接下來調用 attention 函數,得到 x 和 self.attn。其中 x 的 shape 是 (batch, 8,time, 64),而 attn 是 (batch, 8, time, time)。
x.transpose(1, 2) 把 x 變成 (batch, time, 8, 64),然后把它 view 成 (batch, time,512),其實就是把最后 8 個 64 維的向量拼接成 512 的向量。
最后使用 self.linears[-1] 對 x 進行線性變換,因為 self.linears[-1] 是 (512, 512) 的,因此最終的輸出還是 (batch, time, 512)。
我們最初構造了 4 個 (512, 512) 的矩陣,前 3 個用于對 query,key 和 value 進行變換,而最后一個對 8 個 head 拼接后的向量再做一次變換。
##MultiHeadedAttention 的應用
在 Transformer 里,有 3 個地方用到了 MultiHeadedAttention:
Encoder 的 Self-Attention 層里,query,key 和 value 都是相同的值,來自下層
的輸入。Mask 都是 1(當然 padding 的不算)。
Decoder 的 Self-Attention 層,query,key 和 value 都是相同的值,來自下層的輸入。但是 Mask 使得它不能訪問未來的輸入。
Encoder-Decoder 的普通 Attention,query 來自下層的輸入,而 key 和 value 相同,是 Encoder 最后一層的輸出,而 Mask 都是 1。
##全連接 SubLayer
除了 Attention 這個 SubLayer 之外,我們還有全連接的 SubLayer,每個時刻的全連接層是可以獨立并行計算的 (當然參數是共享的)。全連接層有兩個線性變換以及它們之間的 ReLU 激活組成:
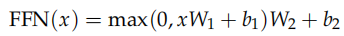
全連接層的輸入和輸出都是 d_model(512) 維的,中間隱單元的個數是 d_ff(2048)。代碼實現非常簡單:
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
在兩個線性變換之間除了 ReLu 還使用了一個 Dropout。
##Embedding 和 Softmax
輸入的詞序列都是 ID 序列,我們需要 Embedding。源語言和目標語言都需要Embedding,此外我們需要一個線性變換把隱變量變成輸出概率,這可以通過前面的類 Generator 來實現。我們這里實現 Embedding:

代碼非常簡單,唯一需要注意的就是 forward 處理使用 nn.Embedding 對輸入 x 進行Embedding 之外,還除以了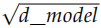 。
。
##Positional Encoding
位置編碼的公式為:
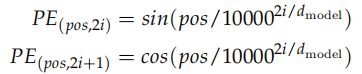
假設輸入是 ID 序列長度為 10,如果輸入 Embedding 之后是 (10, 512),那么位置編碼的輸出也是 (10, 512)。上式中 pos 就是位置 (0-9),512 維的偶數維使用 sin 函數,而奇數維使用 cos 函數。這種位置編碼的好處是: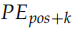 可以表示成 PEpos 的線性函數,這樣網絡就能容易的學到相對位置的關系。代碼為:
可以表示成 PEpos 的線性函數,這樣網絡就能容易的學到相對位置的關系。代碼為:
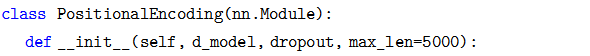
