 計算機體系結構將迎來一個新的黃金時代!
計算機體系結構將迎來一個新的黃金時代!
圖靈獎得主、計算機體系結構宗師David Patterson與John Hennessy認為,未來將是計算機體系結構的黃金十年。最新一期的ACM通訊上刊登了兩人合著的論文《計算機體系結構的新黃金時代》,闡述計算性能如何實現再一次飛升。
計算機體系結構將迎來一個新的黃金時代!
2017年3月,計算機架構領域兩位巨星級人物David Patterson與John Hennessy在斯坦福大學發表演講時如是說。
當時,Hennessy最知名的title是斯坦福大學前任校長,而Patterson則是伯克利的退休教授。他們1990年合著出版的《計算機體系架構:量化研究方法》被譽為領域“體系結構圣經”,培養和指導了無數處理器設計人才。
John Hennessy(左) 和David Patterson 拿著他們合著的《計算機體系架構:量化研究方法》,照片的拍攝時間大約是1991年。來源:ACM
當時,由GPU推動的深度學習浪潮已然興起,谷歌推出了TPU,AI芯片創業公司林立,芯片市場群雄并起,連做軟件的人都能感到從硬件行業迸發出的熱氣。
很快,一年后,已經出任谷歌母公司Alphabet董事長的Hennessy和已經加入谷歌TPU團隊的Patterson又站在了一起,這次是為了紀念他們共同榮獲2017年的圖靈獎。
他們的圖靈獎演講題目叫做《計算機體系結構的新黃金時代》(A New Golden Age for computer Architecture),兩人回顧了自20世紀60年代以來計算機體系結構發展歷史,并展望人工智能為計算機架構設計所帶來的新的挑戰和機遇。
在那次的圖靈演講中,David Patterson與John Hennessy還提到了軟件設計也能為計算機硬件架構帶來靈感,改善軟硬件接口能為架構創新帶來機遇。“在摩爾定律走向終點的同時,體系結構正在閃耀新的活力——以TPU為代表的領域特定架構 (Domain Specific Architectures, DSA) 興起,但CPU、GPU、FPGA仍然有用武之地,最終,市場會決定勝者。
2019年2月出版的Communications of the ACM,刊登了兩人的署名文章“A New Golden Age for computer Architecture”,在圖靈演講的基礎之上進一步完善思想,并用文字將他們的洞見更加清晰地呈現。
“計算機體系結構領域將迎來又一個黃金十年,就像20世紀80年代我們做研究那時一樣,新的架構設計將會帶來更低的成本,更優的能耗、安全和性能。”
下面是新智元對文章的編譯。
不能牢記過去的人,必定重蹈覆轍。
——George Santayana,1905年
軟件通過稱為指令集架構(ISA)的詞匯表與硬件實現交互。在20世紀60年代初,IBM共推出了四個彼此不兼容的計算機系列,每個計算機系列都有自己的ISA、軟件堆棧和輸入/輸出系統,分別針對小型企業、大型企業,科研單位和實時運算。 IBM的工程師們,包括ACM圖靈獎獲獎者Fred Brooks在內,都認為能夠創建一套新的ISA,將這四套ISA有效統一起來。
這需要一套技術解決方案,讓計算8位數據路徑的廉價計算機和計算64位數據路徑的昂貴計算機可以共享一個ISA。數據路徑(data path)是處理器的“肌肉”,因為這部分負責執行算法,但相對容易“加寬”或“縮小”。當時和現在計算機設計人員共同面臨的最大挑戰是處理器的“大腦”,即控制硬件。受軟件編程的啟發,計算機先驅人物、圖靈獎獲得者莫里斯·威爾克斯提出了簡化控制流程的思路。控制部分被指定為一個二維數組,他稱之為“控制存儲”。數組的每一列對應一條控制線,每一行都是微指令,寫微指令的操作稱為微編程。控制存儲包含使用微指令編寫的ISA解釋器,因此執行一個傳統指令需要多個微指令完成。控制存儲通過內存實現,這比使用邏輯門的成本要低得多。
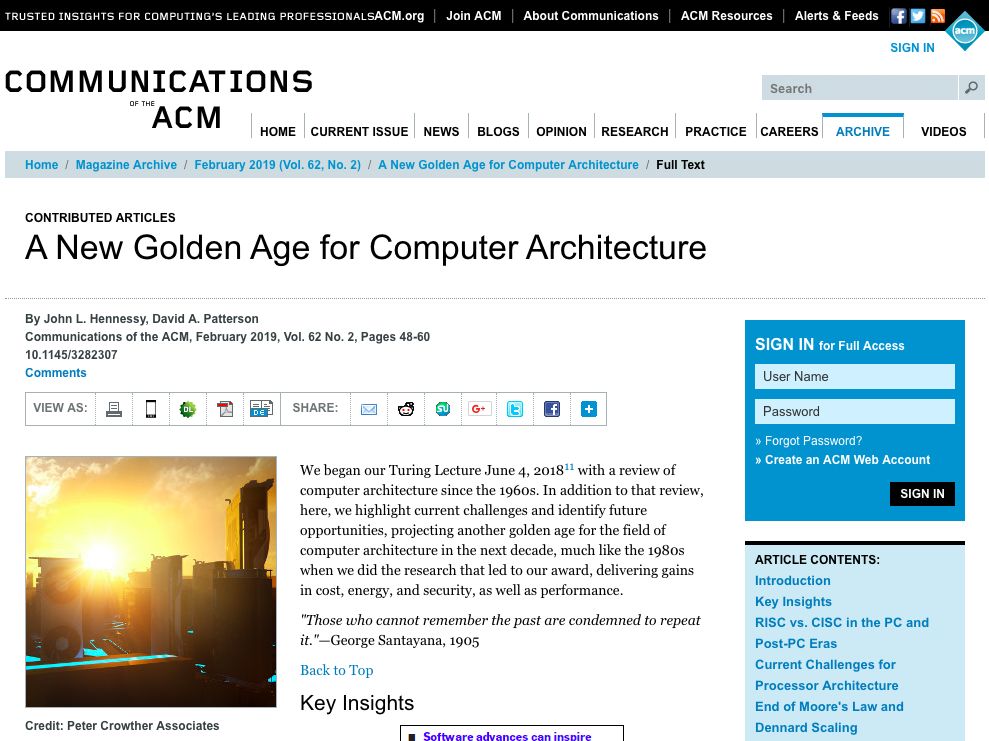
此表列出了IBM于1964年4月7日發布的新360系統的四種型號的指令集。四種型號之間。數據路徑相差8倍,內存容量相差16倍,時鐘速率相差近4倍,而性能相差50倍,其中最昂貴的機型M65具有最大空間的控制存儲,因為更復雜的數據路徑需要使用更多的控制線。由于硬件更簡單,成本最低的機型M30的控制存儲空間最小,但由于它們需要更多的時鐘周期來執行360系統指令,因此需要有更多的微指令。
通過微程序設計,IBM認為新的ISA將能夠徹底改變計算行業,贏得未來。 IBM統治了當時的計算機市場,55年前誕生的IBM大型機,其后代產品現在每年仍能為IBM帶來100億美元的收入。
現在看來,盡管市場對技術問題做出的評判還不夠完善,但由于硬件系統架構與商用計算機之間的密切聯系,市場最終成為計算機架構創新的是否成功的關鍵性因素,這些創新往往需要工程人員方面的大量投入。
集成電路,CISC,432,8086,IBM PC。當計算機開始使用集成電路時,摩爾定律意味著控制存儲可能變得更大。更大的內存可以運行更復雜的ISA。1977年,數字設備公司(Digital Equipment)發布的VAX-11/780機型的控制存儲大小達到5120 word×96 bit,而其之前的型號僅為256 word×56 bit。
一些制造商選擇讓選定的客戶添加名為“可寫控制存儲”(WCS)的自定義功能來進行微程序設計。最著名WCS計算機是Alto,這是圖靈獎獲得者Chuck Thacker和Butler Lampson以及他們的同事們于1973年為Xerox Palo Alto研究中心設計制造的。它是第一臺個人計算機,使用第一臺位映射顯示器和第一個以太局域網。用于支持新顯示器和網絡的設備控制器是存儲在4096 word×32 bit WCS中的微程序。
