") 如何快速入門Python爬蟲的?
如何快速入門Python爬蟲的?
不少讀者是剛剛入門Python或者想學習Python的,今天就來談談如何用快速入門爬蟲。
先說結論:入門爬蟲很容易,幾行代碼就可以,可以說是學習Python最簡單的途徑。
以我純小白、零基礎的背景來說,入門爬蟲其實很容易,容易在代碼編寫很簡單,簡單的爬蟲通常幾行就能搞定,而不容易在確定爬蟲的目標,也就是說為什么要去寫爬蟲,有沒有必要用到爬蟲,是不是手動操作幾乎無法完成,互聯(lián)網(wǎng)上有數(shù)以百萬千萬計的網(wǎng)站,到底以哪一個網(wǎng)站作為入門首選,這些問題才是難點。所以在動手寫爬蟲前,最好花一些時間想一想這清楚這些問題。
「Talk is cheap. Show me the code」,下面我就以曾寫過的一個爬蟲為例,說一說我是如何快速入門Python爬蟲的。
▌確立目標
第一步,確立目標。
為什么想起寫這個爬蟲呢,是因為這是曾經(jīng)在工作中想要解決的問題,當時不會爬蟲,只能用Excel花了數(shù)個小時才勉強地把數(shù)據(jù)爬了下來, 所以在接觸到爬蟲后,第一個想法就是去實現(xiàn)曾未實現(xiàn)的目標。以這樣的方式入門爬蟲,好處顯而易見,就是有了很明確的動力。
很多人學爬蟲都是去爬網(wǎng)上教程中的那些網(wǎng)站,網(wǎng)站一樣就算了,爬取的方法也一模一樣,等于抄一遍,不是說這樣無益,但是會容易導致動力不足,因為你沒有帶著目標去爬,只是為了學爬蟲而爬,爬蟲雖然是門技術活,但是如果能建立在興趣愛好或者工作任務的前提下,學習的動力就會強很多。
在確定好爬蟲目標后,接著我就在腦中預想了想要得到什么樣的結果、如何展示出來、以什么形式展現(xiàn)這些問題。所以,我在爬取網(wǎng)站之前,就預先構想出了想要的一個結果,大致是下面這張圖的樣子。
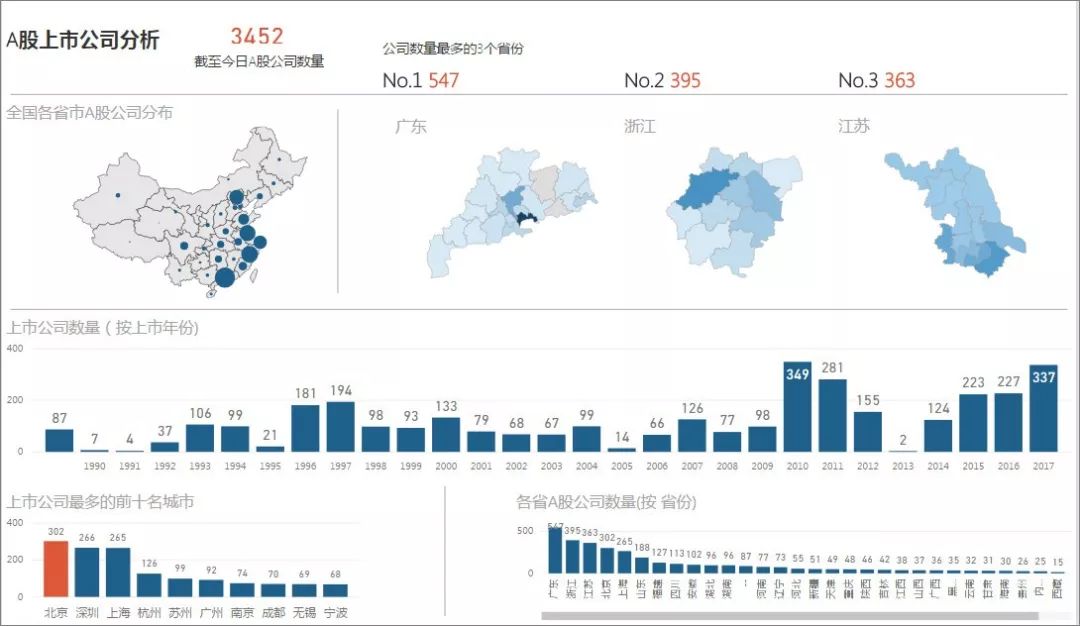
目標是利用爬下來的數(shù)據(jù),嘗試從不同維度年份、省份、城市去分析全國的股市信息,然后通過可視化圖表呈現(xiàn)出來。
拋開數(shù)據(jù),可能你會覺得這張圖在排版布局、色彩搭配、字體文字等方面還挺好看的。這些呢,就跟爬蟲沒什么關系了,而跟審美有關,提升審美的一種方式是可以通過做PPT來實現(xiàn),所以你看,咱們說著說著就從爬蟲跳到了 PPT,不得不說我此前發(fā)的文章鋪墊地很好啊,哈哈。其實,在職場中,你擁有的技能越多越好。
▌直接開始
確定了目標后,第二步就可以開始寫爬蟲了,如果你像我一樣,之前沒有任何編程基礎,那我下面說的思路,可能會有用。
剛開始動手寫爬蟲,我只關注最核心的部分,也就是先成功抓到數(shù)據(jù),其他的諸如:下載速度、存儲方式、代碼條理性等先不管,這樣的代碼簡短易懂、容易上手,能夠增強信心。
所以,我在寫第一遍的時候,只用了5行代碼,就成功抓取了全部所需的信息,當時的感覺就是很爽,覺得爬蟲不過如此啊,自信心爆棚。
1importpandasaspd2importcsv3foriinrange(1,178):#爬取全部頁4tb=pd.read_html('http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s'%(str(i)))[3]5tb.to_csv(r'1.csv',mode='a',encoding='utf_8_sig',hea
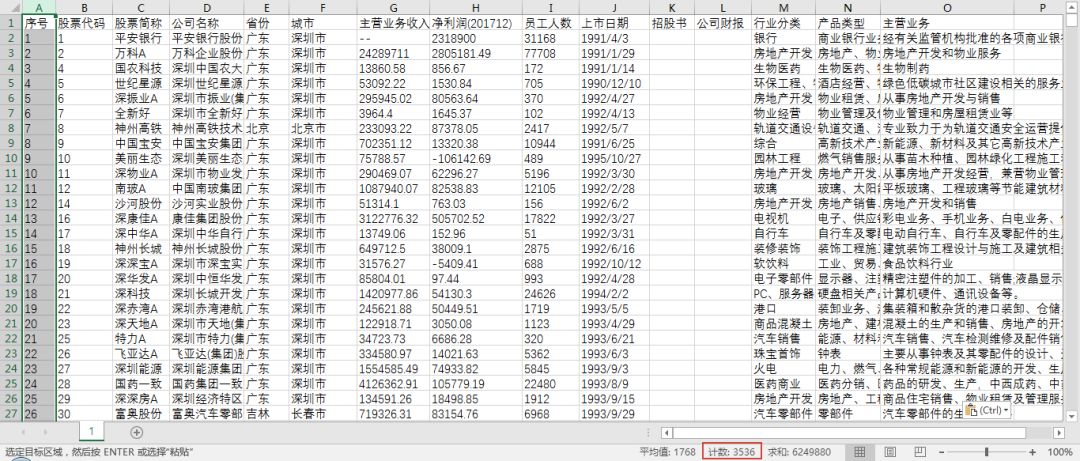
3000+ 上市公司的信息,安安靜靜地躺在 Excel 中:
▌不斷完善
有了上面的信心后,我開始繼續(xù)完善代碼,因為5行代碼太單薄,功能也太簡單,大致從以下幾個方面進行了完善:
增加異常處理
