 《中國近代史綱要》考試過關?Python幫你劃重點
《中國近代史綱要》考試過關?Python幫你劃重點
打開查分界面,我看到我的“中國近現代史綱要”一欄露出了難看的臉色。
這時,一個程序突然自告奮勇:“不就是這種簡單的考試嗎?讓我學一下你們的課本,我也能夠上考場! (  ̄ー ̄)”
我把我的課本文本輸入給它。不到一分鐘以后,它對我說:“我學完了,來考我吧。”
雖然也只是在考前突擊了兩天,但我對它如此之快的速度還是深感嫉妒。我問:“你知道孫中山先生都干了哪些事情嗎?”
“發動護法運動、就任臨時大總統、讓位于***”
“不錯嗎,你是怎么做到的?”
“讓我給你細細講來吧……”
準備工作
程序:“首先引入一些必要的庫,然后我加載doc為1840—1919年中國大事的那一段段文本做個簡單的示例,這部分代碼就不用我列出來了吧。”
旁白:這里使用harvesttext庫進行文本挖掘,它的許多功能能夠使得文本分析的流程變得更加輕松。前面的“用python分析《三國演義》中的社交網絡”一文也使用了這一工具。
ht = HarvestText()sentences = ht.cut_sentences(doc)
有哪些重要對象
“重要對象,一般都是一些專有名詞。我可以利用自然語言處理中的命名實體識別技術就能夠識別出這樣的一些對象,比如:人名、地名、機構名還有其他專有名詞等。”
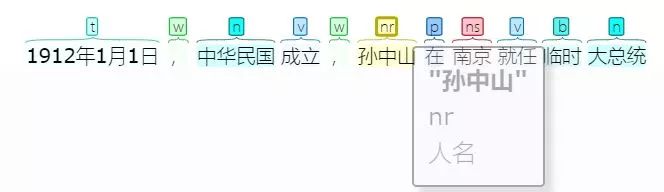
HarvestText中包裝精簡了pyhanlp中的命名實體識別接口,讓我們來使用它找到近代史中的重要對象吧。
entity_type_dict = {}for i, sent in enumerate(sentences): entity_type_dict0 = ht.named_entity_recognition(sent) for entity0, type0 in entity_type_dict0.items(): entity_type_dict[entity0] = type0for entity in list(entity_type_dict.keys())[:10]: print(entity, entity_type_dict[entity])中國 地名鴉片戰爭 其他專名五四運動 其他專名英國 地名南京 地名望廈 其他專名黃埔 地名不平等條約 其他專名洪秀全 人名金田 地名
把找到的實體登錄,我們就可以統計他們出現的次數,通過詞頻來判斷它們的重要性。
ht.add_entities(entity_type_dict = entity_type_dict)inv_index = ht.build_index(sentences)counts = ht.get_entity_counts(sentences,inv_index)print(pd.Series(counts).sort_values(ascending=False).head())中國 21清政府 6日本 5孫中山 4英國 3dtype: int64
我:“這個分析確實有用,看著這些詞我就聯想到了,在1840—1919年的中國,清政府面對外敵的屈辱,以及孫中山先生為代表的有識之士的努力。但是考試不是單考這些對象,關鍵要考和它們有關的知識點啊。”
程序:“別著急,對于知識點,我也有辦法找到。”
有哪些重要知識點
程序:“你們說的重要知識點,可以認為是包含了那些重要對象的事件或者事實吧。對于你們人類,事實可能就是自然語言描述的一句話。不過對于我們程序,我們要用一種標準清晰的結構來表示它。三元組組成的知識圖譜就是一種解決方案。”
三元組就是類似(主語,謂詞,賓語)的結構,比如:
[‘清政府’, ‘簽訂’, ‘天津條約’]
[‘***’, ‘復辟’, ‘帝制’]
[‘孫中山’, ‘就任’, ‘臨時大總統’]
我:“有點意思,三個詞基本就能凝練地表達一句話中的主要事實了。但是你只有文本作為輸入,你要怎么從中提取出這樣的三元組呢?”
程序:“上面已經提到三元組有(主語,謂詞,賓語)的結構。你要是英語/語文課學得好的話,應該會聯想到主語、謂語、賓語這些語法概念吧?而我就可以使用依存句法分析技術從文本中獲得這些句法信息。”
分析大致是這樣的:
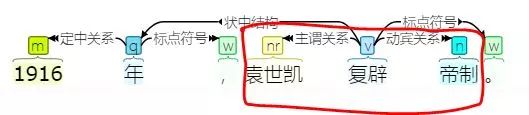
可以看到,從主謂關系和動賓關系,我們就能夠自然地得到我們需要的三元組[‘***’, ‘復辟’, ‘帝制’]。
保留更多的信息,比如修飾主語的形容詞,能夠讓三元組的意思更加完整。我們可以利用別的關系來擴充事實:

