 一份非常詳盡的PyTorch教程,從如何安裝PyTorch開始
一份非常詳盡的PyTorch教程,從如何安裝PyTorch開始
本文通過詳實的代碼,從如何安裝PyTorch開始,一步一步帶領讀者熟悉PyTorch和Jupyter Notebook,最終使用PyTorch實現線性回歸、邏輯回歸以及圖像分類,非常適合0基礎初學者。
今天為大家帶來一份非常詳盡的PyTorch教程。本文共分3大部分:
安裝PyTorch和Jupyter Notebook
用PyTorch實現線性回歸
使用邏輯回歸實現圖像分類
文章超長,秉承用代碼搞定一切的原則,內含大量代碼,建議收藏,并分享給你喜歡的人。同時如果有什么疑問,也歡迎留言告知我們。
Tips:為了方便演示,文中代碼和返回結果是用截圖形式給出。本系列中的所有代碼都以Jupyter Notebook形式提供,托管在Jovian。托管鏈接:
https://jvn.io/aakashns/e5cfe043873f4f3c9287507016747ae5
安裝PyTorch和Jupyter Notebook
我們將使用Anaconda的Python發行版來安裝庫和管理虛擬環境,對于交互式編碼和實驗,我們將使用Jupyter Notebook。
首先按照官方教程安裝Anaconda,接下來安裝jovian:
$ pip install jovian --upgrade
下載針對本教程的notebook:
$ jovian clone e5cfe043873f4f3c9287507016747ae5
此時會創建一個01-pytorch-basics的目錄,包含01-pytorch-basics.ipynb和environment.yml文件。
$ cd 01-pytorch-basics$ conda env update
目的是不破壞本地Python環境,使用一個虛擬環境。接下來激活
$ conda activate 01-pytorch-basics
啟動Jupyter
$ jupyter notebook
打開瀏覽器,輸入http://localhost:8888 。然后點有01-pytorch-basics.ipynb字樣的就開始了。

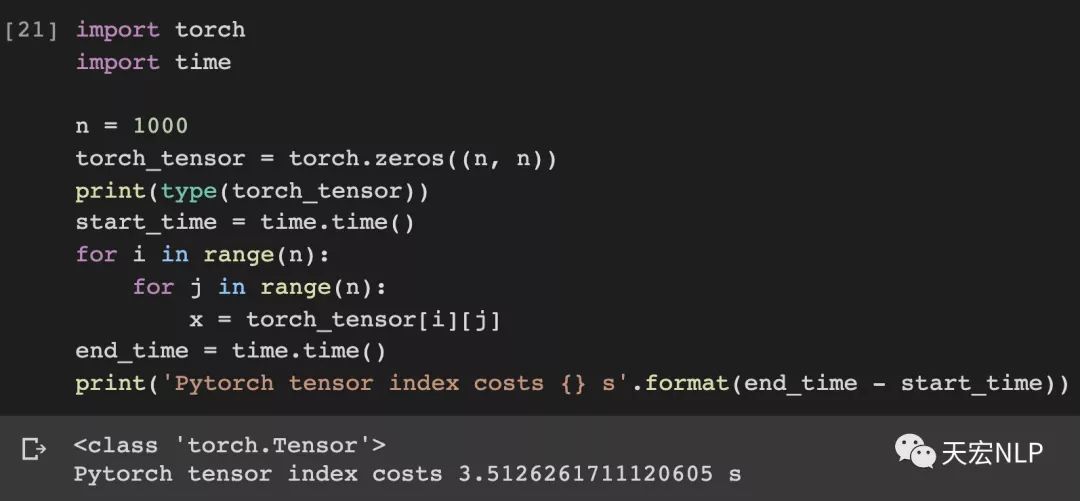
本質上PyTorch是處理Tensor的庫。所以我們先來簡單看下tensor類型:

因為很多時候我們需要在NumPy的數組和PyTorch數組之間進行轉換。


Commit并上傳:

