 mysql8.0中的無鎖重做日志源碼介紹
mysql8.0中的無鎖重做日志源碼介紹
InnoDB 和大部分的存儲引擎一樣, 都是采用WAL 的方式進行寫入數據,所有的數據都先寫入到redo log, 然后后續再從buffer pool 刷臟到數據頁又或者是備份恢復的時候從redo log 恢復到buffer poll, 然后在刷臟到數據頁,WAL很重要的一點是將隨機寫轉換成了順序寫, 所以在機械磁盤時代,順序寫的性能遠遠大于隨機寫的背景下, 充分利用了磁盤的性能. 但是也帶來一個問題, 就是任何的寫入操作都必須加鎖訪問, 保證上一個寫入操作完成以后, 才能進行下一個寫入操作.在 InnoDB 早期版本也是這樣實現, 但是隨著cpu 核數的增長,這樣頻繁的加鎖就無法發揮多核的性能, 所以在InnoDB 8.0 改成了無鎖實現這個是官方的介紹:https://mysqlserverteam.com/mysql-8-0-new-lock-free-scalable-wal-design
5.6 版本實現
有兩個操作需要獲得全局的mutex, log_sys_t::mutex, log_sys_t::flush_order_mutex
每一個用戶連接有一個線程, 要寫入數據之前必須先獲得log_sys_t::mutex,用來保證只有一個用戶線程在寫入log buffer那么隨著連接數的增加, 這個性能必然會受到影響
同樣的在把已經寫入完成的redo log 加入到flush list 的時候,為了保證只有一個用戶線程從log buffer 上添加buffer 到flush list,因此需要去獲得log_sys_t::flush_order_mutex 來保證
如圖:
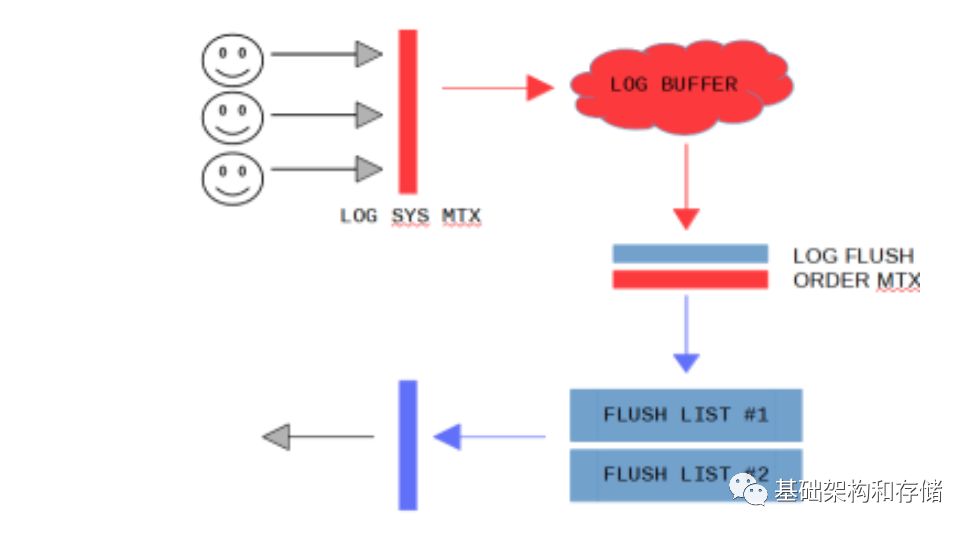
因此在5.6 版本的實現中, 我們需要先獲得log_sys_t::mutex, 然后寫入buffer,然后獲得log_sys_t::flush_order_mutex, 釋放log_sys_t::mutex, 然后把對應的 page加入到flush list
所以8.0 無鎖實現主要就是要去掉這兩個mutex
8.0 無鎖實現
log_sys_t::mutex*
在去掉第一個log_sys_t::mutex 的時候, 通過在寫入之前先預先分配地址,然后在寫入的時候往指定地址寫入, 這樣就無需搶mutex.同樣, 問題來了:所有的線程都去獲得lsn 地址的時候, 同樣需要有一個mutex 來防止沖突, InnoDB通過使用atomic 來達到無鎖的實現, 即: const sn_t start_sn = log.sn.fetch_add(len);
在每一個線程獲得了自己要寫入的lsn 的位置以后, 寫入自然就可以并發起來了.
