 曠視官方首次解讀2018 COCO全景分割冠軍算法
曠視官方首次解讀2018 COCO全景分割冠軍算法
前言
在計算機視覺中,圖像語義分割(Semantic Segmentation)的任務是預測每個像素點的語義類別;實例分割(Instance Segmentation)的任務是預測每個實例物體包含的像素區域。全景分割 (Panoptic Segmentation) [1] 最先由 FAIR 與德國海德堡大學聯合提出,其任務是為圖像中每個像素點賦予類別 Label 和實例 ID ,生成全局的、統一的分割圖像。
ECCV 2018 最受矚目的 COCO + Mapillary 聯合挑戰賽也首次加入全景分割任務,是全景分割領域中最權威與具有挑戰性的國際比賽,代表著當前計算機視覺識別技術最前沿。在全景分割比賽項目中,曠視研究院 Detection 組參與了COCO 比賽項目與 Mapillary 比賽項目,并以大幅領先第二名的成績實力奪魁,在全景分割指標 PQ 上取得了0.532的成績,超越了 human consistency ,另外,我們的工作《An End-to-End Network for Panoptic Segmentation》也發表于 CVPR 2019 上。
接下來我們將全面解讀全景分割任務,下面這張思維導圖有助于大家整體把握全景分割任務特性:
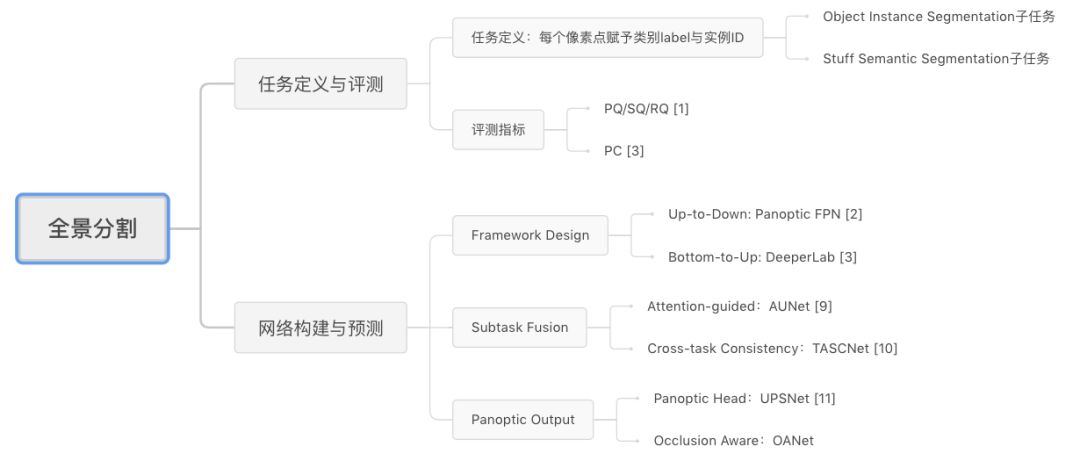
全景分割解讀思維導圖
首先,我們將分析全景分割任務的評價指標及基本特點,并介紹目前最新的研究進展;然后介紹我們發表于 CVPR 2019 的工作 Occlusion Aware Network (OANet),以及曠視研究院 Detection 組參與的 2018 COCO Panoptic Segmentation 比賽工作介紹;最后對全景分割當前研究進行總結與分析。
任務與前沿進展解讀
全景分割任務,從任務目標上可以分為 object instance segmentation 子任務與 stuff segmentation 子任務。全景分割方法通常包含三個獨立的部分:object instance segmentation 部分,stuff segmentation 部分,兩子分支結果融合部分;通常object instance segmentation 網絡和 stuff segmentation 網絡相互獨立,網絡之間不會共享參數或者圖像特征,這種方式不僅會導致計算開銷較大,也迫使算法需要使用獨立的后處理程序融合兩支預測結果,并導致全景分割無法應用在工業中。
因此,可以從以下幾個角度分析與優化全景分割算法:
(1)網絡框架搭建;
(2)子任務融合;
