") 淺談自然語言處理中的注意力機制
淺談自然語言處理中的注意力機制
01
寫在前面
近些年來,注意力機制一直頻繁的出現(xiàn)在目之所及的文獻或者博文中,可見在NLP中算得上是個相當流行的概念,事實也證明其在 NLP 領(lǐng)域散發(fā)出不小得作用。
這幾年的頂會 paper 就能看出這一點。本文深入淺出地介紹了近些年的自然語言中的注意力機制包括從起源、變體到評價指標方面。
據(jù) Lilian Weng 博主[1]總結(jié)以及一些資料顯示,Attention 機制最早應(yīng)該是在視覺圖像領(lǐng)域提出來的,這方面的工作應(yīng)該很多,歷史也比較悠久。
人類的視覺注意力雖然存在很多不同的模型,但它們都基本上歸結(jié)為給予需要重點關(guān)注的目標區(qū)域(注意力焦點)更重要的注意力,同時給予周圍的圖像低的注意力,然后隨著時間的推移調(diào)整焦點。
而直到 Bahdanau 等人[3]發(fā)表了論文《Neural Machine Translation by Jointly Learning to Align and Translate》,該論文使用類似 Attention 的機制在機器翻譯任務(wù)上將翻譯和對齊同時進行。
這個工作目前是最被認可為是第一個提出Attention 機制應(yīng)用到 NLP 領(lǐng)域中的工作,值得一提的是,該論文2015年被 ICLR 錄用,截至現(xiàn)在,谷歌引用量為5596,可見后續(xù)nlp在這一塊的研究火爆程度。
注意力機制首先從人類直覺中得到,在nlp領(lǐng)域的機器翻譯任務(wù)上首先取得不錯的效果。簡而言之,深度學(xué)習(xí)中的注意力可以廣義地解釋為重要性權(quán)重的向量:
為了預(yù)測一個元素,例如句子中的單詞,使用注意力向量來估計它與其他元素的相關(guān)程度有多強,并將其值的總和作為目標的近似值。
既然注意力機制最早在 NLP 領(lǐng)域應(yīng)用于機器翻譯任務(wù),那在這個之前又是怎么做的呢?
傳統(tǒng)的基于短語的翻譯系統(tǒng)通過將源句分成多個塊然后逐個詞地翻譯它們來完成它們的任務(wù),這導(dǎo)致了翻譯輸出的不流暢。
不妨先來想想我們?nèi)祟愂侨绾畏g的?我們首先會閱讀整個待翻譯的句子,然后結(jié)合上下文理解其含義,最后產(chǎn)生翻譯。
從某種程度上來說,神經(jīng)機器翻譯(NMT)的提出正是想去模仿這一過程。而在NMT的翻譯模型中經(jīng)典的做法是由編碼器 - 解碼器架構(gòu)制定(encoder-decoder),用作 encoder 和 decoder 常用的是循環(huán)神經(jīng)網(wǎng)絡(luò)。
這類模型大概過程是首先將源句子的輸入序列送入到編碼器中,提取最后隱藏狀態(tài)的表示并用于解碼器的輸入,然后一個接一個地生成目標單詞,這個過程廣義上可以理解為不斷地將前一個時刻 t-1 的輸出作為后一個時刻 t 的輸入,循環(huán)解碼,直到輸出停止符為止。
通過這種方式,NMT解決了傳統(tǒng)的基于短語的方法中的局部翻譯問題:它可以捕獲語言中的長距離依賴性,并提供更流暢的翻譯。
但是這樣做也存在很多缺點,譬如,RNN 是健忘的,這意味著前面的信息在經(jīng)過多個時間步驟傳播后會被逐漸消弱乃至消失。
其次,在解碼期間沒有進行對齊操作,因此在解碼每個元素的過程中,焦點分散在整個序列中。對于前面那個問題,LSTM、GRU 在一定程度能夠緩解。而后者正是 Bahdanau 等人重視的問題。
02
Seq2Seq 模型
在介紹注意力模型之前,不得不先學(xué)習(xí)一波 Encoder-Decoder 框架,雖然說注意力模型可以看作一種通用的思想,本身并不依賴于特定框架(比如文章[15]:Learning Sentence Representation with Guidance of Human Attention),但是目前大多數(shù)注意力模型都伴隨在 Encoder-Decoder 框架下。
Seq2seq 模型最早由 bengio 等人[17]論文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》。
隨后 Sutskever 等人[16]在文章《Sequence to Sequence Learning with Neural Networks》中提出改進模型即為目前常說的 Seq2Seq 模型。
從廣義上講,它的目的是將輸入序列(源序列)轉(zhuǎn)換為新的輸出序列(目標序列),這種方式不會受限于兩個序列的長度,換句話說,兩個序列的長度可以任意。