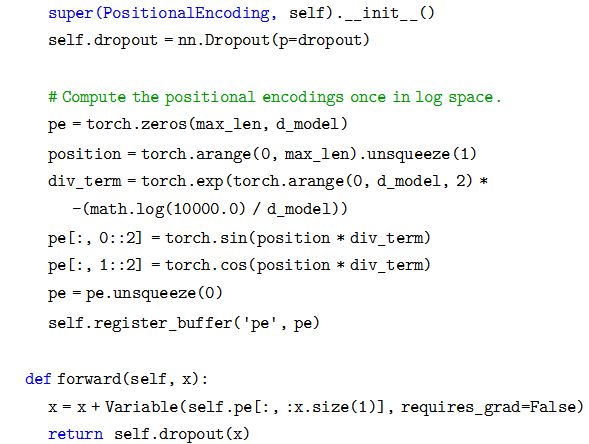
代碼細節請讀者對照公式,這里值得注意的是調用了 Module.register_buffer 函數。這個函數的作用是創建一個 buffer,比如這里把 pi 保存下來。
register_buffer通常用于保存一些模型參數之外的值,比如在 BatchNorm 中,我們需要保存 running_mean(Moving Average),它不是模型的參數 (不用梯度下降),但是模型會修改它,而且在預測的時候也要使用它。這里也是類似的,pe 是一個提前計算好的常量,我們在 forward 要用到它。我們在構造函數里并沒有把 pe 保存到 self 里,但是在forward 的時候我們卻可以直接使用它 (self.pe)。如果我們保存 (序列化) 模型到磁盤的話,PyTorch 框架也會幫我們保存 buffer 里的數據到磁盤,這樣反序列化的時候能恢復它們。
完整模型
構造完整模型的函數代碼如下:


首先把 copy.deepcopy 命名為 c,這樣使下面的代碼簡潔一點。然后構造 MultiHeadedAttention,PositionwiseFeedForward 和 PositionalEncoding 對象。接著就是構造 EncoderDecoder 對象。它需要 5 個參數:Encoder、Decoder、src-embed、tgt-embed和 Generator。
我們首先后面三個簡單的參數,Generator 直接構造就行了,它的作用是把模型的隱單元變成輸出詞的概率。而 src-embed 是一個 Embeddings 層和一個位置編碼層c(position),tgt-embed 也是類似的。
最后我們來看 Decoder(Encoder 和 Decoder 類似的)。Decoder 由 N 個 DecoderLayer 組成,而 DecoderLayer 需要傳入 self-attn, src-attn,全連接層和 Dropout。因為所有的 MultiHeadedAttention 都是一樣的,因此我們直接 deepcopy 就行;同理所有的 PositionwiseFeedForward 也是一樣的網絡結果,我們可以 deepcopy 而不要再構造一個。
訓練
在介紹訓練代碼前我們介紹一些Batch類。


Batch構造函數的輸入是src和trg,后者可以為None,因為再預測的時候是沒有tgt的。我們用一個例子來說明Batch的代碼,這是訓練階段的一個Batch,src是(48,20),48是batch大小,而20是最長的句子長度,其它的不夠長的都padding成20了。而trg是(48,25),表示翻譯后的最長句子是25個詞,不足的也 padding過了。
我們首先看src_mask怎么得到,(src!=pad)把src中大于0的時刻置為1,這
樣表示它可以 attendto的范圍。然后 unsqueeze(-2)把把src_mask變成(48/batch,1,20/time)。它的用法參考前面的attention函數。
對于訓練來說 (TeachingForcing模式),Decoder 有一個輸入和一個輸出。比如句子”
最終得到的 trg_mask 的 shape 是 (48/batch, 24, 24),表示 24 個時刻的 Mask矩陣,這是一個對角線以及之下都是1的矩陣,前面已經介紹過了。
注意src_mask的shape是(batch,1,time),而trg_mask是(batch,time,time)。
因為src_mask的每一個時刻都能attendto所有時刻(padding的除外),一次只需要一個向量就行了,而trg_mask需要一個矩陣。
訓練的代碼就非常簡單了,下面是訓練一個Epoch的代碼:


