 機器學習研究中常見的七大謠傳總結
機器學習研究中常見的七大謠傳總結
在學習深度學習的過程中,我們常會遇到各種謠傳,也會遇到各種想當然的「執念」。在本文中,作者總結了機器學習研究中常見的七大謠傳,他們很多都是我們以前的固有概念,而最近又有新研究對它們提出質疑。所以在為機器學習填坑的生涯中,快自檢這七個言傳吧。
謠傳一:TensorFlow 是一個張量運算庫
事實上,TensorFlow 是矩陣而不是張量運算庫,這兩者的區別非常大。
在 NeurIPS 2018 的論文 Computing Higher Order Derivatives of Matrix and Tensor Expressions 中,研究者表明,他們基于張量微積分(Tensor Calculus)所建立的新自動微分庫具有明顯更緊湊(compact)的表達式樹(expression trees)。這是因為,張量微積分使用了索引標識,進而使前向模式和反向模式的處理方式相同。
與此相反,矩陣微積分出于標識方便的考慮隱藏了索引,這也通常會導致自動微分的表達式樹顯得過于復雜。
若有矩陣的乘法運算:C=AB。在前向模式中,有
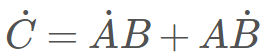
,而在反向模式中,則有
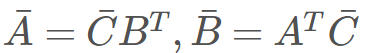
。為了正確完成乘法計算,我們需要注意乘法的順序和轉置的使用。對于機器學習開發者而言,這只是在標識上的一點困惑,但對于程序而言,這是一個計算上的開銷。
以下是另一個例子,毫無疑問意義更大一些:對于求行列式 c=det(A)。在前向模式中,有
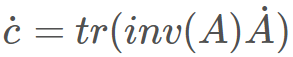
,而在反向模式中,則有
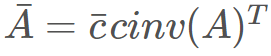
。這里可以明顯看出,無法使用同一個表達式樹來表示兩種模式,因為二者是由不同運算組成的。
總的來說,TensorFlow 和其他庫(如 Mathematica、Maple、 Sage、SimPy、ADOL-C、TAPENADE、TensorFlow, Theano、PyTorch 和 HIPS autograd)實現的自動微分方法,會在前向模式和反向模式中,得出不同的、低效的表達式樹。而在張量微積分中,通過索引標識保留了乘法的可交換性,進而輕松避免了這些問題(具體的實現原理,請閱讀論文原文)
