 對駕駛行為的學習以及對其他車輛駕駛的預測
對駕駛行為的學習以及對其他車輛駕駛的預測
自動駕駛里面很重要的就是估計和預測交通情況。預測的來源就是路上各種物體的姿態和速度歷史,高級的預測會包括可能的行動軌跡。
對于車輛本身來說,其駕駛動作分析離不開動力學理論(kinematic,dynamic),周圍的障礙物,同時還有道路行駛的路況(坡度,曲率)和規則(紅綠燈,限速牌,車道線,交叉路口等等)。所有這些因素組合一起就能體現交通參與者的行為模式,而學習這些行為模型就是自動駕駛掌握老司機技術的必然之路。
一共兩件事,一是對其他車輛的駕駛行為預測,二是司機駕駛行為建模以便學習模仿這種技術。在ADAS層次,基于錯誤的駕駛操作危險預測,可以對司機的不良行為警告,這不是這里的討論范圍。
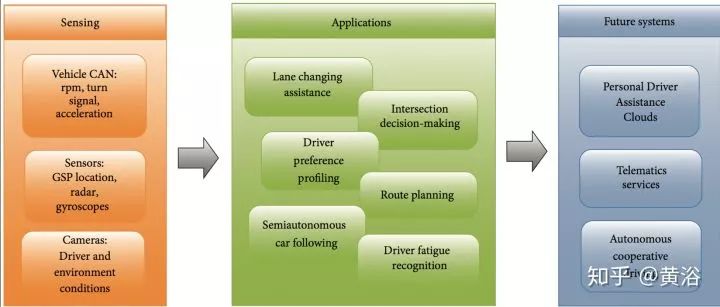
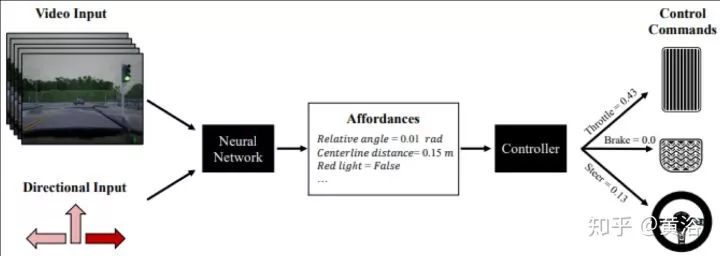
駕駛行為建模(DBM,driver behavior modeling)目的就是預測駕駛動作,預測駕駛員心思,還有環境因素,如下圖所示:各種傳感器和車載控制器CAN數據作為輸入,預處理算法過濾數據,然后給各種應用提供預測模型。
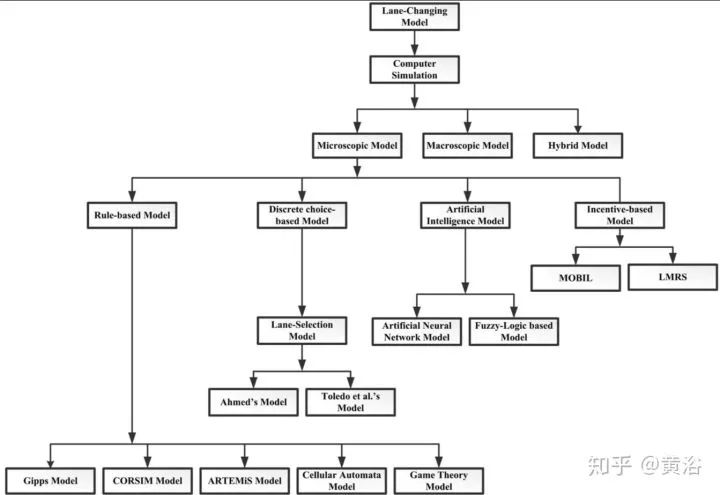
以換車道為例吧,建模方法可以分成微觀模型,宏觀模型(交通流)和二者混合模型。微觀模型又可以細分為基于規則模型,基于(概率)選擇模型,AI模型和基于激勵模型,見下圖。
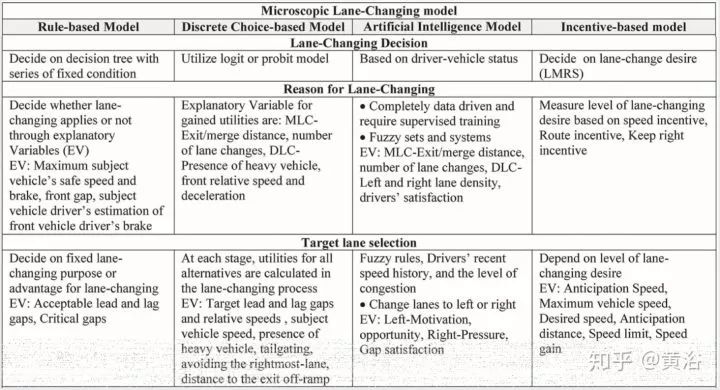
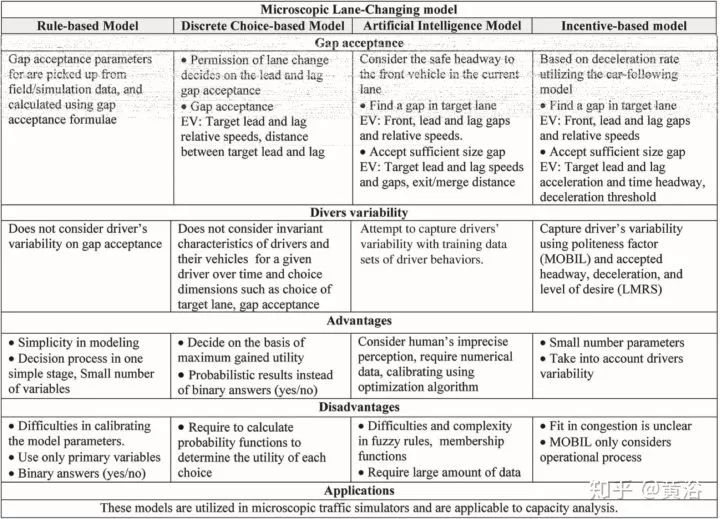
這些微觀模型的各個方法在決策(decision),理由(reason),目標車道選擇(target lane selection),可接受間距(gap),駕駛習慣(drivers variability)比如激進或者溫和 (aggressive or mild)等方面有各自的特色,如下面表格的總結。
規則法主要是基于Gipps模型建立包含一系列固定條件的決策樹,輸出是二值選擇;也有基于其他的,比如游戲理論的方法;