微處理器在20世紀70年代仍處于8位時代(如英特爾的8080處理器),主要采用匯編語言編程。各家企業的設計師會不斷加入新的指令來超越競爭對手,通過匯編語言展示他們的優勢。
戈登·摩爾認為英特爾的下一代指令集架構將能夠延續英特爾的生命,他聘請了大批聰明的計算機科學博士,并將他們送到波特蘭的一個新工廠,以打造下一個偉大的指令集架構。英特爾最初推出8800處理器是一個雄心勃勃的計算機架構項目,適用于任何時代,它具有32位尋址能力、面向對象的體系結構,可變位的長指令,以及用當時新的編程語言Ada編寫的自己的操作系統。
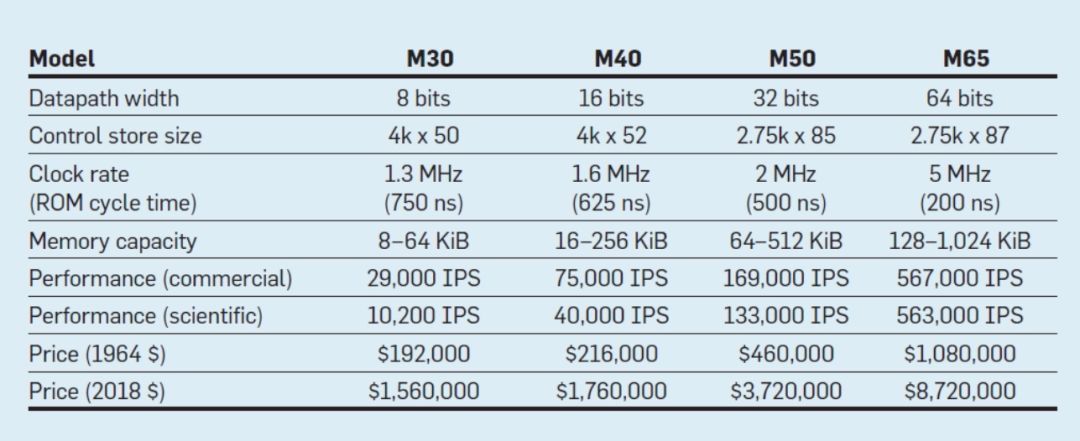
圖1 IBM 360系列機型的參數,IPS意為“每秒操作數”
這個雄心勃勃的項目遲遲不能退出,這迫使英特爾緊急改變計劃,于1979年推出一款16位微處理器。英特爾為新團隊提供了52周的時間來開發新的“8086”指令集,并設計和構建芯片。由于時間緊迫,設計ISA部分僅僅花了3周時間,主要是將8位寄存器和8080的指令集擴展到了16位。團隊最終按計劃完成了8086的設計,但產品發布后幾乎沒有大張旗鼓的宣傳。
英特爾很走運,當時IBM正在開發一款旨在與Apple II競爭的個人計算機,正需要16位微處理器。 IBM一度對摩托羅拉的68000型感興趣,它擁有類似于IBM 360的指令集架構,但與IBM激進的方案相比顯得落后。IBM轉而使用英特爾8086的8位總線版本處理器。IBM于1981年8月12日宣布推出該機型,預計到1986年能夠賣出25萬臺,結果最終在全球賣出了1億臺,未來前景一片光明。
英特爾的8800項目更名為iAPX-432,最終于1981年發布,但它需要多個芯片,并且存在嚴重的性能問題。該項目在1986年終止,此前一年,英特爾將寄存器從16位擴展到32位,在80386芯片中擴展了8086指令集架構。摩爾的預測是正確的,這個指令集確實和英特爾一直存續下來,但市場卻選擇了緊急趕工的產品8086,而不是英特爾寄予厚望的iAPX-432,這對摩托羅拉68000和iAPX-432的架構師來講,都是個現實的教訓,市場永遠是沒有耐心的。
從復雜指令集計算機到精簡指令集計算機。 20世紀80年代初期,對使用大型控制存儲中的大型微程序的復雜指令集計算機(CISC)的相關問題進行過幾項調查。Unix的廣泛應用,證明連操作系統都可以使用高級語言,所以關鍵問題就是:“編譯器會產生什么指令?”而不是“程序員使用什么匯編語言?”軟硬件交互手段的顯著進步,為架構創新創造了機會。
圖靈獎獲得者John Cocke和他的同事為小型計算機開發了更簡單的指令集架構和編譯器。作為一項實驗,他們重新定位了研究編譯器,只使用簡單的寄存器-寄存器操作和IBM 360指令集加載存儲數據傳輸,避免了使用更復雜的指令。他們發現,使用簡單子集的程序運行速度提高了三倍。 Emer和Clark發現,20%的VAX指令需要60%的微代碼,僅占執行時間的0.2%。Patterson發現,如果微處理器制造商要遵循大型計算機的CISC指令集設計,就需要一種方法來修復微代碼錯誤。
Patterson就此問題寫了一篇論文,但被《計算機》期刊拒稿。審稿人認為,構建具有ISA的微處理器是一個糟糕的想法,因為這需要在現場進行修復。這讓人懷疑,CISC 指令集對微處理器的價值究竟有多大。具有諷刺意味的是,現代CISC微處理器確實包含微代碼修復機制,但這篇論文被拒的主要結果是,激勵了他開始研究面向微處理器的精簡指令集,即復雜度較低的指令集架構,以及使用精簡指令集的計算機(RISC)。
這些觀點的產生,以及由匯編語言向高級語言的轉變,為CISC向RISC的過渡創造了條件。首先,RISC指令經過簡化,因此不再需要微代碼解釋器。 RISC指令通常與微指令一樣簡單,硬件能夠直接執行。其次,以前用于CISC 指令集的微代碼解釋器的快速存儲器被重新用作RISC指令的高速緩存。(緩存是一個小而快速的內存,用于緩沖最近執行的指令,因為這類指令很快就會被再次調用。)第三,基于Gregory Chaitin的圖著色方案的寄存器分配器,使編譯器能夠更簡易、高效地使用寄存器,最后,摩爾定律意味著在20世紀80年代能夠誕生有足夠數量的晶體管的芯片,可以容納一個完整的32位數據路徑、指令集和數據高速緩存。
在今天的“后PC時代”,x86芯片的出貨量自2011年達到峰值以來,每年下降近10%,而采用RISC處理器的芯片出貨量則飆升至200億。
下圖分別為1982年和1983年在加州大學伯克利分校和斯坦福大學開發的RISC-I8和MIPS12微處理器,體現出了RISC的優點。這些芯片最終于1984年在IEEE國際固態電路會議上發表。這是一個了不起的時刻,伯克利和斯坦福的一些研究生也可以構建微處理器了,可以說比行業內的產品更優秀。
圖2由加州大學伯克利分校開發的RISC-I8和斯坦福大學開發的MIPS12微處理器
這些由學術機構開發的芯片,激勵了許多企業開始發力RISC微處理器,并成為此后15年中發展最快的領域。其原因是處理器的性能公式:
時間/程序=操作數/程序x(時鐘周期)/指令x時間/(時鐘周期)
DEC公司的工程師后來表明,更復雜的CISC指令集每個程序執行的操作數大約為RISC的75%執行大約75%,不過在類似的技術下,CISC每個指令執行時間約為五到六個時鐘周期,使RISC微處理器的運算速度是CISC的大約4倍。