上傳的項目還可以用 jovian clone 下載回來。操作類似git,這里不再累述。
簡單的開場之后,我們直接進入硬核階段。
用PyTorch實現線性回歸
對于線性回歸,相信大家都很熟悉了,各種機器學習的書第一個要講的內容必定有線性回歸。
這一部分,我們首先通過最原始的手動操作,來理解整個線性回歸的原理和操作流程。
接著我們會再介紹使用PyTorch內置的函數,通過自動化的方式實現線性回歸。
線性回歸模型中,每個目標變量都被估算為輸入變量的加權和及偏差。
先看一張表:
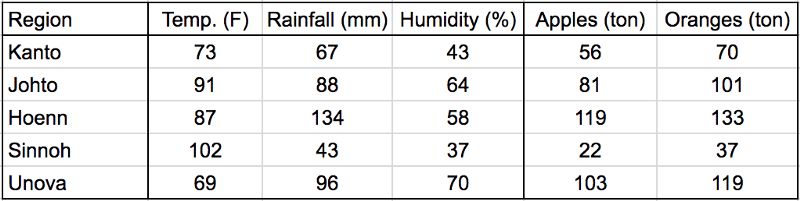
表格第一列是地區,第二類是溫度單位華氏度,第二列是降水量單位毫米,第四列是濕度,第五列是蘋果產量,第六列是橙子產量。
下面這段代碼的目的是為了預估出蘋果和橙子在不同地區、不同環境中的產量。
yield_apple = w11 * temp + w12 * rainfall + w13 * humidity + b1yield_orange = w21 * temp + w22 * rainfall + w23 * humidity + b2
分別個溫度temp、降水量rainfall、濕度humidity加上不同的權重(w11,w12,w13),最后再加一個b1或者b2的偏差。
通過使用被稱為梯度下降的優化技術,少量多次調整權重以獲得更精準的預測結果。
訓練數據
在Jupyter Notebook里導入NumPy和PyTorch

訓練數據我們inputs和targets兩個矩陣表示,每個觀察一行,每個變量一列。

接下來轉換成PyTorch的tensors:

變量和偏差也用矩陣表示,從隨機數值開始

模型可以表示為

我們這樣定義模型:

生成預測

對比一下原始數據

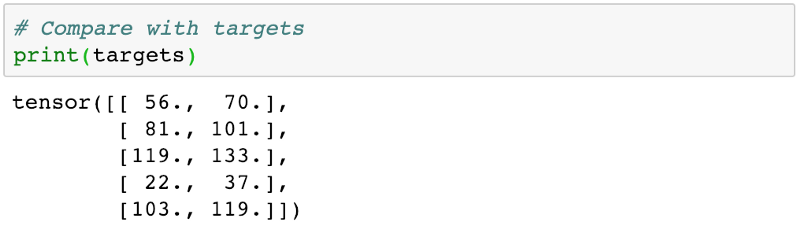
發現差距很大,因為一開始我們用的是隨機數值,所以數據合不上很正常。
接下來我們需要通過損失函數,來評估我們的模型和實際差距多大。分為3個步驟
計算兩個矩陣(preds和targets)之間的差異
平方差矩陣的所有元素以消除負值
計算結果矩陣中元素的平均值
最終結果為均方誤差MSE


計算梯度:

使用PyTorch可以自動計算損耗的梯度或導數w.r.t. 權重和偏差,因為requires_grad被設置為True。
計算權重梯度:

重置梯度:

使用梯度下降調整重量和偏差
我們將使用梯度下降優化算法減少損失并改進我們的模型,該算法具有以下步驟:
生成預測
計算損失
計算梯度w.r.t權重和偏差
通過減去與梯度成比例的小量來調整權重
將漸變重置為零
讓我們逐步實現上述步驟
接下來分別用代碼表示:



最終效果:

再來看看損失:

說明有進步。那么我們就重復上面的過程,把損失減到最小。每詞重復,我們成為1個epoch。我們先來100個epoch:

再看看效果:

損失很低了。print一下結果:

用PyTorch內置函數實現線性回歸
了解了上述原理后,我們就可以用PyTorch內置的函數,簡化我們的工作量。


接下來我們創建一個TensorDataset和一個DataLoader:

TensorDataset允許我們使用數組索引表示法(上面代碼中的[0:3])訪問訓練數據的一小部分。 它返回一個元組(或對),其中第一個元素包含所選行的輸入變量,第二個元素包含目標。