選擇法主要是采用概率模型,最大似然估計給出操作;
AI法需要車輛的行駛數據來訓練NN模型;
激勵法會考慮車道的吸引度和風險安全標準,也可以加入禮貌之類的個性化因素。
各自的優缺點對比:
規則法建模簡單,決策的變量少;難處是參數調節,判決只能二值;
選擇法決定來自于其概率計算,獲取最大的益處;問題是概率如何計算選擇的益處;
AI法是根據司機駕駛的數據,優化模型參數;但數據量要求大,函數復雜度高;
激勵法參數少,有駕駛風格選項可以考慮;但是交通擁擠的時候動機不清楚。
研究DBM,必然涉及道路網絡建模(RNM,road network modeling),即道路的拓撲結構。基本上,道路信息包括多個分級結構,如regional road network–road–road segment–carriageway–lane。
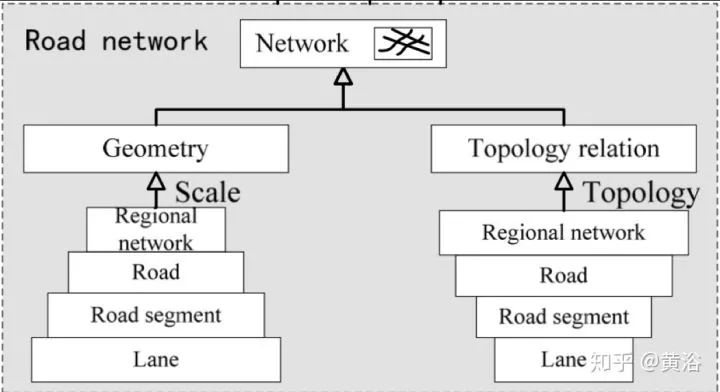
車道(Lane)是最基本的道路單位,而行車道(carriageway)是同一方向和類似交通性質的車道合并而成,如圖所示。

而這個是十字路口的行車道網絡結構。
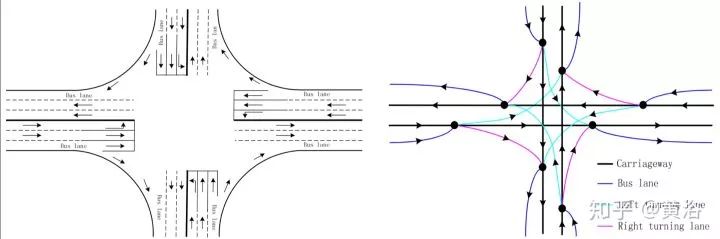
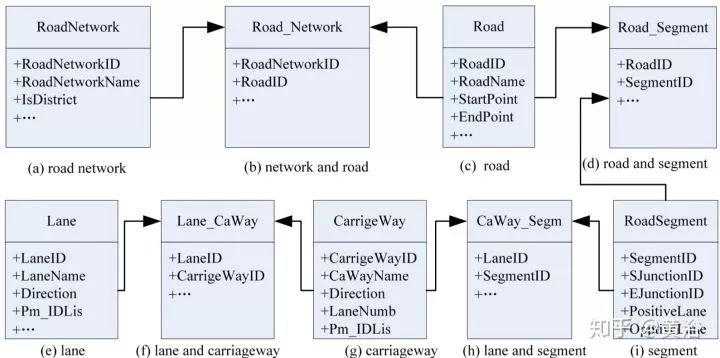
建立一個道路網絡和拓撲結構可以像下圖一樣。
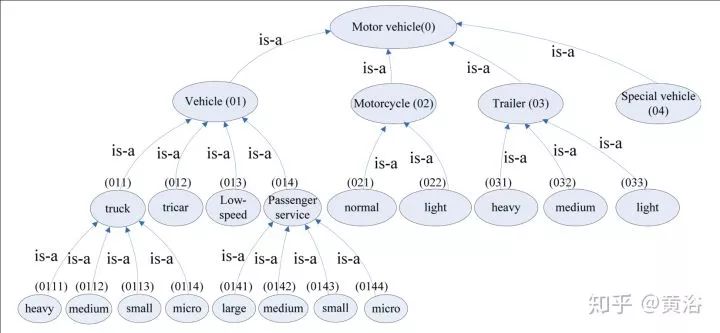
除了道路網絡,DBM也需要考慮車輛模型,下圖是一個車輛種類劃分的分級模型。
下面選幾篇論文分析一下做駕駛行為建模及其預測的研究工作。
這一篇文章是講述如何針對不同場景預測駕駛行為:“A Scenario-Adaptive Driving Behavior Prediction Approach to Urban Autonomous Driving“。
因為城市交通場景經常變化,需要在駕駛行為預測時候考慮對場景的自適應性。首先需要設計一個場景模型庫,稱為ontology,如下圖:包括兩個分支,一是Entity,二是Attribute;Entity包括4個部分:
