") 探析自動(dòng)駕駛規(guī)劃控制發(fā)展現(xiàn)狀及熱點(diǎn)研究
探析自動(dòng)駕駛規(guī)劃控制發(fā)展現(xiàn)狀及熱點(diǎn)研究
對(duì)自動(dòng)駕駛而言,傳感器、感知、地圖定位和規(guī)劃控制是目前研究的熱點(diǎn),本文奇點(diǎn)汽車美研中心首席科學(xué)家兼總裁黃浴博士從多個(gè)方面綜述了目前自動(dòng)駕駛的技術(shù)水平以及不同板塊的重要性。
傳感器技術(shù)
傳感器而言,大家比較關(guān)心新技術(shù)。
在攝像頭技術(shù)方面,HDR,夜視鏡頭,熱敏攝像頭等是比較熱的研究。前段時(shí)間有研究(MIT MediaLab教授)采用新技術(shù)穿透霧氣的鏡頭,叫做single photon avalanche diode (SPAD) camera;另外,能不能采用計(jì)算攝像技術(shù)(computational photography)改進(jìn)一下如何避免雨雪干擾,采用超分辨率(SR)圖像技術(shù)也可以看的更遠(yuǎn)。前不久,圖森的攝像頭可以看1000米遠(yuǎn)嗎,要么采用高清攝像頭4K甚至8K,要么采用SR技術(shù)實(shí)現(xiàn)。
這是介紹SPAD的兩個(gè)截圖:
另外,單目系統(tǒng)比較流行,現(xiàn)在也有雙目系統(tǒng)存在,比如安霸從意大利帕爾馬大學(xué)買到的VisLab自動(dòng)駕駛技術(shù),還有Bertha Benz著名的Stixel障礙物檢測(cè)算法。因?yàn)榛€原因,車上可以配備多個(gè)雙目系統(tǒng),以方便測(cè)量不同距離的障礙物。懂計(jì)算機(jī)視覺(jué)的同學(xué)知道,立體匹配和基線寬度在涉及視覺(jué)系統(tǒng)的時(shí)候有一個(gè)權(quán)衡。深度學(xué)習(xí)已經(jīng)用來(lái)估計(jì)深度/視差圖,就如分割一樣,pixel-to-pixel。甚至單目也可以推理深度,結(jié)果當(dāng)然比雙目差。
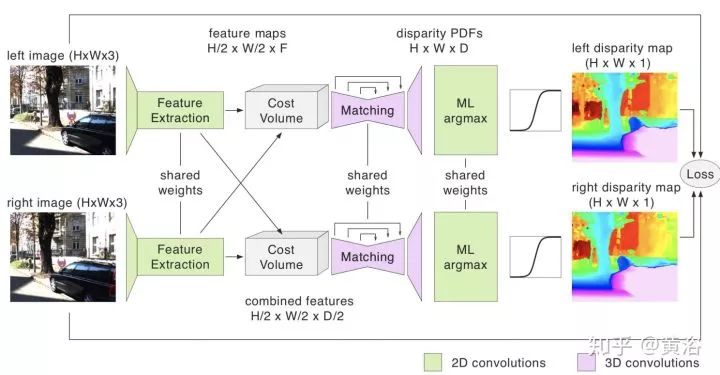
激光雷達(dá)最熱,一是降低成本和車規(guī)門檻的固態(tài)激光雷達(dá),二是如何提高測(cè)量距離,三是提高分辨率和刷新頻率,還有避免互相干擾和入侵的激光編碼技術(shù)等。其實(shí)激光雷達(dá)的反射灰度圖也是一個(gè)指標(biāo),3-D點(diǎn)云加上反射圖會(huì)更好,比如用于車道線檢測(cè)。
另外,攝像頭和激光雷達(dá)在硬件層的融合也是熱點(diǎn),畢竟一個(gè)點(diǎn)云的點(diǎn)是距離信息,加上攝像頭的RGB信息,就是完美了不是?一些做仿真模擬以及VR產(chǎn)品的公司就是這么做的,去除不需要的物體和背景就能生成一個(gè)虛擬的仿真環(huán)境。
這里是一家美國(guó)激光雷達(dá)創(chuàng)業(yè)公司AEye的技術(shù)iDAR截圖,iDAR 是IntelligentDetection and Ranging,最近該公司宣稱已經(jīng)能夠?qū)崿F(xiàn)測(cè)距1000米(一兩年前谷歌就說(shuō),它的激光雷達(dá)能看到3個(gè)足球場(chǎng)那么遠(yuǎn)):
毫米波雷達(dá)方面,現(xiàn)在也在想辦法提高角分辨率。畢竟它是唯一的全天候傳感器了,如果能夠解決分辨率這一痛處,那么以后就不會(huì)僅僅在屏幕上展示一群目標(biāo)點(diǎn),而是有輪廓的目標(biāo),加上垂直方向的掃描,完全可以成為激光雷達(dá)的競(jìng)爭(zhēng)對(duì)手。希望新的天線和信號(hào)處理技術(shù)可以解決雷達(dá)成像的難點(diǎn),包括功耗。
這里是NXP提供的新型高分辨率雷達(dá)和激光雷達(dá)比較的截圖:
超聲波雷達(dá),基本是用在泊車場(chǎng)景,便宜。
感知模塊
下面談感知模塊。
感知是基于傳感器數(shù)據(jù)的,以前反復(fù)提過(guò)了,傳感器融合是標(biāo)配,信息越多越好嗎,關(guān)鍵在于怎么融合最優(yōu)。比如某個(gè)傳感器失效怎么辦?某個(gè)傳感器數(shù)據(jù)質(zhì)量變差(某個(gè)時(shí)候,比如隧道,比如天氣,比如夜晚,比如高溫低溫等等造成的)怎么辦?如果你要用數(shù)據(jù)訓(xùn)練一個(gè)感知融合模型,那么訓(xùn)練數(shù)據(jù)是否能夠包括這些情況呢?