(3)全景輸出預測;
這三個問題分別對應的是全景分割算法中的三個重要環節,下面我們將分別分析這些問題存在的難點,以及近期相關工作提出的改進方法與解決方案。
全景分割評價指標
FAIR研究團隊 [1] 為全景分割定了新的評價標準 PQ (panoptic segmentation) 、SQ ( segmentation quality)、RQ (recognition quality) ,計算公式如下:
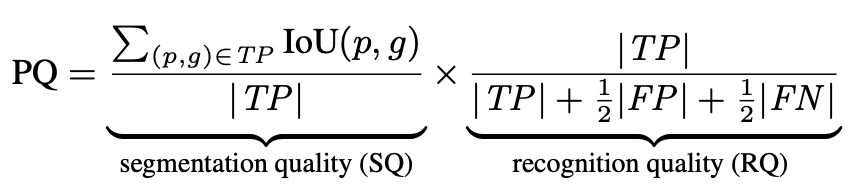
PQ 評價指標計算公式
其中,RQ是檢測中應用廣泛的 F1 score,用來計算全景分割中每個實例物體識別的準確性,SQ 表示匹配后的預測 segment與標注 segment 的 mIOU,如下圖所示,只有當預測 segment 與標注 segment 的 IOU 嚴格大于 0.5 時,認為兩個 segment 是匹配的。
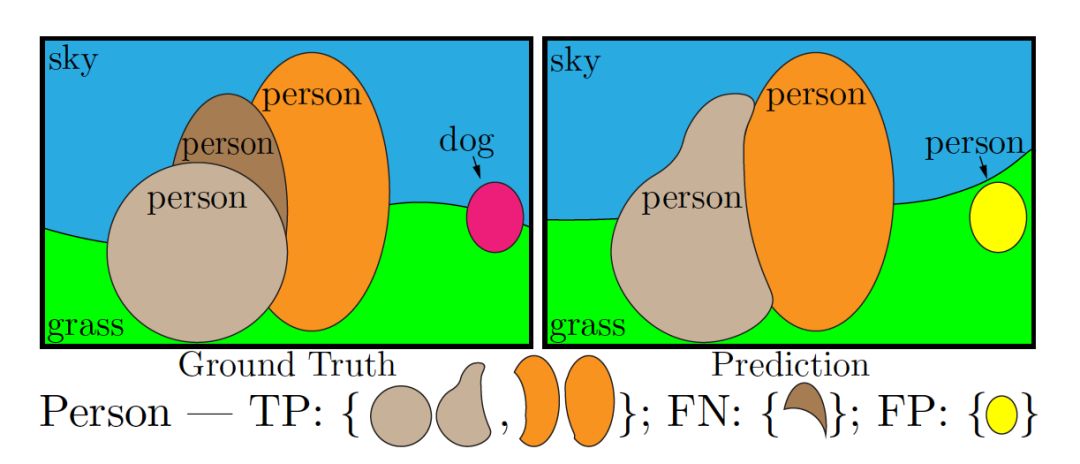
全景分割預測結果與真實標注匹配圖解 [1]
從上面的公式能夠看到,在預測與標注匹配后的分割質量 SQ 計算時,評價指標PQ只關注每個實例的分割質量,而不考慮不同實例的大小,即大物體與小物體的分割結果對最終的PQ結果影響相同。Yang et al. [6] 注意到在一些應用場景中更關注大物體的分割結果,如肖像分割中大圖的人像分割、自動駕駛中近距離的物體等,提出了 PC (Parsing Covering) 評價指標,計算公式如下:
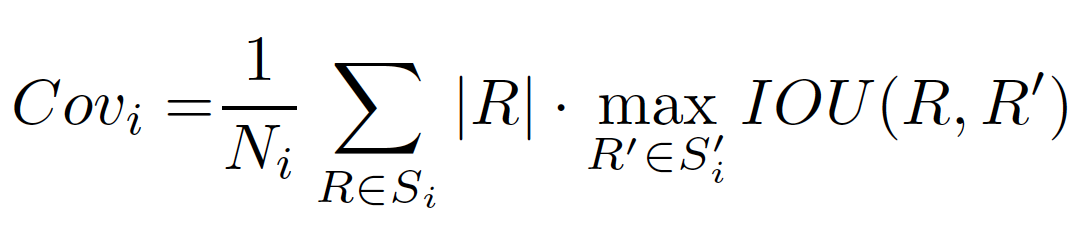
PC 評價指標計算公式
其中,

分別表示對應類別的預測 segments 與真實segments,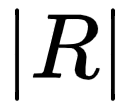 表示對應類別的實例在真實標注中像素點數量,
表示對應類別的實例在真實標注中像素點數量,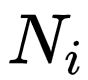 表示類別為i的真實標注像素點總和。通過對大的實例物體賦予更大的權重,使評價指標能夠更明顯地反映大物體的分割指標。
表示類別為i的真實標注像素點總和。通過對大的實例物體賦予更大的權重,使評價指標能夠更明顯地反映大物體的分割指標。
網絡框架搭建
由于 object instance segmentation 子任務與 stuff segmentation 子任務分別屬于兩個不同的視覺預測任務,其輸入數據及數據增強方式、訓練優化策略與方法、網絡結構與方法具有較大的不同,如何將兩個子任務融合并統一網絡結構、訓練策略,是解決該問題的關鍵。