那么在寫入的時候, 如果位置在前面的線程未寫完, 而位置靠后的已經寫完了,這個時候我該如何將Log buffer 中的內容寫入到redo log,肯定不允許寫入的數據有空洞.
8.0 里面引入了log_writer 線程, log_writer 線程去檢查log buffer 是否有空洞.具體實現是引入了叫 recent_written 用來記錄log buffer 是否連續, 這個recent_written 是一個link_buf 實現, 類型于并查集. 因此最大t允許并發寫入的大小就是這個recent_written 的大小
link_buf 實現如圖:

這個后臺線程在用戶寫入數據到recent_written buffer 的時候, 就被喚醒,檢查這個recent_written 連續的位置是否可以往前推進, 如果可以, 就往前走,將recent_written buffer 中的內容寫入到redo log
log_sys_t::flush_order_mutex
如果不去掉flush_order_mutex, 用戶線程依然無法并發起來, 因為用戶線程在寫完redolog 以后, 需要把對應的page 加入到flush list才可以退出, 而加入到flush list需要去獲得 flush_order_mutex 鎖, 才能保證順序的加入flush list.因此也必須把flush_order_mutex 去掉.
具體做法允許把log buffer 中的對應的臟頁無序的添加到flush list. 用戶寫完logbuffer 以后就可以把對應的 log buffer 對應的臟頁添加到flush list.而無需去搶flush_order_mutex. 這樣可能出現加入到flush list 上的page lsn 是無序的,因此在做checkpoint 的時候, 就無法保證每一個flush list 上面最頭的page lsn是最小的
InnoDB 用一個recent_closed 來記錄添加到flush list 的這一段log buffer 是否連續,那么容易得出, flush list 上page lsn - recent_closed.size() 得到的lsn用于做checkpoint 肯定的安全的.
同樣, InnoDB 后臺有Log_closer 線程定期檢查recent_closed 是否連續, 如果連續就把recent_closed buffer 向前推進, 那么checkpoint 的信息也可以往前推進了
所以在8.0 的實現中, 把一個write redo log 的操作分成了幾個階段
獲得寫入位置, 實現: 用戶線程
寫入數據到log buffer 實現: 用戶線程
將log buffer 中的數據寫入到 redo log 文件 實現: log writer
將redo log 中的page cache flush 到磁盤 實現: log flusher
將redo log 中的log buffer 對應的page 添加到flush list
更新可以打checkpoint 位點信息 recent_closed 實現: log closer
根據recent_closed 打checkpoint 信息 實現: log checkpointer
代碼實現
redo log 里面主要的內存結構
log file. 也就是我們常見的ib_logfile 文件
log buffer, 通常的大小是64M. 用戶在寫入的時候先從mtr 拷貝到redo log buffer, 然后在log buffer 里面會加入相應的header/footer 信息, 然后由log buffer 刷到redo log file.
log recent written buffer 默認大小是4M, 這個是MySQL 8.0 加入的, 為的是提高寫入時候的concurrent, 早5.6 版本的時候, 寫入Log buffer 的時候是需要獲得Lock, 然后順序的寫入到Log Buffer. 在8.0 的時候做了優化, 寫入log buffer 的時候先reserve 空間, 然后后續的時候寫入就可以并行的寫入了, 也就是這一段的內容是允許有空洞的.

log recent closed buffer 默認大小也是4M, 這個也是MySQL 8.0 加入的, 可以理解為log recent written buffer 在這個log buffer 的最前面, log recent closed buffer 在log buffer 的最后面. 也是為了添加到flush list 的時候提供concurrent. 具體實現方式和log recent written buffer 類似. 5.6 版本的時候, 將page 添加到flush list 的時候, 必須有一個Mutex 加鎖, 然后按照順序的添加到flush list 上. 8.0 的時候運行recent closed buffer 大小的page 是并行的加入到flush list, 也就是這一段的內容是允許有空洞的.
log write ahead buffer 默認大小是 4k, 用于避免寫入小于4k 大小數據的時候需要先將磁盤上的讀取, 然后修改一部分的內容, 在寫入回去.