研究者通過反向傳播,在三個不同問題上,測試了反向模式自動微分新方法的性能,并度量了其計算 Hessian 矩陣所消耗的時間。
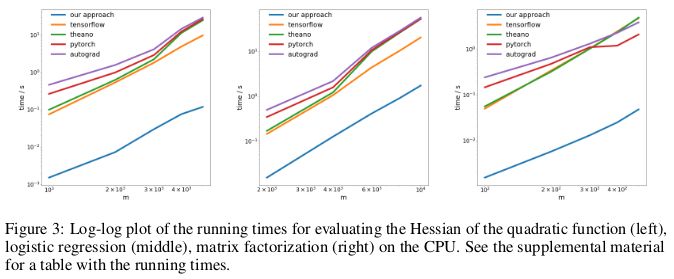
第一個問題是優化一個形如 xAx 的二次函數;第二個問題是求解一個邏輯回歸;第三個問題是求解矩陣分解。
在 CPU 上,新方法與當下流行的 TensorFlow、Theano、PyTorch 和 HIPS autograd 等自動微分庫相比,要快兩個數量級。
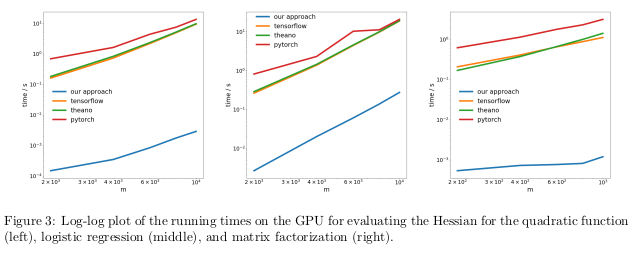
在 GPU 上,研究者發現,新方法的提速更加明顯,超出流行庫的速度近似三個數量級。
意義:利用目前的深度學習庫完成對二次或更高階函數的求導,所花費的成本比本應消耗的更高。這包含了計算諸如 Hessian 的通用四階張量(例:在 MAML 中,以及二階牛頓法)。幸運的是,在「深度」學習中,二階函數并不常見。但在「傳統」機器學習中,它們卻廣泛存在:SVM對偶問題、最小二乘回歸、LASSO,高斯過程……
謠傳二:機器學習研究者并不使用測試集進行驗證
在機器學習第一門課中,我們會學習到將數據集分為訓練集、驗證集以及測試集。將在訓練集上訓練得到模型,在驗證集上進行效果評估,得出的效果用以指導開發者調節模型,以求在真實場景下獲得效果最好的模型。直到模型調節好之后,才應該使用測試集,提供模型在真實場景下實際表現的無偏估計。如果開發者「作弊」地在訓練或驗證階段使用了測試集,那么模型就很可能遇到對數據集偏差產生過擬合的風險:這類偏差信息是無法在數據集外泛化得到的。
在機器學習研究高度競爭的環境下,對新算法/模型的評估,通常都會使用其在測試集上的表現。因此對于研究者而言,沒有理由去寫/提交一篇測試集效果不 SOTA 的論文。這也說明在機器學習研究領域,總體而言,使用測試集進行驗證是一個普遍現象。
這種「作弊」行為的影響是什么?
在論文 DoCIFAR-10Classifiers Generalize to CIFAR-10? 中,研究者們通過在 CIFAR-10 上建立了一個新的測試集,來研究此問題。為此,他們解析標注了來自 Tiny Images 庫的圖像,就像最初的數據采集過程一樣。