它遍歷一個 epoch 的數據,然后調用 forward,接著用 loss_compute 函數計算梯度,更新參數并且返回 loss。這里的 loss_compute 是一個函數,它的輸入是模型的預測 out,真實的標簽序列 batch.trg_y 和 batch 的詞個數。實際的實現是MultiGPULossCompute 類,這是一個 callable。本來計算損失和更新參數比較簡單,但是這里為了實現多 GPU 的訓練,這個類就比較復雜了。
MultiGPULossCompute
這里介紹了 Transformer 最核心的算法,這個代碼還包含了 Label Smoothing,BPE等技巧,有興趣的讀者可以自行閱讀,本書就不介紹了。
Skip Thought Vector
簡介
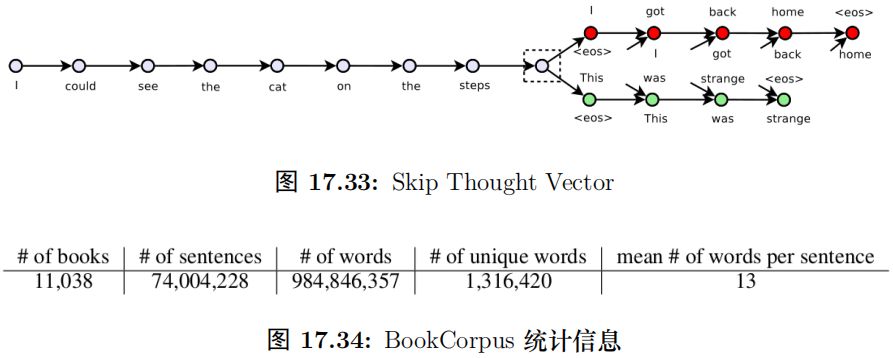
我們之前學習過 word2vec,其中一種模型是 Skip-Gram 模型,根據中心詞預測周圍的 (context) 詞,這樣我們可以學到詞向量。那怎么學習到句子向量呢?一種很自然想法就是用一個句子預測它周圍的句子,這就是 Skip Thought Vector 的思路。它需要有連續語義相關性的句子,比如論文中使用的書籍。一本書由很多句子組成,前后的句子是有關聯的。那么我們怎么用一個句子預測另一個句子呢?這可以使用Encoder-Decoder,類似于機器翻譯。比如一本書里有 3 個句子”I got back home”、”I could see the cat on the steps”和”This was strange”。我們想用中間的句子”I could see the cat on the steps.” 來預測前后兩個句子。
如圖15.83所示,輸入是句子”I could see the cat on the steps.”,輸出是兩個句子”Igot back home.” 和”This was strange.”。
我們首先用一個 Encoder(比如 LSTM 或者 GRU) 把輸入句子編碼成一個向量。而右邊是兩個 Decoder(我們任務前后是不對稱的,因此用兩個 Decoder)。因為我們不需要預測 (像機器翻譯那樣生成一個句子),所以我們只考慮 Decoder 的訓練。Decoder 的輸入是”
經過訓練之后,我們就得到了一個 Encoder(Decoder 不需要了)。給定一個新的句子,我們可以把它編碼成一個向量。這個向量可以用于下游 (down stream) 的任務,比如情感分類,語義相似度計算等等。
數據集
和訓練 Word2Vec 不同,Word2Vec 只需要提供句子,而 Skip Thought Vector 需要文章 (至少是段落)。論文使用的數據集是 BookCorpus(http://yknzhu.wixsite.com/mbweb),目前網站已經不提供下載鏈接了!
BookCorpus 的統計信息如圖15.84所示,有一萬多本書,七千多萬個句子。
模型
接下來我們介紹一些論文中使用的模型,注意這是 2015 年的論文,過去好幾年了,其實我們是可以使用更新的模型。但是基本的思想還是一樣的。Encoder 是一個 GRU。假設句子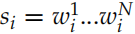 ,t 時刻的隱狀態是
,t 時刻的隱狀態是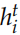 認為編碼了字符串
認為編碼了字符串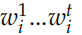 ?的語義,因此
?的語義,因此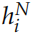 可以看成對整個句子語義的編碼。t 時刻 GRU 的計算公式為:
可以看成對整個句子語義的編碼。t 時刻 GRU 的計算公式為:
