") 深度強(qiáng)化學(xué)習(xí)大神Pieter Abbeel發(fā)表深度強(qiáng)化學(xué)習(xí)的加速方法
深度強(qiáng)化學(xué)習(xí)大神Pieter Abbeel發(fā)表深度強(qiáng)化學(xué)習(xí)的加速方法
深度強(qiáng)化學(xué)習(xí)一直以來(lái)都以智能體訓(xùn)練時(shí)間長(zhǎng)、計(jì)算力需求大、模型收斂慢等而限制很多人去學(xué)習(xí),比如:AlphaZero訓(xùn)練3天的時(shí)間等,因此縮短訓(xùn)練周轉(zhuǎn)時(shí)間成為一個(gè)重要話(huà)題。
加州大學(xué)伯克利分校教授,Pieter Abbeel最近發(fā)表了深度強(qiáng)化學(xué)習(xí)的加速方法,他從整體上提出了一個(gè)加速深度強(qiáng)化學(xué)習(xí)周轉(zhuǎn)時(shí)間的方法,成功的解決了一些問(wèn)題。
論文地址: https://arxiv.org/pdf/1803.02811.pdf
最近幾年,深度強(qiáng)化學(xué)習(xí)在各行各業(yè)已經(jīng)有了很成功的應(yīng)用,但實(shí)驗(yàn)的周轉(zhuǎn)時(shí)間(turn-around time)仍然是研究和實(shí)踐中的一個(gè)關(guān)鍵瓶頸。
該論文研究如何在現(xiàn)有計(jì)算機(jī)上優(yōu)化現(xiàn)有深度RL算法,特別是CPU和GPU的組合。
且作者確認(rèn)可以調(diào)整策略梯度和Q值學(xué)習(xí)算法以學(xué)習(xí)使用許多并行模擬器實(shí)例。 通過(guò)他們進(jìn)一步發(fā)現(xiàn)可以使用比標(biāo)準(zhǔn)尺寸大得多的批量進(jìn)行訓(xùn)練,而不會(huì)對(duì)樣品復(fù)雜性或最終性能產(chǎn)生負(fù)面影響。
同時(shí)他們利用這些事實(shí)來(lái)構(gòu)建一個(gè)統(tǒng)一的并行化框架,從而大大加快了兩類(lèi)算法的實(shí)驗(yàn)。 所有神經(jīng)網(wǎng)絡(luò)計(jì)算都使用GPU,加速數(shù)據(jù)收集和訓(xùn)練。
在使用同步和異步算法的基礎(chǔ)上,結(jié)果標(biāo)明在使用整個(gè)DGX-1在幾分鐘內(nèi)學(xué)習(xí)Atari游戲中的成功策略。
注: 【1】 周轉(zhuǎn)時(shí)間(turnaround time):訓(xùn)練模型的時(shí)間。【2】. Nvidia DGX-1是Nvidia生產(chǎn)的服務(wù)器和工作站系列,專(zhuān)門(mén)用于使用GPGPU加速深度學(xué)習(xí)應(yīng)用程序。這些服務(wù)器具有8個(gè)GPU,基于帶有HBM 2內(nèi)存的Pascal或Volta 子卡,通過(guò)NVLink 網(wǎng)狀網(wǎng)絡(luò)連接。該產(chǎn)品系列旨在彌合GPU和AI加速器之間的差距,因?yàn)樵撛O(shè)備具有專(zhuān)門(mén)用于深度學(xué)習(xí)工作負(fù)載的特定功能。最初的基于Pascal的DGX-1提供了170 teraflops的半精度處理,而基于Volta的升級(jí)將其提高到960 teraflops。更多信息,點(diǎn)擊查看
背景和相關(guān)內(nèi)容
目前的深度強(qiáng)化學(xué)習(xí)嚴(yán)重依賴(lài)于經(jīng)驗(yàn)評(píng)估,因此turnaround 時(shí)間成為一個(gè)關(guān)鍵的限制因素,盡管存在這一重要瓶頸,但許多參考實(shí)施方案不能滿(mǎn)足現(xiàn)代計(jì)算機(jī)的吞吐量潛力,在這項(xiàng)工作中,作者研究如何在不改變其基本公式的情況下調(diào)整深度RL算法,并在一臺(tái)機(jī)器中更好地利用多個(gè)CPU和GPU進(jìn)行實(shí)驗(yàn)。 結(jié)果標(biāo)明,顯著提高了硬件利用率的效率和規(guī)模,從而提高了學(xué)習(xí)速度。