以 NLP 領(lǐng)域來說,序列可以是句子、段落、篇章等,所以我們也可以把它看作處理由一個句子(段落或篇章)生成另外一個句子(段落或篇章)的通用處理模型。
對于句子對,我們期望輸入句子 Source,期待通過 Encoder-Decoder 框架來生成目標句子Target。
Source 和 Target 可以是同一種語言,也可以是兩種不同的語言,若是不同語言,就可以處理翻譯問題了。
若是相同語言,輸入序列 Source 長度為篇章,而目標序列 Target 為小段落則可以處理文本摘要問題 (目標序列 Target 為句子則可以處理標題生成問題)等等等。
seq2seq 模型通常具有編碼器 - 解碼器架構(gòu):
編碼器 encoder: 編碼器處理輸入序列并將序列信息壓縮成固定長度的上下文向量(語義編碼/語義向量 context)。期望這個向量能夠比較好的表示輸入序列的信息。
解碼器 decoder: 利用上下文向量初始化解碼器以得到變換后的目標序列輸出。早期工作僅使用編碼器的最后狀態(tài)作為解碼器的輸入。
編碼器和解碼器都是循環(huán)神經(jīng)網(wǎng)絡(luò),比較常見的是使用 LSTM 或 GRU。
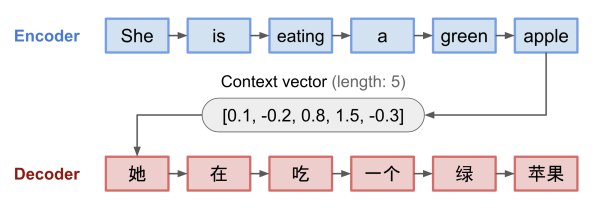
編碼器 - 解碼器模型
03
NLP 中注意力機制的起源
前面談到在 Seq2Seq 結(jié)構(gòu)中,encoder 把所有的輸入序列都編碼成一個統(tǒng)一的語義向量 context,然后再由 decoder 解碼。而 context 自然也就成了限制模型性能的瓶頸。
譬如機器翻譯問題,當要翻譯的句子較長時,一個 context 可能存不下那么多信息。除此之外,只用編碼器的最后一個隱藏層狀態(tài),感覺上都不是很合理。
實際上當我們翻譯一個句子的時候,譬如:Source: 機器學(xué)習(xí)-->Target: machine learning。當decoder要生成"machine"的時候,應(yīng)該更關(guān)注"機器",而生成"learning"的時候,應(yīng)該給予"學(xué)習(xí)"更大的權(quán)重。
所以如果要改進Seq2Seq結(jié)構(gòu),一個不錯的想法自然就是利用 encoder 所有隱藏層狀態(tài)解決 context 限制問題。
Bahdanau等人[3]把 attention 機制用到了神經(jīng)網(wǎng)絡(luò)機器翻譯(NMT)上。傳統(tǒng)的 encoder-decoder 模型通過 encoder 將 Source 序列編碼到一個固定維度的中間語義向量 context,然后再使用 decoder 進行解碼翻譯到目標語言序列。
前面談到了這種做法的局限性,而且,Bahdanau 等人[3]在其文章的摘要中也說到這個 context 可能是提高這種基本編碼器 - 解碼器架構(gòu)性能的瓶頸,那 Bahdanau 等人又是如何嘗試緩解這個問題的呢? 別急,讓我們來一探究竟。
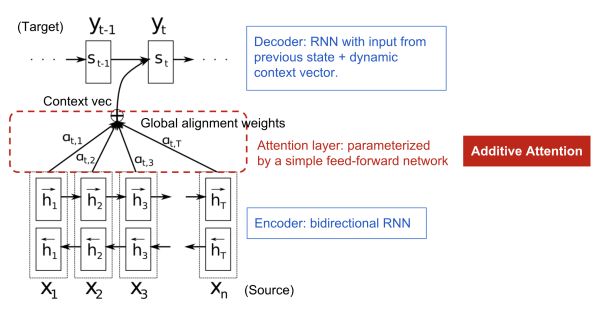
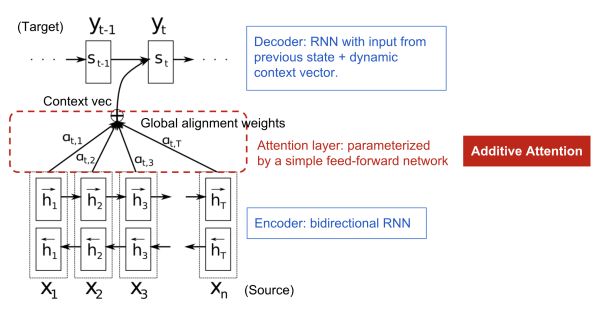
作者為了緩解中間向量 context 很難將 Source 序列所有重要信息壓縮進來的問題,特別是對于那些很長的句子。提出在機器翻譯任務(wù)上在 encoder–decoder 做出了如下擴展:將翻譯和對齊聯(lián)合學(xué)習(xí)。
這個操作在生成 Target 序列的每個詞時,用到的中間語義向量context是Source序列通過 encoder 的隱藏層的加權(quán)和,而傳統(tǒng)的做法是只用 encoder 最后一個時刻輸出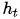 作為 context,這樣就能保證在解碼不同詞的時候,Source 序列對現(xiàn)在解碼詞的貢獻是不一樣的。
作為 context,這樣就能保證在解碼不同詞的時候,Source 序列對現(xiàn)在解碼詞的貢獻是不一樣的。
想想前面那個例子:Source: 機器學(xué)習(xí)-->Target: machine learning (假如中文按照字切分)。
decoder 在解碼"machine"時,"機"和"器"提供的權(quán)重要更大一些,同樣,在解碼"learning"時,"學(xué)"和"習(xí)"提供的權(quán)重相應(yīng)的會更大一些,這在直覺也和人類翻譯也是一致的。