20世紀80年代時,這些內容還沒有進入計算機體系結構的書中,所以我們在1989年編寫《計算機架構:定量方法》(Computer Architecture: AQuantitative Approach)一書。本書的主題是使用測量和基準測試來對計算機架構進行量化評估,而不是更多地依賴于架構師的直覺和經驗,就像過去一樣。我們使用的定量方法也得益于圖靈獎得主高德納(Donald Knuth)關于算法的著作內容的啟發。
VLIW,EPIC,Itanium。指令集架構的下一次創新試圖同時惠及RISC和CISC,即超長指令字(VLIW)和顯式并行指令計算機(EPIC)的誕生。這兩項發明由英特爾和惠普共同命名的,在每條指令中使用捆綁在一起的多個獨立操作的寬指令。VLIW和EPIC的擁護者認為,如果用一條指令可以指定六個獨立的操作——兩次數據傳輸,兩次整數操作和兩次浮點操作,編譯器技術可以有效地將這些操作分配到六個指令槽中,硬件架構就可以變得更簡單。與RISC方法一樣,VLIW和EPIC的目的是將工作負載從硬件轉移到編譯器上。
英特爾和惠普合作設計了一款基于EPIC理念的64位處理器Itanium,想用其取代32位x86處理器并對其抱了很高的期望,但實際情況與他們的早期預期并不相符。雖然EPIC方法適用于高度結構化的浮點程序,但在可預測性較低的緩存或的分支整數程序上很難實現高性能。正如高德納后來所指出的那樣:“Itanium的設想非常棒,但事實證明滿足這種設想的編譯器基本上不可能寫出來。” 開發人員注意到Itanium的遲鈍和性能不佳,將用命途多舛的游輪“Titanic”其重命名為“Itanic”。不過,市場再次失去了耐心,最終64位版本的x86成為32位x86的繼承者,沒有輪到Itanium。
不過一個好消息是,VLIW在較窄的應用程序與小程序上,包括數字信號處理任務中留有一席之地。
PC和后PC時代的RISC vs. CISC
AMD和英特爾利用500人的設計團隊和先進的半導體技術,縮小了x86和RISC之間的性能差距。同樣,受到流水線化簡單指令vs.復雜指令的性能優勢的啟發,指令解碼器在運行中將復雜的x86指令轉換成類似RISC的內部微指令。AMD和英特爾隨后將RISC微指令的執行流程化。RISC的設計人員為了性能所提出的任何想法,例如隔離指令和數據緩存、片上二級緩存、deep pipelines以及同時獲取和執行多條指令等,都可以集成到x86中。在2011年PC時代的巔峰時期,AMD和英特爾每年大約出貨3.5億臺x86微處理器。PC行業的高產量和低利潤率也意味著價格低于RISC計算機。
考慮到全球每年售出數億臺個人電腦,PC軟件成為了一個巨大的市場。盡管Unix市場的軟件供應商會為不同的商業RISC ISA (Alpha、HP-PA、MIPS、Power和SPARC)提供不同的軟件版本,但PC市場只有一個ISA,因此軟件開發人員發布的“壓縮打包”軟件只能與x86 ISA兼容。更大的軟件基礎、相似的性能和更低的價格使得x86在2000年之前同時統治了臺式機和小型服務器市場。
Apple公司在2007年推出了iPhone,開創了后PC時代。智能手機公司不再購買微處理器,而是使用其他公司的設計(包括ARM的RISC處理器),在芯片上構建自己的系統(SoC)。移動設備的設計者不僅重視性能,而且重視晶格面積和能源效率,這對CISC ISA不利。此外,物聯網的到來大大增加了處理器的數量,以及在晶格大小、功率、成本和性能方面所需的權衡。這種趨勢增加了設計時間和成本的重要性,進一步不利于CISC處理器。在今天的后PC時代,x86的出貨量自2011年達到峰值以來每年下降近10%,而采用RISC處理器的芯片的出貨量則飆升至200億。今天,99%的32位和64位處理器都是RISC。
總結上面的歷史回顧,我們可以說市場已經解決了RISC-CISC的爭論;CISC贏得了PC時代的后期階段,但RISC正在贏得整個后PC時代。幾十年來,沒有出現新的CISC ISA。令我們吃驚的是,今天在通用處理器的最佳ISA原則方面的共識仍然是RISC,盡管距離它們的推出已經過去35年了。
處理器架構當前的挑戰
雖然上一節的重點是指令集體系結構(ISA)的設計,但大多數計算機架構師并不設計新的ISA,而是在當前的實現技術中實現現有的ISA。自20世紀70年代末以來,技術的選擇一直是基于金屬氧化物半導體(MOS)的集成電路,首先是n型金屬氧化物半導體(nMOS),然后是互補金屬氧化物半導體(CMOS)。MOS技術驚人的改進速度(Gordon Moore的預測中已經提到這一點)已經成為驅動因素,使架構師能夠設計更積極的方法來實現給定ISA的性能。摩爾在1965年26年的最初預測要求晶體管密度每年翻一番;1975年,他對其進行了修訂,預計每兩年翻一番。這最終被稱為摩爾定律。由于晶體管密度呈二次增長,而速度呈線性增長,架構師們使用了更多的晶體管來提高性能。
摩爾定律和 Dennard Scaling的終結
盡管摩爾定律已經存在了幾十年(見圖2),但它在2000年左右開始放緩,到2018年,摩爾的預測與目前的能力之間的差距大約是15倍。目前的預期是,隨著CMOS技術接近基本極限,差距將繼續擴大。
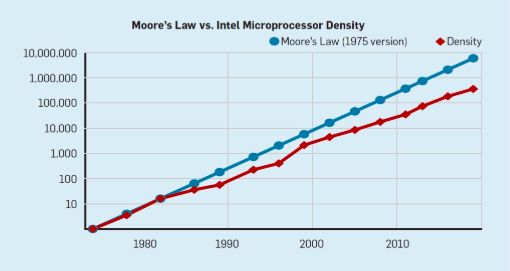
圖2:每片英特爾微處理器的晶體管與摩爾定律的差別
與摩爾定律相伴而來的是羅伯特·登納德(Robert Dennard)的預測,稱為“登納德縮放比例”(Dennard Scaling)。該定律指出,隨著晶體管密度的增加,每個晶體管的功耗會下降,因此每平方毫米硅的功耗幾乎是恒定的。由于硅的計算能力隨著每一代新技術的發展而提高,計算機將變得更加節能。Dennard Scaling在2007年開始顯著放緩,到2012年幾乎變為零(見圖3)。
圖3:Transistors per chip and power per mm2.