MapEntity。它包括兩個部分,即AreaEntity和PointEntity。前者表示道路的一個區域,包括RoadPart,SideWalk,Junction,Segment和Lane。后者表示道路剩下的部分,包括TrafficSign,LaneMarker,StopLine。
ObstacleEntity。包括靜態和運動的。
EgoEntity。自身車的部分,VehicleType,EquippedSensors等等。
Environment。包括Weather,LightingConditions和RoadSurfaceConditions。
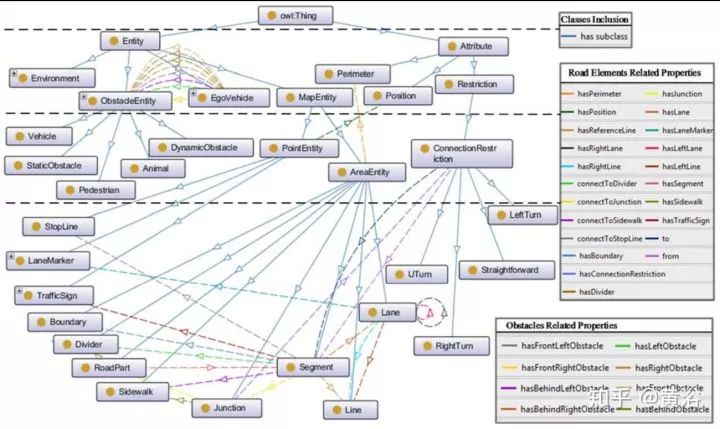
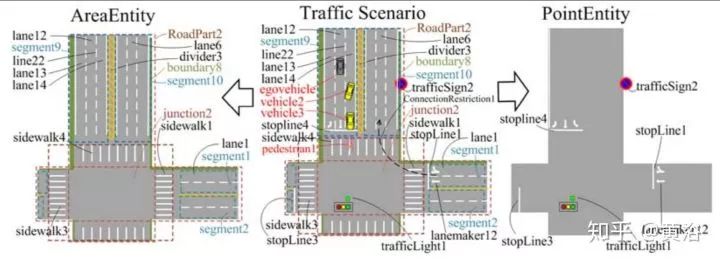
Attributes 描述位置,區域范圍和限制類型。包括Position,Perimeter和ConnectedRestriction。下圖是一個道路基于此ontology的分解:
回頭看,該駕駛行為預測方法的系統框架如圖描述:存在兩個工作模式,在線和離線。
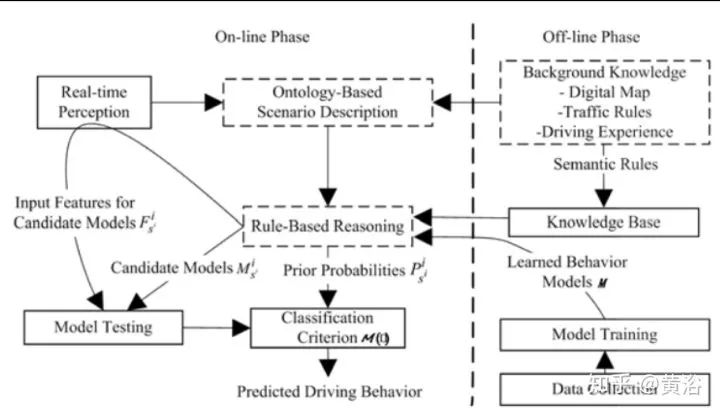
在離線模式,從數字地圖中提取道路信息,并根據上面的ontology模型進行描述;先從典型的交通場景里提取數據用于學習駕駛行為的連續特征;每個駕駛模型通過一個HMM學習;基于先驗知識(交通規則,駕駛經驗)定義候選行為模型,輸入特征,以及每個模型的先驗知識概率,構成語義規則;所有這些規則存于知識庫。
在線模式下,將知識庫的所有學習的模型和語義規則在初始化裝入內存,然后每個候選行為模型會計算其似然值,結合先驗概率得到行為標簽(tag)。
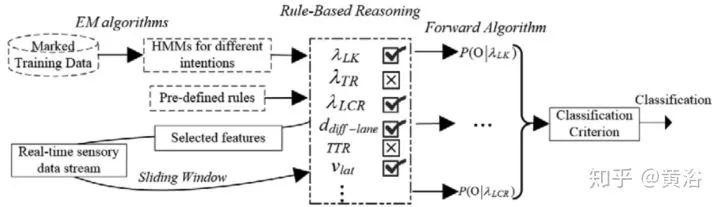
最后駕駛行為的預測方法如圖:對應行為集合的一組HMM已經離線學習完成,現在輸入實時的感知器數據,那么對于每個車輛,基于規則的推理模塊會計算產生其候選模型,而HMM中的Forward算法就能估計每個所選模型的擬合程度,即最大后驗估計。
這里給出一個實驗例子:
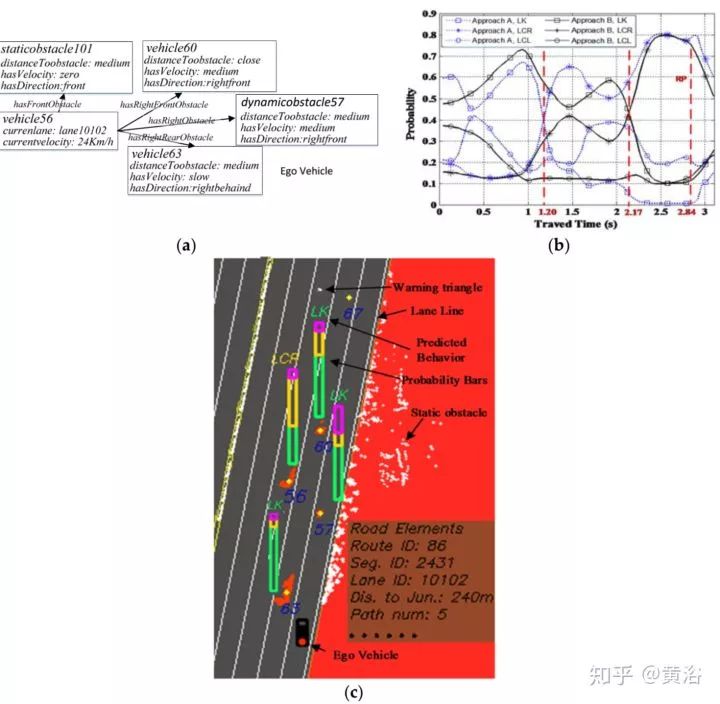
其中 (a) 是場景推理結果, (b) 不同行為似然值,(c) 駕駛行為預測界面。