這里當(dāng)然談到深度學(xué)習(xí)了,而且深度學(xué)習(xí)也不僅僅用在圖像數(shù)據(jù),激光雷達(dá)點(diǎn)云數(shù)據(jù)也用,效果也非常好,明顯勝過(guò)傳統(tǒng)方法。不過(guò),深度學(xué)習(xí)有弱點(diǎn),畢竟還是靠大量數(shù)據(jù)“喂”出來(lái)的模型,有時(shí)候很敏感,比如像素上改變一點(diǎn)兒對(duì)人眼沒(méi)什么而機(jī)器識(shí)別就造成錯(cuò)誤,還有當(dāng)識(shí)別類別增多性能會(huì)下降,同時(shí)出現(xiàn)一些奇怪的誤判,比如谷歌曾經(jīng)把黑人識(shí)別成猩猩。機(jī)器學(xué)習(xí)一個(gè)問(wèn)題是泛化問(wèn)題(generalization),如何避免overfitting是一個(gè)模型訓(xùn)練的普遍問(wèn)題,當(dāng)然大家都提出了不少解決方法,比如data augmentation,drop out等。
深度學(xué)習(xí)發(fā)展還是很快的,好的模型不斷涌現(xiàn),如ResNet, DenseNet;好的訓(xùn)練方法也是,比如BN成了標(biāo)配,采用NAS基礎(chǔ)上的AutoML基本上可以不用調(diào)參了(GPU設(shè)備很貴呀);具體應(yīng)用上也是進(jìn)步很大,比如faster RCNN,YOLO3等等。
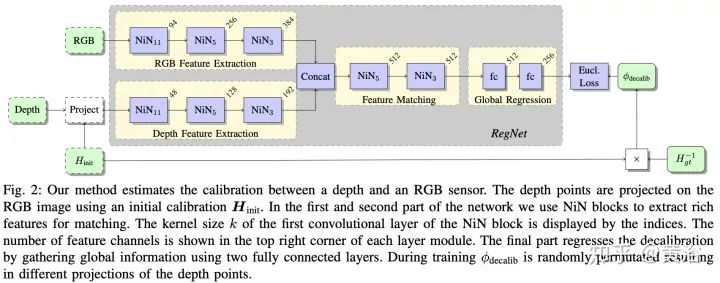
在激光雷達(dá)數(shù)據(jù)上,最近深度學(xué)習(xí)應(yīng)用發(fā)展很快,畢竟新嗎,而且這種傳感器會(huì)逐漸普及,成本也會(huì)降下來(lái),畢竟是3-D的,比2-D圖像還是好。這里要提到sync和calibration問(wèn)題,要做好激光雷達(dá)和攝像頭數(shù)據(jù)的同步也不容易,二者的坐標(biāo)系校準(zhǔn)也是,去年有個(gè)CNN模型叫RegNet,就是深度學(xué)習(xí)做二者calibration的。
談到融合,這里包括幾個(gè)意思,一是數(shù)據(jù)層的直接融合,前面提到硬件層可以直接完成,軟件也可以,而且還可以解決硬件做不了的問(wèn)題:激光雷達(dá)畢竟稀疏,越遠(yuǎn)越稀疏,有時(shí)候還會(huì)有“黑洞”,就是不反射的物質(zhì),比如車窗玻璃;而圖像可以致密,分辨率也可以很高,畢竟造價(jià)便宜,二者在深度圖(depth map)空間結(jié)合是一個(gè)互補(bǔ),深度學(xué)習(xí)可以幫上忙,有興趣的可以看看MIT的論文。
除了數(shù)據(jù)層,還有中間模型層融合,以及最后任務(wù)層(一般指多個(gè)模型結(jié)果輸出)的融合,目前深度學(xué)習(xí)用在激光雷達(dá)數(shù)據(jù)以及結(jié)合圖像數(shù)據(jù)融合的目標(biāo)檢測(cè)識(shí)別分割跟蹤等方面有不少論文,基本可以在這三個(gè)層次劃分。
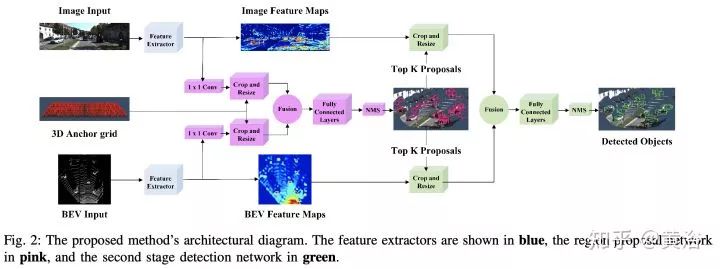