今天比較領(lǐng)先的深度RL算法大致分為兩類(lèi):
策略梯度方法 ,以Asynchronous Advantage Actor-Critic(A3C)(Mnih et al 2016)是一個(gè)代表性的例子
Q值學(xué)習(xí)方法 ,一個(gè)代表性的例子是Deep Q-Networks(DQN)(Mnih等,2015)
傳統(tǒng)上,這兩個(gè)系列出現(xiàn)在不同的實(shí)現(xiàn)中并使用不同的硬件資源,該篇paper作者將它們統(tǒng)一在相同的擴(kuò)展框架下。
作者貢獻(xiàn)了并行化深度RL的框架,包括用于推理和訓(xùn)練的GPU加速的新技術(shù)。演示了以下算法的多GPU版本:Advantage Actor-Critic(A3C),Proximal Policy Optimization(PPO),DQN,Categorical DQN和Rainbow。
為了提供校準(zhǔn)結(jié)果,作者通過(guò)Arcade學(xué)習(xí)環(huán)境(ALE)測(cè)試我們?cè)谥囟然鶞?zhǔn)測(cè)試的Atari-2600域中的實(shí)現(xiàn)。
同時(shí)使用批量推斷的高度并行采樣可以加速所有實(shí)驗(yàn)的(turnaround)周轉(zhuǎn)時(shí)間,同時(shí)發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)可以使用比標(biāo)準(zhǔn)大得多的批量大小來(lái)學(xué)習(xí),而不會(huì)損害樣本復(fù)雜性或最終游戲分?jǐn)?shù)。
除了探索這些新的學(xué)習(xí)方式之外,作者還利用它們來(lái)大大加快學(xué)習(xí)速度。例如, 策略梯度算法在8-GPU服務(wù)器上運(yùn)行,在10分鐘內(nèi)學(xué)會(huì)成功的游戲策略,而不是數(shù)小時(shí)。
他們同樣將一些標(biāo)準(zhǔn)Q值學(xué)習(xí)的持續(xù)時(shí)間從10天減少到2小時(shí)以下。或者,獨(dú)立的RL實(shí)驗(yàn)可以與每臺(tái)計(jì)算機(jī)的高聚合吞吐量并行運(yùn)行。相信這些結(jié)果有望加速深度研究,并為進(jìn)一步研究和發(fā)展提出建議。
另外,作者對(duì)演員評(píng)論方法的貢獻(xiàn)在很多方面超越了目前的很多人做法,他們主要做了:“”改進(jìn)抽樣組織,使用多個(gè)GPU大大提高規(guī)模和速度,以及包含異步優(yōu)化。
并行,加速的RL框架
作者考慮使用深度神經(jīng)網(wǎng)絡(luò)來(lái)實(shí)驗(yàn)基于CPU的模擬器環(huán)境和策略,在這里描述了一套完整的深度RL并行化技術(shù),可以在采樣和優(yōu)化過(guò)程中實(shí)現(xiàn)高吞吐量。
同時(shí)并對(duì)GPU進(jìn)行均勻處理,每個(gè)都執(zhí)行相同的抽樣學(xué)習(xí)過(guò)程,該策略可以直接擴(kuò)展到各種數(shù)量的GPU。
同步采樣(Synchronized Sampling)
首先將多個(gè) CPU核心 與 單個(gè)GPU 相關(guān)聯(lián)。多個(gè)模擬器在CPU內(nèi)核上以并行進(jìn)程運(yùn)行,并且這些進(jìn)程以同步方式執(zhí)行環(huán)境步驟。在每個(gè)步驟中,將所有單獨(dú)的觀察結(jié)果收集到批處理中以進(jìn)行推理,在提交最后一個(gè)觀察結(jié)果后在GPU上調(diào)用該批處理。 一旦動(dòng)作返回,模擬器再次步驟,依此類(lèi)推,系統(tǒng)共享內(nèi)存陣列提供了動(dòng)作服務(wù)器和模擬器進(jìn)程之間的快速通信。