北卡的駕駛行為預測的工作,兩篇論文:
第一篇是規劃算法AutonoVi,以支持滿足交通約束的無人駕駛動態機動(dynamic maneuvers):“AutonoVi: Autonomous Vehicle Planning with Dynamic Maneuvers and Traffic Constraints”。
其中機動包括拐彎,換道和剎車等動作,要求遵守各種交通規則(路口紅燈/stop牌停車)和避撞(行人,車輛,自行車)。下圖是算法流水線圖:

路徑規劃在前,按車道駕駛和交通生成一個引導軌跡,以及一串候選控制輸入(PID控制器)。這些控制會以數據驅動的車輛動力建模和控制障礙物理論(Control Obstacle)的無碰撞導航為標準評估,最后剩下的軌跡再通過優化算法(Path,Comfort,Maneuver,Proximity等為開銷)決定最佳控制信號。
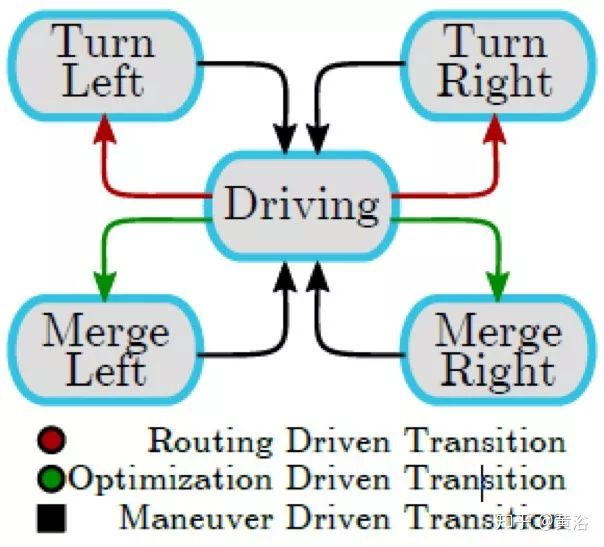
車輛的行為描述為有限狀態機(FSM),如下圖:
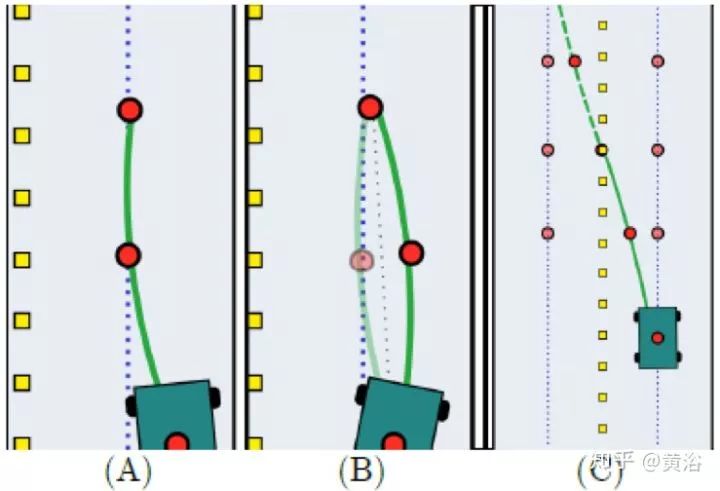
軌跡規劃要計算一組沿著車道中心等時間間隔的waypoints。如圖給出一個計算引導路徑的例子:(a)偏離中心被平滑引回;(b) 突然改變前進方向;(c)換道,離開和目標車道的waypoints加權平均。
第二篇討論如何從車輛軌跡分析駕駛行為并用于自動駕駛:"Identifying Driver Behaviors using Trajectory Features for Vehicle Navigation"。
算法的框架如圖:
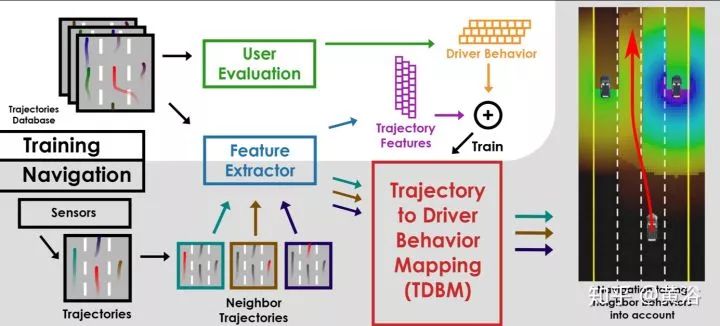
其中定義一個模塊叫Trajectory to Driver Behavior Mapping (TDBM),有6種駕駛員行為定義和分析,主要衍生于兩種基本模式Aggressiveness 和Carefulness,定義如下。

其中0-5是駕駛行為測度,6-9是注意(attention)測度。