很有趣的現(xiàn)象是,激光雷達(dá)點(diǎn)云投射到平面上變成圖像數(shù)據(jù)是一個(gè)很討巧的方法,而且鳥瞰平面比前視平面(攝像機(jī)方向)效果好,當(dāng)然也有直接在3-D數(shù)據(jù)上做的,比如VoxelNet,PointNet。很多工作都是將圖像領(lǐng)域成功的模型用在激光雷達(dá)數(shù)據(jù)上,做些調(diào)整和推廣,比如faster RCNN,其中RPN和RCNN部分可以通過(guò)不同傳感器數(shù)據(jù)訓(xùn)練。
這里是一個(gè)激光雷達(dá)+攝像頭融合做目標(biāo)檢測(cè)的論文截圖:
談到深度學(xué)習(xí)在圖像/視頻/深度圖/3-D點(diǎn)云上的應(yīng)用,不局限在檢測(cè)識(shí)別分割上,這個(gè)以后再談吧,又要寫一篇才行。
感知的任務(wù)是理解自動(dòng)駕駛車的周圍環(huán)境,除了定位跟地圖有關(guān),像障礙物檢測(cè),運(yùn)動(dòng)目標(biāo)跟蹤,紅綠燈識(shí)別,道路標(biāo)志識(shí)別,車道線檢測(cè)(根據(jù)需要而定,比如有些地圖直接用路標(biāo)或者特征匹配實(shí)現(xiàn)定位,車道線就是由地圖給出)都是感知的任務(wù)。更高級(jí)的任務(wù)會(huì)涉及對(duì)周圍其他物體的行為預(yù)測(cè),比如行人,尤其是路口行人過(guò)馬路的預(yù)測(cè),比如行駛車輛,到底是打算cut-in還是僅僅偏離了車道,在高速入口的車輛,到底是想加速先過(guò)還是減速等你,這些都是“老司機(jī)”很擅長(zhǎng)的,而提供線索的恰恰是感知模塊。
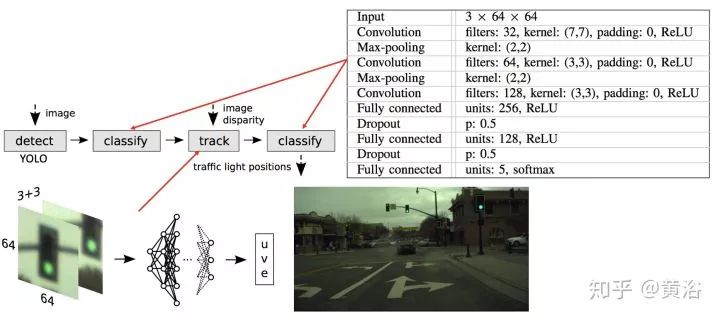
這里是一個(gè)做紅綠燈檢測(cè)識(shí)別的NN模型例子:
而一個(gè)檢測(cè)路牌的NN模型:
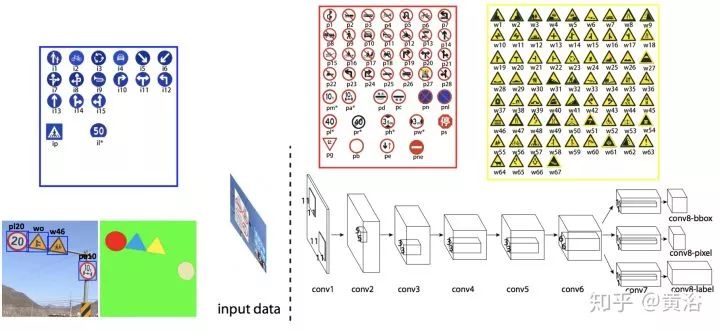
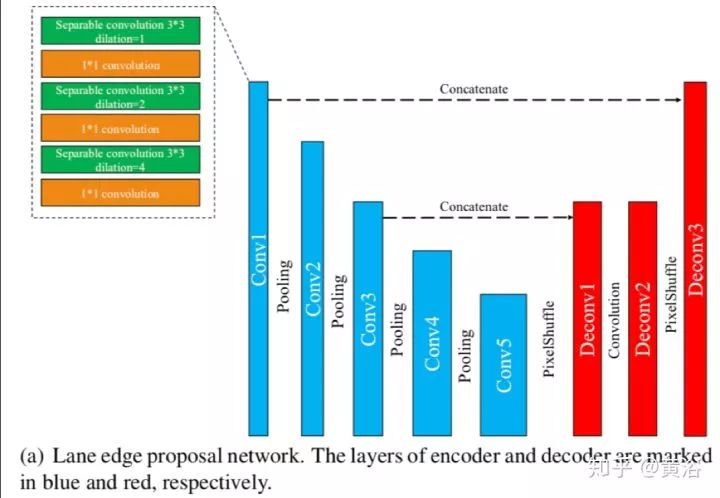
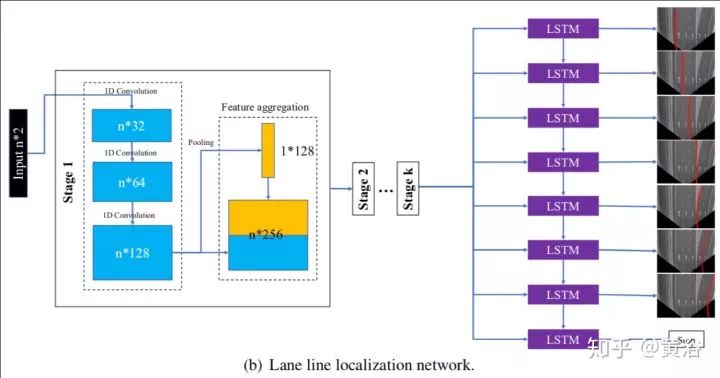
這是一個(gè)車道線檢測(cè)的NN模型LaneNet示意圖:車道線proposal network和車道線localization network。
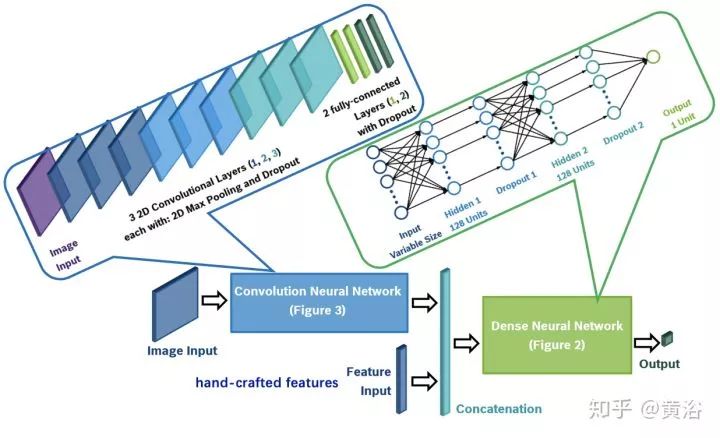
這個(gè)NN模型就是對(duì)行人預(yù)測(cè)的:
應(yīng)用場(chǎng)景可以看下面的示意圖:激光雷達(dá)點(diǎn)云作為輸入
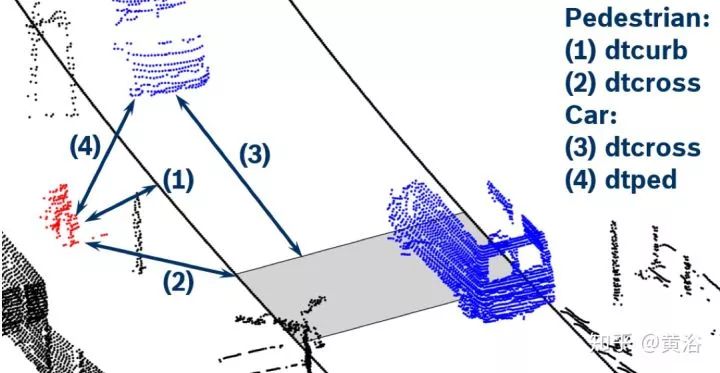