常用測試集帶來過擬合?你真的能控制自己不根據測試集調參嗎
研究者們之所以選擇 CIFAR-10,是因為它是機器學習界使用最廣泛的數據集之一,也是 NeurIPS 2017 中第二受歡迎的數據集(在 MNIST 之后)。CIFAR-10 數據集的創建過程也有完善公開的文檔記錄。而龐大的 Tiny Images 庫中,也有足夠的細粒度標簽數據,進而使得在盡量不引起分布偏移的情況下重建一個測試集成為了可能。
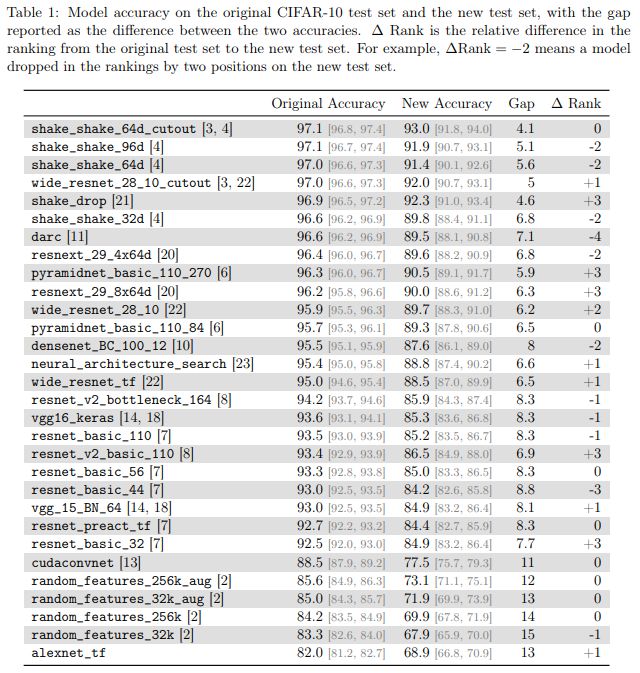
研究者發現,很多神經網絡模型在從原來的測試集切換到新測試集的時候,都出現了明顯的準確率下降(4% - 15%)。但各模型的相對排名依然相對穩定。
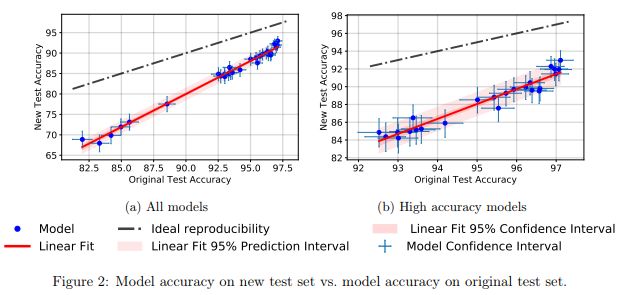
總的來說,相較于表現較差的模型,表現較好模型的準確率下降程度也相對更小。這是一個振奮人心的消息,因為至少在 CIFAR-10 上,隨著研究社區發明出更好機器學習模型/方法,由于「作弊」得到的泛化損失,也變得更加輕微。
謠傳三:神經網絡訓練過程會使用訓練集中的所有數據點。
有這樣一個常見說法,數據是新的原油(財富),數據量越大,我們就能將數據相對不足的、過參數化的深度學習模型訓練得越好。
在 ICLR 2019 的一篇論文 An Empirical Study of Example Forgetting During Deep Neural Network Learning 中,研究者們表示在多個常見的較小圖像數據集中,存在顯著冗余。令人震驚的是,在 CIFAR-10 中,我們可以在不顯著影響測試集準確率的情況下剔除 30% 的數據點。
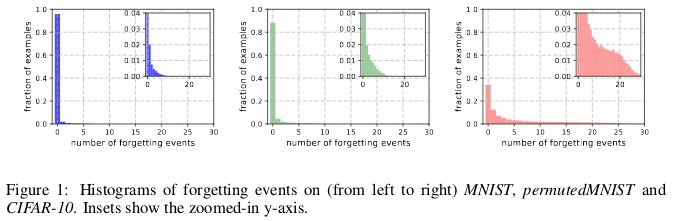
當神經網絡在 t+1 時刻給出誤分類、而在 t 時刻給出了準確的分類時,就稱為發生了遺忘事件(forgetting event)。這里的「時刻」是指訓練網絡的隨機梯度下降(SGD)的更新次數。為了讓記錄遺忘事件變得可行,研究者每次只在用于完成 SGD 更新的小批量數據上運行神經網絡,而不是在數據集的單個樣本上運行。對于不會經歷遺忘事件的樣本,稱之為不可遺忘樣本(unfogettable example)。