很重要的一點是,作者定義了一組軌跡的特征,以此形成軌跡到行為的映射,10個候選特征見下表,其中綠色部分就是用來計算行為測度的,藍色是用來一起計算行為測度和注意測度。

選擇特征的方法是基于LASSO分析,映射關系最終是矩陣形式。應用在自動駕駛時,選擇了前面提到的AutonoVi規劃算法。
Uber Toronto最近的駕駛預測工作,有兩篇論文
"Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net"
"IntentNet: Learning to Predict Intention from Raw Sensor Data"
第一篇論文介紹一種將目標檢測工作和預測合為一體的系統FAF,如圖所示:
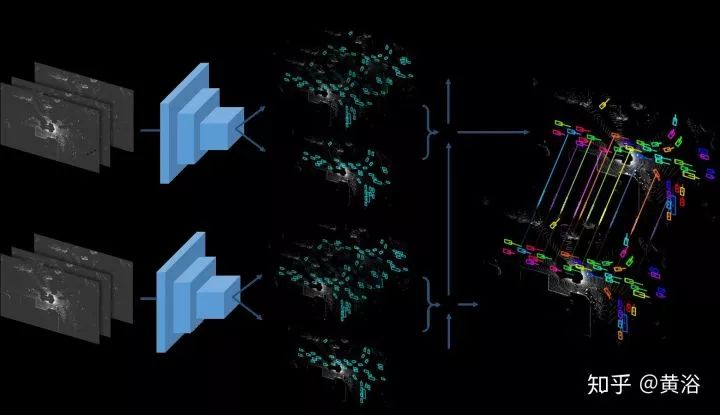
這里數據是激光雷達的點云,利用它的鳥瞰投影作為模型輸入。其實預測部分才是我們感興趣的,當然三合一的NN模型是新穎的方式。模型輸入多幀數據構成4-D張量,利用3-D卷積做預測。下圖是運動預測的示意圖(t, t+1, ...,t+n-1):

第二篇論文在此基礎上,定義意向(intent)是一個高級行為和連續的軌跡的組合,提出了一個預測意向的模型IntentNet。看看模型的輸入,輸出和模型結構的介紹:
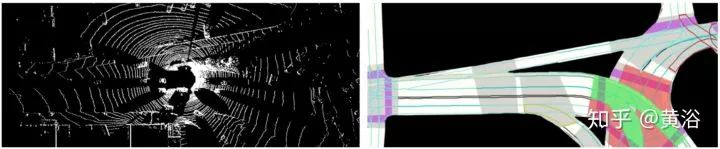
輸入如上圖,左邊是點云鳥瞰投影,右邊是靜態地圖部分,包括道路,車道,十字路口,交通牌和紅綠燈等。
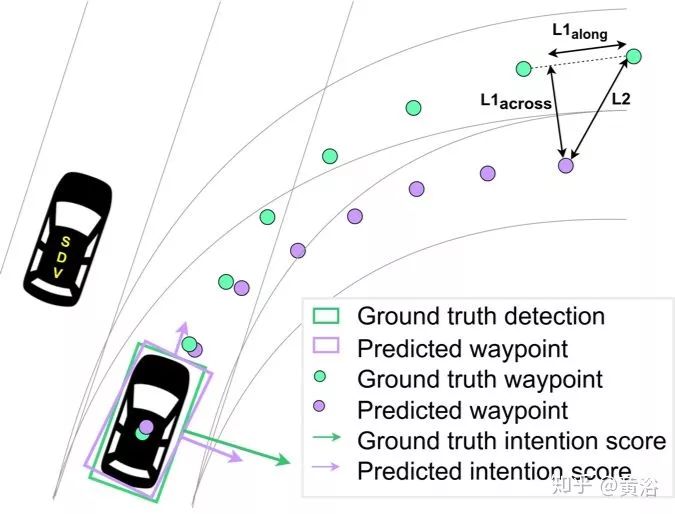
下圖是輸出部分:綠色是groundtruth,粉色是預測的結果,箭頭表示意向分數,針對定義的8種行為類型而言,即保持車道,左轉,右轉,換左道,換右道,停止,泊車和其他。
下圖是模型結構:一種后融合方法。
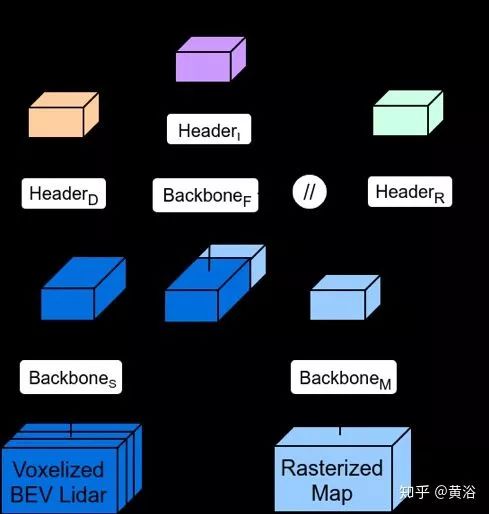
其中一些模型細節:
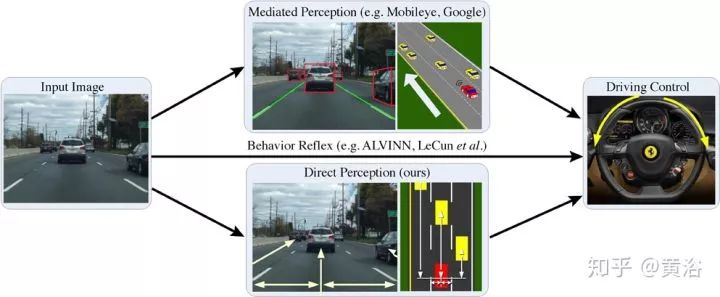
關于學習駕駛行為的工作,先介紹一篇相對舊的文章,是普林斯頓大學X教授研究組的:“DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving“。