由于落后效應(yīng)等同于每一步的最慢過(guò)程,同步采樣可能會(huì)減速。步進(jìn)時(shí)間的變化源于不同模擬器狀態(tài)的不同計(jì)算負(fù)載和其他隨機(jī)波動(dòng)。隨著并行進(jìn)程數(shù)量的增加,落后者效應(yīng)會(huì)惡化,但通過(guò)在每個(gè)進(jìn)程中堆疊多個(gè)獨(dú)立的模擬器實(shí)例來(lái)緩解它。每個(gè)進(jìn)程為每個(gè)推理批處理步驟(順序)執(zhí)行所有模擬器。這種安排還允許用于推斷的批量大小增加超過(guò)進(jìn)程數(shù)(即CPU核心),其原理如圖1(a)所示。
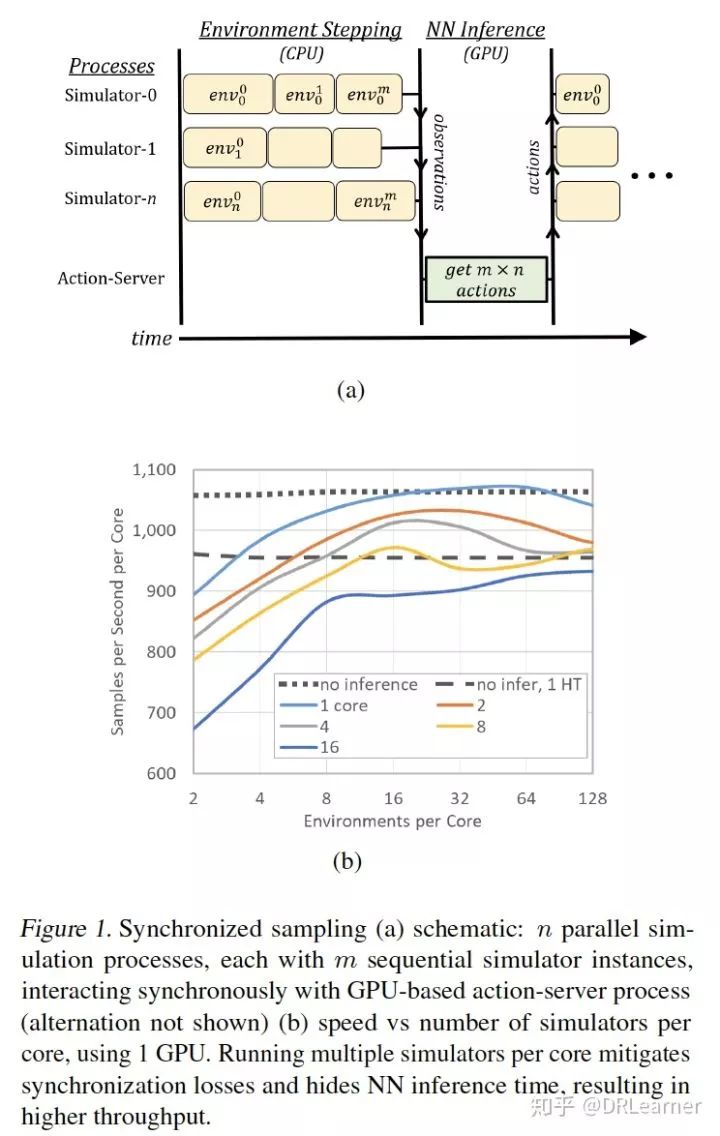
通過(guò)僅在優(yōu)化暫停期間重置可以避免由長(zhǎng)環(huán)境重置引起的減速,如果模擬和推理負(fù)載平衡,則每個(gè)組件將在一半的時(shí)間內(nèi)處于空閑狀態(tài),因此我們形成兩組交替的模擬器過(guò)程。當(dāng)一個(gè)組等待其下一個(gè)動(dòng)作時(shí),其他步驟和GPU在為每個(gè)組服務(wù)之間交替。交替保持高利用率,并且進(jìn)一步隱藏兩者中較快的計(jì)算的執(zhí)行時(shí)間。我們通過(guò)重復(fù)模板組織多個(gè)GPU,均勻分配可用的CPU核心。我們發(fā)現(xiàn)修復(fù)每個(gè)模擬器進(jìn)程的CPU分配是有益的,其中一個(gè)核心保留用于運(yùn)行每個(gè)GPU。實(shí)驗(yàn)部分包含采樣速度的測(cè)量值,該測(cè)量值隨環(huán)境實(shí)例的數(shù)量而增加。
同步多GPU優(yōu)化(Synchronous Multi-GPU Optimization)
在同步算法中,所有GPU都保持相同的參數(shù)值,利用隨機(jī)梯度估計(jì)的數(shù)據(jù)并行性并在每個(gè)GPU上使用眾所周知的更新程序:
使用本地采集的樣本計(jì)算梯度
全部減少GPU之間的梯度
使用組合梯度更新本地參數(shù)。我們使用NVIDIA集體通信庫(kù)在GPU之間進(jìn)行快速通信。
異步多GPU優(yōu)化(Asynchronous Multi-GPU Optimization)
在異步優(yōu)化中,每個(gè)GPU充當(dāng)其自己的采樣器-學(xué)習(xí)器單元,并將更新應(yīng)用于CPU內(nèi)存中保存的中央?yún)?shù)存儲(chǔ)。
使用加速器會(huì)強(qiáng)制選擇執(zhí)行參數(shù)更新的位置。根據(jù)經(jīng)驗(yàn),在GPU上將更快的常見(jiàn)規(guī)則應(yīng)用于網(wǎng)絡(luò)更快。一般更新程序包括三個(gè)步驟:
在本地計(jì)算梯度并將其存儲(chǔ)在GPU上
將當(dāng)前中心參數(shù)拉到GPU上并使用預(yù)先計(jì)算的梯度將更新規(guī)則應(yīng)用于它們
寫(xiě)入更新的參數(shù)回到中央CPU商店
在此序列之后,本地GPU參數(shù)與中心值同步,并且再次進(jìn)行采樣,集中更新規(guī)則參數(shù)。其不會(huì)將更新增量添加到需要CPU計(jì)算的中心參數(shù),而是覆蓋這些值。
因此,采用上述步驟(2)和(3)的鎖定,防止其他進(jìn)程同時(shí)讀取或?qū)懭雲(yún)?shù)值。同時(shí)將參數(shù)分成少量不相交的塊,這些塊分別更新,每個(gè)塊都有自己的鎖(步驟2-3成為塊上的循環(huán))。這可以平衡更新調(diào)用效率與鎖爭(zhēng)用,并可以提供良好的性能。
實(shí)驗(yàn)
使用Atari-2600域來(lái)研究高度并行化RL的縮放特性,研究如下:
同步采樣的效率如何,它可以達(dá)到什么速度?
策略梯度和Qlearning算法是否可以適應(yīng)學(xué)習(xí)使用許多并行模擬器實(shí)例而不會(huì)降低學(xué)習(xí)成績(jī)
大批量培訓(xùn)和/或異步方法能否加快優(yōu)化速度而不會(huì)降低樣品的復(fù)雜性?