FAIR 研究團隊提出了一種簡潔有效的網絡結構 Panoptic FPN [2],在網絡框架層面將語義分割的全卷積網絡(FCN)[3] 和實例分割網絡 Mask RCNN [4] 統一起來,設計了單一網絡同時預測兩個子任務,網絡結構如下圖所示。
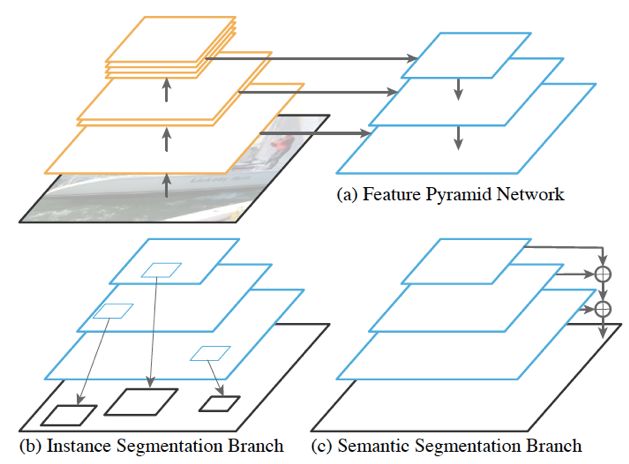
Panoptic FPN網絡框架圖
該網絡結構能夠有效預測 object instance segmentation 子任務與 stuff segmentation 子任務。在 Mask RCNN 網絡與 FPN [5] 的基礎上,作者設計了簡單而有效的 stuff segmentation 子分支:在 FPN 得到的不同層級的特征圖基礎上,使用不同的網絡參數得到相同大小的特征圖,并對特征圖進行加法合并,最后使用雙線性插值上采樣至原圖大小,并進行stuff 類別預測。
MIT與谷歌等聯合提出DeeperLab [6] ,使用 bottom-to-up 的方法,同時實現 object instance segmentation 子任務與 stuff segmentation 子任務,其網絡結構如下圖所示:
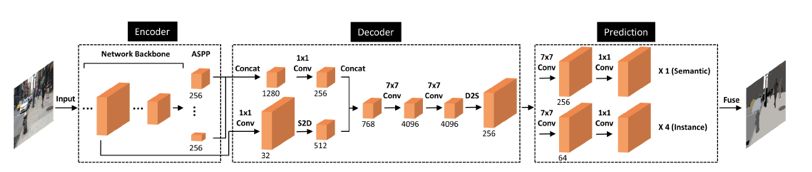
DeeperLab 網絡結構圖
該網絡包含了 encoder、decoder 與 prediction 三個環節,其中,encoder 和 decoder 部分對兩個子任務均是共享的,為了增強 encoder 階段的特征,在 encoder 的末尾使用了ASPP (Atrous Spatial Pyramid Pooling) 模塊 [7];而在decoder階段,首先使用 1×1 卷積對低層特征圖與 encoder 輸出的特征圖進行降維,并使用內存消耗較少的space-to-depth [8, 9] 操作替代上采樣操作對低層特征圖進行處理,從而將低層特征圖(大小為原圖1/4)與 encoder 輸出的特征圖(大小為原圖 1/16 )拼接起來;最后,使用兩層 7×7 的大卷積核增加感受野,然后通過 depth-to-space 操作降低特征維度。
為了得到目標實例預測,作者采用類似 [10, 11, 12] 的使用基于關鍵點表示的方法,如下圖所示,在 object instance segmentation 子分支頭部,分別預測了 keypoint heatmap(圖a)、long-range offset map(圖b)、short-range offset map(圖c)、middle-range offset map(圖d)四種輸出,得到像素點與每個實例關鍵點之間的關系,并依此融合形成類別不可知的不同實例,最后得到全景分割的結果。