這個圖對E2E學習“老”司機駕駛的方法進行劃分:mediated perception,分析觀測場景得到駕駛決策;behavior reflex 直接映射傳感器數據(圖像為例)到駕駛動作,有些類似特斯拉提出的Autopilot software 2.0;第三種方法,direct perception,作者定義affordance,標記一些如車輛相對道路的角度,到車道線的距離,和相鄰車輛的距離等,這些信息由感知得到,然后映射到駕駛動作。
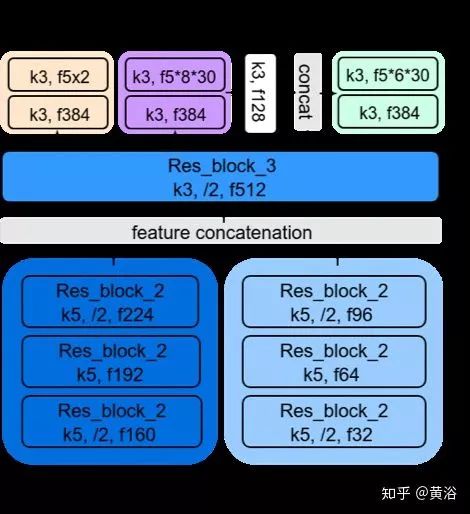
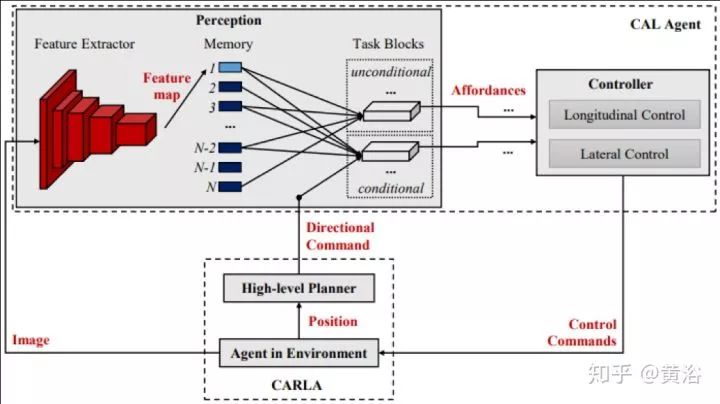
沿著Affordance這個思路,看看最近蘇黎世ETH的駕駛行為學習工作:“Conditional Affordance Learning for Driving in Urban Environments“。
為了和模擬學習或條件性模擬學習區別開,作者稱自己的方法為Conditional Affordance Learning (CAL) 。上圖所示,輸入的除了傳感器的數據(視頻為例),還有一些高級方向性的信號,即“直行“,”左行“和”右行“之類的行為類別。
下圖給出系統的框圖:模型訓練出來一組駕駛行為Affordance,送入車輛控制器。
定義的Affordance見左下表:分類取決于種類(連續/離散)和條件性(紅綠燈,限速)。
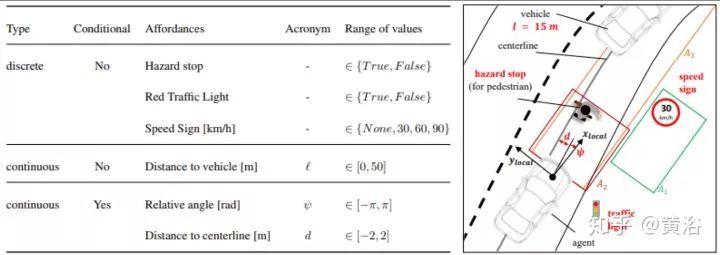
文中定義了6個危險事件:駕駛車道錯誤,車上行人道,闖紅燈,車相撞,撞行人,和撞靜態物體。訓練在開源仿真模擬軟件Carla進行,測試也是。
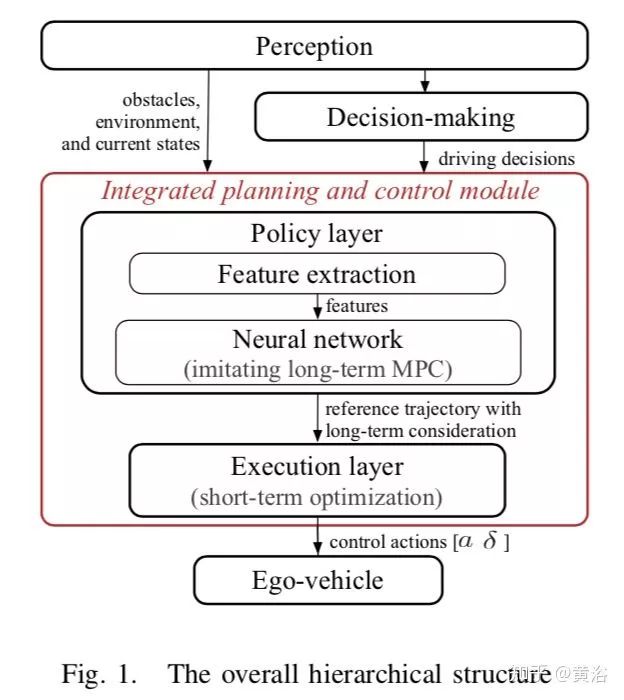
加州伯克利分校的這個工作是通過模擬學習(Imitation Learning)方法得到一個集成規劃和控制的框架,結合了機器學習和優化理論的兩層分級結構:“A Fast Integrated Planning and Control Framework for Autonomous Driving via Imitation Learning“ 。