主要的lsn
log.write_lsn
這個lsn 是到這個lsn 為止, 之前所有的data 已經從log buffer 寫到log files了, 但是并沒有保證這些log file 已經flush 到磁盤上了, 下面log.fushed_to_disk_lsn 指的才是已經flush 到磁盤的lsn 了.
這個值是由log writer thread 來更新
log.buf_ready_for_write_lsn
這個lsn 主要是由于redo log 引入的concurrent writes 才引進的, 也就是log recent written buffer. 也就是到了這個lsn 為止, 之前的log buffer 里面都不會有空洞,
這個值也是由 log writer thread 來更新
log.flushed_to_disk_lsn
到了這個lsn 為止, 所有的寫入到redo log 的數據已經flush 到log files 上了
這個值是由log flusher thread 來更新
所以有 log.flushed_to_disk_lsn <= log.write_lsn <= log.buf_ready_for_write_lsn
log.sn
也就是不算上12字節的header, 4字節的checksum 以后的實際寫入的字節數信息. 通常用這個log.sn 去換算獲得當前的current_lsn
*current_lsn = log_get_lsn(log);inline lsn_t log_get_lsn(const log_t &log) { return (log_translate_sn_to_lsn(log.sn.load()));}constexpr inline lsn_t log_translate_sn_to_lsn(lsn_t sn) { return (sn / LOG_BLOCK_DATA_SIZE * OS_FILE_LOG_BLOCK_SIZE + sn % LOG_BLOCK_DATA_SIZE + LOG_BLOCK_HDR_SIZE);}
以下幾個lsn 跟checkpoint 相關
log.buffer_dirty_pages_added_up_to_lsn
到這個lsn 為止, 所有的redo log 對應的dirty page 已經添加到buffer pool 的flush list 了.
這個值其實就是recent_closed.tail()
inline lsn_t log_buffer_dirty_pages_added_up_to_lsn(const log_t &log) { return (log.recent_closed.tail());}
這個值由log closer thread 來更新
log.available_for_checkpoint_lsn
到這個lsn 為止, 所有的redo log 對應的dirty page 已經flush 到btree 上了, 因此這里我們flush 的時候并不是順序的flush, 所以有可能存在有空洞的情況, 因此這個lsn 的位置并不是最大的redo log 已經被flush 到btree 的位置. 而是可以作為checkpoint 的最大的位置.
這個值是由log checkpointer thread 來更新
log.last_checkpoint_lsn
到這個lsn 為止, 所有的btree dirty page 已經flushed 到disk了, 并且這個lsn 值已經被更新到了ib_logfile0 這個文件去了.
這個lsn 也是下一次recovery 的時候開始的地方, 因為last_checkpoint_lsn 之前的redo log 已經保證都flush 到btree 中去了. 所以比這個lsn 小的redo log 文件已經可以刪除了, 因為數據已經都flush 到btree data page 中去了.
這個值是由log checkpointer thread 來更新
所以log.last_checkpoint_lsn <= log.available_for_checkpoint_lsn <= log.buf_dirty_pages_added_up_to_lsn
為什么會有這么多的lsn?
主要還是由于寫redo log 這個過程被拆開成了多個異步的流程.
先寫入到log buffer, 然后由log writer 異步寫入到 redo log, 然后再由log flusher 異步進行刷新.
中間在log writer 寫入到 redo log 的時候, 引入了log recent written buffer 來提高concurrent 寫入性能.
同時在把這個page 加入到flush list 的時候, 也一樣是為了提高并發, 增加了recent_closed buffer.