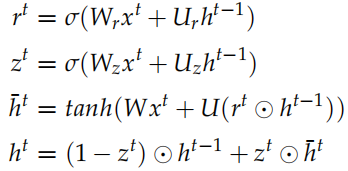
這就是標準的 GRU,其中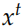 是
是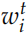 的Embedding 向量,
的Embedding 向量,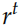 是重置 (reset) 門,
是重置 (reset) 門,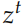 是更新 (update) 門,⊙ 是 element-wise 的乘法。
是更新 (update) 門,⊙ 是 element-wise 的乘法。
Decoder 是一個神經網絡語言模型。
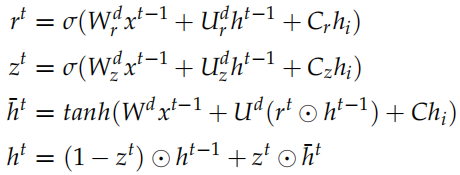
和之前我們在機器翻譯里介紹的稍微有一些區別。標準 Encoder-Decoder 里Decoder 每個時刻的輸入是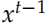 和
和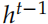 ,Decoder 的初始狀態設置為 Encoder 的輸出
,Decoder 的初始狀態設置為 Encoder 的輸出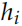 。而這里 Decodert 時刻的輸入除了
。而這里 Decodert 時刻的輸入除了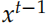 和
和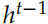
,還有 Encoder 的輸出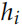 。
。
計算出 Decoder 每個時刻的隱狀態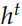 之后,我們在用一個矩陣 V 把它投影到詞的空間,輸出的是預測每個詞的概率分布。注意:預測前一個句子和后一個句子是兩個 GRU 模型,它們的參數是不共享的,但是投影矩陣 V 是共享的。當然輸入
之后,我們在用一個矩陣 V 把它投影到詞的空間,輸出的是預測每個詞的概率分布。注意:預測前一個句子和后一個句子是兩個 GRU 模型,它們的參數是不共享的,但是投影矩陣 V 是共享的。當然輸入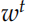 到
到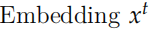 的 Embedding 矩陣也是共享的。和 Word2Vec 對比的話,V 是輸出向量 (矩陣) 而這個 Embedding(這里沒有起名字) 是輸入向量 (矩陣)。
的 Embedding 矩陣也是共享的。和 Word2Vec 對比的話,V 是輸出向量 (矩陣) 而這個 Embedding(這里沒有起名字) 是輸入向量 (矩陣)。
詞匯擴展
這篇論文還有一個比較重要的方法就是詞匯擴展。因為 BookCorpus 相對于訓練Word2Vec 等的語料來說還是太小,很多的詞都根本沒有在這個語料中出現,因此直接使用的話效果肯定不好。
本文使用了詞匯擴展的辦法。具體來說我們可以先用海量的語料訓練一個
Word2Vec,這樣可以把一個詞映射到一個語義空間,我們把這個向量叫作 Vw2v。而我們之前訓練的得到的輸入向量也是把一個詞映射到另外一個語義空間,我們記作Vrnn。
我們假設它們之間存在一個線性變換 f :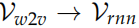 。這個線性變換的參數是矩陣 W,使得