研究者發現,MNIST 中 91.7%、permutedMNIST 中 75.3%、CIFAR-10 中 31.3% 以及 CIFAR-100 中 7.62% 的數據屬于不可遺忘樣本。這符合直觀理解,因為隨著圖像數據集的多樣性和復雜性上升,神經網絡理應遺忘更多的樣本。
相較于不可遺忘樣本,可遺忘樣本似乎表現了更多不尋常的獨特特征。研究者將其類比于 SVM 中的支持向量,因為它們似乎劃分了決策邊界。
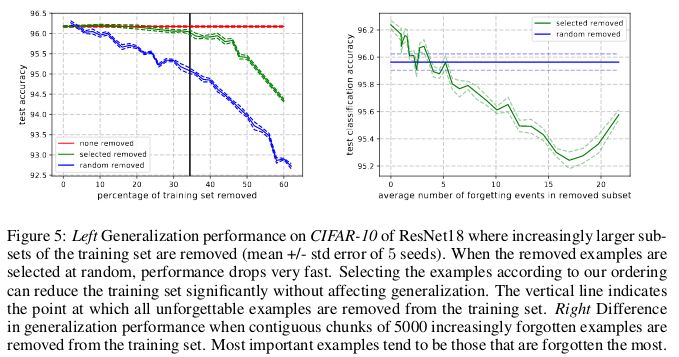
與此相反,不可遺忘樣本則編碼了絕大部分的冗余信息。如果將樣本按其不可遺忘性(unforgettability)進行排序,就可以通過刪除絕大部分的不可遺忘樣本,而對數據集完成壓縮。
在 CIFAR-10 中,30% 的數據可以在不影響測試集準確率的情況下移除,而刪除 35% 的數據則會產生 0.2% 的微小測試準確率下降。如果所移除的 30% 數據是隨機挑選而非基于不可遺忘性,那么就會導致約 1% 的顯著下降。
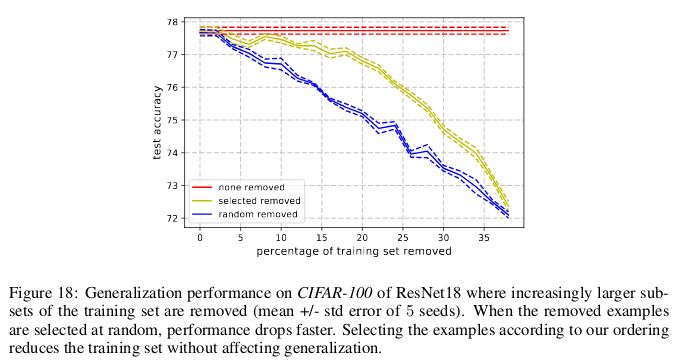
與此類似,在 CIFAR-100 上,8% 的數據可以在不影響測試集準確率的情況下移除。
這些發現表明,在神經網絡的訓練中,存在明顯的數據冗余,就像 SVM 的訓練中,非支持向量的數據可以在不影響模型決策的情況下移除。
意義:如果在開始訓練之前,就能確定哪些樣本是不可遺忘的,那么我們就可以通過刪除這些數據來節省存儲空間和訓練時間。
謠傳四:我們需要批標準化來訓練超深度殘差網絡。
長久以來,人們都相信「通過隨機初始參數值和梯度下降,直接優化有監督目標函數(如:正確分類的對數概率)來訓練深度網絡,效果不會很好。」
從那時起,就有很多聰明的隨機初始化方法、激活函數、優化方法以及其他諸如殘差連接的結構創新,來降低利用梯度下降訓練深度神經網絡的難度。
但真正的突破來自于批標準化(batch normalization)的引入(以及其他的后續標準化技術),批標準化通過限制深度網絡每層的激活值尺度,來緩和梯度消失、爆炸等問題。
值得注意的是,在今年的論文 Fixup Initialization: Residual Learning Without Normalization 中,研究表明在不引入任何標準化方法的情況下,通過使用 vanilla SGD,可以有效地訓練一個 10,000 層的深度網絡。