通過這種 attention的 設(shè)計,作者將 Source 序列的每個詞(通過encoder的隱藏層輸出)和 Target 序列 (當前要翻譯的詞) 的每個詞巧妙的建立了聯(lián)系。
想一想,翻譯每個詞的時候,都有一個語義向量,而這個語義向量是Source序列每個詞通過 encoder 之后的隱藏層的加權(quán)和。
由此可以得到一個 Source 序列和 Target序列的對齊矩陣,通過可視化這個矩陣,可以看出在翻譯一個詞的時候,Source 序列的每個詞對當前要翻譯詞的重要性分布,這在直覺上也能給人一種可解釋性的感覺。
論文中的圖也能很好的看出這一點:
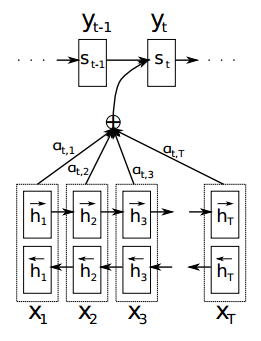
生成第t個目標詞
更形象一點可以看這個圖:
現(xiàn)在讓我們從公式層面來看看這個東東 (加粗變量表示它們是向量,這篇文章中的其他地方也一樣)。 假設(shè)我們有一個長度為n的源序列x,并嘗試輸出長度為m的目標序列y:
作者采樣bidirectional RNN作為encoder(實際上這里可以有很多選擇),具有前向隱藏狀態(tài)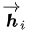 和后向隱藏狀態(tài)
和后向隱藏狀態(tài)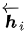 。為了獲得詞的上下文信息,作者采用簡單串聯(lián)方式將前向和后向表示拼接作為encoder的隱藏層狀態(tài),公式如下:
。為了獲得詞的上下文信息,作者采用簡單串聯(lián)方式將前向和后向表示拼接作為encoder的隱藏層狀態(tài),公式如下:
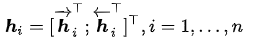
對于目標(輸出)序列的每個詞(假設(shè)位置為t),decoder網(wǎng)絡(luò)的隱藏層狀態(tài):
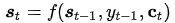
其中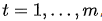 ,語義向量
,語義向量 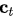 是源(輸入)序列的隱藏狀態(tài)的加權(quán)和,權(quán)重為對齊分數(shù):
是源(輸入)序列的隱藏狀態(tài)的加權(quán)和,權(quán)重為對齊分數(shù):
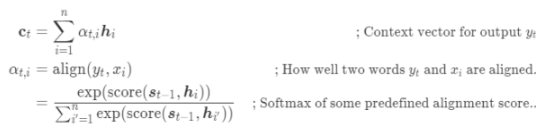
(注意:這里的score函數(shù)為原文的a函數(shù),原文的描述為: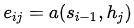 is an alignment model)
is an alignment model)
對齊模型基于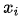 (在i時刻的輸入)和
(在i時刻的輸入)和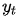 (在t時刻的輸出)的匹配程度分配分數(shù)
(在t時刻的輸出)的匹配程度分配分數(shù)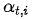 。
。
在Bahdanau[3]的論文中,作者采用的對齊模型為前饋神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)與所提出的系統(tǒng)的所有其他組件共同訓(xùn)練。因此,score函數(shù)采用以下形式,tanh用作非線性激活函數(shù),公式如下:
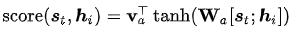
其中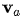 ,
,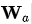 和都是在對齊模型中學(xué)習(xí)的權(quán)重矩陣。對齊分數(shù)矩陣是一個很好的可解釋性的東東,可以明確顯示源詞和目標詞之間的相關(guān)性。
和都是在對齊模型中學(xué)習(xí)的權(quán)重矩陣。對齊分數(shù)矩陣是一個很好的可解釋性的東東,可以明確顯示源詞和目標詞之間的相關(guān)性。
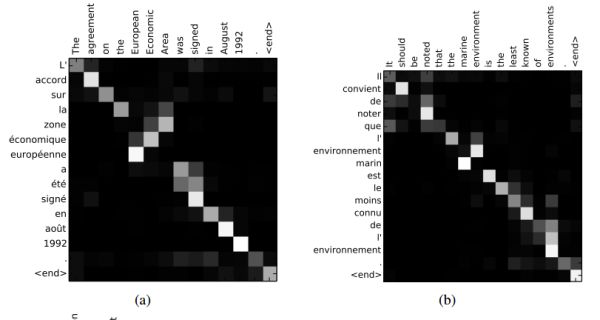
對齊矩陣例子
而decoder每個詞的條件概率為:
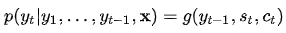
g為非線性的,可能是多層的輸出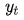 概率的函數(shù),