。這個線性變換的參數是矩陣 W,使得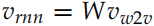 。那怎么求這個變換矩陣 W 呢?因為兩個訓練語料會有公共的詞 (通常訓練 word2vec 的語料比 skip vector 大得多,從而詞也多得多)。因此我們可以用這些公共的詞來尋找 W。尋找的依據是:遍歷所有可能的 W,使得Wvw2v 和 vrnn 盡量接近。用數學語言描述就是:
。那怎么求這個變換矩陣 W 呢?因為兩個訓練語料會有公共的詞 (通常訓練 word2vec 的語料比 skip vector 大得多,從而詞也多得多)。因此我們可以用這些公共的詞來尋找 W。尋找的依據是:遍歷所有可能的 W,使得Wvw2v 和 vrnn 盡量接近。用數學語言描述就是:
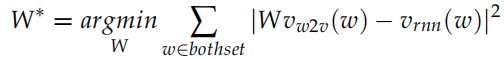
訓練細節
首先訓練了單向的 GRU,向量的維度是 2400,我們把它叫作 uni-skip 向量。此外還訓練了 bi-skip 向量,它是這樣得到的:首先訓練 1200 維的 uni-skip,然后句子倒過來,比如原來是”aa bb”、”cc dd” 和”ee ff”,我們是用”cc dd” 來預測”aa bb” 以及”eeff”,現在反過來變成”ff ee”、”dd cc” 和”bb aa”。這樣也可以訓練一個模型,當然也
就得到一個 encoder(兩個 decoder 不需要了),給定一個句子我們把它倒過來然后也編碼成 1200 為的向量,最后把這個兩個 1200 維的向量拼接成 2400 維的向量。模型訓練完成之后還需要進行詞匯擴展。通過 BookCorpus 學習到了 20,000 個詞,而 word2vec 共選擇了 930,911 詞,通過它們共同的詞學習出變換矩陣 W,從而使得我們的 Skip Thought Vector 可以處理 930,911 個詞。
實驗
為了驗證效果,本文把 Sentence Embedding 作為下游任務的輸入特征,任務包括分類 (情感分類),SNI(RTE) 等。前者的輸入是一個句子,而后者的輸入是兩個句子。
Semantic relatedness 任務
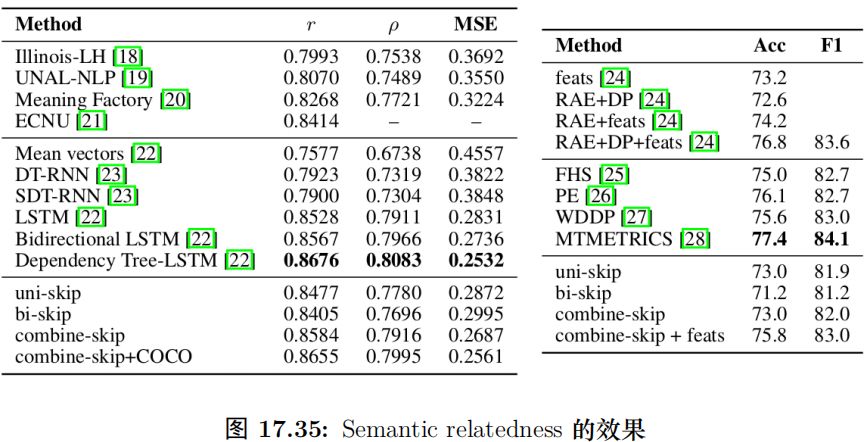
這里使用了 SICK(SemEval 2014 Task 1,給定兩個句子,輸出它們的語義相關性 1-5五個分類) 和 Microsoft Paraphrase Corpus(給定兩個句子,判斷它們是否一個意思/兩分類)。
它們的輸入是兩個句子,輸出是分類數。對于輸入的兩個句子,我們用 SkipThought Vector 把它們編碼成兩個向量 u 和 v,然后計算 u · v 與 |u ? v|,然后把它們拼接起來,最后接一個 logistic regression 層 (全連接加 softmax)。使用這么簡單的分類模型的原因是想看看 Sentence Embedding 是否能夠學習到復雜的非線性的語義關系。使用結果如圖15.85所示。可以看到效果還是非常不錯的,和 (當時) 最好的結果差別不大,而那些結果都是使用非常復雜的模型得到結果,而這里只使用了簡單的邏輯回歸模型。
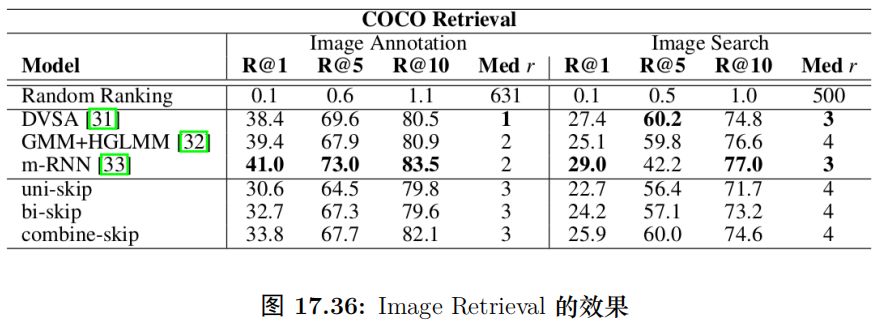
COCO 圖像檢索任務
這個任務的輸入是一幅圖片和一個句子,模型輸出的是它們的相關性 (句子是否描述了圖片的內容)。句子我們可以用 Skip Thought Vector 編碼成一個向量;而圖片也可以用預訓練的 CNN 編碼成一個向量。模型細節這里不再贅述了,最終的結果如圖15.86所示。
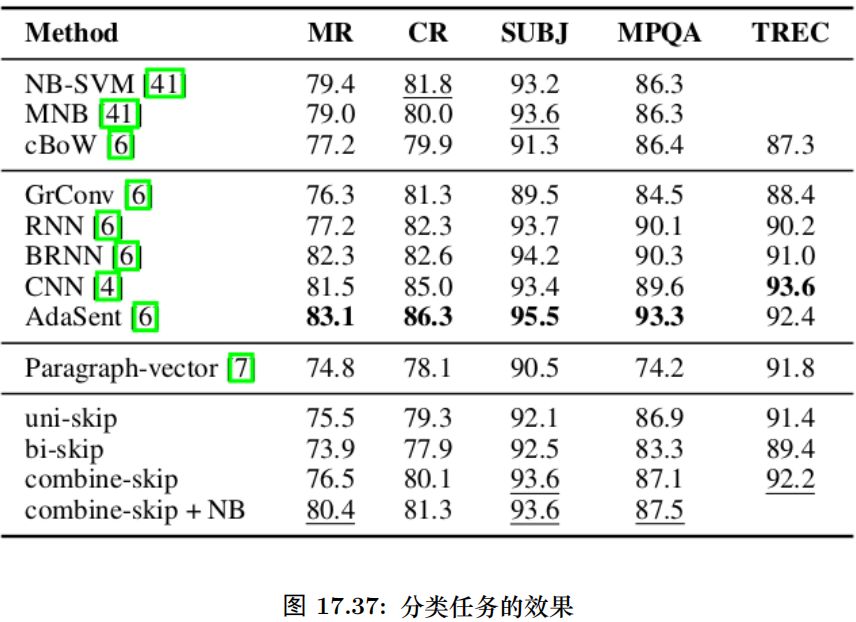
分類任務