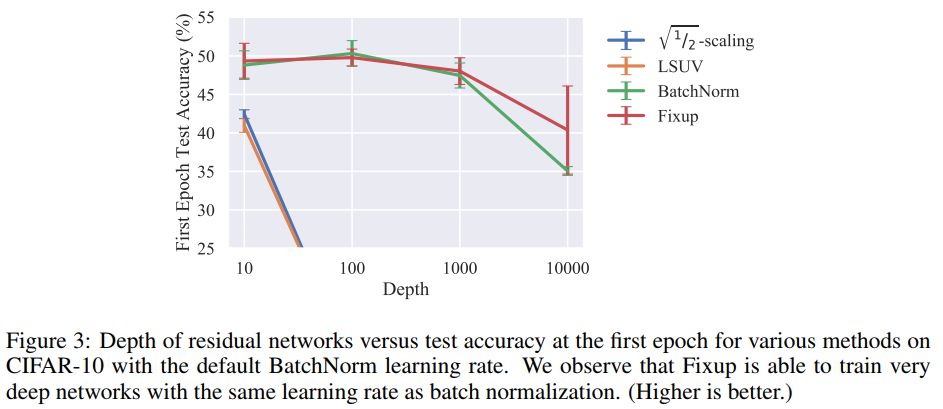
研究者比較了在 CIFAR-10 上,不同深度殘差網絡訓練一個 epoch 的結果。并發現,雖然標準初始化方法在 100 層的網絡上失敗了,但 Fixup 和批標準化都在 10,000 層的網絡上成功了。

研究者通過理論分析,證明了「特定神經層的梯度范數,以某個隨網絡深度增加而增大的數值為期望下界」,即梯度爆炸問題。
為避免此問題,Fixup 中的核心思想是在每 L 個殘差分支上,對 m 個神經層的權重,使用同時依賴于 L 和 m 的因子進行調整。」
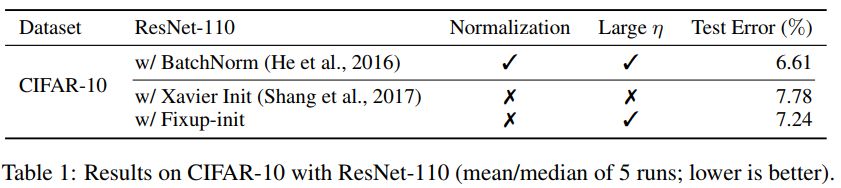
Fixup 使得能夠在 CIFAR-10 上以高學習速率訓練一個 110 層的深度殘差網絡,得到的測試集表現和利用批標準化訓練的同結構網絡效果相當。
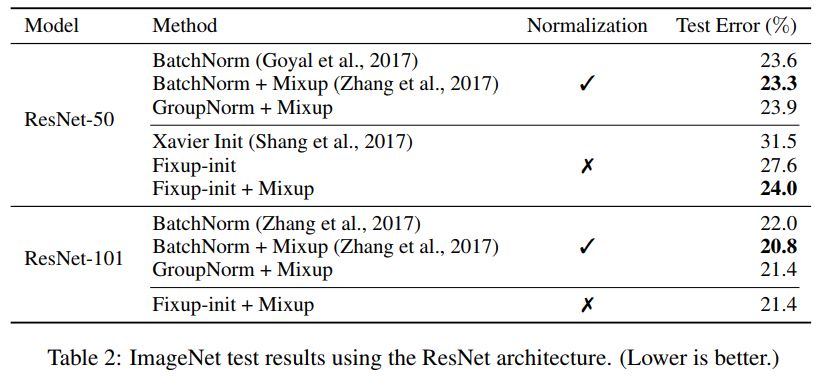
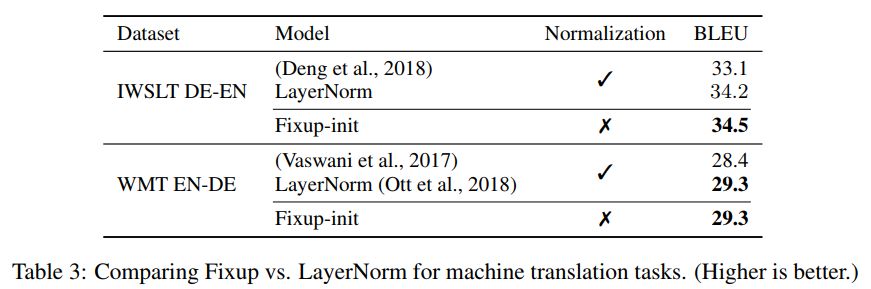
研究者也進一步展示了在沒有任何標準化處理下,基于 Fixup 得到的神經網絡在 ImageNet 數據集和英語-德語機器翻譯任務上相當的測試結果。
謠傳五:注意力>卷積
在機器學習領域,有一個正得到認同的說法,認為注意力機制是卷積的更優替代。重要的是 Vaswani et al 注意到「一個可分離卷積的計算成本,和一個自注意力層與一個逐點前饋層結合后的計算成本一致」。
即使是最新的 GAN 網絡,也展示出自注意力相較于標準卷積,在對長期、多尺度依賴性的建模上效果更好。
在 ICLR 2019 的論文 Pay Less Attention with Lightweight and Dynamic Convolutions 中,研究者對自注意力機制在長期依賴性的建模中,參數的有效性和效率提出了質疑,他們表示一個受自注意力啟發而得到的卷積變體,其參數效率更高。
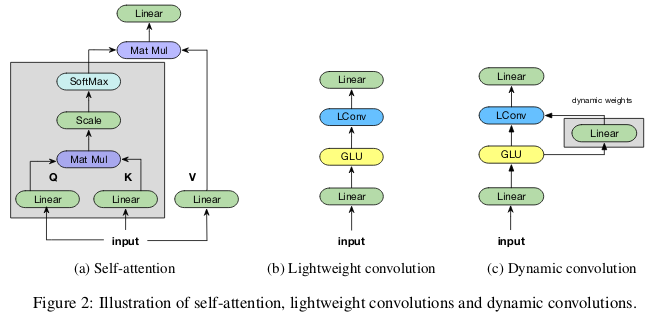