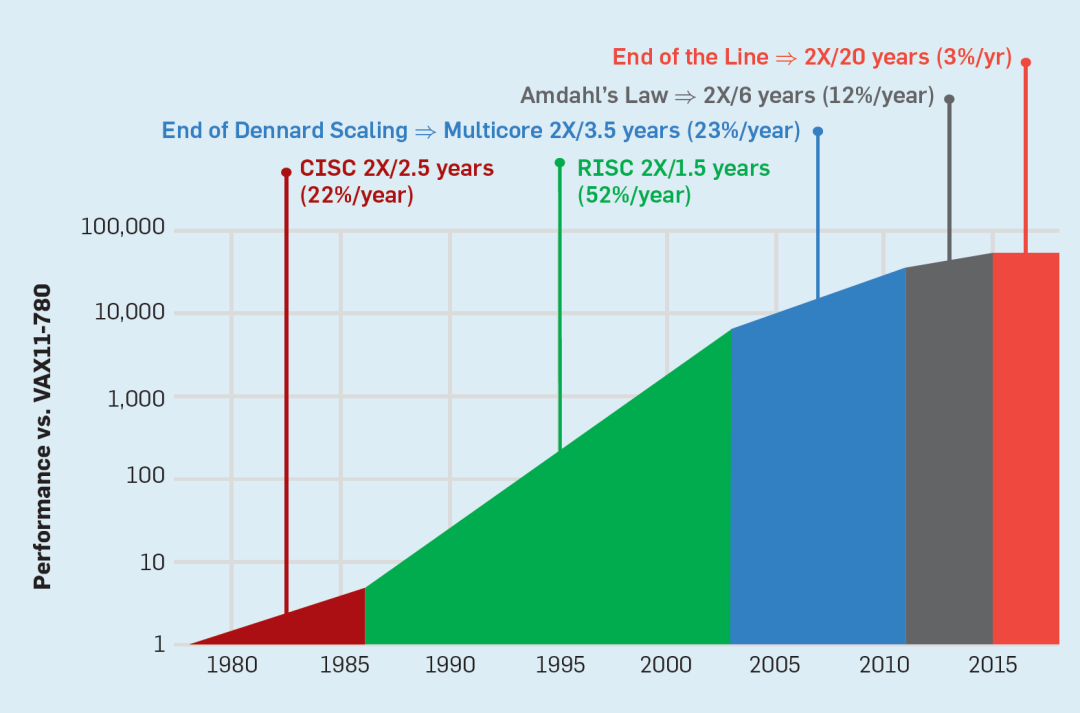
在1986年到2002年之間,指令級并行(ILP)的開發是提高性能的主要架構方法,并且隨著晶體管速度的提高,每年的性能增長大約50%。Dennard Scaling的結束意味著架構師必須找到更有效的方法來利用并行性。
要理解為什么ILP的增加會導致更大的效率低下,可以考慮一個像ARM、Intel和AMD這樣的現代處理器核心。假設它有一個15-stage的pipeline,每個時鐘周期可以發出四條指令。因此,它在任何時刻都有多達60條指令在pipeline中,包括大約15個分支,因為它們代表了大約25%的執行指令。為了使pipeline保持完整,需要預測分支,并推測地將代碼放入pipeline中以便執行。投機性的使用是ILP性能和效率低下的根源。當分支預測完美時,推測可以提高性能,但幾乎不需要額外的能源成本——甚至可以節省能源——但是當它“錯誤地預測”分支時,處理器必須扔掉錯誤推測的指令,它們的計算工作和能量就被浪費了。處理器的內部狀態也必須恢復到錯誤預測分支之前的狀態,這將花費額外的時間和精力。
要了解這種設計的挑戰性,請考慮正確預測15個分支的結果的難度。如果處理器架構師希望將浪費的工作限制在10%的時間內,那么處理器必須在99.3%的時間內正確預測每個分支。很少有通用程序具有能夠如此準確預測的分支。
為了理解這些浪費的工作是如何累加起來的,請考慮下圖中的數據,其中顯示了有效執行但由于處理器的錯誤推測而被浪費的指令的部分。在Intel Core i7上,這些基準測試平均浪費了19%的指令。
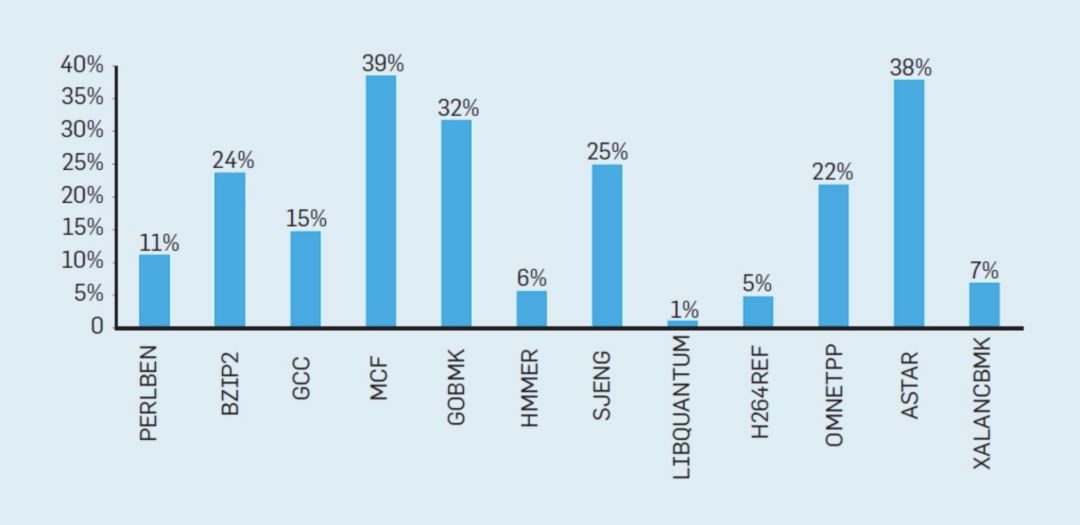
圖4
但是,浪費的能量更大,因為處理器在推測錯誤時必須使用額外的能量來恢復狀態。這樣的度量導致許多人得出結論,架構師需要一種不同的方法來實現性能改進。多核時代就這樣誕生了。
多核將識別并行性和決定如何利用并行性的責任轉移給程序員和語言系統。多核并不能解決由于登納德縮放比例定律結束而加劇的節能計算的挑戰。無論有源堆芯對計算的貢獻是否有效,有源堆芯都會消耗能量。
一個主要的障礙是Amdahl定律,它指出并行計算機的加速受到連續計算部分的限制。為了理解這一觀察的重要性,請考慮下圖,其中顯示了假設串行執行的不同部分(其中只有一個處理器處于活動狀態),在最多64個內核的情況下,應用程序的運行速度要比單個內核快得多。例如,當只有1%的時間是串行的,64處理器配置的加速大約是35。不幸的是,所需的功率與64個處理器成正比,因此大約45%的能量被浪費了。
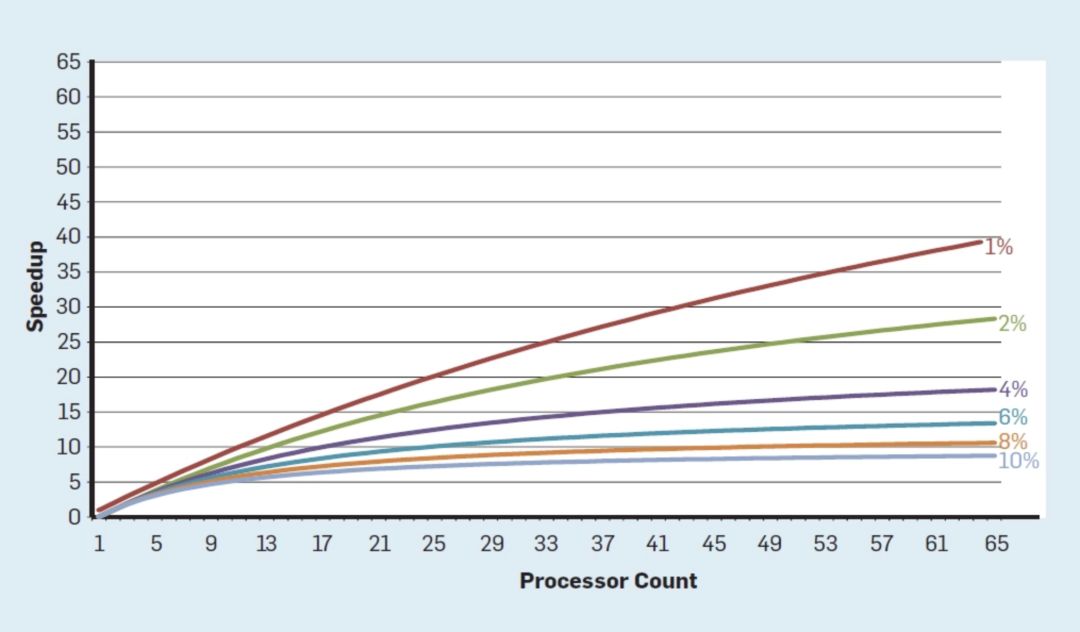
圖5
當然,真正的程序有更復雜的結構,其中部分允許在任何給定的時間點使用不同數量的處理器。盡管如此,定期通信和同步的需求意味著大多數應用程序的某些部分只能有效地使用一部分處理器。盡管Amdahl定律已有50多年的歷史,但它仍然是一個困難的障礙。
隨著Dennards Scaling定律的結束,芯片上內核數量的增加意味著功率也在以幾乎相同的速度增長。不幸的是,進入處理器的能量也必須以熱量的形式被移除。因此,多核處理器受到熱耗散功率(TDP)的限制,即封裝和冷卻系統可以移除的平均功率。雖然一些高端數據中心可能會使用更先進的軟件包和冷卻技術,但沒有電腦用戶愿意在辦公桌上安裝一個小型熱交換器,或者在背上安裝散熱器來冷卻手機。TDP的限制直接導致了“暗硅”時代,處理器會降低時鐘速率,關閉空閑內核以防止過熱。另一種看待這種方法的方法是,一些芯片可以重新分配他們寶貴的權力,從空閑的核心到活躍的。