在所有學(xué)習(xí)實(shí)驗(yàn)中,作者保持原始訓(xùn)練強(qiáng)度,意味著每個(gè)采樣數(shù)據(jù)點(diǎn)的平均訓(xùn)練使用次數(shù)。
對(duì)于A3C,PPO和DQN+變體,參考訓(xùn)練強(qiáng)度分別為1,4和8。此處顯示的所有學(xué)習(xí)曲線(xiàn)均為至少兩個(gè)隨機(jī)種子的平均值。
對(duì)于策略梯度方法,我們跟蹤在線(xiàn)分?jǐn)?shù),對(duì)最近100個(gè)完成的軌跡進(jìn)行平均。對(duì)于DQN和變體,我們每100萬(wàn)步暫停以評(píng)估,直到達(dá)到125,000步,最大路徑長(zhǎng)度為27,000步。
Sampling(采樣)
一系列僅采樣測(cè)量表明,盡管存在潛在的落后者,同步采樣方案可以實(shí)現(xiàn)良好的硬件利用率。
首先,我們研究了 單個(gè)GPU 在為多個(gè)環(huán)境提供推理時(shí)的容量。圖1(b)顯示了在播放BREAKOUT時(shí)在P100 GPU上運(yùn)行訓(xùn)練有素的A3C-Net策略的測(cè)量結(jié)果。
通過(guò)CPU核心計(jì)數(shù)歸一化的聚合采樣速度被繪制為在每個(gè)核心上運(yùn)行的(順序)Atari模擬器的數(shù)量的函數(shù),交替方案的最小值是每個(gè)核心2個(gè)模擬器。
不同的曲線(xiàn)表示運(yùn)行模擬的不同數(shù)量的CPU核心。作為參考,我們包括在沒(méi)有推斷的情況下運(yùn)行的單個(gè)核心的采樣速度--單個(gè)過(guò)程的虛線(xiàn),以及兩個(gè)超線(xiàn)程中的每一個(gè)的虛線(xiàn)一個(gè)過(guò)程。
使用推理和單核運(yùn)行,采樣速度隨著模擬器計(jì)數(shù)而增加,直到推斷時(shí)間完全隱藏。出現(xiàn)更高核心數(shù)的同步丟失。但是,每個(gè)核心只有8個(gè)環(huán)境,GPU甚至支持16個(gè)CPU內(nèi)核,運(yùn)行速度大約為無(wú)推理速度的80%。
接下來(lái),測(cè)量了在整個(gè)8-GPU,40核服務(wù)器上并行播放BREAKOUT的同一A3C-Net的僅采樣速度。
在模擬器計(jì)數(shù)為256(每個(gè)核心8個(gè))及以上時(shí),服務(wù)器每秒實(shí)現(xiàn)大于35,000個(gè)樣本,或每小時(shí)5億個(gè)仿真器幀,其結(jié)果如圖:
許多模擬器實(shí)例(Learning with Many Simulator Instances)
為了利用并行采樣的高吞吐量,同時(shí)研究了如何使用現(xiàn)有的深度RL算法來(lái)學(xué)習(xí)許多模擬器實(shí)例。
以下研究結(jié)果表明,只有微小的變化才能適應(yīng)所有算法并保持性能。我們?yōu)槊糠N算法嘗試了不同的技術(shù)。有趣的是,縮放對(duì)同步和異步學(xué)習(xí)的影響有所不同。
開(kāi)始狀態(tài)解相關(guān)(Starting State Decorrelation) 在許多模擬器的一些策略梯度實(shí)驗(yàn)中,學(xué)習(xí)很早就失敗了。
我們發(fā)現(xiàn)在起始游戲狀態(tài)中的相關(guān)性導(dǎo)致大的但知情度不足的學(xué)習(xí)信號(hào),從而破壞了早期學(xué)習(xí)的穩(wěn)定性。
通過(guò)在實(shí)驗(yàn)初始化期間通過(guò)隨機(jī)數(shù)量的均勻隨機(jī)動(dòng)作步進(jìn)每個(gè)模擬器來(lái)糾正此問(wèn)題。采取這一措施時(shí),發(fā)現(xiàn)學(xué)習(xí)率升溫沒(méi)有進(jìn)一步的效果。在訓(xùn)練時(shí),游戲重置照常進(jìn)行。
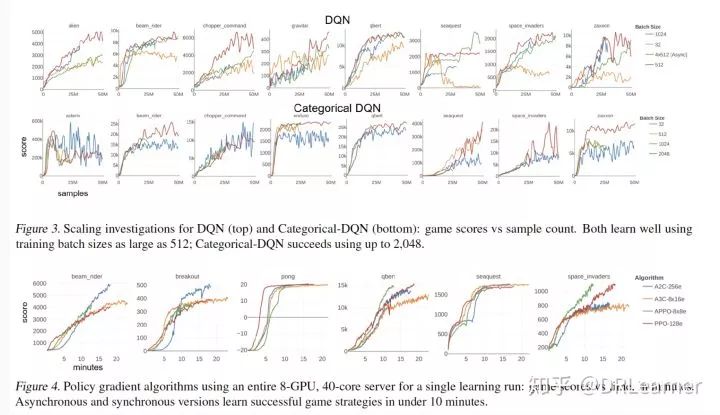
A2C:優(yōu)化批量大小隨著模擬器的數(shù)量而增加(保持采樣范圍固定)。相應(yīng)地,每個(gè)采集的樣本進(jìn)行的參數(shù)更新步驟更少,我們發(fā)現(xiàn),在一組測(cè)試游戲中,以批量大小的平方根增加學(xué)習(xí)率是最佳的。圖2的上圖顯示了學(xué)習(xí)曲線(xiàn)與總樣本數(shù),模擬器計(jì)數(shù)范圍為16到512(批量大小為80到2,560)。雖然大型模擬器計(jì)數(shù)的樣本效率逐漸下降,但游戲分?jǐn)?shù)基本沒(méi)有變化。