用for-in循環就可以了

用nn.linear自動初始化
剛開始我們是手動隨機輸入的初識權重。現在我們可以使用nn.linear自動完成初始化工作。

對于我們的線性回歸模型,我們有一個權重矩陣和一個偏差矩陣。
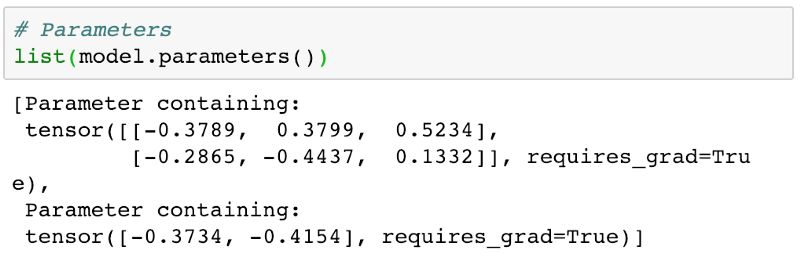
接下來我們重復上面的流程,首先通過損失函數計算出差距,接著不斷的降低損失。

以及用內置損失函數mse_loss:



優化的時候,我們可以使用優化器optim.SGD,不用手動操作模型的權重和偏差。

SGD代表隨機梯度下降。 它被稱為隨機因為樣本是分批選擇的(通常是隨機抽樣)而不是單個組。
訓練模型,思路上面已經講過了,直接看代碼

上面要注意的一些事項:
我們使用前面定義的數據加載器來獲取每次迭代的batch數據
我們不是手動更新參數(權重和偏差),而是使用opt.step來執行更新,而使用opt.zero_grad將梯度重置為零
我們還添加了一個日志語句,用于打印每10個時期最后一批數據的丟失,以跟蹤訓練的進度。 loss.item返回存儲在損失tensor中的實際值
來100個epoch

結果:

對比一下:

Commit并上傳
現在可以將你的代碼上傳到我們的Notebook了。看了這么多代碼估計你可能已經忘記怎么Commit了。

用PyTorch的邏輯回歸實現圖像分類
數據集來自MNIST手寫數字數據庫。它由手寫數字(0到9)的28px乘28px灰度圖像以及每個圖像的標簽組成。

導入torch、torchvision和MNIST

看一下lengh:

這個數據集有60000張圖片,可以用來訓練模型。還有一個10,000個圖像的附加測試集,可以通過將train = False傳遞給MNIST類來創建。

該圖像是PIL.Image.Image類的對象,由28x28圖像和標簽組成。PIL是Python成像庫Pillow。


我們可以使用matplotlib在Jupyter中查看圖像,matplotlib是Python中數據科學的事實繪圖和圖形庫。
先看數據集里的幾個圖片:
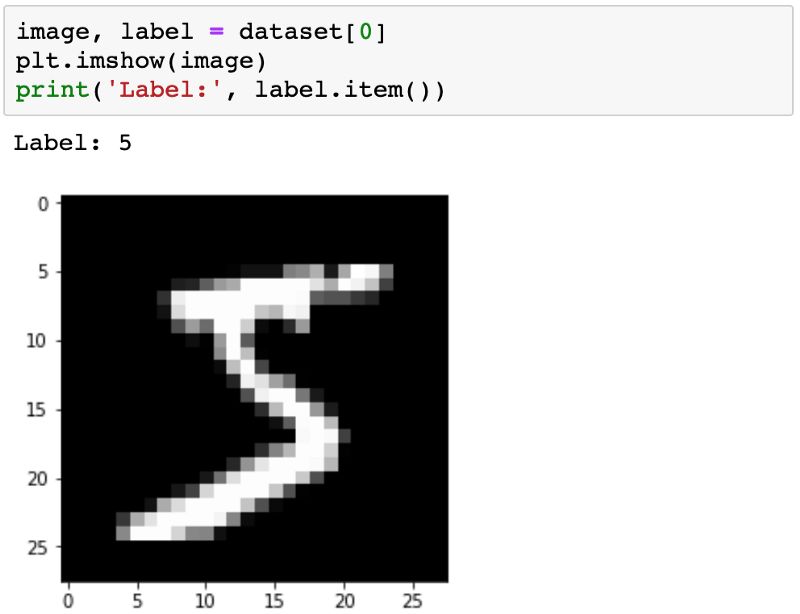