順便說(shuō)一下,我對(duì)一些大講“感知已經(jīng)OK,現(xiàn)在最重要的是規(guī)劃決策”的言論難以茍同,畢竟感知在這些行為細(xì)節(jié)上缺乏充分的數(shù)據(jù)提供給預(yù)測(cè)和規(guī)劃部分,所以也很難有更細(xì)膩的規(guī)劃決策模型來(lái)用。當(dāng)然采用大數(shù)據(jù)訓(xùn)練的規(guī)劃決策模型可以包括這些,但僅僅憑軌跡/速度/加速度這些輸入信息夠嗎?大家也可以注意到一些startup公司已經(jīng)在展示人體運(yùn)動(dòng)跟蹤,頭部姿態(tài),路上人工駕駛車輛的駕駛員視線方向 (gaze detection) 和面部表情/手勢(shì)識(shí)別的結(jié)果,說(shuō)明大家已經(jīng)意識(shí)到這些信息的重要性。
這里展示最近一些基于深度學(xué)習(xí)的人體姿態(tài)研究論文截圖:
另外,感知模型基本上是概率決策,是軟的推理(soft inference),最后是最小化誤差的硬決定(hard decision),所以誤差是難免的。現(xiàn)在一些安全標(biāo)準(zhǔn),比如ASIL,ISO26262, NHTSA,要求做到功能安全,還有最近的SOTIF,要求考慮unknown safe/unsafe,這些對(duì)感知在自動(dòng)駕駛的作用是提出了更嚴(yán)格的標(biāo)準(zhǔn)。說(shuō)白了就是,以前給出判斷就行,現(xiàn)在必須給出判斷的可靠性以及不自信的警告(confidence score)。有時(shí)候融合就要考慮這個(gè)問(wèn)題,最好給出多個(gè)模型輸出,當(dāng)一個(gè)模型可靠性不高的時(shí)候,就要采用其他可靠性高的模型輸出,當(dāng)所有模型都不可靠,自然就是準(zhǔn)備進(jìn)入安全模式了。對(duì)突發(fā)性事故的適應(yīng)性有多強(qiáng),就考驗(yàn)安全模型了。
以前提到過(guò)L2-L3-L4演進(jìn)式開發(fā)自動(dòng)駕駛模式和L4這種終極自動(dòng)駕駛開發(fā)模式的不同,提醒大家可以注意一個(gè)地方:特斯拉的演進(jìn)模式在用戶自己人工駕駛的時(shí)候仍然運(yùn)行自動(dòng)駕駛程序,稱之為“影子”模式,當(dāng)用戶的駕駛動(dòng)作和自動(dòng)駕駛系統(tǒng)的判斷出現(xiàn)矛盾的時(shí)候,相關(guān)上傳的數(shù)據(jù)會(huì)引起重視,以幫助提升自動(dòng)駕駛系統(tǒng)性能,比如一個(gè)立交橋出現(xiàn),自動(dòng)駕駛系統(tǒng)誤認(rèn)為是障礙物,而駕駛員毫無(wú)猶豫的沖過(guò)去,顯然這種傳感器數(shù)據(jù)會(huì)重新被標(biāo)注用來(lái)訓(xùn)練更新模型,甚至引導(dǎo)工程師采集更多相關(guān)數(shù)據(jù)進(jìn)行訓(xùn)練;另外,當(dāng)駕駛員突然剎車或者避讓,而自動(dòng)駕駛系統(tǒng)認(rèn)為道路無(wú)障的情況,收集數(shù)據(jù)的服務(wù)器一端也會(huì)將這種數(shù)據(jù)重新標(biāo)注。