A3C:我們測(cè)試的異步適應(yīng)使用16環(huán)境A2C代理作為基礎(chǔ)采樣器 - 學(xué)習(xí)器單元。圖2顯示學(xué)習(xí)曲線(xiàn)與學(xué)習(xí)者數(shù)量的總樣本計(jì)數(shù),范圍從1到32,4,對(duì)應(yīng)于16到512個(gè)模擬器。在大多數(shù)情況下,由此產(chǎn)生的學(xué)習(xí)曲線(xiàn)幾乎無(wú)法區(qū)分,盡管有些學(xué)習(xí)曲線(xiàn)在最大范圍內(nèi)降級(jí)。
PPO:已經(jīng)用于基準(zhǔn)PPO的大批量(8模擬器x 256-horizon = 2,048)提供了與許多模擬器學(xué)習(xí)的不同途徑:我們減少了采樣范圍,使得總批量大小保持固定。圖2顯示了模擬器計(jì)數(shù)從8到512的學(xué)習(xí)曲線(xiàn)與樣本計(jì)數(shù),相應(yīng)的采樣范圍從256到4步。成功的學(xué)習(xí)繼續(xù)保持最大規(guī)模。
APPO:嘗試了PPO的異步版本,使用8模擬器PPO代理作為基礎(chǔ)學(xué)習(xí)器單元。圖2中的底部面板顯示了對(duì)8個(gè)GPU運(yùn)行的8個(gè)學(xué)習(xí)者的研究的學(xué)習(xí)曲線(xiàn),其中通信頻率不同。標(biāo)準(zhǔn)PPO每個(gè)時(shí)期使用4個(gè)梯度更新,每個(gè)優(yōu)化使用4個(gè)時(shí)期;我們?cè)谕街g進(jìn)行了1-4次漸變更新(補(bǔ)充材料中提供了更新規(guī)則)。我們發(fā)現(xiàn)在采樣期間定期從中心參數(shù)中提取新值是有幫助的,并且在所有情況下都采用64步的范圍(因此減少了異步技術(shù)中固有的策略滯后,PPO的頻率降低,但更頻繁,但更實(shí)質(zhì)性的更新) 。在幾個(gè)游戲中,學(xué)習(xí)保持一致,表明可以減少某些異步設(shè)置中的通信。
DQN + Variants:我們通過(guò)模擬器組織了體驗(yàn)重放緩沖區(qū)。總緩沖區(qū)大小保持在1百萬(wàn)次轉(zhuǎn)換,因此每個(gè)模擬器保持相應(yīng)較短的歷史記錄。我們觀察到學(xué)習(xí)性能在很大程度上獨(dú)立于模擬器計(jì)數(shù)高達(dá)200以上,前提是每個(gè)優(yōu)化周期的更新步驟數(shù)不是太多(大批量大小可以改善這一點(diǎn))。
Q-Value Learning with Large Training Batches
DQN:我們?cè)囼?yàn)了從標(biāo)準(zhǔn)32到2,048的批量大小。我們發(fā)現(xiàn)一致的學(xué)習(xí)成績(jī)高達(dá)512,超過(guò)這一點(diǎn),很難找到在所有測(cè)試游戲中表現(xiàn)良好的單一(縮放)學(xué)習(xí)率。在幾個(gè)游戲中,更大的批量大小改進(jìn)了學(xué)習(xí),如圖3所示。

發(fā)現(xiàn)異步DQN可以使用多達(dá)4個(gè)GPU學(xué)習(xí)者很好地學(xué)習(xí),每個(gè)學(xué)習(xí)者使用批量大小512。
分類(lèi)DQN:我們發(fā)現(xiàn)分類(lèi)DQN比DQN進(jìn)一步擴(kuò)展。圖3的下顯示批量大小高達(dá)2,048的學(xué)習(xí)曲線(xiàn),最大分?jǐn)?shù)沒(méi)有減少。
這可能是由于梯度信號(hào)的內(nèi)容更豐富。值得注意的是,SEAQUEST游戲中最大批量的學(xué)習(xí)被延遲,但最終達(dá)到了更高的最高分。由于使用了Adam優(yōu)化器,因此沒(méi)有必要縮放學(xué)習(xí)率。
e-Rainbow:盡管使用了分布式學(xué)習(xí),但在某些游戲中,e-Rainbow的性能卻超過(guò)批量512。該批次大小的分?jǐn)?shù)大致與批量大小為32的文獻(xiàn)中報(bào)道的分?jǐn)?shù)相符(Hessel等,2017)(曲線(xiàn)顯示在附錄中)。
學(xué)習(xí)速度(Learning Speed)
研究運(yùn)行8-GPU,40核服務(wù)器(P100 DGX-1),以學(xué)習(xí)單個(gè)游戲時(shí)可獲得的學(xué)習(xí)速度,作為大規(guī)模實(shí)施的示例。

圖4顯示了策略梯度方法A2C,A3C,PPO和APPO的良好性能配置的結(jié)果。幾場(chǎng)比賽表現(xiàn)出陡峭的初始學(xué)習(xí)階段;所有算法都在10分鐘內(nèi)完成了該階段。值得注意的是,PPO在4分鐘內(nèi)掌握了Pong。
具有256個(gè)環(huán)境的A2C每秒處理超過(guò)25,000個(gè)樣本,相當(dāng)于每小時(shí)超過(guò)9000萬(wàn)步(3.6億幀)。表2列出了縮放測(cè)量,顯示使用8個(gè)GPU相對(duì)于1的加速比大于6倍。