一個沒有Dennards Scaling,摩爾定律減速、Amdahl法則完全有效的時代,意味著低效率限制了性能的提升,每年只有幾個百分點的提升(見圖6)。實現更高的性能改進需要新的架構方法,更有效地使用集成電路功能。在討論了現代計算機的另一個主要缺點后,我們將回到可能起作用的方法上來。
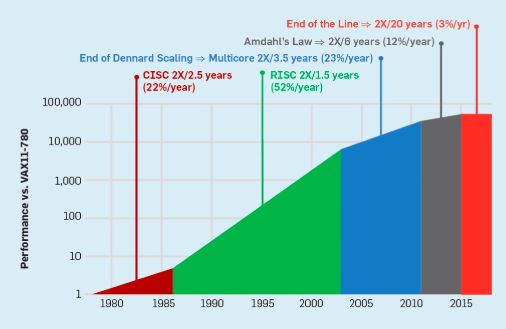
圖6
被忽視的安全問題
20世紀70年代,處理器架構師將重點放在通過保護環等概念來增強計算機安全性上。這些架構師充分認識到大多數錯誤將出現在軟件中,但是他們相信架構支持可以提供幫助。這些特性在很大程度上沒有被操作系統所采用,這些操作系統被有意地集中在所謂的良性環境中(比如個人電腦),并且成本很高,所以很快被放棄了。在軟件社區中,許多人認為正式驗證機制和微內核這樣的技術,將為構建高度安全的軟件提供有效的機制。遺憾的是,規模化軟件系統和對性能的追求,使得這些技術無法跟上處理器的性能。其結果是,大型軟件系統仍然存在許多安全缺陷,由于在線個人信息的大量增加,以及云計算的大規模應用,這種缺陷的影響被進一步放大了。
盡管計算機架構師們安全性的重要意識方面進展緩慢,但他們也已經開始為虛擬機和加密硬件提供安全支持。遺憾的是,這也可能為不少處理器帶來了一個未知、但重要的安全缺陷。尤其是,Meltdown和Spectre安全缺陷導致了新的漏洞,這些漏洞會利用微架構中的漏洞,使得本來受保護的信息迅速泄露。Meltdown和Spectre使用所謂的側通道攻擊(Side-channel attacks),通過觀察任務所需時間,將ISA級別上不可見的信息轉換為時間上可見的屬性,從而泄露信息。
2018年,研究人員展示了如何利用Spectre的變種在網絡上泄露信息,而攻擊者并不需要將代碼加載到目標處理器上。盡管這種被稱為NetSpectre的攻擊泄漏信息速度很慢,但它可以讓同一局域網(或云中的同一集群)上的任何機器受到攻擊,這又產生了許多新的漏洞。隨后有報告稱發現了虛擬機體系結構中的另外兩個漏洞。其中一種被稱為“預見”(hadow),可以滲透英特爾旨在保護高風險數據(如加密密鑰)的安全機制。此后每月都有新的漏洞被發現。
側通道攻擊并不新鮮,但在早期,軟件缺陷導致這種攻擊往往能夠成功。在Meltdown和Spectre和其他攻擊中,導致受保護信息泄露的是硬件實現中的一個缺陷。處理器架構師在如何定義ISA的正確實現上存在基本的困難,因為標準定義中并沒有說明執行指令序列對性能的影響,只是說明了執行指令的ISA可見的體系結構狀態。處理器架構師們需要重新考慮ISA的正確實現的定義,以防范此類安全缺陷。同時,架構師們應該重新考慮他們對計算機安全性的關注程度,以及如何與軟件設計人員合作來打造更安全的系統。從目前來看,架構師過于依賴于信息系統,并不愿意將安全性問題視為設計時的首要關注焦點。
計算機體系結構新機遇
“我們面前的一些令人嘆為觀止的機會被偽裝成不可解決的問題。” ——John Gardner,1965年
通用處理器固有的低效率,無論是由ILP技術還是多核所致,加上登納德縮放定律(DennardScaling)和摩爾定律的終結,使我們認為處理器架構師和設計人員在一般情況下難以繼續保持通用處理器性能實現顯著的提升。而鑒于提高處理器性能以實現新的軟件功能的重要性,我們必須要問:還有哪些其他可行的方法?
