 工業互聯網時代,我們為什么需要時序數據庫之二:適合的就是最好的
工業互聯網時代,我們為什么需要時序數據庫之二:適合的就是最好的
在上周的格物匯文章中,我們給大家介紹過,目前國內外主流工業互聯網平臺幾乎都是采用時序數據庫來承接海量涌入的工業數據。那為什么強大的Oracle、PostgreSQL 等傳統關系型數據庫搞不定時序數據?為什么不用HBase、MongoDB、Cassandra等先進的分布式數據庫來解決工業數據問題?
作為資深“杠精”,當然需要先知道要“杠”的到底是什么?就時序數據庫而言,就是要“杠”兩個東西:1、“杠”數據;2、“杠”數據庫。
先從數據“杠”起,數據可是一個高深莫測的東西。
想當年圖靈用他深邃的眼睛,看穿了世間萬物的計算本質:凡是可以計算的,通過迭代,最終都可以表示為0、1的邏輯判斷。圖靈機需要一個無限長的紙帶來表征和記錄計算,這無限長的紙帶上記錄的0、1的組合,就是數據最原始的抽象。圖靈機指出了數據的3個核心需求:1、數據存儲;2、數據寫入;3、數據讀取。
可以說,目前所有數據庫、文件系統等等,都是為了以最佳性價比來滿足數據的這三個核心需求。對時序數據而言,其三個核心需求特征十分明顯:
數據寫入
時間是一個主坐標軸,數據通常按照時間順序抵達
大多數測量是在觀察后的幾秒或幾分鐘內寫入的,抵達的數據幾乎總是作為新條目被記錄
95%到99%的操作是寫入,有時更高
更新幾乎沒有
數據讀取
隨機位置的單個測量讀取、刪除操作幾乎沒有
讀取和刪除是批量的,從某時間點開始的一段時間內
時間段內讀取的數據有可能非常巨大
數據存儲
數據結構簡單,價值隨時間推移迅速降低
通過壓縮、移動、刪除等手段降低存儲成本
而關系數據庫主要應對的數據特點:
(1)數據寫入:大多數操作都是DML操作,插入、更新、刪除等;
(2)數據讀取:讀取邏輯一般都比較復雜;
(3)數據存儲:很少壓縮,一般也不設置數據生命周期管理。
因此,從數據本質的角度而言,時序數據庫(不變性, 唯一性以及可排序性)和關系型數據庫的服務需求完全不同。
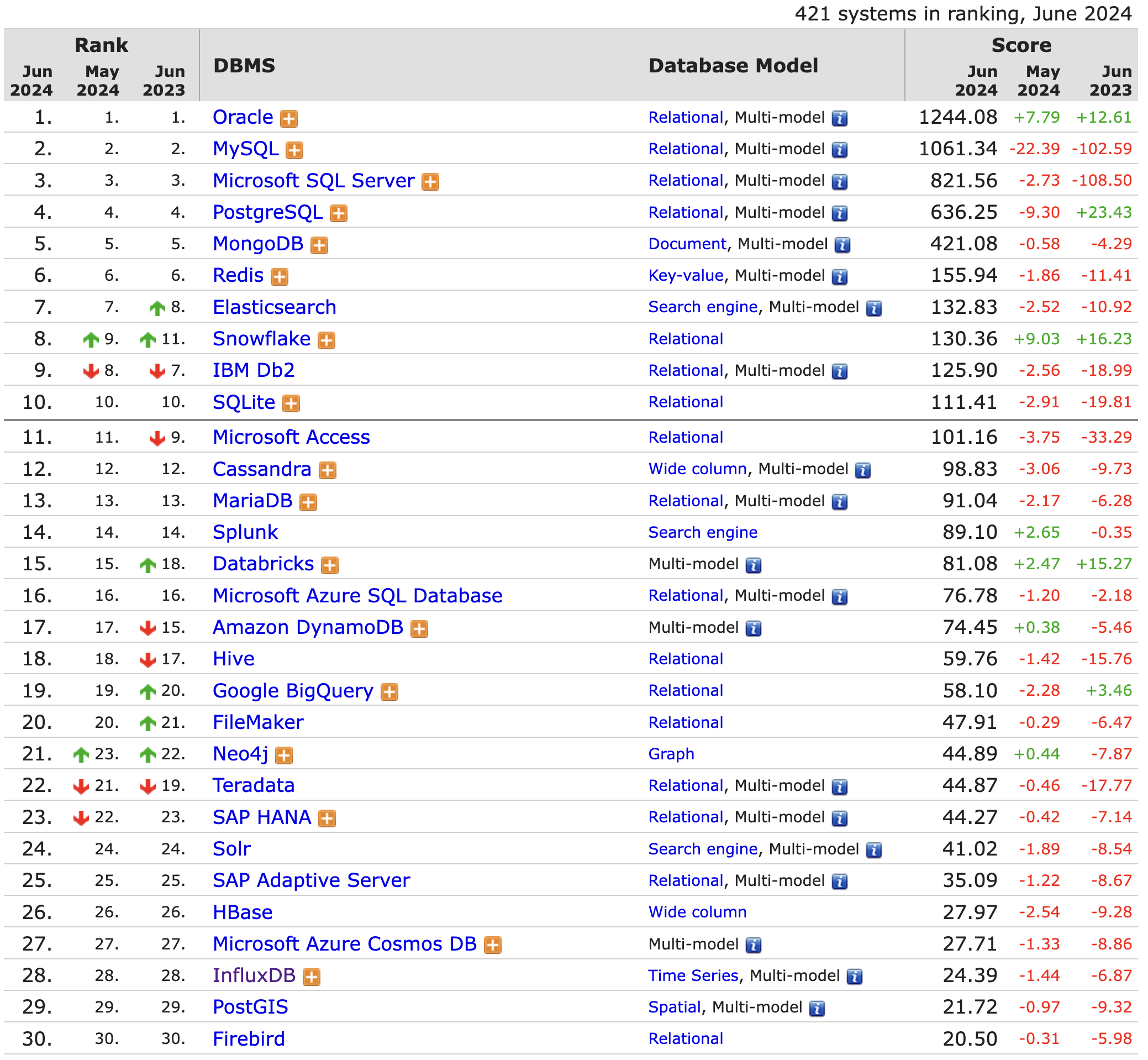
再說說數據庫。數據庫系統的發展從20世紀60年代中期開始到現在,經歷若干代演變,造就了C.W. Bachman(巴克曼)、E.F.Codd(考特)和J. Gray(格雷)三位圖靈獎得主,發展了以數據科學、數據建模和數據庫管理系統(DBMS)等為核心理論、技術和產品的一個巨大的軟件產業(詳見下圖,資料來源:https://db-engines.com/en/ranking_categories)。