我們運(yùn)行了DQN及其變體的同步版本,訓(xùn)練時(shí)間如表2所示。使用1個(gè)GPU和5個(gè)CPU核心,DQN和e-Rainbow分別在8小時(shí)和14小時(shí)內(nèi)完成了5000萬(wàn)步(2億幀),一個(gè)重要的獲得超過(guò)10天的參考時(shí)間。
后者使用1個(gè)GPU和376個(gè)CPU核心(參見(jiàn)例如圖2中的10小時(shí)學(xué)習(xí)曲線(xiàn))。使用多個(gè)GPU和更多內(nèi)核加速了我們的實(shí)施。
憑借更大的批量大小,Categorical-DQN使用整個(gè)服務(wù)器在2小時(shí)內(nèi)完成最佳擴(kuò)展和完成培訓(xùn),相對(duì)于1 GPU,速度超過(guò)6倍。
然而,DQN和e-Rainbow的回報(bào)減少超過(guò)2個(gè)GPU。我們無(wú)法找到進(jìn)一步提高學(xué)習(xí)速度而不會(huì)在某些游戲中降低性能的異步配置(我們只測(cè)試了完全通信的算法)。可能存在改善我們擴(kuò)展的機(jī)會(huì)。

批量大小對(duì)優(yōu)化的影響(Effects of Batch Size on Optimization)
限制培訓(xùn)批量大小的可能因素包括:
(1) 減少探索,因?yàn)樵诃h(huán)境中運(yùn)行的網(wǎng)絡(luò)較少
(2) 網(wǎng)絡(luò)權(quán)重的數(shù)值優(yōu)化存在困難
我們進(jìn)行了實(shí)驗(yàn)以開(kāi)始識(shí)別這些因素。
二級(jí)學(xué)習(xí)者實(shí)驗(yàn)(Secondary-Learner Experiment)
我們配置了一個(gè)輔助DQN學(xué)習(xí)器,僅使用普通DQN代理的重放緩沖區(qū)進(jìn)行訓(xùn)練。
初級(jí)學(xué)習(xí)者使用與主要參數(shù)值相同的參數(shù)值進(jìn)行初始化, “采樣器 - 學(xué)習(xí)器”,兩個(gè)網(wǎng)絡(luò)同時(shí)訓(xùn)練,數(shù)據(jù)消耗速率相同。每個(gè)人都抽樣自己的培訓(xùn)批次。
在BREAKOUT的游戲中,64和2048采樣器學(xué)習(xí)者獲得了相同的分?jǐn)?shù),但是2048學(xué)習(xí)者需要更多的樣本,盡管使用最快的穩(wěn)定學(xué)習(xí)率(數(shù)字指的是訓(xùn)練批量大小)。
當(dāng)使用2048樣本學(xué)習(xí)者訓(xùn)練64中學(xué)習(xí)者時(shí),中學(xué)習(xí)者的分?jǐn)?shù)跟蹤了初級(jí)學(xué)習(xí)者的分?jǐn)?shù)。然而,在相反的情況下,2048中學(xué)生無(wú)法學(xué)習(xí)。
我們認(rèn)為這是由于參數(shù)更新數(shù)量減少的優(yōu)化速度較慢 - 它無(wú)法跟蹤初始化附近的Q值估計(jì)的快速變化,并且變得過(guò)于偏離策略學(xué)習(xí)。
在使用兩個(gè)256學(xué)習(xí)者的相同測(cè)試中,他們的分?jǐn)?shù)相匹配。如果2048年的二級(jí)學(xué)習(xí)者超過(guò)了2048年的樣本學(xué)習(xí)者,那么就會(huì)認(rèn)為探索是一個(gè)比優(yōu)化更重要的因素。有關(guān)數(shù)據(jù),請(qǐng)參閱補(bǔ)充材料。
更新規(guī)則(Update Rule)
我們進(jìn)行了一項(xiàng)實(shí)驗(yàn),以確定更新規(guī)則對(duì)分類(lèi)DQN中的優(yōu)化的影響。我們發(fā)現(xiàn)Adam公式優(yōu)于RMSProp,為大批量學(xué)習(xí)者提供了在學(xué)習(xí)過(guò)程中遍歷參數(shù)空間的能力。
當(dāng)比較實(shí)現(xiàn)相同學(xué)習(xí)曲線(xiàn)的代理時(shí),那些使用較小批量(并因此執(zhí)行更多更新步驟)的代理傾向于在訓(xùn)練中的所有點(diǎn)具有更大的參數(shù)矢量規(guī)范。
與RMSProp不同,Adam規(guī)則導(dǎo)致批量大小之間參數(shù)規(guī)范的相當(dāng)緊密的傳播,而不會(huì)改變學(xué)習(xí)率。
這解釋了在分類(lèi)DQN和e-Rainbow中不需要縮放學(xué)習(xí)率,并且表明更新規(guī)則在縮放中起著重要作用。更多細(xì)節(jié),包括卷積和完全連通層的趨勢(shì).