除了導入matplotlib之外,還添加了一個特殊聲明%matplotlib inline,告知Jupyter要在Notebook中繪制圖形。
沒有這個聲明的話,Jupyter將在彈出窗口中顯示圖像。以%開頭的語句稱為IPython magic命令,用于配置Jupyter本身的行為。
PyTorch無法直接處理圖像,需要將圖像轉換成tensor。

PyTorch數據集允許我們指定一個或多個轉換函數,這些函數在加載時應用于圖像。
torchvision.transforms包含許多這樣的預定義函數,我們將使用ToTensor變換將圖像轉換為PyTorchtensor。

現在圖像轉換為1x28x28的tensor。第一個維度用于跟蹤顏色通道。由于MNIST數據集中的圖像是灰度級的,因此只有一個通道。 其他數據集具有彩色圖像,在這種情況下有3個通道:紅色,綠色和藍色(RGB)。
讓我們看一下tensor內的一些樣本值:

0表示黑色,1表示白色,中間的值表示不同的灰度。嗯還可以使用plt.imshow將tensor繪制為圖像。

請注意,我們只需要將28x28矩陣傳遞給plt.imshow,而不需要通道尺寸。
我們還傳遞了一個顏色映射(cmap ='gray'),表示我們想要查看灰度圖像。
訓練和驗證數據集
在構建真實世界的機器學習模型時,將數據集分成3個部分是很常見的:
訓練集:用于訓練模型,即計算損失并使用梯度下降調整模型的權重
驗證集:用于在訓練時評估模型,調整超參數(學習率等)并選擇最佳版本的模型
測試集:用于比較不同的模型或不同類型的建模方法,并報告模型的最終準確性
在MNIST數據集中,有60,000個訓練圖像和10,000個測試圖像。測試集是標準化的,以便不同的研究人員可以針對同一組圖像報告其模型的結果。
由于沒有預定義的驗證集,我們必須手動將60,000個圖像拆分為訓練和驗證數據集
讓我們定義一個函數,隨機選擇驗證集的圖像的給定部分。

split_indices隨機地混洗數組索引0,1,... n-1,并從中為驗證集分離出所需的部分。
在創建驗證集之前對索引進行混洗是很重要的,因為訓練圖像通常由目標標簽排序,即0s的圖像,然后是1s的圖像,接著是2s的圖像,依此類推。
如果我們僅通過選擇最后20%的圖像來選擇20%的驗證集,則驗證集將僅包括8s和9s的圖像,而訓練集將不包含8s和9s的圖像,這樣就不可能訓練一個好的模型。

我們隨機調整了指數,并選擇了一小部分(20%)作為驗證集。
現在可以使用SubsetRandomSampler為每個創建PyTorch數據加載器,SubsetRandomSampler從給定的索引列表中隨機采樣元素,同時創建batch數據。
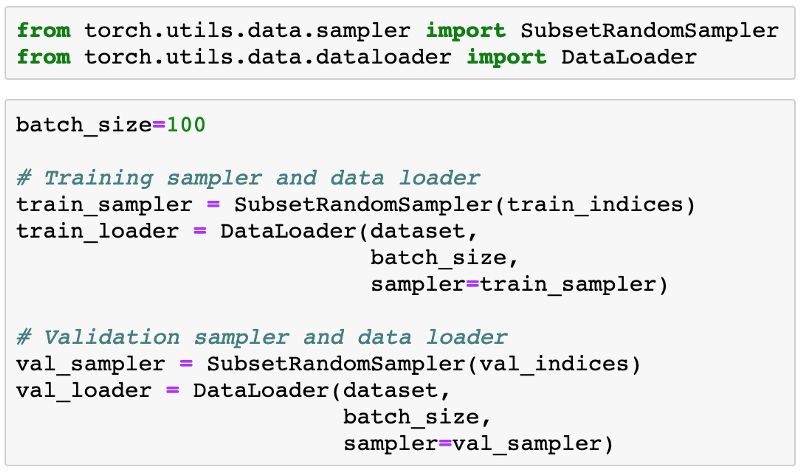
模型
現在我們已經準備好了數據加載器,我們可以定義我們的模型。
邏輯回歸模型幾乎與線性回歸模型相同,即存在權重和偏差矩陣,并且使用簡單矩陣運算(pred = x @ w.t()+ b)獲得輸出
就像我們使用線性回歸一樣,我們可以使用nn.Linear來創建模型,而不是手動定義和初始化矩陣
由于nn.Linear期望每個訓練示例都是一個tensor,因此每個1x28x28圖像tensor需要在傳遞到模型之前被展平為大小為784(28 * 28)的tensor
每個圖像的輸出是大小為10的tensor,tensor的每個元素表示特定目標標記(即0到9)的概率。 圖像的預測標簽只是具有最高概率的標簽