有兩個很清楚的機會,以及將兩者結合起來所創造出的第三個機會。首先,現有的軟件構建技術廣泛使用具有動態類型和存儲管理的高級語言。不幸的是,這些語言的可解釋性和執行效率往往非常低。Leiserson等人用矩陣乘法運算為例來說明這種低效率。如圖7所示,簡單地把動態高級語言Python重寫為C語言代碼,將性能提高了47倍。使用多核并行循環處理將性能提升了大約7倍。優化內存布局提高緩存利用率,將性能提升了20倍,最后,使用硬件擴展來執行單指令多數據(SIMD)并行操作每條指令能夠執行16個32位操作,讓性能提高了9倍。總而言之,與原始Python版本相比,最終的高度優化版在多核英特爾處理器上的運行速度提高了62,000倍。這當然只是一個小的例子,程序員應該使用優化后的代碼庫。雖然它夸大了通常的性能差距,但有許多軟件都可以實現這樣性能100倍到1000倍的提升。
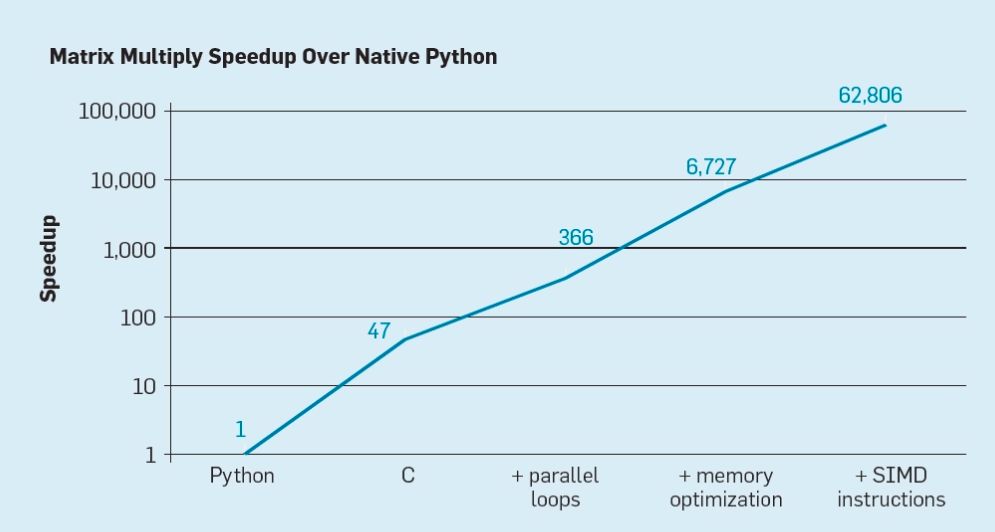
一個有趣的研究方向是關于是否可以使用新的編譯器技術來縮小某些性能差距,這可能有助于體系結構的增強。盡管高效編譯和實現Python等高級腳本語言的難度很大,但潛在的收益也是巨大的。哪怕編譯性能提升25%的潛在收益都可能使Python程序運行速度提高數十乃至數百倍。這個簡單的例子說明了在注重程序員效率的現代語言與傳統方法之間有多大的差距。
領域特定結構(DAS)。一個更加以硬件為中心的方法,是設計針對特定問題域定制的體系結構,并為該領域提供顯著的性能(和能效)增益,這也被稱之為“領域特定結構”(DSA),是一種為特定領域可編程且通常是圖靈完整的,但針對特定應用程序類別進行了定制。從這個意義上說,DSA與專用集成電路(ASIC)不同,后者通常用于單一功能,代碼很少發生變化。DSA通常稱為加速器,因為與在通用CPU上執行整個應用程序相比,它們只會加速某些應用程序。此外,DSA可以實現更好的性能,因為它們更貼近應用程序的需求;DSA的例子包括圖形處理單元(GPU),用于深度學習的神經網絡處理器和用于軟件定義網絡(SDN)的處理器。
DSA可以實現更好的性能和更高的能效,主要有以下四個原因:
首先也是最重要的一點,DSA利用了特定領域中更有效的并行形式。例如,單指令多數據并行(SIMD)比多指令多數據(MIMD)更有效,因為它只需要獲取一個指令流并且處理單元以鎖步操作。雖然SIMD不如MIMD靈活,但它很適合許多DSA。DSA也可以使用VLIW方法來實現ILP,而不是推測性的無序機制。如前所述,VLIW處理器與通用代碼不匹配,但由于控制機制更簡單,因此對于數量有限的幾個領域更為有效。特別是,大多數高端通用處理器都是亂序超標量執行,需要復雜的控制邏輯來啟動和完成指令。相反,VLIW在編譯時會進行必要的分析和調度,這非常適用于運行顯式并行程序。
其次,DSA可以更高效地利用內存層次結構。正如Horowitz所指出的,內存訪問比加減計算成本要高得多。例如,訪問32K字節緩存塊所需的能量成本比32位整數相加高約200倍。這種巨大的差異使得優化存儲器訪問對于實現高能效至關重要。通用處理器在運行代碼的時候,存儲器訪問往往表現出空間和時間局部性,但這在編譯時非常難以預測。因此,CPU使用多級高速緩存來增加帶寬,并隱藏相對較慢的片外DRAM的延遲。這些多級高速緩存通常消耗大約一半的處理器能量,但幾乎都不需要對片外DRAM的所有訪問,導致這些訪問需要大約10倍于最后一級高速緩存訪問的能量。
緩存有兩大明顯缺點:
數據集非常大時:當數據集非常大并且時間或空間位置較低時,緩存根本不能很好工作;
當緩存工作得很好時:當緩存運行良好時,位置非常高,這意味著,根據定義,大多數緩存大部分時間都處于空閑狀態。
在編譯時可以很好地定義和發現應用程序中的內存訪問模式,這對于典型的DSL來說是正確的,程序員和編譯器可以比動態分配緩存,更好地優化內存的使用。因此,DSA通常使用由軟件明確控制的動態分層存儲器,類似于矢量處理器的操作。對于合適的應用,用戶控制的存儲器可以比高速緩存消耗更少的能量。
第三,DSA可以適度使用較低的精度。通用CPU通常支持32位和64位整數和浮點(FP)數據。機器學習和圖形學中的許多應用不需要計算得這樣精確。例如,在深度神經網絡(DNN)中,推理通常使用4位,8位或16位整數,從而提高數據和計算吞吐量。同樣,對于DNN訓練應用,FP很有用,但32位足夠了,一般16位就行。
最后,DSA受益于以領域特定語言(DSL)編寫的目標程序,這些程序可以利用更多的并行性,改進內存訪問的結構和表示,并使應用程序更有效地映射到特定領域處理器。
領域特定語言
DSA要求將高級運算融入到體系結構里,但嘗試從Python,Java,C或Fortran等通用語言中提取此類結構和信息實在太難了。領域特定語言(DSL)支持這一過程,并能有效地對DSA進行編程。例如,DSL可以使向量、密集矩陣和稀疏矩陣運算顯式化,使DSL編譯器能夠有效地將將運算映射到處理器。常見的DSL包括矩陣運算語言Matlab,編程DNN的數據流語言TensorFlow,編程SDN的語言P4,以及用于指定高級變換的圖像處理語言Halide。