redo log 模塊后臺thread


在啟動的函數 Log_start_background_threads 的時候, 會把相應的線程啟動
os_thread_create(log_checkpointer_thread_key, log_checkpointer, &log); os_thread_create(log_closer_thread_key, log_closer, &log); os_thread_create(log_writer_thread_key, log_writer, &log); os_thread_create(log_flusher_thread_key, log_flusher, &log); os_thread_create(log_write_notifier_thread_key, log_write_notifier, &log); os_thread_create(log_flush_notifier_thread_key, log_flush_notifier, &log);
這里主要有
log_writer:
log_writer 這個線程等在writer_event 這個os_event上, 然后判斷的是 log.write_lsn.load() < ready_lsn. 這個ready_lsn 是去掃一下log buffer, 判斷是否有新的連續的內存了. 這個線程主要做的事情就是不斷去檢查 log buffer 里面是否有連續的已經寫入數據的內存 buffer, ?執行的函數是 log_writer_write_buffer()=>log_files_write_buffer()=>write_blocks()=>fil_redo_io() =>shard->do_redo_io()=>os_file_write() =>...=> pwrite(m_fh, m_buf, m_n, m_offset);
這里這個io 是同步, 非direct IO.
將這部分的數據內容刷到redolog 中去, 但是不執行fsync 命令, 具體執行fsync 命令的是log_flusher.
問題: 誰來喚醒Log_writer 這個線程?
正常情況下. srv_flush_log_at_trx_commit == 1 的時候是沒有人去喚醒這個log_writer, 這個os_event_wait_for 是在pthread_cond_timedwait 上的, 這個時間為 srv_log_writer_timeout = 10 微秒.
這個線程被喚醒以后, 執行log_writer_write_buffer() 后, 在執行Log_files_write_buffer() 函數里面 執行 notify_about_advanced_write_lsn() 函數去喚醒write_notifier_event,
同時, 在執行完成 log_writer_write_buffer() 后. 會判斷srv_flush_log_at_trx_commit == 1 就去喚醒 log.flusher_event
log_write_notifier:
log_write_notifer 是等待在 write_notifier_event 這個os_event上, 然后判斷的是 log.write_lsn.load() >= lsn, lsn 是上一次的log.write_lsn. 也就是判斷Log.write_lsn 有沒有增加, 如果有增加就喚醒這個log_write_notifier, 然后log_write_notifier 就去喚醒那些等待在 log.write_events[slot] 的用戶thread.
從上面可以看到, 由log_writer 執行os_event_set 喚醒
有哪些線程等待在log.write_events上呢?
都是用戶的thread 最后會等待在Log.write_events上, 用戶的線程調用log_write_up_to, 最后根據
srv_flush_log_at_trx_commit 這個變量來判斷是執行
!=1 log_wait_for_write(log, end_lsn); 然后等待在log.write_events[slot] 上.
const auto wait_stats = os_event_wait_for(log.write_events[slot], max_spins, srv_log_wait_for_write_timeout, stop_condition);
=1 log_wait_for_flush(log, end_lsn); 等待在log.flush_events[slot] 上.
const auto wait_stats = os_event_wait_for(log.flush_events[slot], max_spins, srv_log_wait_for_flush_timeout, stop_condition);
log_flusher
log_flusher 是等待在 log.flusher_event 上,
從上面可以看到一般來說, 由log_writer 執行os_event_set 喚醒
如果是 srv_flush_log_at_trx_commit == 1 的場景, 也就是我們最常見的寫了事務, 必須flush 到磁盤, 才能返回的場景. 然后判斷的是 last_flush_lsn < log.write_lsn.load(), 也就是上一次last_flush_lsn 比當前的write_lsn, 如果比他小, 說明有新數據寫入了, 那么就可以執行flush 操作了,
如果是 srv_flush_log_at_trx_commit != 1 的場景, 也就是寫了事務不需要保證redolog 刷盤的場景, 那么執行的是
os_event_wait_time_low(log.flusher_event, flush_every_us - time_elapsed_us, 0);
也就是會定期的根據時間來喚醒, 然后執行 flusher 操作.
最后 執行完成flush 以后喚醒的是log.flush_notifier_event os_event_set(log.flush_notifier_event);
log_flush_notifier
和log_write_notifier 基本一樣, 等待在 flush_notifier_event 上, 然后判斷的是 log.flushed_to_disk_lsn.load() >= lsn, 這里lsn 是上一次的flushed_to_disk_lsn, 也就是判斷flushed_to_disk_lsn 有沒有增加, 如果有增加就喚醒等待在 flush_events[slot] 上面的用戶線程, 跟上面一樣, 也是用戶線程最后會等待在flush_events 上
從上面可以看到, 有log_flusher 喚醒它
log_closer
log_closer 這個線程是在后臺不斷的去清理recent_closed 的線程, 在mtr/mtr0mtr.cc:execute() 也就是mtr commit 的時候, 會把這個mtr 修改的內容對應start_lsn, end_lsn 的內容添加到recent_closed buffer 里面, 并且在添加到recent_closed buffer 之前, 也會把相應的page 都掛到buffer pool 的flush list 里面.