這種影子模式就是演進(jìn)式開發(fā)模式系統(tǒng)升級(jí)的法寶,同時(shí)大量駕駛數(shù)據(jù)的收集也可以幫助規(guī)劃決策的提升,這個(gè)下面再講。相比之下,谷歌模式在安全員操控車輛時(shí)候,自然也在收集數(shù)據(jù),當(dāng)運(yùn)行自動(dòng)駕駛出現(xiàn)報(bào)警或者安全員覺(jué)得危險(xiǎn)需要接管的時(shí)候,這種數(shù)據(jù)也會(huì)像影子模式一樣需要注意。兩種開發(fā)模式都會(huì)及時(shí)獲取特別數(shù)據(jù)方法,唯一不同的是前者是付錢的(買車),而后者是要錢的(工資)。
地圖與定位
再談地圖和定位。
我們知道自動(dòng)駕駛在L2是不需要地圖的,特別高清地圖(HD Map),帶有車道線信息,L2級(jí)別用不上,現(xiàn)在有一種“降維打擊”模式,采用L4技術(shù)去開發(fā)L3甚至L2,主要是地圖定位可以提供很多輔助信息,簡(jiǎn)化一些感知負(fù)擔(dān),比如車道線,路牌和紅綠燈位置。
一般我們看到的地圖,俗稱導(dǎo)航地圖,基于GPS進(jìn)行車定位和道路規(guī)劃。現(xiàn)在又出現(xiàn)了一種ADAS地圖(四維圖新就提供這種服務(wù)),其實(shí)就是在導(dǎo)航地圖上附加一些信息,比如道路曲率和坡度,可以有助于車輛控制的時(shí)候調(diào)整參數(shù),如ACC,LKS。
我們一般談到定位,可以是GPS/IMU,也可以是高清地圖。前者有誤差,要么采用差分GPS,如RTK(國(guó)內(nèi)的千尋網(wǎng)絡(luò)就是提供這樣的服務(wù)),要么和其他方式融合,比如激光雷達(dá)的點(diǎn)云匹配,攝像頭的特征匹配,也包括基于車道線和路牌的識(shí)別定位。
談到高清地圖,以前提到過(guò)兩種模式,一是谷歌的高成本方式,采用高價(jià)的數(shù)據(jù)采集車,獲取環(huán)境的激光雷達(dá)點(diǎn)云以及反射灰度圖,濾除不需要的物體(行人/車輛/臨時(shí)障礙物),提取車道線/紅綠燈/路牌(停止/讓路符號(hào),街道距離信息)/車道標(biāo)志(箭頭/限速/斑馬線)等等,另外也標(biāo)注了道路的其他信息如曲率,坡度,高程,側(cè)傾等等。
這是一個(gè)谷歌HD Map的截圖:
由于激光雷達(dá)點(diǎn)云數(shù)據(jù)大,大家就考慮壓縮的方法,比如TomTom的RoadDNA,國(guó)內(nèi)高德地圖的道路指紋匹配,美國(guó)startup地圖公司CivilMaps也有類似地圖指紋技術(shù),不過(guò)前者是在視覺(jué)層,而后者是在點(diǎn)云層。有些公司是不提供點(diǎn)云層,因?yàn)閿?shù)據(jù)太大,相反視覺(jué)層和語(yǔ)義層可以給,基本矢量圖就能描述,數(shù)據(jù)量小多了,但匹配難度大。地圖的繪制,存儲(chǔ)和訪問(wèn)是相當(dāng)復(fù)雜的工程,所以投入很大,尤其是底圖(base map)的繪制。
這是TomTom的RoadDNA定位的介紹截圖:
高清地圖的第二種方式就是Mobileye和Tesla采用的,一般低成本,期望通過(guò)眾包實(shí)現(xiàn)。不用激光雷達(dá),采用攝像頭獲取道路標(biāo)識(shí),Mobileye稱之是REM(Road Experience Management),也是“路書”(Roadbook)。REM提取的信息有道路邊緣線、車道中心線、車道邊緣線以及靜態(tài)物體的標(biāo)示。