使用DSL的難點在于如何保持足夠的架構獨立性,使得在DSL中編寫的軟件可以移植到不同的架構,同時還可以實現將軟件映射到底層DSA的高效率。例如,XLA系統將Tensorflow編譯到使用Nvidia GPU和張量處理器單元(TPU)的異構處理器。權衡DSA的可移植性以及效率是語言設計人員、編譯器創建者和DSA架構師面臨的一項有趣的研究挑戰。
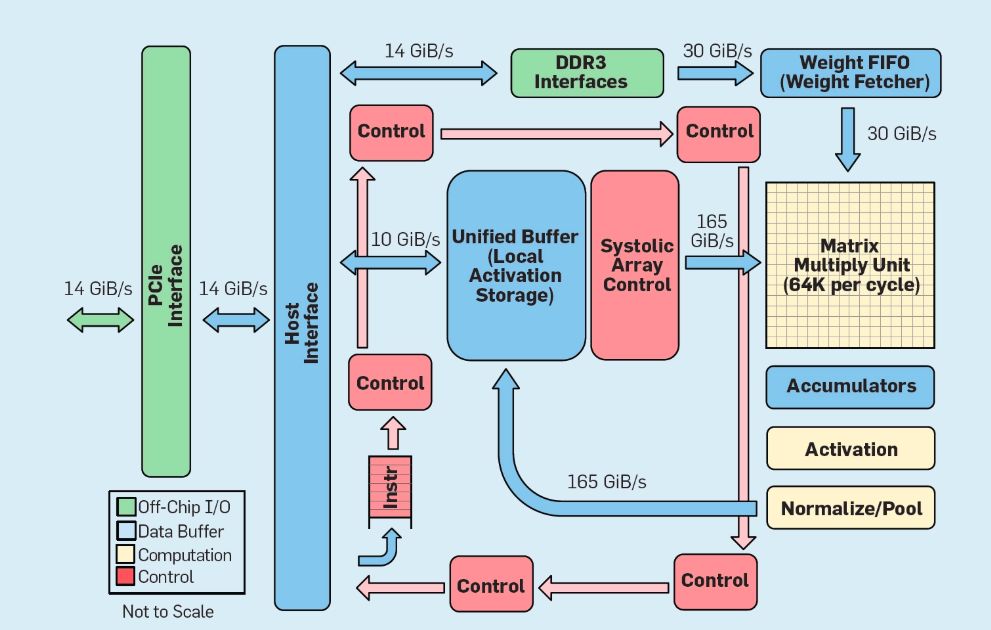
DSA TPU v1。以Google TPU v1作為DSA的一個例子,Google TPU v1旨在加速神經網絡推理。TPU自2015年開始投入生產,應用范圍從搜索查詢到語言翻譯再到圖像識別,再到DeepMind的圍棋程序AlphaGo和通用棋類程序AlphaZero,其目標是將深度神經網絡推理的性能和能效提高10倍。
如圖8所示,TPU的組織架構與通用處理器完全不同。
總結
我們考慮了兩種不同的方法,通過提高硬件技術的使用效率來提高程序運行性能:首先,通過提高現代高級語言的編譯性能;其次,通過構建領域特定體系結構,可以大大提高性能和效率。DSL是另一個如何改進支持DSA等架構創新的硬件/軟件接口的例子。通過這些方法獲得顯著性能提升。在行業橫向結構化之前,需要在跨抽象層次上垂直集成并做出設計決策,這是計算機早期工作的主要特征。在這個新時代,垂直整合變得更加重要,能夠核查和進行復雜權衡及優化的團隊將會受益。
這個機會已經引發了架構創新的激增,吸引了許多競爭性的架構理念:
Nvidia GPU使用許多內核,每個內核都有大型寄存器文件,許多硬件線程和緩存;
Google TPU依賴于大型二維收縮倍增器和軟件控制的片上存儲器;
FPGA,微軟在其數據中心部署了現場可編程門陣列(FPGA),它可以根據神經網絡應用進行定制;
CPU,英特爾提供的CPU具有許多內核,這些內核通過大型多級緩存和一維SIMD指令(微軟使用的FPGA)以及更接近TPU而不是CPU的新型神經網絡處理器得到增強。
除了這些大型企業外,還有數十家創業公司正在尋求自己的路徑。為了滿足不斷增長的需求,體系結構設計師正在將數百到數千個此類芯片互連,形成神經網絡超級計算機。
DNN架構的這種雪崩使計算機架構變得有趣。在2019年很難預測這些方向中哪些(或者即使有)會贏,但市場肯定會最終解決技術以及架構爭議。
開放式架構
受開源軟件成功的啟發,計算機體系結構中的第二個機遇是開源的ISA。要創建一個“面向處理器的Linux”,該領域需要行業標準的開源ISA,這樣社區就可以創建開源內核(除了擁有專有內核的個別公司之外)。如果許多組織使用相同的ISA設計處理器,那么更大的競爭可能會推動更快的創新。目標是為芯片提供處理器,成本從幾美分到100美元不等。
第一個例子是RISC-V(稱為“RISC Five”),這是加州大學伯克利分校開發的第五個RISC架構。RISC-V的社區在RISC-V基金會(http://riscv.org/)的管理下維護體系結構。開源允許ISA在公開的場景下發生演變,在決策最終確定之前,由硬件和軟件專家進行協作。
RISC-V是一個模塊化的指令集。一小部分指令運行完整的開源軟件棧,然后是可選的標準擴展設計器,設計人員可以根據需求包含或省略這些擴展。這個基礎包括32位和64位版本。RISC-V只能通過可選擴展來發展;即使架構師不接受新的擴展,軟件堆棧仍可以很好的運行。
專有架構通常需要向上的二進制兼容性,這意味著當處理器公司添加新特性時,所有在此之后的處理器也必須包含這些新特性。而RISC-V則不是如此,所有增強功能都是可選的,如果應用程序不需要,可以刪除。以下是迄今為止的標準擴展名,使用的是代表其全名的縮寫:
M. Integer multiply/divide;
A. Atomic memory operations;
F/D. Single/double-precision floating-point;
C. Compressed instructions。
RISC-V的第三個顯著特征是ISA的簡單性。雖然難以量化,但這里有兩個與ARM公司同期開發的ARMv8架構的比較:
更少的指令。RISC-V的指令要少得多。在基礎版本中只有50個,在數量和性質上與最初的RIS-i驚人地相似。剩下的標準擴展(M,A,F和D)添加了53條指令,再加上C又增加了34條,共計137條。而ARMv8有500多條。
更少的指令格式。 RISC-V的指令格式少了六個,而ARMv8至少有14個。
簡單性減少了設計處理器和驗證硬件正確性的工作量。 由于RISC-V的目標范圍從數據中心芯片到物聯網設備,因此設計驗證可能是開發成本的重要組成部分。
第四,RISC-V是一個全新的設計。與第一代RISC架構不同,它避免了微架構或依賴技術的特性(如延遲分支和延遲加載),也避免了被編譯器技術的進步所取代的創新(如注冊窗口)。
最后,RISC-V通過為自定義加速器保留大量的操作碼空間來支持DSA。
除了RISC-V之外,英偉達還(在2017年)宣布了一種名為NVDLA的免費開放架構,這是一種可伸縮、可配置的機器學習推斷DSA。配置選項包括數據類型(int8、int16或fp16)和二維乘法矩陣的大小。模具尺寸從0.5mm2到3mm2不等,功率從20毫瓦到300毫瓦不等。ISA、軟件堆棧和實現都是開放的。