這個框架的第一層是policy layer,通過NN學習長期的最優MPC駕駛策略,第二層是execution layer,主要跟蹤上一層policy layer生成的參考軌跡(reference trajectory),是一個保證短期安全和可行性的基于優化的短期控制器。特別提出的一點,第一層采用在線模擬學習,其中借用了dataset aggregation(DAgger)的方法,可以快速連續地改進policy layer。
下圖是整個分級二層結構:包括感知,決策,規劃控制等模塊。它不是一個E2E的模擬學習方法,其實包括感知在內的E2E機器學習框架是比較risky的,以前也提過這種corner case太多。
下圖是定義的Sampled DAgger,用在policy layer的模擬學習:
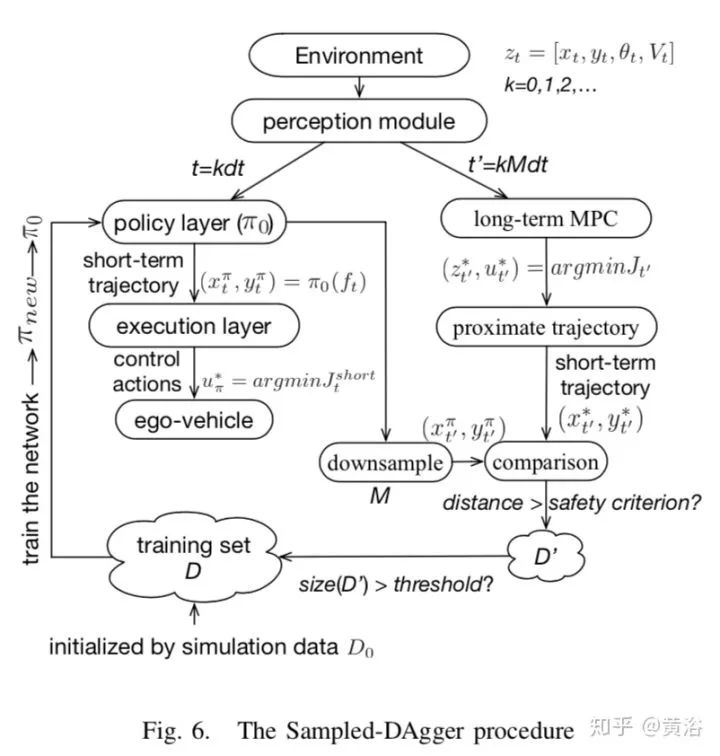
跟以前的DAgger相比,Sampled DAgger的數據效率更高。
另外,論文里做了對學習的policy泛化處理,可以用在復雜的駕駛場景,下圖是一個多車道的駕駛場景:
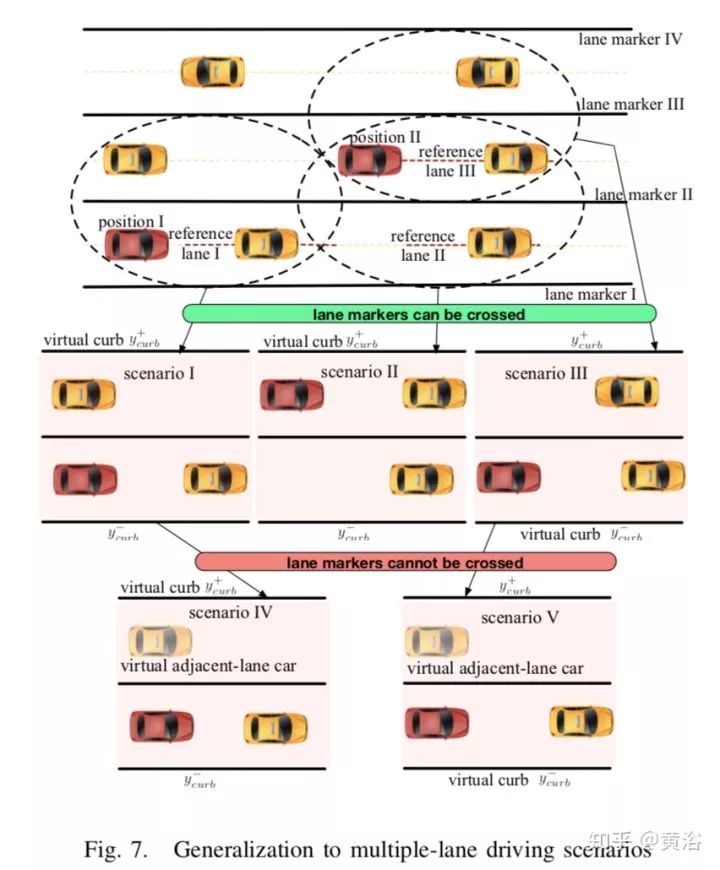
泛化就是將一個連續駕駛的問題降為一系列的抽象場景,而每個抽象場景能直接應用學習的policy模型來求解。
谷歌WayMo的最新文章介紹通過駕駛數據模擬學習駕駛策略:“ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst“。
該文反對純粹地模擬所有數據,而是在模擬損失上附加一些損失(比如碰撞,離開路和幾何上軌跡的不光滑等)來懲罰不期望出現的事件和鼓勵進步,這些擾動增強了模型的魯棒性。實驗中表明ChauffeurNet模型可以處理復雜的情況。
以下圖是模型的輸入-輸出:地圖,交通燈,限速,路徑,自身位置和姿態,其他車輛/行人/自行車的位置和姿態和自身姿態的過去軌跡,作為輸入,而輸出是自身的下一個姿態。

駕駛模型包括幾個部分,如下圖:FeatureNet,AgentRNN,Road Mask Net,PerceptionRNN。