原來我們只會得到[‘孫中山’, ‘就任’, ‘大總統’]。現在利用定中關系,我們就知道“臨時”一詞修飾“大總統”,我們就能夠得到[‘孫中山’, ‘就任’, ‘臨時大總統’]這個更完整的事實了。
我:“emmm…我的英語學得不好,這些語法看得有點頭暈。”
程序:“好吧 (¬_¬),不過把它包裝成接口以后,我們就可以很簡單地使用這個技術了。現在讓我們用它來找到課本里的重要知識點:”
ht2 = HarvestText()SVOs = []for i, sent in enumerate(sentences): SVOs += ht2.triple_extraction(sent.strip())print(" ".join(" ".join(tri) for tri in SVOs[5:10]))英法聯軍 發動 侵略中國清政府 簽訂 天津條約清政府 簽訂 北京條約慈禧太后 掌握 清王朝政權這是中國半殖民地半封建社會 形成 中國資本主義產生時期
程序:“怎么樣?要不考慮下次考試讓我幫你劃重點?”
我:“有的三元組看起來還挺不錯的,但是有的感覺有點奇怪啊。”
程序:“不要在意這些細節……那是因為你們給我寫的算法還有很多提升空間嗎,但總體質量還是不錯的。”
“有了這些結構化的知識,我就可以接著建立知識圖譜,‘掌握’這些知識之間的聯系。”
知識圖譜長什么樣呢?它可以理解為實體之間的網絡,網絡之間的連邊就是實體之間的聯系,做出一張圖來直觀地感受下:
fig = plt.figure(figsize=(12,8),dpi=100)g_nx = nx.DiGraph()labels = {}for subj, pred, obj in SVOs: g_nx.add_edge(subj,obj) labels[(subj,obj)] = predpos=nx.spring_layout(g_nx)nx.draw_networkx_nodes(g_nx, pos, node_size=300)nx.draw_networkx_edges(g_nx,pos,width=4)nx.draw_networkx_labels(g_nx,pos,font_size=10,font_family='sans-serif')nx.draw_networkx_edge_labels(g_nx, pos, labels , font_size=10, font_family='sans-serif')plt.axis("off")plt.show()
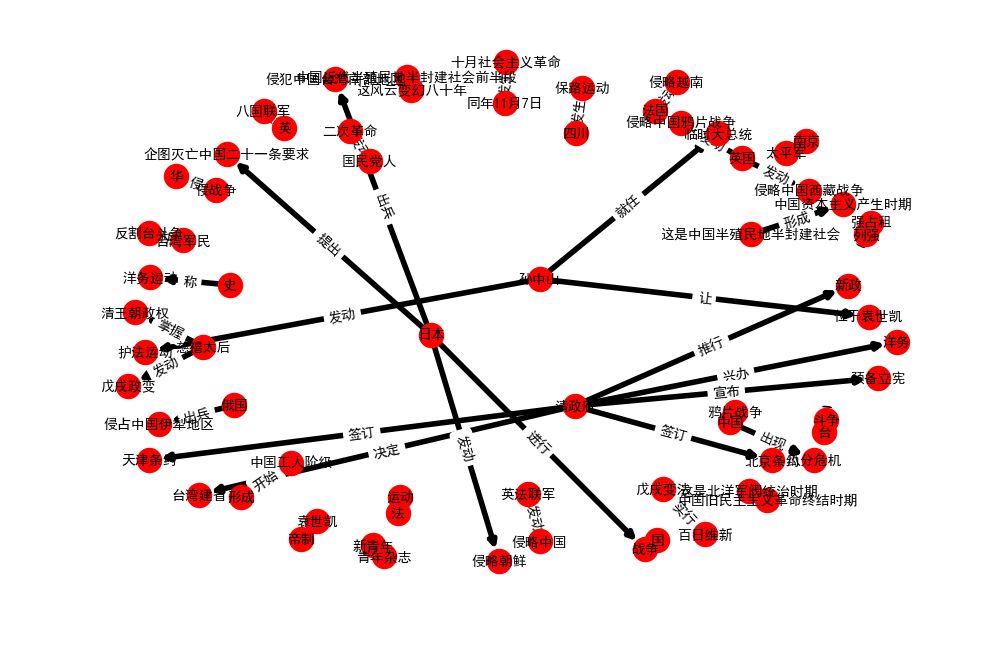
現在,上考場吧
“現在我學會了這些知識,就可以建立起問答系統,回答一些問題。出幾個問題來考考我吧?”
問答系統的具體實現思路可以見我的另一篇博客:https://blog.csdn.net/blmoistawinde/article/details/86556844
QA = NaiveKGQA(SVOs, entity_type_dict=entity_type_dict)questions = ["孫中山干了什么事?","清政府簽訂了哪些條約?","誰復辟了帝制?"]for question0 in questions: print("問:"+question0) print("答:"+QA.answer(question0))問:孫中山干了什么事?答:讓位于***、發動護法運動、就任臨時大總統問:清政府簽訂了哪些條約?答:天津條約、北京條約問:誰復辟了帝制?答:***
回答得相當不錯。盡管當下這些問題是我特地挑選出來的,確定知識庫里有正確的答案。不過當技術發展完善,或許有一天,它真的能夠走上考場,取得不錯的成績呢。
本文故事純屬虛構,近綱考砸卻是真事。不過我會感謝這門課教給我的歷史教訓,還有帶給我的本文寫作靈感。
-
python
+關注
關注
56文章
4782瀏覽量
84452 -
識別技術
+關注
關注
0文章
202瀏覽量
19684 -
自然語言
+關注
關注
1文章
287瀏覽量
13330
原文標題:《中國近代史綱要》考試過關?Python幫你劃重點
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
適配器?輸出電壓異常、紋波過高、EMI傳導不過關?這些竅門管用

2021年高壓電工考試報名及高壓電工考試資料相關推薦
2021年電工(初級)證考試及電工(初級)作業模擬考試相關資料分享
2021年電工(初級)報名考試及電工(初級)考試內容相關資料推薦
2021年電工(初級)考試及電工(初級)考試題庫相關資料下載
劃平行線和垂直線的導向工具
Python程序設計的考試大綱詳細資料說明







 工商網監
工商網監
評論