和其他線程不一樣的地方在于, Log_closer 并沒有wait 在一個條件變量上, 只是每隔1s 的輪詢而已.
而在這1s 一次的輪詢里面, 一直執行的操作是 log_advance_dirty_pages_added_up_to_lsn() 這個函數類似recent_writtern 里面的 log_advance_ready_for_write_lsn(), 去這個recent_close 里面的Link_buf 里面
/* * 從recent_closed.m_tail 一直往下找, 只要有連續的就串到一起, 直到 * 找到有空洞的為止 * 只要找到數據, 就更新m_tail 到最新的位置, 然后返回true * 一條數據都沒有返回false * 注意: 在advance_tail_until 操作里面, 本身同時會進行的操作就是回收之前的空間 * 所以執行完advance_tail_until 以后, 連續的內存就會被釋放出來了 * 下面還有validate_no_links 函數進行檢查是否釋放正確 */
這樣一直清理著recent_closed buffer, 就可以保證recent_closed buffer 一直是有空間的
log_closer thread 會一直更新著這個 log_advance_dirty_pages_added_up_to_lsn(), 這個函數里面就是一直去更新recent_close buffer 里面的 log_buffer_dirty_pages_added_up_to_lsn(), 然后在做check pointer 的時候, 會一直去檢查這個log_buffer_dirty_pages_added_up_to_lsn(), 可以做check point 的lsn 必須小于這個log_buffer_dirty_pages_added_up_to_lsn(), 因為 log_buffer_dirty_pages_added_up_to_lsn 表示的是 recent close buffer 里面的其實位置, 在這個位置之前的Lsn 都已經被填滿, 是連續的了, 在這個位置之后的lsn 沒有這個保證.
那么是誰負責更新recent_closed 這個數組呢?log_closed thread
什么時候把dirty page 加入到buffer pool 的 flush list 上?
在mtr->commit() 的時候, 就會把這個mtr 修改過的page 都加到flush list 上, 在添加到flush list 上之前, 我們會保證寫入到redo log, 并且這個redo log 已經flush 了.
log_checkpointer
這個線程等待在 log.checkpointer_event 上, 然后判斷的是10*1000, 也就是10s 的時間,
os_event_wait_time_low(log.checkpointer_event, 10 * 1000, sig_count);
os_event_wait_time_low 是等待checkpointer_event 被喚醒, 或者超時時間10s 到了, 其實就是pthread_cond_timedwait()
正常情況下都是等10s 然后log_checkpointer 被喚醒, 那么被通知到checkpointer_event 被喚醒的場景在哪里呢?
其實也是在 log_writer_write_buffer() 函數里面, 先判斷
while(1) {const lsn_t lsn_diff = min_next_lsn - checkpoint_lsn;if (lsn_diff <= log.lsn_capacity) {? ?checkpoint_limited_lsn = checkpoint_lsn + log.lsn_capacity;? ?break;?}?log_request_checkpoint(log, false);? ?...?}?// 為什么需要在log_writer 的過程加入這個邏輯, 這個邏輯是判斷lsn_diff(當前這次要寫入的數據的大小) 是否超過了log.lsn_capacity(redolog 的剩余容量大小), 如果比它小, 那么就可以直接進行寫入操作, 就break 出去, 如果比它大, 那么說明如果這次寫入寫下去的話, 因為redolog 是rotate 形式的, 會把當前的redolog 給寫壞, 所以必須先進行一次checkpoint, 把一部分的redolog 中的內容flush 到btree data中, 然后把這個checkpoint 點增加, 騰出空間.?// 所以我們看到如果checkpoint 做的不夠及時, 會導致redolog 空間不夠, 然后直接影響到線上的寫入線程.?