輕量級卷積(lightweight convolutions)是深度可分離(depthwise-separable)的,它在時間維度上進行了 softmax 標準化,通道維度上共享權重,且在每個時間步上重新使用相同權重(類似于 RNN 網絡)。動態卷積(dynamic convolutions)則是在每個時間步上使用不同權重的輕量級卷積。
這些技巧使得輕量級卷積和動態卷積相較于傳統的不可分卷積,在效率上優越幾個數量級。
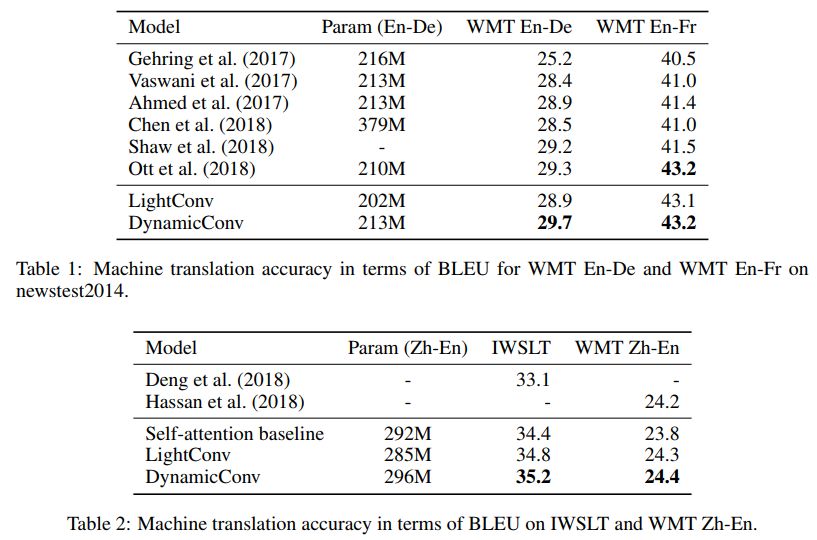
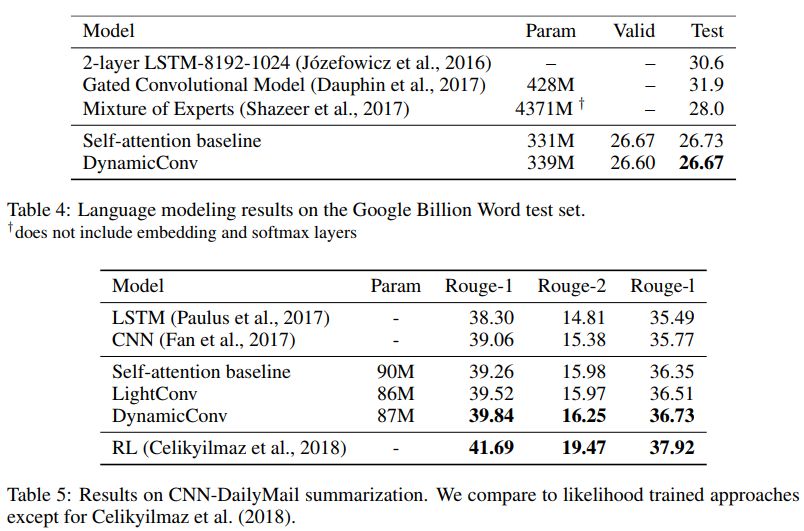
研究者也證明,在機器翻譯、語言建模和抽象總結等任務上,這些新卷積能夠使用數量相當或更少的參數,達到或超過基于自注意力的基準效果。
謠傳六:圖像數據集反映了自然世界真實圖像分布
我們可能會認為,如今的神經網絡在目標識別任務上,效果已經超出真人水平。這并不正確。在 ImageNet 等篩選出來的圖像數據集上,它們的效果可能確實優于真人。但對于自然世界的真實圖像,它們在目標識別上絕對無法比正常成年人做得更加出色。這是因為,從目前的圖像數據集中抽取的圖像,和從真實世界整體中抽取的圖像并不一樣,二者分布并不相同。
這里有一篇 2011 年比較老的論文: Unbiased Look at Dataset Bias,其中,研究者根據 12 個流行的圖像數據集,嘗試通過訓練一個分類器用以判斷一個給定圖像來自于哪個數據集,來探索是否存在數據集偏差。
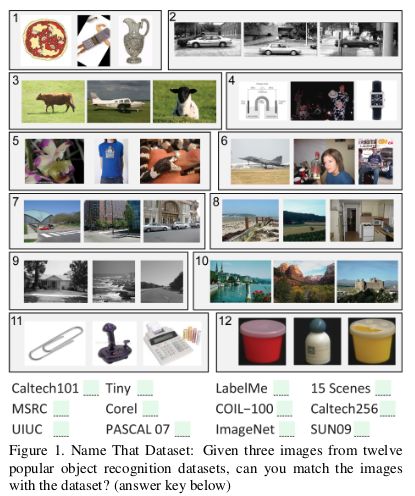
隨機猜測的正確率應該是 1/12 = 8%,而實驗結果的準確率高于 75%。

研究者在 HOG 特征上訓練了一個 SVM,并發現其正確率達到 39%,高于隨機猜測水平。如今,如果使用最先進的 CNN 來復現這一實驗,很可能得到更好的分類器效果。
如果圖像數據集確實能夠表征來自自然世界的真實圖像,就不應能夠分辨出某個特定圖像是來自于哪個數據集的。
但數據中的偏差,使得每個數據集變得可識別。例如,在 ImageNet 中,有非常多的「賽車」,不能認為這代表了通常意義上「汽車」的理想概念。
研究者在某數據集訓練分類器,并在其他數據集上評估表現效果,進一步度量數據集的價值。根據這個指標,LabelMe 和 ImageNet 是偏差最小的數據集,在「一籃子貨幣(basket of currencies)」上得分 0.58。所有數據集的得分都小于 1,表明在其他數據集上訓練的模型都給出了更低的準確度。在沒有數據集偏差的理想情況下,應該有一些得分是高于 1 的。