這里比較了 5 個分類任務:電影評論情感分類 (MR), 商品評論情感分類 (CR) [37],主觀/客觀分類 (SUBJ) [38], 意見分類 (MPQA) 和 TREC 問題類型分類。結果如圖15.87所示。
ELMo
簡介
ELMo 是 Embeddings from Language Models 的縮寫,意思就是語言模型得到的 (句子)Embedding。另外 Elmo 是美國兒童教育電視節目芝麻街 (Sesame Street) 里的小怪獸15.88的名字。原始論文叫做《Deep contextualized word representations》。
這篇論文的想法其實非常非常簡單,但是取得了非常好的效果。它的思路是用深度的雙向 RNN(LSTM) 在大量未標注數據上訓練語言模型,如圖15.89所示。然后在實際的任務中,對于輸入的句子,我們使用這個語言模型來對它處理,得到輸出的向量,因此這可以看成是一種特征提取。但是和普通的 Word2Vec 或者 GloVe 的pretraining 不同,ELMo 得到的 Embedding 是有上下文的。比如我們使用 Word2Vec也可以得到詞”bank” 的 Embedding,我們可以認為這個 Embedding 包含了 bank 的語義。但是 bank 有很多意思,可以是銀行也可以是水邊,使用普通的 Word2Vec 作
為 Pretraining 的 Embedding,只能同時把這兩種語義都編碼進向量里,然后靠后面的模型比如 RNN 來根據上下文選擇合適的語義——比如上下文有 money,那么它更可能是銀行;而如果上下文是 river,那么更可能是水邊的意思。但是 RNN 要學到這種上下文的關系,需要這個任務有大量相關的標注數據,這在很多時候是沒有的。而ELMo 的特征提取可以看成是上下文相關的,如果輸入句子有 money,那么它就 (或者我們期望) 應該能知道 bank 更可能的語義,從而幫我們選擇更加合適的編碼。
無監督的預訓練
給定一個長度為 N 的句子,假設為 t1, t2, ..., tN,語言模型會計算給定 t1, ..., tk?1 的條件下出現 tk 的概率:
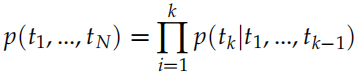
傳統的 N-gram 語言模型不能考慮很長的歷史,因此現在的主流是使用多層雙向的RNN(LSTM/GRU) 來實現語言模型。在每個時刻 k,RNN 的第 j 層會輸出一個隱狀態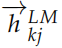 ,其中 j = 1, 2, ..., L,L 是 RNN 的層數。最上層是
,其中 j = 1, 2, ..., L,L 是 RNN 的層數。最上層是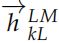 ,對它進行 softmax之后就可以預測輸出詞的概率。類似的,我們可以用一個反向的 RNN 來計算概率:
,對它進行 softmax之后就可以預測輸出詞的概率。類似的,我們可以用一個反向的 RNN 來計算概率:
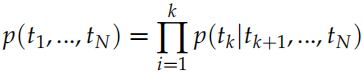
通過這個 RNN,我們可以得到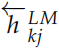 。我們把這兩個方向的 RNN 合并起來就得到 Bi-LSTM。我們優化的損失函數是兩個 LSTM 的交叉熵加起來是最小的:
。我們把這兩個方向的 RNN 合并起來就得到 Bi-LSTM。我們優化的損失函數是兩個 LSTM 的交叉熵加起來是最小的:
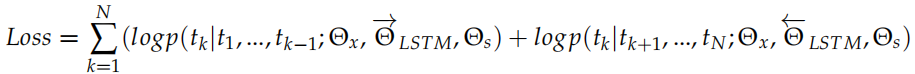
這兩個 LSTM 有各自的參數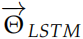 和
和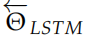 ,但是 word embedding 參數