概率的函數(shù),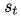 是RNN的隱藏狀態(tài),
是RNN的隱藏狀態(tài), 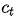 為語義向量。
為語義向量。
04
NLP中的注意力機制
隨著注意力機制的廣泛應(yīng)用,在某種程度上緩解了源序列和目標序列由于距離限制而難以建模依賴關(guān)系的問題。現(xiàn)在已經(jīng)涌現(xiàn)出了一大批基于基本形式的注意力的不同變體來處理更復(fù)雜的任務(wù)。讓我們一起來看看其在不同NLP問題中的注意力機制。
其實我們可能已經(jīng)意識到了,對齊模型的設(shè)計不是唯一的,確實,在某種意義上說,根據(jù)不同的任務(wù)設(shè)計適應(yīng)于特定任務(wù)的對齊模型可以看作設(shè)計出了新的attention變體,讓我們再回過頭來看看這個對齊模型(函數(shù)):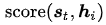 。再來看看幾個代表性的work。
。再來看看幾個代表性的work。
Citation[5]等人提出Content-base attention,其對齊函數(shù)模型設(shè)計為:
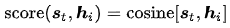
Bahdanau[3]等人的Additive(*),其設(shè)計為:
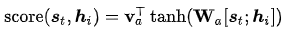
Luong[4]等人文獻包含了幾種方式:
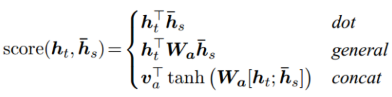
以及Luong[4]等人還嘗試過location-based function: 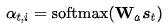
這種方法的對齊分數(shù)僅從目標隱藏狀態(tài)學(xué)習(xí)得到。
Vaswani[6]等人的Scaled Dot-Product(^):
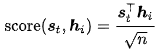
細心的童鞋可能早就發(fā)現(xiàn)了這東東和點積注意力很像,只是加了個scale factor。當輸入較大時,softmax函數(shù)可能具有極小的梯度,難以有效學(xué)習(xí),所以作者加入比例因子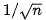 。
。
Cheng[7]等人的Self-Attention(&)可以關(guān)聯(lián)相同輸入序列的不同位置。 從理論上講,Self-Attention可以采用上面的任何 score functions。在一些文章中也稱為“intra-attention” 。
Hu[7]對此分了個類:

前面談到的一些Basic Attention給人的感覺能夠從序列中根據(jù)權(quán)重分布提取重要元素。而Multi-dimensional Attention能夠捕獲不同表示空間中的term之間的多個交互,這一點簡單的實現(xiàn)可以通過直接將多個單維表示堆疊在一起構(gòu)建。
Wang[8]等人提出了coupled multi-layer attentions,該模型屬于多層注意力網(wǎng)絡(luò)模型。作者稱,通過這種多層方式,該模型可以進一步利用術(shù)語之間的間接關(guān)系,以獲得更精確的信息。
05
Hierarchical Attention
再來看看Hierarchical Attention,Yang[9]等人提出了Hierarchical Attention Networks,看下面的圖可能會更直觀:
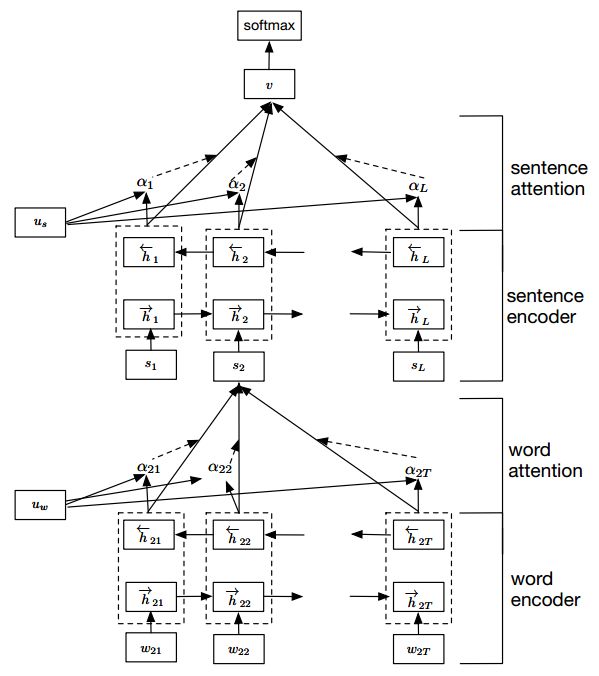
Hierarchical Attention Networks
這種結(jié)構(gòu)能夠反映文檔的層次結(jié)構(gòu)。模型在單詞和句子級別分別設(shè)計了兩個不同級別的注意力機制,這樣做能夠在構(gòu)建文檔表示時區(qū)別地對待這些內(nèi)容。
Hierarchical attention 可以相應(yīng)地構(gòu)建分層注意力,自下而上(即,詞級到句子級)或自上而下(詞級到字符級),以提取全局和本地的重要信息。
自下而上的方法上面剛談完。那么自上而下又是如何做的呢?讓我們看看Ji[10]等人的模型:
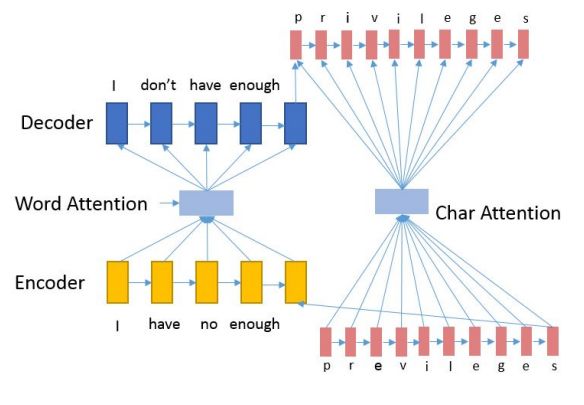
Nested Attention Hybrid Model