謠傳七:顯著圖(saliency maps)是解釋神經網絡的一個穩健方法。
雖然神經網絡通常被認為是黑箱模型,現在還是已經有了有非常多對其進行解釋的探索。顯著圖,或其他類似對特征或訓練樣本賦予重要性得分的方法,是其中最受歡迎的形式。
能夠將圖像進行特定分類的理由,總結為圖像特定部分對模型決策過程中起的作用,是一個非常誘人的課題。已有的幾種計算顯著圖的方法,通常都基于神經網絡在特定圖像上的激活情況,以及網絡中所傳播的梯度。
在 AAAI 2019 的一篇論文 Interpretation of Neural Networks is Fragile 中,研究者表明,可以通過引入一個無法感知的擾動,來破壞一個特定圖像的顯著圖。
「帝王蝶之所以被分類為帝王蝶,并不是因為翅膀的圖案樣式,而是因為背景上一些不重要的綠色樹葉。」
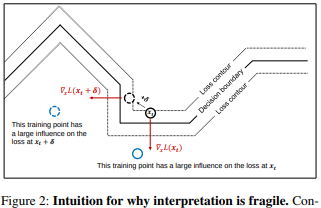
高維圖像通常都位于深度神經網絡所建立的決策邊界附近,因此很容易受到對抗攻擊的影響。對抗攻擊會將圖像移動至決策邊界的另一邊,而對抗解釋攻擊則是將圖像在相同決策區域內,沿著決策邊界等高線移動。

為實現此攻擊,研究者所使用的基本方法是Goodfellow提出的 FGSM(fast gradient sign method)方法的變體,這是最早的一種為實現有效對抗攻擊而引入的方法。這也表明,其他更近的、更復雜的對抗攻擊也可以用于攻擊神經網絡的解釋性。
意義:隨著深度學習越來越普遍地應用于高風險場景,如醫學成像,對于如何解釋神經網絡所做的結論也越發重要。例如,雖然 CNN 網絡將 MRI 圖像上的小點識別為惡性致癌腫瘤是非常好的事情,但如果它們是基于非常脆弱的解釋方法,那么也不應姑妄信之。
-
機器學習
+關注
關注
66文章
8377瀏覽量
132407 -
tensorflow
+關注
關注
13文章
328瀏覽量
60498
原文標題:機器學習的七大謠傳,這都是根深蒂固的執念吧
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是機器學習?通過機器學習方法能解決哪些問題?