我們看看權重和偏差


雖然這里我們的額參數量編程了7850個,但總的思路是類似的。我們從的數據集中,取得第一個batch,包含100張圖片,傳遞給模型。

直接輸出的話報錯。因為我們的輸入數據的形狀不正確。我們的圖像形狀為1x28x28,但我們需要它們是784的矢量。
即我們需要將它們“展評”。我們將使用一個tensor的.reshape方法,這將允許我們有效地“查看”每個圖像作為平面向量,而無需真正更改基礎數據。
要在我們的模型中包含此附加功能,我們需要通過從PyTorch擴展nn.Module類來定義自定義模型。

在__init__構造函數方法中,我們使用nn.Linear實例化權重和偏差。
在我們將一批輸入傳遞給模型時調用的forward方法中,我們將輸入tensor展平,然后將其傳遞給self.linear。
xb.reshape(-1,28 * 28)向PyTorch指明,我們想要具有兩個維度的xbtensor的視圖,其中沿第二維度的長度是28 * 28(即784)。
.reshape的一個參數可以設置為-1(在這種情況下是第一個維度),讓PyTorch根據原始tensor的形狀自動計算出來。
請注意,模型不再具有.weight和.bias屬性(因為它們現在位于.linear屬性中),但它確實有一個.parameters方法,該方法返回包含權重和偏差的列表,并且可以使用PyTorch優化器。

我們的新自定義模型可以像以前一樣使用。 讓我們看看它是否有效。

對于100個輸入圖像中的每一個,我們得到10個輸出,每個類別一個。 如前所述,我們希望這些輸出表示概率,但是為此,每個輸出行的元素必須介于0到1之間并且加起來為1,這顯然不是這里的情況。
要將輸出行轉換為概率,我們使用softmax函數,它具有以下公式:

首先,我們將輸出行中的每個元素yi替換為e ^ yi,這使得所有元素都為正,然后我們將每個元素除以所有元素的總和,以確保它們加起來為1。
雖然很容易實現softmax函數,我們將使用PyTorch中提供的實現,因為它適用于多維tensor(在我們的例子中是輸出行列表)。

softmax函數包含在torch.nn.functional包中,并要求我們指定必須應用softmax的維度。

最后,我們可以通過簡單地選擇每個輸出行中具有最高概率的元素的索引來確定每個圖像的預測標簽。
這是使用torch.max完成的,它返回最大元素和沿tensor的特定維度的最大元素的索引。

上面打印的數字是第一批訓練圖像的預測標簽。 我們將它們與實際標簽進行比較。

顯然,預測標簽和實際標簽完全不同。這是因為我們已經開始使用隨機初始化的權重和偏差。
我們需要訓練模型,即使用梯度下降調整權重以做出更好的預測。
評估度量和損失函數
與線性回歸一樣,我們需要一種方法來評估模型的執行情況。一種自然的方法是找到正確預測的標簽百分比,即預測的準確性。

==運算符執行具有相同形狀的兩個tensor的逐元素比較,并返回相同形狀的tensor,對于不相等的元素包含0,對于相等的元素包含1。
將結果傳遞給torch.sum會返回正確預測的標簽數。最后,我們除以圖像總數來獲得準確性。
讓我們計算第一批數據的當前模型的準確性。顯然,我們預計它會非常糟糕。