由于爬取上百頁的網(wǎng)頁,中途很可能由于各種問題導致爬取失敗,所以增加了 try except 、if 等語句,來處理可能出現(xiàn)的異常,讓代碼更健壯。
增加代碼靈活性
初版代碼由于固定了URL參數(shù),所以只能爬取固定的內容,但是人的想法是多變的,一會兒想爬這個一會兒可能又需要那個,所以可以通過修改 URL 請求參數(shù),來增加代碼靈活性,從而爬取更靈活的數(shù)據(jù)。
修改存儲方式
初版代碼我選擇了存儲到Excel這種最為熟悉簡單的方式,人是一種惰性動物,很難離開自己的舒適區(qū)。但是為了學習新知識,所以我選擇將數(shù)據(jù)存儲到 MySQL 中,以便練習 MySQL 的使用。
加快爬取速度
初版代碼使用了最簡單的單進程爬取方式,爬取速度比較慢,考慮到網(wǎng)頁數(shù)量比較大,所以修改為了多進程的爬取方式。
經(jīng)過以上這幾點的完善,代碼量從原先的5行增加到了下面的幾十行:
1importrequests2importpandasaspd3frombs4importBeautifulSoup4fromlxmlimportetree5importtime6importpymysql7fromsqlalchemyimportcreate_engine8fromurllib.parseimporturlencode#編碼URL字符串910start_time=time.time()#計算程序運行時間11defget_one_page(i):12try:13headers={14'User-Agent':'Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/66.0.3359.181Safari/537.36'15}16paras={17'reportTime':'2017-12-31',18#可以改報告日期,比如2018-6-30獲得的就是該季度的信息19'pageNum':i#頁碼20}21url='http://s.askci.com/stock/a/?'+urlencode(paras)22response=requests.get(url,headers=headers)23ifresponse.status_code==200:24returnresponse.text25returnNone26exceptRequestException:27print('爬取失敗')2829defparse_one_page(html):30soup=BeautifulSoup(html,'lxml')31content=soup.select('#myTable04')[0]#[0]將返回的list改為bs4類型32tbl=pd.read_html(content.prettify(),header=0)[0]33#prettify()優(yōu)化代碼,[0]從pd.read_html返回的list中提取出DataFrame34tbl.rename(columns={'序號':'serial_number','股票代碼':'stock_code','股票簡稱':'stock_abbre','公司名稱':'company_name','省份':'province','城市':'city','主營業(yè)務收入(201712)':'main_bussiness_income','凈利潤(201712)':'net_profit','員工人數(shù)':'employees','上市日期':'listing_date','招股書':'zhaogushu','公司財報':'financial_report','行業(yè)分類':'industry_classification','產品類型':'industry_type','主營業(yè)務':'main