和機器翻譯類似,作者依舊采用encoder-decoder架構(gòu),然后用word-level attention對全局語法和流暢性糾錯,設(shè)計character-level attention對本地拼寫錯誤糾正。
06
Self-Attention
那Self-Attention又是指什么呢?
Self-Attention(自注意力),也稱為intra-attention(內(nèi)部注意力),是關(guān)聯(lián)單個序列的不同位置的注意力機制,以便計算序列的交互表示。它已被證明在很多領(lǐng)域十分有效比如機器閱讀,文本摘要或圖像描述生成。
比如Cheng[11]等人在機器閱讀里面利用了自注意力。當前單詞為紅色,藍色陰影的大小表示激活程度,自注意力機制使得能夠?qū)W習(xí)當前單詞和句子前一部分詞之間的相關(guān)性。

當前單詞為紅色,藍色陰影的大小表示激活程度
比如Xu[12]等人利用自注意力在圖像描述生成任務(wù)。注意力權(quán)重的可視化清楚地表明了模型關(guān)注的圖像的哪些區(qū)域以便輸出某個單詞。
我們假設(shè)序列元素為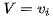 ,其匹配向量為
,其匹配向量為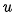 。讓我們再來回顧下前面說的基本注意力的對齊函數(shù),attention score通過
。讓我們再來回顧下前面說的基本注意力的對齊函數(shù),attention score通過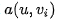 計算得到,由于是通過將外部u與每個元素
計算得到,由于是通過將外部u與每個元素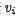 匹配來計算注意力,所以這種形式可以看作是外部注意力。
匹配來計算注意力,所以這種形式可以看作是外部注意力。
當我們把外部u替換成序列本身(或部分本身),這種形式就可以看作為內(nèi)部注意力(internal attention)。
我們根據(jù)文章[7]中的例子來看看這個過程,例如句子:"Volleyball match is in progress between ladies"。
句子中其它單詞都依賴著"match",理想情況下,我們希望使用自注意力來自動捕獲這種內(nèi)在依賴。
換句話說,自注意力可以解釋為,每個單詞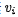 去和V序列中的內(nèi)部模式
去和V序列中的內(nèi)部模式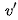 匹配,匹配函數(shù)
匹配,匹配函數(shù)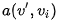 。
。
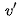 很自然的選擇為V中其它單詞
很自然的選擇為V中其它單詞 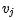 ,這樣遍可以計算成對注意力得分。為了完全捕捉序列中單詞之間的復(fù)雜相互作用,我們可以進一步擴展它以計算序列中每對單詞之間的注意力。這種方式讓每個單詞和序列中其它單詞交互了關(guān)系。
,這樣遍可以計算成對注意力得分。為了完全捕捉序列中單詞之間的復(fù)雜相互作用,我們可以進一步擴展它以計算序列中每對單詞之間的注意力。這種方式讓每個單詞和序列中其它單詞交互了關(guān)系。
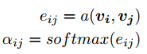
另一方面,自注意力還可以自適應(yīng)方式學(xué)習(xí)復(fù)雜的上下文單詞表示。譬如經(jīng)典文章[14]:A structured self-attentive sentence embedding。
這篇文章提出了一種通過引入自關(guān)注力機制來提取可解釋句子嵌入的新模型。 使用二維矩陣而不是向量來代表嵌入,矩陣的每一行都在句子的不同部分,想深入了解的可以去看看這篇文章,另外,文章的公式感覺真的很漂亮。
值得一提還有2017年谷歌提出的Transformer[6],這是一種新穎的基于注意力的機器翻譯架構(gòu),也是一個混合神經(jīng)網(wǎng)絡(luò),具有前饋層和自注意層。
論文的題目挺霸氣:Attention is All you Need,毫無疑問,它是2017年最具影響力和最有趣的論文之一。那這篇文章的Transformer的廬山真面目到底是這樣的呢?