首先我們必須知道一個問題是, 一次transaction 修改的page 什么時候flush 下去, 我們是不知道的. 因為用戶只需要寫入到redo log, 并且確認redo log 已經flush 了以后, 就直接返回了. 至于什么時候從Buffer pool flush 到btree data, 這個是后臺異步的, 用戶也不關注的. 但是我們打checkpoint 以后, 在checkpoint 之前的redo log 應該是都可以刪除的, 因此我們必須保證打的checkpoint lsn 的這個點之前的redo log 已經將對應的page flush到磁盤上了,
那么這里的問題就是如何確定這個checkpoint lsn 點?
在函數 log_update_available_for_checkpoint_lsn(log); 里面更新 log.available_for_checkpoint_lsn
具體的更新過程:
然后在log_request_checkpoint里面執行 log_update_available_for_checkpoint_lsn(log) =>
const lsn_t oldest_lsn = log_get_available_for_checkpoint_lsn(log);
然后執行 lsn_t lwn_lsn = buf_pool_get_oldest_modification_lwm() =>
buf_pool_get_oldest_modification_approx()
這里buf_pool_get_oldest_modification_approx() 指的是獲得大概的最老的lsn 的位置, 這里是引入了recent_closed buffer 帶來的一個問題, 因為引入了 recent_closed buffer 以后, 從redo log 上面的page 添加到buffer pool 的flush list 是不能保證有序的, 有可能一個flush list 上面存在的是 98 => 85 => 110 這樣的情況. 因此這個函數只能獲得大概的oldest_modification lsn
具體的做法就是遍歷所有的buffer pool 的flush list, 然后只需要取出flush list 里面的最后一個元素(雖然因為引入了recent_closed 不能保證是最老的 lsn), 也就是最老的lsn, 然后對比8個flush_list, 最老的lsn 就是目前大概的lsn 了
然后在buf_pool_get_oldest_modification_lwm() 還是里面, 會將buf_pool_get_oldest_modification_approx() 獲得的 lsn 減去recent_closed buffer 的大小, 這樣得到的lsn 可以確保是可以打checkpoint 的, 但是這個lsn 不能保證是最大的可以打checkpoint 的lsn. 而且這個 lsn 不一定是指向一個記錄的開始, 更多的時候是指向一個記錄的中間, 因為這里會強行減去一個 recent_closed buffer 的size. 而以前在5.6 版本是能夠保證這個lsn 是默認一個redo log 的record 的開始位置
最后通過 log_consider_checkpoint(log); 來確定這次是否要寫這個checkpointer 信息
然后在 log_should_checkpoint() 具體的有3個條件來判斷是否要做 checkpointer
最后決定要做的時候通過 log_checkpoint(log); 來寫入checkpointer 的信息
在log_checkpoint() 函數里面
通過 log_determine_checkpoint_lsn() 來判斷這次checkpointer 是要寫入dict_lsn, 還是要寫入available_for_checkpoint_lsn. 在 dict_lsn 指的是上一次DDL 相關的操作, 到dict_lsn 為止所有的metadata 相關的都已經寫入到磁盤了, 這里為什么要把DDL 相關的操作和非 DDL 相關的操作分開呢?
最后通過 log_files_write_checkpoint 把checkpoint 信息寫入到ib_logfile0 文件中
-
函數
+關注
關注
3文章
4308瀏覽量
62449 -
代碼
+關注
關注
30文章
4753瀏覽量
68369 -
MySQL
+關注
關注
1文章
802瀏覽量
26453
原文標題:[InnoDB 源碼介紹] lock-free redo log in mysql8.0
文章出處:【微信號:inf_storage,微信公眾號:數據庫和存儲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
騰訊云打造MySQL 8.0全新引擎,進一步加速客戶產業升級
MySQL 5.7與MySQL 8.0 性能對比
MySQL事務日志
MySQL中的redo log是什么
基于mysql自有方式采集獲取監控數據
一文徹底搞懂MySQL鎖究竟鎖的啥1
一文徹底搞懂MySQL鎖究竟鎖的啥2

關于MySQL8.0版本選型的小技巧
請問mysql8.0不能在grant時創建用戶是什么原因?
mysql8.0默認字符集是什么
GitHub底層數據庫無縫升級到MySQL 8.0的經驗





 工商網監
工商網監
評論