截圖來(lái)自Mobileye的REM介紹:
Bosch基于此,還提出一種基于毫米波雷達(dá)的方法提取道路其他信息,比如隔離欄、電線桿和橋梁等等,稱為Bosch Road Signature(BRS)。追隨這種眾包方法的公司也不少,如特斯拉出來(lái)的人成立的公司Lvl5,國(guó)內(nèi)有幾家,如寬凳科技,MOMENTA,深動(dòng)科技,最近地平線也給出一個(gè)NavNet平臺(tái),支持這種眾包的低成本制圖方式。
這是Lvl5作圖的一個(gè)示意圖:像VO的例子吧。
其實(shí)“實(shí)時(shí)更新”是高清地圖提供服務(wù)的關(guān)鍵,而對(duì)這個(gè)服務(wù)的成本考慮當(dāng)然是第二種方式容易推廣。眾包的缺點(diǎn)是容易數(shù)據(jù)碎片化,同時(shí)攝像頭的制圖難度也遠(yuǎn)大于激光雷達(dá)方法,視覺(jué)SLAM是比較有挑戰(zhàn)性的,當(dāng)然如果限制一下做車道線和路牌為主的目標(biāo)取地圖特征,難度可以降低。
美國(guó)地圖公司HERE采用的更新方法也是通過(guò)眾包,只是它先建了底圖。所以,一些提出眾包建圖的公司都想先擁有底圖。Mobileye就和HERE合作,最近它在日本已經(jīng)完成了REM的高速公路建圖。
這張圖是在今年CES介紹REM的一頁(yè)P(yáng)PT:
定位是基于地圖的,融合方式是包括GPS/IMU/HD Map,比如隧道就沒(méi)有GPS信號(hào),甚至高樓大廈密集的地方也不會(huì)有穩(wěn)定的GPS信號(hào),如果網(wǎng)絡(luò)不好造成地圖下載不利,基本就是靠IMU和L2的車道線/路牌識(shí)別了(激光雷達(dá)的反射灰度圖可以做車道線識(shí)別,但是傳感器性能有時(shí)候限制它的工作距離,不如攝像頭靈活),這時(shí)候“降維打擊”的方法都失效了,回歸原始,就靠現(xiàn)場(chǎng)感知了,真正的“老司機(jī)”做派:)。
值得一提的是,MIT教授就有在研究如何不用地圖做自動(dòng)駕駛。
規(guī)劃控制
下面該是規(guī)劃控制(包含預(yù)測(cè)和決策)。
規(guī)劃分三個(gè)層面,路徑規(guī)劃(任務(wù)規(guī)劃),行為規(guī)劃和運(yùn)動(dòng)規(guī)劃。最后一個(gè)運(yùn)動(dòng)規(guī)劃,和后面的控制模塊捆在一起,基本上L2-L4都通用了,除非軟硬件聯(lián)合開發(fā),L2和L4用的運(yùn)動(dòng)規(guī)劃(經(jīng)典的有RRT,Lattice planner)及控制(PID,MPC之類)沒(méi)啥變化。路徑規(guī)劃,就是基于道路網(wǎng)絡(luò)確定地圖上A點(diǎn)到B點(diǎn)的路徑,這個(gè)以前導(dǎo)航地圖也是要做這個(gè)任務(wù)。那么,剩下一個(gè)最新的問(wèn)題就是行為規(guī)劃了。
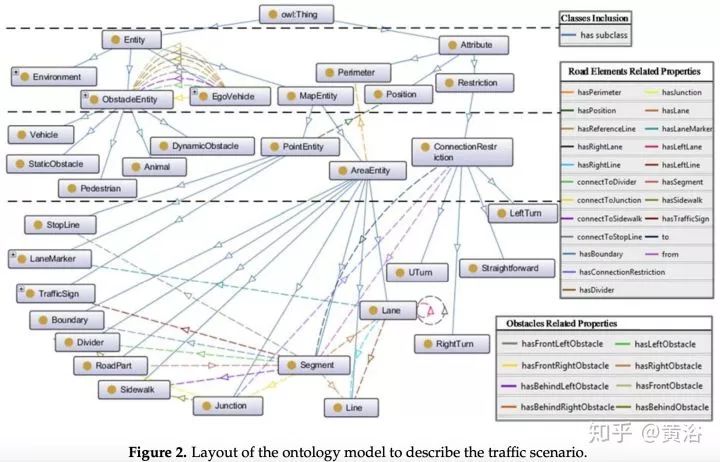