關(guān)于更新規(guī)則和批量大小規(guī)模的觀察的細(xì)節(jié)
我們?cè)趦蓚€(gè)不同的參數(shù)更新規(guī)則下提出了縮放訓(xùn)練批量大小對(duì)神經(jīng)網(wǎng)絡(luò)優(yōu)化的影響的觀察結(jié)果:Adam和RMSProp(沒(méi)有動(dòng)量的RMSProp,只有平方梯度的直接累積,參見(jiàn)例如:
https://github.com/Lasagne/Lasagne/blob/master/lasagne/updates.py
我們?cè)谟螒騋 * BERT上培訓(xùn)代理,調(diào)整學(xué)習(xí)率以產(chǎn)生非常相似的所有設(shè)置的性能曲線(xiàn),并且我們?cè)趯W(xué)習(xí)期間跟蹤了幾個(gè)量的L-2矢量規(guī)范。
這些包括漸變,參數(shù)更新步驟和參數(shù)值本身。與本文中的所有DQN實(shí)驗(yàn)一樣,訓(xùn)練強(qiáng)度固定為8,因此學(xué)習(xí)期間參數(shù)更新步驟的數(shù)量與批量大小成反比。每個(gè)設(shè)置運(yùn)行兩個(gè)隨機(jī)種子。
盡管整個(gè)訓(xùn)練過(guò)程中游戲分?jǐn)?shù)大致相同,但在任何一點(diǎn)上找到的確切解決方案都沒(méi)有,正如不同的參數(shù)規(guī)范所證明的那樣。沒(méi)有使用正規(guī)化。
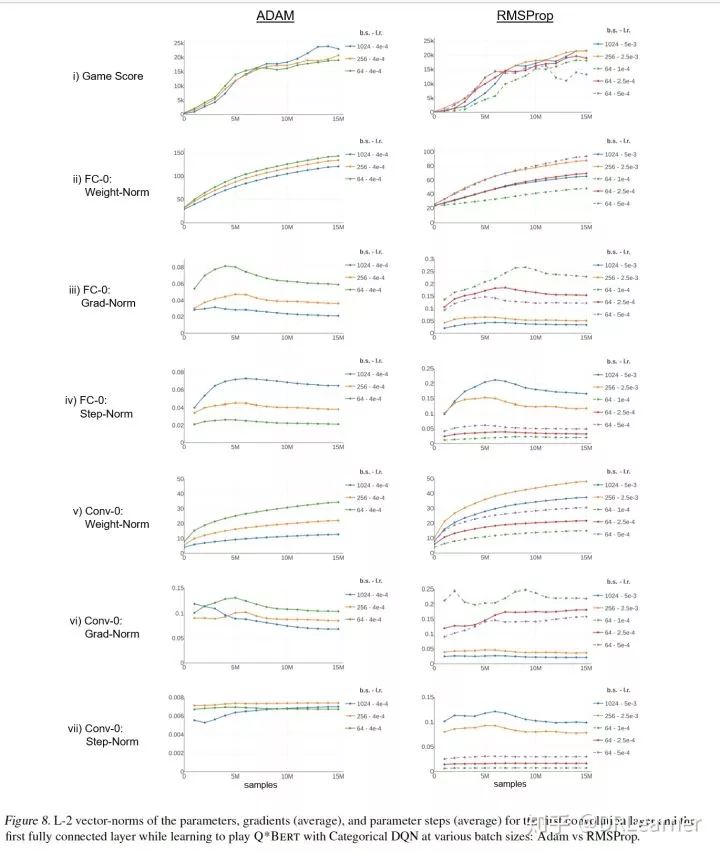
根據(jù)圖-8,其中曲線(xiàn)由批量大小和學(xué)習(xí)率標(biāo)記。當(dāng)整體觀察網(wǎng)絡(luò)(即所有權(quán)重和偏差的規(guī)范作為單個(gè)向量)時(shí),趨勢(shì)反映了在大多數(shù)權(quán)重為的FC-0中看到的趨勢(shì)。
(i)學(xué)習(xí)曲線(xiàn):我們控制游戲得分,根據(jù)需要調(diào)整學(xué)習(xí)率。對(duì)于批量大小為64的RMSProp,我們考慮的學(xué)習(xí)率略低(1×10^(-4)),學(xué)習(xí)速度慢,最終得分較低,學(xué)習(xí)率略高(5*10^-4) ),由于不穩(wěn)定性而產(chǎn)生較低的最終得分 - 這些是所有面板中的虛線(xiàn)。
(ii)完全連接-0 Weights-Norm:盡管對(duì)所有設(shè)置使用相同的學(xué)習(xí)速率,但Adam優(yōu)化器產(chǎn)生了相當(dāng)緊密的分組。另一方面,RMSProp學(xué)習(xí)者需要在批量大小為64到1,024之間將學(xué)習(xí)率提高20倍,然后產(chǎn)生非常相似的規(guī)范。在批量大小64處,慢/不穩(wěn)定學(xué)習(xí)分別以小/大規(guī)范為特征。批量大小256次運(yùn)行的大規(guī)范表明這種學(xué)習(xí)率可能接近穩(wěn)定性的上限。
(iii)完全連接-0梯度 - 范數(shù):在兩個(gè)更新規(guī)則下,大批量大小總是產(chǎn)生較小的梯度向量 - 減小的方差導(dǎo)致減小的量值。在查看總梯度范數(shù)時(shí),我們還在策略梯度方法中觀察到了這種模式。這里,梯度的大小與參數(shù)范數(shù)成反比;請(qǐng)參閱RMSProp 64批量大小的曲線(xiàn)。這種效果與批量大小的影響相反并且被抵消了。
( iv)完全連接-0步驟規(guī)范:盡管梯度較小,但Adam優(yōu)化器為較大批量學(xué)習(xí)者產(chǎn)生了明顯更大的步長(zhǎng)。 RMSProp需要調(diào)整學(xué)習(xí)率才能產(chǎn)生相同的效果。在兩個(gè)更新規(guī)則下,步長(zhǎng)增加量并未完全補(bǔ)償步數(shù)的減少,這表明較大的批量學(xué)習(xí)者通過(guò)參數(shù)空間遵循更直的軌跡。 RMSProp總體上導(dǎo)致了更大的步驟,但盡管以較小的權(quán)重結(jié)束了學(xué)習(xí) - 其學(xué)習(xí)軌跡顯然不那么直接,更蜿蜒。
(v)卷積-0權(quán)重 - 范數(shù):亞當(dāng)優(yōu)化器在這里的規(guī)范中比在FC-0層中擴(kuò)展得更多;隨著批量增加,學(xué)習(xí)重點(diǎn)從Conv-0轉(zhuǎn)移。但是在RMSProp中,學(xué)習(xí)率的提高導(dǎo)致第一個(gè)卷積層對(duì)于更大的批量大小變大,更加強(qiáng)調(diào)這一層。
(vi)卷積-0梯度 - 范數(shù):亞當(dāng)更新規(guī)則在梯度范數(shù)中產(chǎn)生了一個(gè)有趣的交叉;大批量學(xué)習(xí)者實(shí)際上開(kāi)始走高,抵消了其他情況下看到的趨勢(shì)。 RMSProp下的模式與FC-0的模式相匹配。