開放的簡單體系結構與安全性是協同的。
首先,安全專家不相信通過“隱藏”實現的安全性,因此實現開源很有吸引力,而開源的實現需要開放的體系結構。
同樣重要的是,增加能夠圍繞安全架構進行創新的人員和組織的數量。專有架構限制了員工的參與,但是開放架構允許學術界和業界所有最優秀的“頭腦”來幫助共同實現安全性。
最后,RISC-V的簡單性使得它的實現更容易檢查。
此外,開放的架構、實現和軟件棧,加上FPGA的可塑性,意味著架構師可以在線部署和評估新的解決方案,并每周迭代它們,而不是每年迭代一次。雖然FPGA比定制芯片慢10倍,但這種性能仍然足以支持在線用戶。
我們希望開放式架構成為架構師和安全專家進行硬件/軟件協同設計的典范。
輕量級硬件開發
由Beck等人撰寫的《輕量級軟件開發》(The Manifesto for Agile Software Development,2011)徹底改變了軟件開發方式,克服了瀑布式開發中傳統的詳細計劃和文檔的頻繁失敗。小型編程團隊在開始下一次迭代之前快速開發工作原型(但不完整)并獲得了客戶反饋。輕量級開發的scrum版本匯集了5到10個程序員的團隊,每次迭代執行需兩到四周的沖刺。
再次受到軟件成功的啟發,第三個機遇是輕量級硬件開發。對于架構師來說,好消息是現代電子計算機輔助設計(ECAD)工具提高了抽象級別,從而支持輕量級開發,而這種更高的抽象級別增加了設計之間的重用。
但從設計芯片到得到用戶反饋的幾個月之間,像輕量級軟件開發那樣申請“硬件四周的沖刺”似乎是不合理的。
下圖概述了輕量級開發方法如何通過在適當的級別上更改原型來工作。
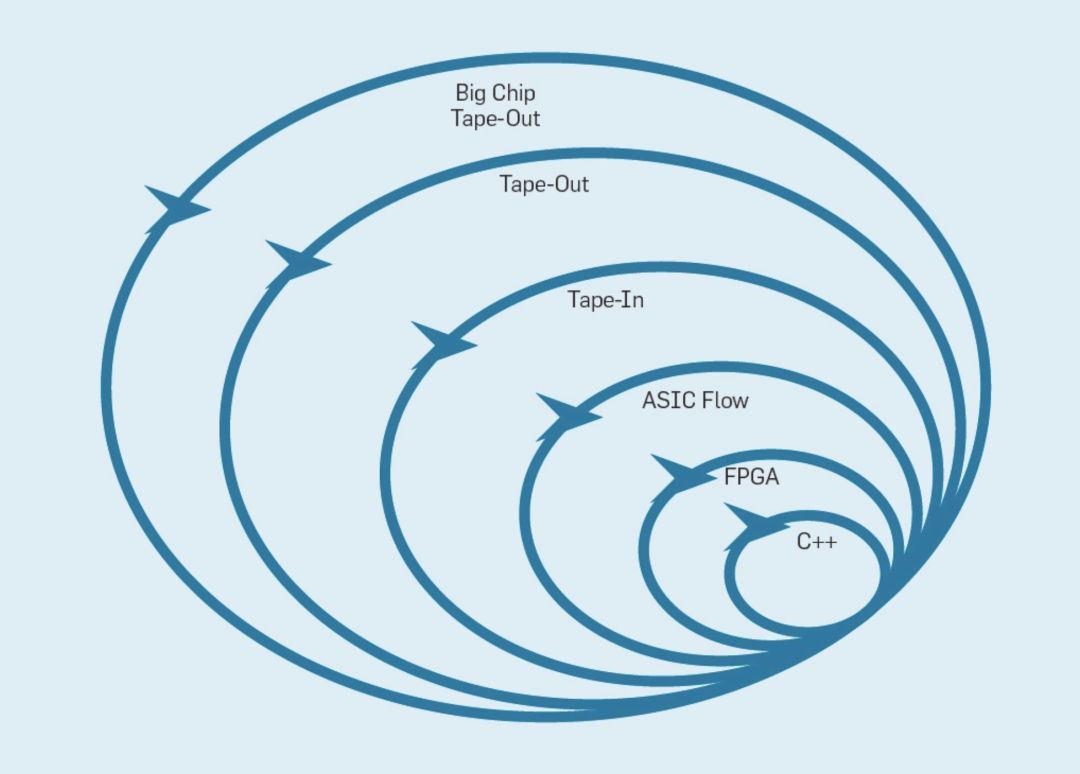
最內層是一個軟件模擬器,如果模擬器能夠滿足迭代,那么這一環節是進行更改最容易和最快的地方。
下一級是FPGA,它的運行速度比一個詳細的軟件模擬器快數百倍。FPGA可以運行像SPEC那樣的操作系統和完整的基準測試,從而可以對原型進行更精確的評估。Amazon Web Services在云中提供FPGA,因此架構師可以使用FPGA,而不需要先購買硬件并建立實驗室。
為了記錄芯片面積和功率的數字,下一個外層使用ECAD工具生成芯片的布局。
即使在工具運行之后,在準備生產新的處理器之前,仍然需要一些手動步驟來細化結果。處理器設計人員將此級別稱為“Tape-In”。
前四個級別都支持為期四周的沖刺。
出于研究目的,當面積、能量和性能評估是非常準確的時候,我們可以停在Tape-In這個級別上。然而,這就像跑一場長跑,在終點前100碼停了下來,盡管在比賽前做了大量的準備工作,運動員還是會錯過真正跨越終點線的興奮和滿足。硬件工程師與軟件工程師相比,其中一個優勢是他們可以構建物理的東西。讓芯片重新測量、運行真實的程序并顯示給朋友和家人,這是硬件設計的一大樂趣。
許多研究人員認為他們必須在此環節停下來,因為制造一個芯片的成本著實太高了。當設計規模較小的時候,它們出奇的便宜:只需14,000美元即可訂購100個1-mm2芯片。在28nm的規格下,1mm2的面積包含數百萬個晶體管,足夠容納一個RISC-V處理器和一個NVLDA加速器。如果設計者的目標是構建一個大型芯片,那么最外層的成本是極其昂貴的,但是架構師可以用小型芯片演示許多新穎的想法。
總結
“黎明前最黑暗。”
——托馬斯·富勒,1650
為了從歷史的教訓中獲益,架構師必須意識到軟件創新也可以激發架構師的興趣,提高硬件/軟件界面的抽象層次可以帶來創新機會,并且市場最終會解決計算機架構的爭論。 iAPX-432和Itanium說明了架構投資如何超過回報,而S/360,8086和ARM提供了長達數十年的高年度回報,并且看不到盡頭。
登納德縮放比例定律和摩爾定律的終結,以及標準微處理器性能增長的減速,這些都不是必須解決的問題,而是公認的事實,并且提供了讓人驚嘆的機遇。
高級、特定于領域的語言和體系結構,將架構師從專有指令集的鏈中解放出來,以及公眾對改進安全性的需求,將為計算機架構師帶來一個新的黃金時代。
在開源生態系統的幫助下,輕量級開發的芯片將會令人信服,從而加速商業應用。這些芯片中通用處理器的ISA理念很可能是RISC,它經受住了時間的考驗。可以期待與上一個黃金時代相同的快速改善,但這一次是在成本、能源、安全以及性能方面。
-
計算機
+關注
關注
19文章
7423瀏覽量
87719 -
圖靈
+關注
關注
1文章
39瀏覽量
9688 -
AI芯片
+關注
關注
17文章
1860瀏覽量
34911
原文標題:兩位圖靈獎得主萬字長文:新計算機架構,黃金十年爆發!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CPU時鐘周期與主頻的關系和區別
CPU時鐘周期的組成和作用
寄存器是什么意思?寄存器是如何構成的?
工業控制計算機的體系結構是什么
寄存器和內存的區別
昉·星光2 RISC-V單板計算機體驗(一) - 開箱

【RISC-V開放架構設計之道|閱讀體驗】學習處理器體系架構的一本好書
智能化的計算機體系結構設計方案
《RVfpga:理解計算機體系結構》3.0 版本更新上線

微機原理接口地址范圍怎么算
馮諾依曼架構和哈佛架構有何不同





 工商網監
工商網監
評論