行為規(guī)劃需要定義一個(gè)行為類型集,類似多媒體領(lǐng)域采用的ontology,領(lǐng)域知識(shí)的描述。而行為規(guī)劃的過(guò)程,變成了一個(gè)有限狀態(tài)機(jī)的決策過(guò)程,需要各種約束求解最優(yōu)解。這里對(duì)周圍運(yùn)動(dòng)障礙物(車輛/行人)的行為也有一個(gè)動(dòng)機(jī)理解和軌跡預(yù)測(cè)的任務(wù)。上面談到的,感知模塊對(duì)周圍車輛行人的行為理解,就會(huì)在這里扮演一個(gè)重要的角色。
深度學(xué)習(xí)在這里有價(jià)值了。行為模型的學(xué)習(xí)過(guò)程需要大量的駕駛數(shù)據(jù),包括感知和定位的輸出,路徑規(guī)劃和車輛的運(yùn)動(dòng)狀態(tài)作為輸入,最終的車輛行駛的控制信號(hào)(方向盤,油門,剎車)作為輸出,那么這就是一個(gè)E2E的行為規(guī)劃+運(yùn)動(dòng)規(guī)劃+控制的模型;如果把車輛軌跡作為輸出,那么這個(gè)E2E就不包括控制。
如果把傳感器/GPS/IMU/HD Map和路徑規(guī)劃作為輸入,那么這個(gè)E2E就是前端加上感知的模型,這就變成特斯拉想做的software 2.0,不過(guò)感知太復(fù)雜了,不好辦。還是覺(jué)得把感知和定位的輸出作為輸入吧,這樣放心:)。
這里不得不提到自動(dòng)駕駛的仿真模擬系統(tǒng),按我看,這種規(guī)劃控制的行為模型學(xué)習(xí),最適合在模擬仿真環(huán)境做測(cè)試。Waymo在Carcraft仿真系統(tǒng)中測(cè)試左拐彎行為時(shí)候,會(huì)加上各種變化來(lái)測(cè)試性能,稱子為“fuzzing"。
這里給大家推薦兩篇重要論文做參考:
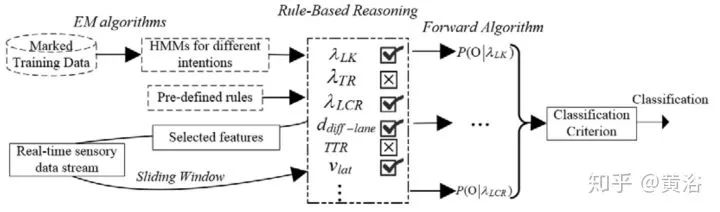
1 “A Scenario-Adaptive Driving Behavior Prediction Approach to Urban Autonomous Driving”
2 “ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst”
第一篇是中科大的論文,個(gè)人認(rèn)為非常適合大家了解百度剛剛發(fā)布的Apollo 3.5的行為規(guī)劃模型。這篇文章我一年前就讀了,不是深度學(xué)習(xí)的方法。這里貼幾個(gè)截圖:
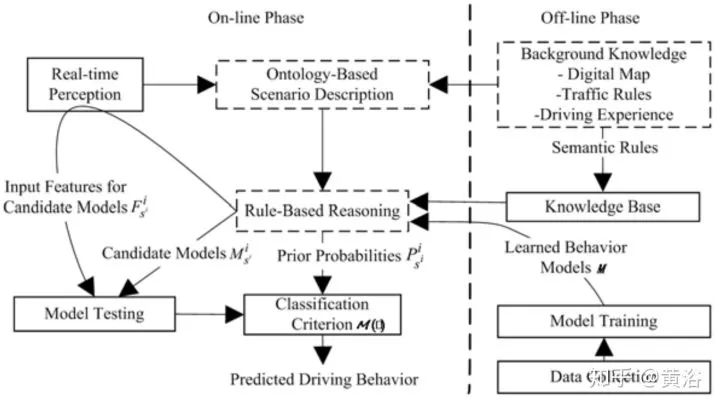
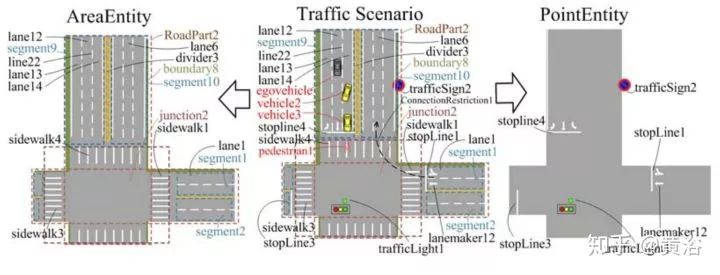
第二篇論文是Waymo最近發(fā)的research工作,是深度學(xué)習(xí)方法,完全依賴其強(qiáng)大的感知模塊輸入,還有1000萬(wàn)英里的駕駛數(shù)據(jù),強(qiáng)烈推薦。附上幾個(gè)截圖:
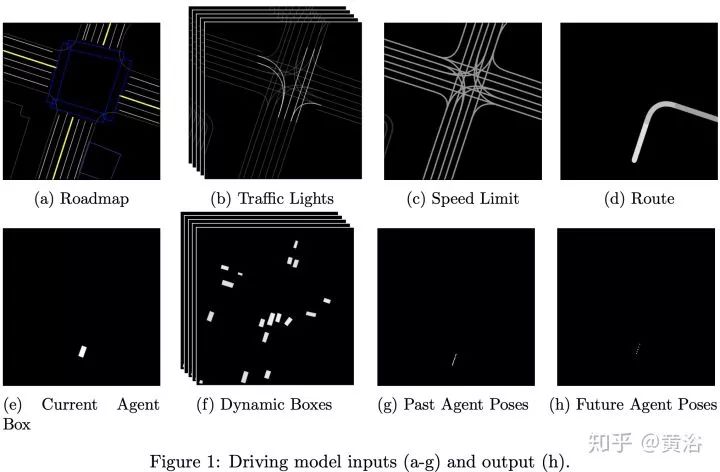
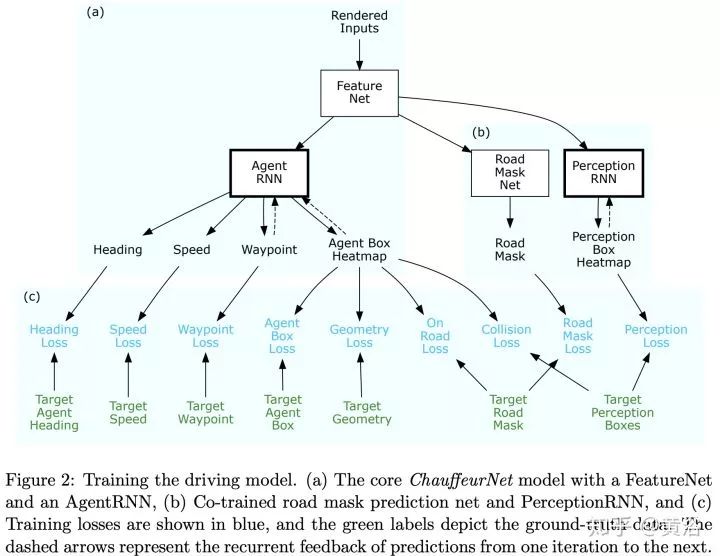