_business'},inplace=True)35returntbl3637defgenerate_mysql():38conn=pymysql.connect(39host='localhost',40user='root',41password='******',42port=3306,43charset='utf8',44db='wade')45cursor=conn.cursor()4647sql='CREATETABLEIFNOTEXISTSlisted_company(serial_numberINT(20)NOTNULL,stock_codeINT(20),stock_abbreVARCHAR(20),company_nameVARCHAR(20),provinceVARCHAR(20),cityVARCHAR(20),main_bussiness_incomeVARCHAR(20),net_profitVARCHAR(20),employeesINT(20),listing_dateDATETIME(0),zhaogushuVARCHAR(20),financial_reportVARCHAR(20),industry_classificationVARCHAR(20),industry_typeVARCHAR(100),main_businessVARCHAR(200),PRIMARYKEY(serial_number))'48cursor.execute(sql)49conn.close()5051defwrite_to_sql(tbl,db='wade'):52engine=create_engine('mysql+pymysql://root:******@localhost:3306/{0}?charset=utf8'.format(db))53try:54tbl.to_sql('listed_company2',con=engine,if_exists='append',index=False)55#append表示在原有表基礎上增加,但該表要有表頭56exceptExceptionase:57print(e)5859defmain(page):60generate_mysql()61foriinrange(1,page):62html=get_one_page(i)63tbl=parse_one_page(html)64write_to_sql(tbl)6566##單進程67if__name__=='__main__':68main(178)69endtime=time.time()-start_time70print('程序運行了%.2f秒'%endtime)7172#多進程73frommultiprocessingimportPool74if__name__=='__main__':75pool=Pool(4)76pool.map(main,[iforiinrange(1,178)])#共有178頁77endtime=time.time()-start_time78print('程序運行了%.2f秒'%(time.time()-start_time))
雖然代碼行數(shù)增加了不少,但是這個過程卻覺得很自然,因為每次修改都是針對一個小點,一點點去學,搞懂后添加進來,而如果讓我上來就直接寫出這幾十行的代碼,我很可能就放棄了。
所以,你可以看到,入門爬蟲是有套路的,最重要的是給自己信心。
-
代碼
+關注
關注
30文章
4748瀏覽量
68356 -
python
+關注
關注
56文章
4782瀏覽量
84453 -
爬蟲
+關注
關注
0文章
82瀏覽量
6840
原文標題:5行代碼就能入門爬蟲?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論