(vii)卷積-0步驟范數(shù):與FC-0不同,步驟范數(shù)在Adam下的批量大小沒(méi)有顯著變化。 RMSProp產(chǎn)生了與FC-0類(lèi)似的模式。總體而言,Adam優(yōu)化器似乎可以補(bǔ)償FC-0層中的批量大小,但在Conv-0層中則較少,導(dǎo)致Conv-0中大批量學(xué)習(xí)時(shí)不再?gòu)?qiáng)調(diào)。 RMSProp中學(xué)習(xí)率的提高補(bǔ)償了FC-0層中的批量大小,并增加了對(duì)Conv-0學(xué)習(xí)的重視程度。這種模式可能會(huì)對(duì)學(xué)習(xí)表示與游戲策略產(chǎn)生影響。對(duì)這些明顯趨勢(shì)的進(jìn)一步研究可以深入了解學(xué)習(xí)退化的原因以及大批量RL的可能解決方案。

梯度估計(jì)飽和度(Gradient Estimate Saturation)
使用A2C,我們?cè)诿看蔚鷷r(shí)測(cè)量正常,全批次梯度和僅使用批次的一半計(jì)算的梯度之間的關(guān)系。對(duì)于小批量試劑,測(cè)量的全批次和半批次梯度之間的平均余弦相似度接近1 =P2。
這意味著兩個(gè)半批漸變是正交的,高維空間中的零中心隨機(jī)向量也是正交的。 然而,對(duì)于大批量學(xué)習(xí)者(例如256個(gè)環(huán)境),余弦相似性在1 = p2之上顯著增加。 梯度估計(jì)的飽和度明顯與較差的樣本效率相關(guān),如圖2頂部的學(xué)習(xí)曲線(xiàn)所示。

總結(jié)
:
我們引入了一個(gè)統(tǒng)一的框架來(lái)并行化深度RL,它使用硬件加速器來(lái)實(shí)現(xiàn)快速學(xué)習(xí)。該框架適用于一系列算法,包括策略梯度和Q值學(xué)習(xí)方法。
我們的實(shí)驗(yàn)表明,幾種領(lǐng)先的算法可以高度并行的方式學(xué)習(xí)各種Atari游戲,而不會(huì)損失樣本復(fù)雜性和前所未有的掛鐘時(shí)間。
該結(jié)果表明了顯著提高實(shí)驗(yàn)規(guī)模的有希望的方向。我們將發(fā)布代碼庫(kù)。我們注意到擴(kuò)展該框架的幾個(gè)方向。
首先是將其應(yīng)用于Atari以外的領(lǐng)域,尤其是涉及感知的領(lǐng)域。其次,由于GPU加速推理和訓(xùn)練,我們的框架很可能有利地?cái)U(kuò)展到更復(fù)雜的神經(jīng)網(wǎng)絡(luò)代理。
此外,隨著網(wǎng)絡(luò)復(fù)雜性的增加,擴(kuò)展可能變得更容易,因?yàn)镚PU可以以較小的批量大小有效地運(yùn)行,盡管通信開(kāi)銷(xiāo)可能會(huì)惡化。
降低精度算術(shù)可以加速學(xué)習(xí) - 由于使用基于CPU的推理,在深度RL中尚待探索的主題。當(dāng)前的單節(jié)點(diǎn)實(shí)現(xiàn)可以是用于分布式算法的構(gòu)建塊。
關(guān)于深度RL中可能的并行化程度的問(wèn)題仍然存在。我們還沒(méi)有最終確定縮放的限制因素,也沒(méi)有確定每個(gè)游戲和算法是否相同。
雖然我們已經(jīng)看到大批量學(xué)習(xí)中的優(yōu)化效果,但其他因素仍然存在。異步擴(kuò)展的限制仍未得到探索;我們沒(méi)有明確確定這些算法的最佳配置,但只提供了一些成功的版本。
更好的理解可以進(jìn)一步提高縮放率,這是推動(dòng)深度RL的一個(gè)有希望的方向。
-
gpu
+關(guān)注
關(guān)注
28文章
4700瀏覽量
128697 -
模擬器
+關(guān)注
關(guān)注
2文章
867瀏覽量
43165 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
266瀏覽量
11213
原文標(biāo)題:Pieter Abbeel:深度強(qiáng)化學(xué)習(xí)加速方法
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是深度強(qiáng)化學(xué)習(xí)?深度強(qiáng)化學(xué)習(xí)算法應(yīng)用分析

深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
薩頓科普了強(qiáng)化學(xué)習(xí)、深度強(qiáng)化學(xué)習(xí),并談到了這項(xiàng)技術(shù)的潛力和發(fā)展方向
如何深度強(qiáng)化學(xué)習(xí) 人工智能和深度學(xué)習(xí)的進(jìn)階
深度強(qiáng)化學(xué)習(xí)是否已經(jīng)到達(dá)盡頭?
深度強(qiáng)化學(xué)習(xí)的筆記資料免費(fèi)下載
深度強(qiáng)化學(xué)習(xí)到底是什么?它的工作原理是怎么樣的
DeepMind發(fā)布強(qiáng)化學(xué)習(xí)庫(kù)RLax
模型化深度強(qiáng)化學(xué)習(xí)應(yīng)用研究綜述

基于深度強(qiáng)化學(xué)習(xí)仿真集成的壓邊力控制模型
基于深度強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)控制律設(shè)計(jì)方法
《自動(dòng)化學(xué)報(bào)》—多Agent深度強(qiáng)化學(xué)習(xí)綜述

ESP32上的深度強(qiáng)化學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論