這篇文章為提出許多改進,在完全拋棄了RNN的情況下進行seq2seq建模。接下來一起來詳細看看吧。
Key, Value and Query
眾所周知,在NLP任務(wù)中,通常的處理方法是先分詞,然后每個詞轉(zhuǎn)化為對應(yīng)的詞向量。接著一般最常見的有二類操作:
第一類是接RNN(變體LSTM、GRU、SRU等),但是這一類方法沒有擺脫時序這個局限,也就是說無法并行,也導(dǎo)致了在大數(shù)據(jù)集上的速度效率問題。
第二類是接CNN,CNN方便并行,而且容易捕捉到一些全局的結(jié)構(gòu)信息。很長一段時間都是以上二種的抉擇以及改造,直到谷歌提供了第三類思路:純靠注意力,也就是現(xiàn)在要講的這個東東。
將輸入序列編碼表示視為一組鍵值對(K,V)以及查詢 Q,因為文章[6]取K=V=Q,所以也自然稱為Self Attention。
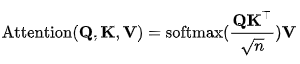
K, V 像是 key-value 的關(guān)系從而是一一對應(yīng)的,那么上式的意思就是通過Q中每個元素query,與K中各個元素求內(nèi)積然后 softmax 的方式,來得到Q中元素與V中元素的相似度,然后加權(quán)求和,得到一個新的向量。
其中因子為了使得內(nèi)積不至于太大。以上公式在文中也稱為點積注意力(scaled dot-product attention):輸出是值的加權(quán)和,其中分配給每個值的權(quán)重由查詢的點積與所有鍵確定。
而Transformer主要由多頭自注意力(Multi-Head Self-Attention)單元組成。那么Multi-Head Self-Attention又是什么呢?以下為論文中的圖:
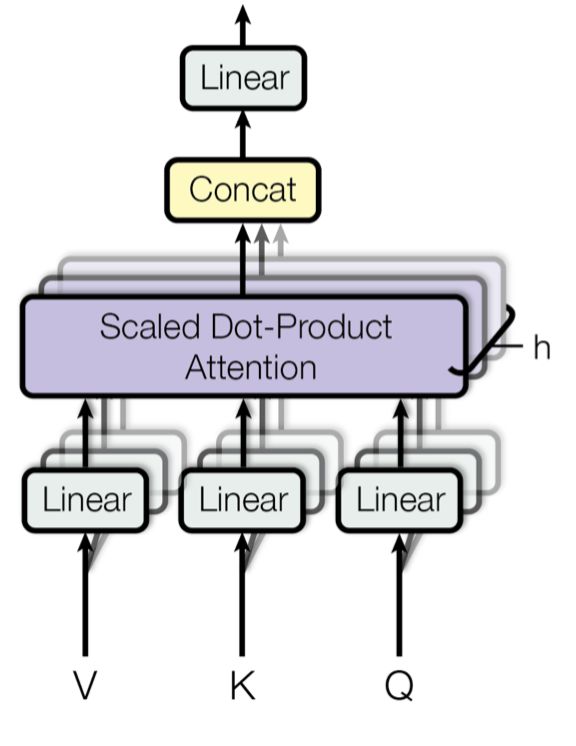
Multi-head scaled dot-product attention mechanism
Multi-Head Self-Attention不是僅僅計算一次注意力,而是多次并行地通過縮放的點積注意力。 獨立的注意力輸出被簡單地連接并線性地轉(zhuǎn)換成預(yù)期的維度。
論文[6]表示,多頭注意力允許模型共同關(guān)注來自不同位置的不同表示子空間的信息。 只有一個注意力的頭,平均值就會抑制這一點。

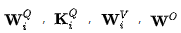 是需要學(xué)習(xí)的參數(shù)矩陣。既然為seq2seq模式,自然也包括encoder和decoder,那這篇文章又是如何構(gòu)建這些的呢?莫急,請繼續(xù)往下看。