從上圖可以得出一個結論,針對不同的數據需求,應該有不同的數據庫系統應對之。否則,也沒有必要出現這么多種的數據庫系統了。
時間序列數據跟關系型數據庫有太多不同,但是很多公司并不想放棄關系型數據庫。于是就產生了一些特殊的用法,比如:用 MySQL 的 VividCortex, 用 Postgres 的 TimescaleDB;當然,還有人依賴K-V、NoSQL數據庫或者列式數據庫的,比如:OpenTSDB的HBase,而Druid則是一個不折不扣的列式存儲系統;更多人覺得特殊的問題需要特殊的解決方法,于是很多時間序列數據庫從頭寫起,不依賴任何現有的數據庫, 比如: Graphite,InfluxDB。

對選擇數據庫的開發者和使用者而言,針對時序數據庫和關系型數據庫之間選擇,也主要考慮以下幾個因素:
性能
研究過Oracle的存儲結構和索引結構的都知道Oracle的ACID強一致性和B-Tree,保證強一致性導致數據持久化、可靠性、可用性實現的邏輯復雜,而加速數據訪問,則需要Oracle 數據庫使用 B-Tree 存儲索引。
B-Tree 結構的有很多優勢:在索引中從任何地方檢索任何記錄都大約花費相同的時間;B-Tree對大范圍查詢提供優秀的檢索性能,包括精確匹配和訪問查詢;插入、更新和刪除操作有效,維護鍵的順序,以便快速檢索;B-Tree性能對小表和大表都很好,不會隨著表的增長而降低。從Tree這個名字就可以看出,這種B-Tree就是為了解決隨機讀寫問題的。
而時序數據庫,核心問題去解決批量讀寫,對于 95% 以上場景都是寫入的時序數據庫,B-Tree 很明顯是不合適的,業界主流都是采用 LSM Tree(Log Structured Merge Tree)或者LSM的“升級版”TSM(Time Sort Merge Tree) 替換 B-Tree,比如 Hbase、Cassandra、InfluxDB等。LSM Tree 核心思想就是通過內存寫和后續磁盤的順序寫入獲得更高的寫入性能,避免了隨機寫入。
LSM Tree 簡單操作流程如下:
數據寫入和更新時首先寫入位于內存里的數據結構。同時,為了避免數據丟失也會先寫到磁盤文件中。
內存里的數據結構會定時或者達到固定大小會刷到磁盤。
隨著磁盤上積累的文件越來越多,會定時的進行合并操作,減少文件數量。
在內存or文件中,對數據進行壓縮、去重等操作。
還有一個提升性能的關鍵點,即:分布式處理。這里以InfluxDB為例來說明。(順便吐槽一下:InfluxDB單機版開源,集群版收費……,扔個魚餌,“吃相”難看呀。)