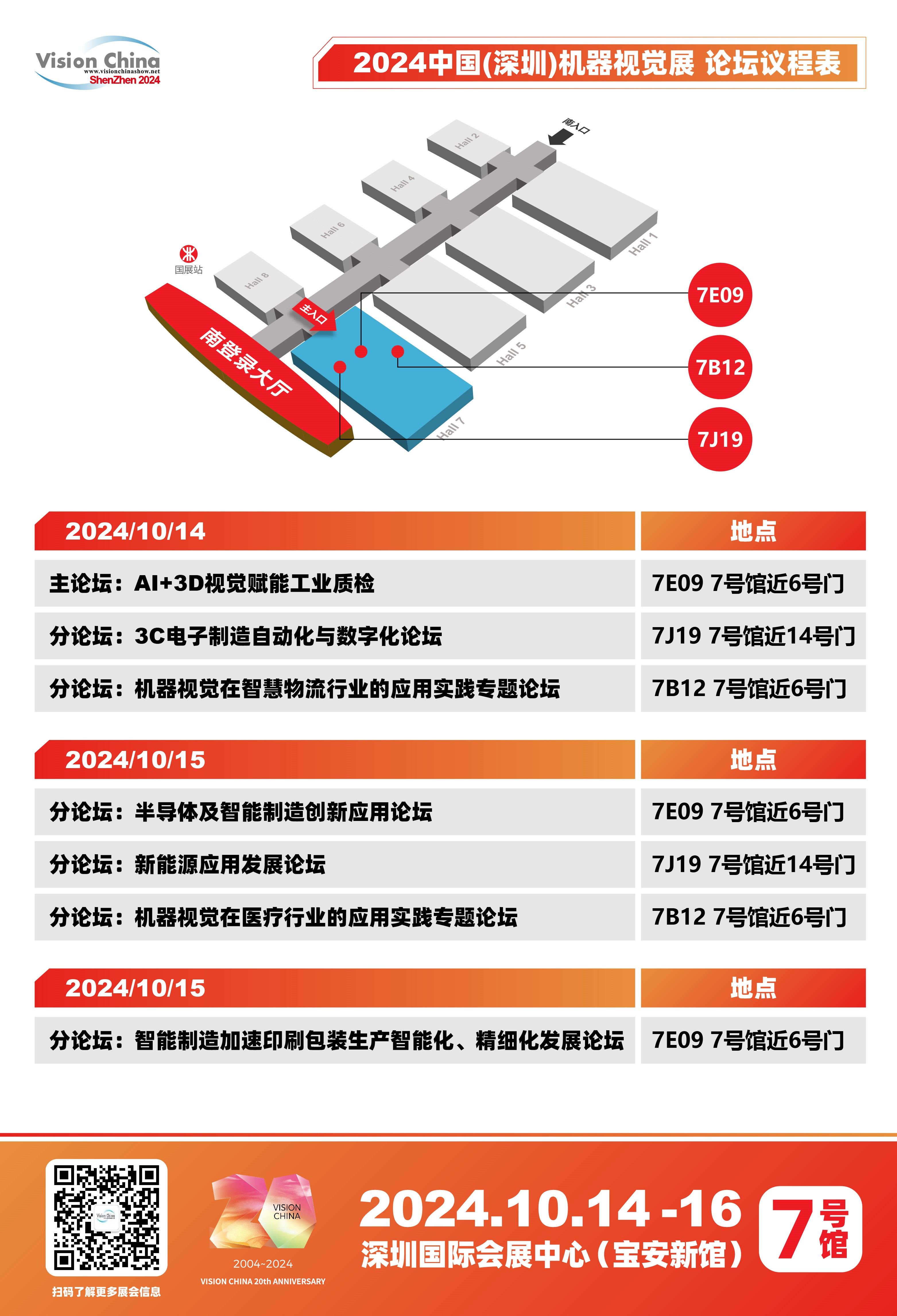
VisionChina2024(深圳)七大議題引領視覺技術跨界融合,部分論壇議程搶先看!







 工商網監
工商網監
評論