是需要學(xué)習(xí)的參數(shù)矩陣。既然為seq2seq模式,自然也包括encoder和decoder,那這篇文章又是如何構(gòu)建這些的呢?莫急,請繼續(xù)往下看。
Encoder
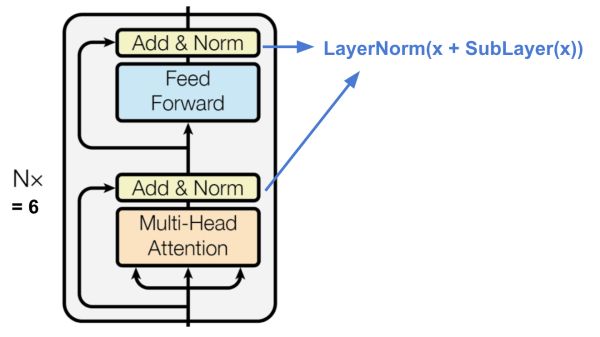
The transformer's encoder
編碼器生成基于自注意力的表示,其能夠從可能無限大的上下文中定位特定信息。值得一提的是,上面的結(jié)構(gòu)文章堆了六個。
每層都有一個多頭自注意力層
每層都有一個簡單的全連接的前饋網(wǎng)絡(luò)
每個子層采用殘差連接和層規(guī)范化。 所有子層輸出相同維度dmodel = 512。
Decoder
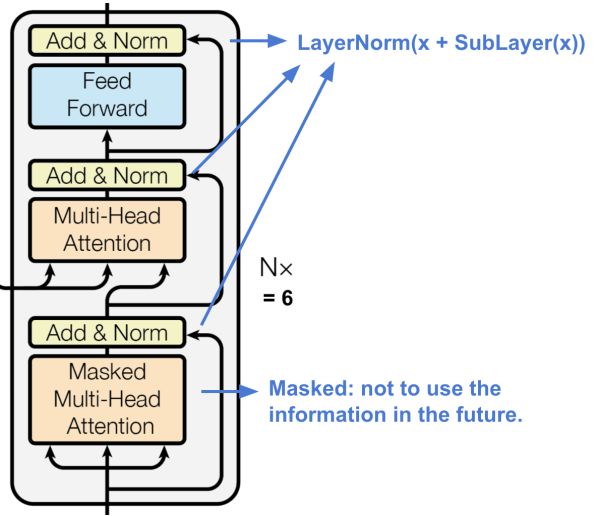
The transformer's decoder.
解碼器能夠從編碼表示中檢索。上面的結(jié)構(gòu)也堆了六個。
每層有兩個多頭注意機制子層。
每層有一個完全連接的前饋網(wǎng)絡(luò)子層。
與編碼器類似,每個子層采用殘差連接和層規(guī)范化。
與encoder不同的是,第一個多頭注意子層被設(shè)計成防止關(guān)注后續(xù)位置,因為我們不希望在預(yù)測當前位置時查看目標序列的未來。最后來看一看整體架構(gòu):
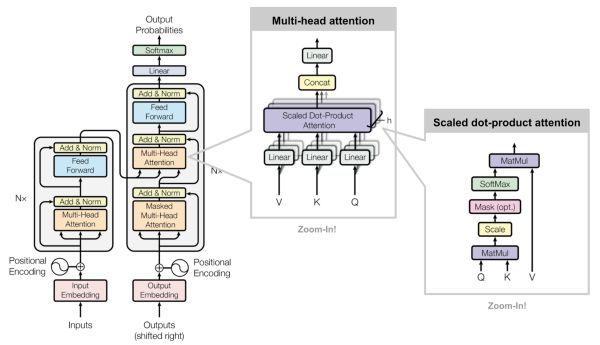
The full model architecture of the transformer.
07
Memory-based Attention
那Memory-based Attention又是什么呢?我們先換種方式來看前面的注意力,假設(shè)有一系列的鍵值對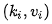 存在內(nèi)存中和查詢向量q,這樣便能重寫為以下過程:
存在內(nèi)存中和查詢向量q,這樣便能重寫為以下過程:
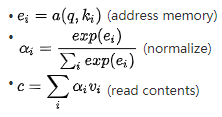
這種解釋是把注意力作為使用查詢q的尋址過程,這個過程基于注意力分數(shù)從memory中讀取內(nèi)容。聰明的童鞋肯定已經(jīng)發(fā)現(xiàn)了,如果我們假設(shè)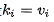 ,這不就是前面談到的基礎(chǔ)注意力么?