,但是 word embedding 參數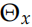 和 softmax 參數
和 softmax 參數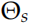 是共享的。
是共享的。
ELMo
ELMo 會根據不同的任務,把上面得到的雙向的 LSTM 的不同層的隱狀態組合起來。對于輸入的詞 tk,我們可以得到 2L+1 個向量,分別是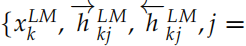 =1, 2, ..., L},我們把它記作
=1, 2, ..., L},我們把它記作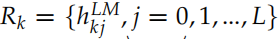 。其中
。其中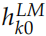 是詞的 Embedding,它與上下文無關,而其它的
是詞的 Embedding,它與上下文無關,而其它的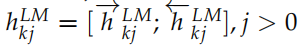 是把雙向的 LSTM 的輸出拼接起來的,它們與上下文相關的。
是把雙向的 LSTM 的輸出拼接起來的,它們與上下文相關的。
為了進行下游 (downstream) 的特定任務,我們會把不同層的隱狀態組合起來,組合的參數是根據特定任務學習出來的,公式如下:
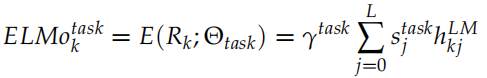
這里的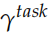 是一個縮放因子,而
是一個縮放因子,而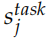 用于把不同層的輸出加權組合出來。在實際的任務中,RNN 的參數
用于把不同層的輸出加權組合出來。在實際的任務中,RNN 的參數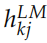 都是固定的,可以調的參數只是
都是固定的,可以調的參數只是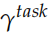
和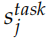 。當然這里 ELMo 只是一個特征提取,實際任務會再加上一些其它的網絡結構,那么那些參數也是一起調整的。
。當然這里 ELMo 只是一個特征提取,實際任務會再加上一些其它的網絡結構,那么那些參數也是一起調整的。
實驗結果
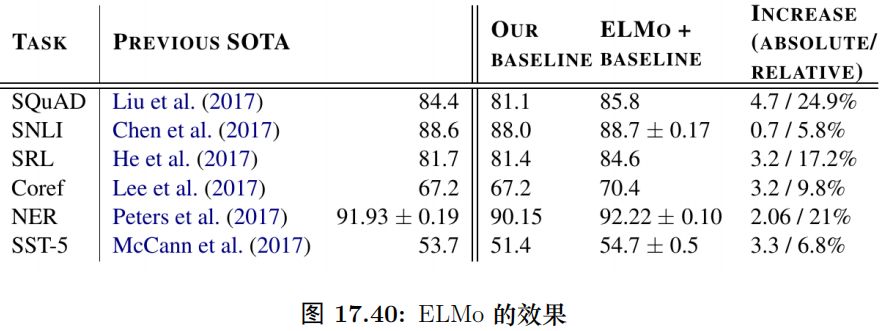
圖15.90是 ELMo 在 SQuAD、SNLI 等常見任務上的效果,相對于 Baseline 系統都有不小的提高。
-
函數
+關注
關注
3文章
4304瀏覽量
62429 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975 -
nlp
+關注
關注
1文章
487瀏覽量
22011
原文標題:詳解谷歌最強NLP模型BERT(理論+實戰)
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
圖解2018年領先的兩大NLP模型:BERT和ELMo
NLP領域取得最重大突破!BERT模型開啟了NLP的新時代!
BERT模型的PyTorch實現
用圖解的方式,生動易懂地講解了BERT和ELMo等模型
史上最強通用NLP模型誕生
谷歌大腦CMU聯手推出XLNet,20項任務全面超越BERT
圖解BERT預訓練模型!
基于BERT的中文科技NLP預訓練模型
如何使用BERT模型進行抽取式摘要
參天生長大模型:昇騰AI如何強壯模型開發與創新之根?
NLP入門之Bert的前世今生






 工商網監
工商網監
評論