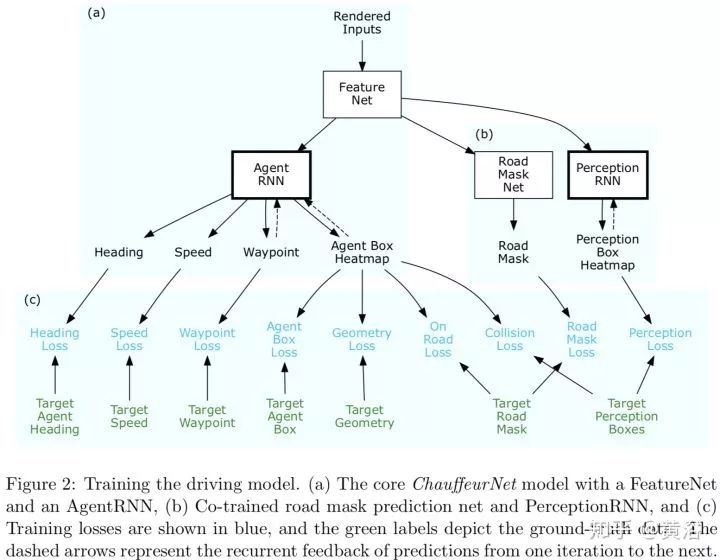
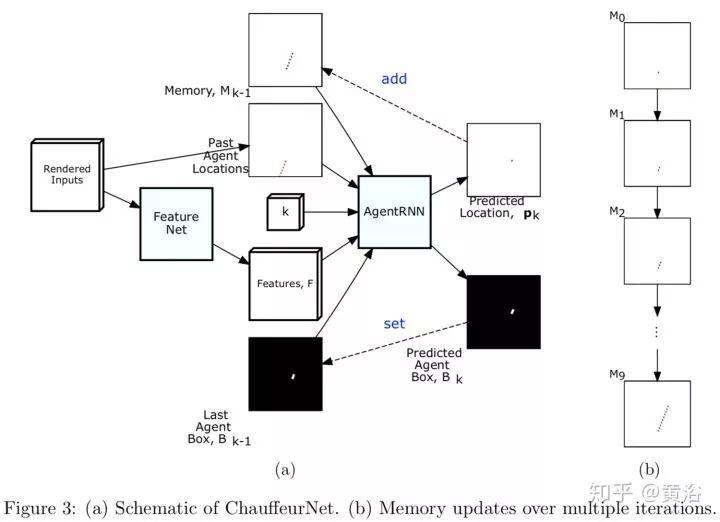
更詳細的描述可以見下圖:那些輸入先進入FeatureNet輸出Feature,然后再進入AgentRNN來預測駕駛軌跡的下一個位置,車身的heatMap,迭代次數,以前預測的Memory(單通道圖像,是一個疊加型內存,每次迭代會在預測位置加一),和上次迭代預測的車身heatMap。
整個軟件系統框圖如下:

實驗中特意提到有一個路旁停車被成功地繞開的例子。
總的看,駕駛行為的學習以及對其他車輛駕駛的預測都是目前比較關鍵的問題,如果感知的一些不足,可以說是一些失誤,能不能被行為模型看成噪聲或者干擾而成功忽略和“屏蔽”,那么就是自動駕駛模塊化的研發過程中成功的進步。但目前的實驗,還不能證明這一點,主要是數據不夠,而且駕駛模型中ontology也不完備。
另外大家也認為感知和規劃應該被看成一個整體,所以研發的次序應該是在感知和規劃+控制的交替中前進,感知的進步會驅使駛決策模型的更新。
-
adas
+關注
關注
309文章
2168瀏覽量
208526 -
自動駕駛
+關注
關注
783文章
13687瀏覽量
166154
原文標題:自動駕駛中的駕駛行為建模和預測方法
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
豐田與NTT合作開發自動駕駛軟件,AI預測事故助力安全駕駛
智能駕駛對環境保護的貢獻
智能駕駛所需的基礎設施
智能駕駛對交通安全的影響
智能駕駛系統的工作原理
FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
深度學習在自動駕駛中的關鍵技術
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
Waymo自愿召回444輛自動駕駛汽車 L4的自動駕駛還有很多路要走


如何使用Trajeglish幫助自動駕駛汽車學習人類駕駛行為語言呢?

LabVIEW開發自動駕駛的雙目測距系統
使用 Bi-Level 模仿學習仿真現實交通行為






 工商網監
工商網監
評論