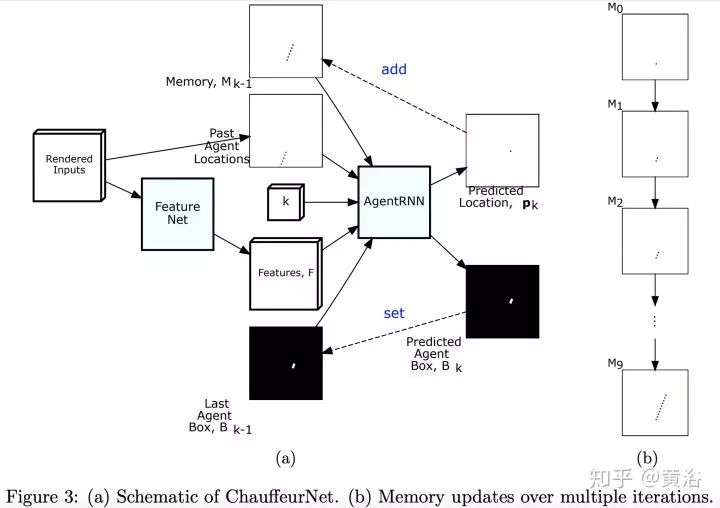

仿真模擬平臺(tái)
順便介紹一下,仿真模擬平臺(tái)的發(fā)展。
DARPA當(dāng)年比賽的時(shí)候前幾名都做了模擬系統(tǒng),谷歌收購(gòu)斯坦福團(tuán)隊(duì)以后就先把模擬仿真平臺(tái)升級(jí)了。畢竟它是一個(gè)軟件系統(tǒng),谷歌天生就強(qiáng)。這里不包括那些車體動(dòng)力和電子性能的模擬仿真工作,這個(gè)已經(jīng)存在好多年,是車企的強(qiáng)項(xiàng),比如它們常用的CarMaker,PreScan,CarSim等商用軟件系統(tǒng)。
這是谷歌CarCraft和Xview的樣子:
其中提到的"fuzzing"圖就是這樣的:
仿真模擬平臺(tái)已經(jīng)是自動(dòng)駕駛開發(fā)的標(biāo)配,看看Daimler汽車公司這部分工作的介紹:
還有自動(dòng)駕駛高校研究的例子:北卡的AutonoVi-Sim
-
傳感器
+關(guān)注
關(guān)注
2548文章
50678瀏覽量
752005 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
783文章
13684瀏覽量
166147
原文標(biāo)題:自動(dòng)駕駛傳感器,感知,地圖定位和規(guī)劃控制發(fā)展現(xiàn)狀及熱點(diǎn)研究
文章出處:【微信號(hào):IV_Technology,微信公眾號(hào):智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
線控底盤,自動(dòng)駕駛時(shí)代的基石?
淺談自動(dòng)駕駛技術(shù)的現(xiàn)狀及發(fā)展趨勢(shì)
工控機(jī)廠家發(fā)展現(xiàn)狀及未來(lái)趨勢(shì)

FPGA在自動(dòng)駕駛領(lǐng)域有哪些優(yōu)勢(shì)?
FPGA在自動(dòng)駕駛領(lǐng)域有哪些應(yīng)用?
嵌入式熱門領(lǐng)域有哪些?
深度學(xué)習(xí)在自動(dòng)駕駛中的關(guān)鍵技術(shù)
2.晶體和振蕩器 行業(yè)研究及十五五規(guī)劃分析報(bào)告(行業(yè)發(fā)展現(xiàn)狀及“十五五”前景預(yù)測(cè))
自動(dòng)駕駛發(fā)展問(wèn)題及解決方案淺析
乘用車一體化電池的發(fā)展現(xiàn)狀和未來(lái)趨勢(shì)

語(yǔ)音數(shù)據(jù)集在自動(dòng)駕駛中的應(yīng)用與挑戰(zhàn)
全球自動(dòng)駕駛市場(chǎng)分析報(bào)告
LabVIEW開發(fā)自動(dòng)駕駛的雙目測(cè)距系統(tǒng)
年度聚焦|路凱智行:礦山自動(dòng)駕駛投資價(jià)值標(biāo)桿企業(yè)
自動(dòng)駕駛“十問(wèn)十答”





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論