上圖是InfluxDB的邏輯存儲架構圖,通過RP、ShardGroup、Shard的逐層分解,寫入數據被盡可能的分布攤平。最后,每個Shard的TSM引擎負責對數據進行處理。Shard Group實現了數據分區,但是Shard才是InfluxDB中真正存儲數據以及提供讀寫服務的服務。Shard是InfluxDB的TSM Engine,負責數據的編碼存儲、讀寫服務等。

通常分布式數據庫一般有兩種Sharding策略:Range Sharding和Hash Sharding,前者對于基于主鍵的范圍掃描比較高效;后者對于離散大規模寫入以及隨即讀取相對比較友好。
InfluxDB的Sharding策略是典型的兩層Sharding,上層使用Range Sharding,下層使用Hash Sharding。對于時序數據庫來說,基于時間的Range Sharding是最合理的考慮,但如果僅僅使用Time Range Sharding,會存在一個很嚴重的問題,即寫入會存在熱點,基于TimeRange Sharding的時序數據庫寫入必然會落到最新的Shard上,其他老Shard不會接收寫入請求。對寫入性能要求很高的時序數據庫來說,熱點寫入肯定不是最優的方案。解決這個問題最自然的思路就是再使用Hash進行一次分區,基于Key的Hash分區方案可以通過散列很好地解決熱點寫入的問題。
Shard分區好了,就可以采用分布式集群架構予以支撐,分攤壓力,提高并行度。
成本和功能
很多時間序列數據都沒有多大用處,特別是當系統長時間正常運行時,完整的歷史數據意義并不大。而這些低價值數據,占據大量高價值存儲空間,會讓企業“抓狂”。因此,一些共通的對時間序列數據分析的功能和操作:數據壓縮、數據保留策略、連續查詢、靈活的時間聚合等,都是為了解決時序數據庫的性價比問題的。同時,有些數據庫比如 RDDTool 和 Graphite 會自動刪除高精度的數據,只保留低精度的。而這些“功能”對關系型數據庫而言,簡直是不可想象的。
還有一些成本很多人會忘記考慮,比如:License,用需要License的關系型數據庫來存儲時序數據,成本根本沒法承受。
至此,我們得出的結論就一個:選擇到底用什么數據庫來支持時序數據,還是需要對時序數據的需求進行透徹的分析,然后根據時序數據的特點,來選擇適合的數據庫。
啟用名言作為本文結尾:適合的,就是最好的。
本文作者:格創東智首席架構師王錦博士。格創東智是由智能產品制造及互聯網應用服務領軍企業TCL孵化的創新型科技公司,致力于深度融合人工智能(AI)、大數據、云計算等前沿技術與制造行業經驗,打造行業領先的“制造x”工業互聯網平臺,同時為各類制造業企業提供優質、安全、高效的管理IT服務,助力傳統制造業智能化轉型升級。(轉載請注明作者及來源)
-
智能制造
+關注
關注
48文章
5482瀏覽量
76261 -
工業互聯網
+關注
關注
28文章
4299瀏覽量
94050 -
工業大數據
+關注
關注
0文章
72瀏覽量
7826
發布評論請先 登錄
相關推薦
有云服務器還需要租用數據庫嗎?
數字化時代的數據管理:多樣化數據庫選型指南
工業互聯網三大體系是什么?
時序數據庫是什么?時序數據庫的特點
工業互聯網平臺是什么
工業互聯網發展進路:反思與建議
什么是JSON數據庫






 工商網監
工商網監
評論