雖然精度是我們(人類)評估模型的好方法,但它不能用作使用梯度下降優化模型的損失函數,原因如下:
這不是一個可區分的功能。torch.max和==都是非連續和非可微操作,因此我們無法使用精度來計算重量和偏差的梯度
它沒有考慮模型預測的實際概率,因此無法為漸進式改進提供足夠的反饋
由于這些原因,準確性是分類的一個很好的評估指標,但不是一個好的損失函數。 分類問題常用的損失函數是交叉熵,其具有以下公式:
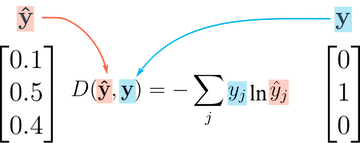
雖然它看起來很復雜,但實際上非常簡單:
對于每個輸出行,選擇正確標簽的預測概率。例如。如果圖像的預測概率是[0.1,0.3,0.2,...]并且正確的標簽是1,我們選擇相應的元素0.3并忽略其余的
然后,取所選概率的對數。如果概率很高,即接近1,則其對數是非常小的負值,接近于0。如果概率低(接近0),則對數是非常大的負值。我們還將結果乘以-1,結果是預測不良的損失的大正值 最后,獲取所有輸出行的交叉熵的平均值,以獲得一批數據的總體損失
與準確度不同,交叉熵是一種連續且可微分的函數,它還為模型中的漸進改進提供了良好的反饋(正確標簽導致較低損失的概率略高)。這使它成為損失函數的一個很好的選擇。
PyTorch提供了一種有效且張量友好的交叉熵實現,作為torch.nn.functionalpackage的一部分。
此外,它還在內部執行softmax,因此我們可以直接傳遞模型的輸出而不將它們轉換為概率。

由于交叉熵是在所有訓練樣本上平均的正確標簽的預測概率的負對數,因此一種解釋結果數的方法,例如,2.23是e ^ -2.23,平均值約為0.1,作為正確標簽的預測概率。降低損失,改善模型。
優化
我們將使用optim.SGD優化器在訓練期間更新權重和偏差,但學習率更高,為1e-3。

batch大小,學習率等參數需要在訓練機器學習模型時提前選取,并稱為超參數。
選擇正確的超參數對于在合理的時間內訓練準確的模型至關重要,并且是研究和實驗的活躍領域。隨意嘗試不同的學習率,看看它如何影響訓練過程。
訓練模型
現在我們已經定義了數據加載器,模型,損失函數和優化器,我們已準備好訓練模型。
訓練過程幾乎與線性回歸相同。但是,我們將增加我們之前定義的擬合函數,以使用每個epoch末尾的驗證集來評估模型的準確性和損失。
我們首先定義一個函數loss_batch:
計算一批數據的損失
如果提供了優化程序,則可以選擇執行梯度下降更新步驟
可選地使用預測和實際目標來計算度量(例如,準確度)

優化器是一個可選參數,以確保我們可以重用loss_batch來計算驗證集上的損失。
我們還將batch處理的長度作為結果的一部分返回,因為它在組合整個數據集的損失/度量時非常有用。
接下來,我們定義一個函數evaluate,它計算驗證集的總體損失。

如果不能立即清楚此函數的作用,請嘗試在單獨的單元格中執行每個語句,然后查看結果。
我們還需要重新定義精確度以直接操作整批輸出,以便我們可以將其用作擬合度量。

請注意,我們不需要將softmax應用于輸出,因為它不會更改結果的相對順序。
這是因為e ^ x是增加函數,即如果y1> y2,則e ^ y1> e ^ y2,并且在對值求平均值以獲得softmax之后也是如此。
讓我們看看模型如何使用初始權重和偏差集在驗證集上執行。

初始準確度低于10%,這是人們對隨機初始化模型的預期(因為它有十分之一的機會通過隨機猜測獲得標簽)。
另請注意,我們使用.format方法和消息字符串僅打印小數點后的前四位數。
我們現在可以使用loss_batch和evaluate輕松定義擬合函數。