,這不就是前面談到的基礎(chǔ)注意力么?
然而,由于結(jié)合了額外的函數(shù),可以實現(xiàn)可重用性和增加靈活性,所以Memory-based attention mechanism可以設(shè)計得更加強大。
那為什么又要這樣做呢?在nlp的一些任務(wù)上比如問答匹配任務(wù),答案往往與問題間接相關(guān),因此基本的注意力技術(shù)就顯得很無力了。
那處理這一任務(wù)該如何做才好呢?這個時候就體現(xiàn)了Memory-based attention mechanism的強大了,譬如Sukhbaatar[19]等人通過迭代內(nèi)存更新(也稱為多跳)來模擬時間推理過程,以逐步引導(dǎo)注意到答案的正確位置:

在每次迭代中,使用新內(nèi)容更新查詢,并且使用更新的查詢來檢索相關(guān)內(nèi)容。一種簡單的更新方法為相加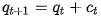 。那么還有其它更新方法么?
。那么還有其它更新方法么?
當然有,直覺敏感的童鞋肯定想到了,光是這一點,就可以根據(jù)特定任務(wù)去設(shè)計,比如Kuma[13]等人的工作。這種方式的靈活度也體現(xiàn)在key和value可以自由的被設(shè)計,比如我們可以自由地將先驗知識結(jié)合到key和value嵌入中,以允許它們分別更好地捕獲相關(guān)信息。看到這里是不是覺得文章灌水其實也不是什么難事了。
08
Soft/Hard Attention
最后想再談?wù)凷oft/Hard Attention,是因為在很多地方都看到了這個名詞。
據(jù)我所知,這個概念由《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》提出,這是對attention另一種分類。
SoftAttention本質(zhì)上和Bahdanau等人[3]很相似,其權(quán)重取值在0到1之間,而Hard Attention取值為0或者1。
09
Global/Local Attention
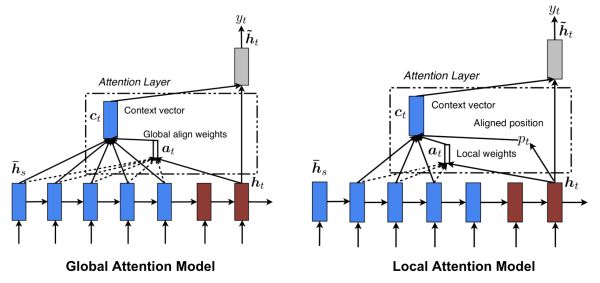
Luong等人[4]提出了Global Attention和Local Attention。Global Attention本質(zhì)上和Bahdanau等人[3]很相似。
Global方法顧名思義就是會關(guān)注源句子序列的所有詞,具體地說,在計算語義向量時,會考慮編碼器所有的隱藏狀態(tài)。
而在Local Attention中,計算語義向量時只關(guān)注每個目標詞的一部分編碼器隱藏狀態(tài)。
由于Global方法必須計算源句子序列所有隱藏狀態(tài),當句子長度過長會使得計算代價昂貴并使得翻譯變得不太實際,比如在翻譯段落和文檔的時候。
10
評價指標
在看一些帶有attention的paper時,常常會伴隨著為了說明自己文章attention是work的實驗,但實際上嘗試提供嚴格數(shù)學(xué)證明的文章極少。
Hu[7]把Attention的評價方式分為兩類,Quantitative(定量指標)和Qualitative(定性指標)。
定量指標顧名思義就是對attention的貢獻就行量化,這一方面一般會結(jié)合下游任務(wù),最常見的當屬機器翻譯,我們都知道機器翻譯的最流行評價指標之一是BLEU。
我們可以在翻譯任務(wù)設(shè)計attention和不加attention進行對比,對比的指標就是BLEU,設(shè)置我們可以設(shè)計多種不同的attention進行對比。
定性指標評價是目前應(yīng)用最廣泛的評價技術(shù),因為它簡單易行,便于可視化。
具體做法一般都是為整個句子構(gòu)建一個熱力圖,其熱力圖強度與每個單詞接收到的標準化注意力得分成正比。
也就是說,詞的貢獻越大,顏色越深。其實這在直覺上也是能夠接收的,因為往往相關(guān)任務(wù)的關(guān)鍵詞的attention權(quán)值肯定要比其它詞重要。
-
自然語言處理
+關(guān)注
關(guān)注
1文章
585瀏覽量
13418 -
nlp
+關(guān)注
關(guān)注
1文章
481瀏覽量
21932
原文標題:自然語言處理中注意力機制綜述
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論