我們現在準備訓練模型。 讓我們訓練5個epoch并觀察結果。

不錯哦!來更多點eploch

線圖更直觀的顯示一下效果

從上面的圖片中可以清楚地看出,即使經過很長時間的訓練,該模型也可能不會超過90%的準確度閾值。
一個可能的原因是學習率可能太高。模型的參數可能會圍繞具有最低損耗的最佳參數集“彈跳”。
您可以嘗試降低學習速度和訓練幾個epoch,看看它是否有幫助。
更可能的原因是該模型不夠強大。如果你還記得我們的初始假設,我們假設輸出(在這種情況下是類概率)是輸入(像素強度)的線性函數,通過對權重矩陣執行矩陣乘法并添加偏差來獲得。
這是一個相當弱的假設,因為圖像中的像素強度和它所代表的數字之間可能實際上不存在線性關系。
雖然它對于像MNIST這樣的簡單數據集(使我們達到85%的準確度)工作得相當好,但我們需要更復雜的模型來捕捉圖像像素和標簽之間的非線性關系,以便識別日常物品,動物等復雜任務。
使用單個圖像進行測試
雖然到目前為止我們一直在跟蹤模型的整體精度,但在一些樣本圖像上查看模型的結果也是一個好主意。
讓我們用10000個圖像的預定義測試數據集中的一些圖像測試我們的模型。 我們首先使用ToTensor變換重新創建測試數據集。

數據集中單個圖像的樣本:

讓我們定義一個輔助函數predict_image,它返回單個圖像張量的預測標簽。

img.unsqueeze只是在1x28x28張量的開始處添加另一個維度,使其成為1x1x28x28張量,模型將其視為包含單個圖像的批處理。




通過收集更多的訓練數據,增加/減少模型的復雜性以及更改超參數,確定我們的模型表現不佳的位置可以幫助我們改進模型。
最后,讓我們看看測試集上模型的整體損失和準確性。

我們希望這與驗證集上的準確度/損失相似。如果沒有,我們可能需要一個更好的驗證集,它具有與測試集類似的數據和分布(通常來自現實世界數據)。
保存并加載模型
由于我們已經長時間訓練模型并獲得了合理的精度,因此將權重和偏置矩陣保存到磁盤是個好主意,這樣我們可以在以后重用模型并避免從頭開始重新訓練。以下是保存模型的方法。

.state_dict方法返回一個OrderedDict,其中包含映射到模型右側屬性的所有權重和偏置矩陣。

要加載模型權重,我們可以實例化MnistModel類的新對象,并使用.load_state_dict方法。

正如完整性檢查一樣,讓我們驗證此模型在測試集上具有與以前相同的損失和準確性。
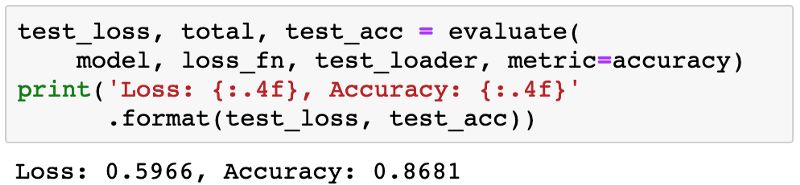
好了。大功告成了。又到了我們的commit環節。以防你已經忘記了怎么操作:

-
函數
+關注
關注
3文章
4308瀏覽量
62434 -
機器學習
+關注
關注
66文章
8381瀏覽量
132426 -
pytorch
+關注
關注
2文章
803瀏覽量
13150
原文標題:從零開始學PyTorch:一文學會線性回歸、邏輯回歸及圖像分類
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
將pytorch模型轉化為onxx模型的步驟有哪些
怎樣使用PyTorch Hub去加載YOLOv5模型
通過Cortex來非常方便的部署PyTorch模型
如何往星光2板子里裝pytorch?
Pytorch入門教程與范例
一篇非常新的介紹PyTorch內部機制的文章

基于PyTorch的深度學習入門教程之PyTorch的安裝和配置
一份簡便的PyTorch教程,從不用自己配置環境開始。





 工商網監
工商網監
評論