object instance segmentation 子分支頭部預測目標
子任務融合
雖然通過特征共享機制與網絡結構設計,能夠將 object instance segmentation 子任務與 stuff segmentation 子任務統一起來,但是這兩個子分支之間的相互聯系與影響并沒有得到充分的探究,例如:兩個子分支的任務是否能夠達到相互增益或者單向增益的效果?或者如何設計將兩個子分支的中間輸出或者預測關聯起來?這一部分問題我們可以統一將它稱作兩個子任務的相互提升與促進。
中科院自動化研究所提出了AUNet [13],文中設計了 PAM (Proposal Attention Module)與 MAM(Mask Attention Module)模塊,分別基于RPN階段的特征圖與 object instance segmentation 輸出的前景分割區域,為 stuff segmentation 提供了物體層級注意力與像素層級注意力,其網絡結構圖如下圖所示:
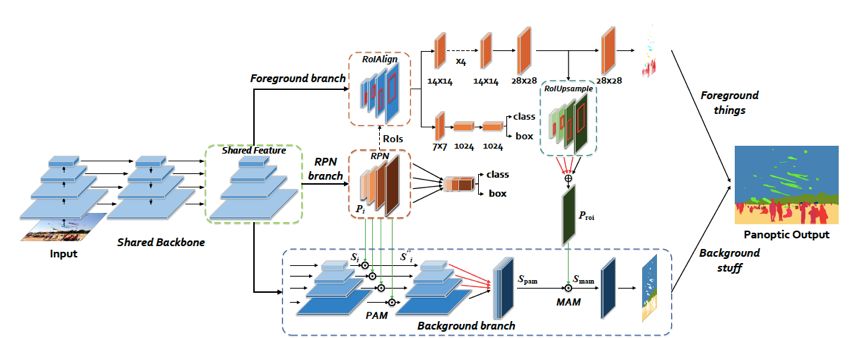
AUNet 網絡結構圖
為了使 object instance segmentation 的預測輸出與 stuff segmentation 預測輸出保持一致性,豐田研究院設計了 TASCNet [14],其網絡結構如下圖所示:
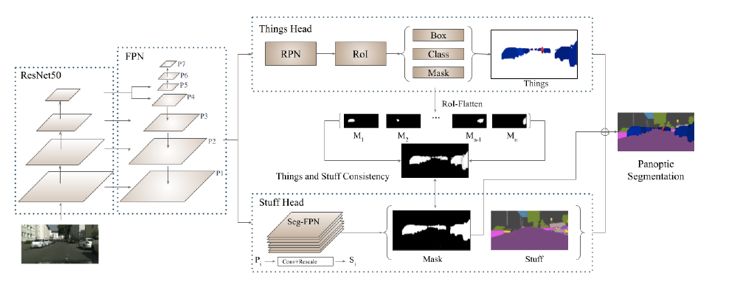
TASCNet網絡結構圖
網絡首先將 object instance segmentation 子分支得到的實例前景掩膜區域,映射到原圖大小的特征圖中,得到全圖尺寸下的實例前景掩膜區域,并與 stuff segmentation 預測的實例前景掩膜進行對比,使用L2損失函數最小化兩個掩膜的殘差。
全景輸出預測
Object instance segmentation 子分支與 stuff segmentation 子分支的預測結果在融合的過程中,一般通過啟發式算法(heuristic algorithm)處理相沖突的像素點,例如簡單地以 object instance segmentation 子分支的預測結果為準,并以 object instance segmentation 子分支的檢測框得分作為不同實例的合并依據。
這種方式依據簡單的先驗邏輯判斷,并不能較好地解決全景分割復雜的合并情況,因此,如何設計有效的模塊解決 object instance segmentation 子分支與 stuff segmentation 子分支到全景分割輸出的融合過程,也是全景分割任務中的重要問題。
Uber與港中文聯合提出了 UPSNet [15] ,其網絡結構圖如下圖所示:
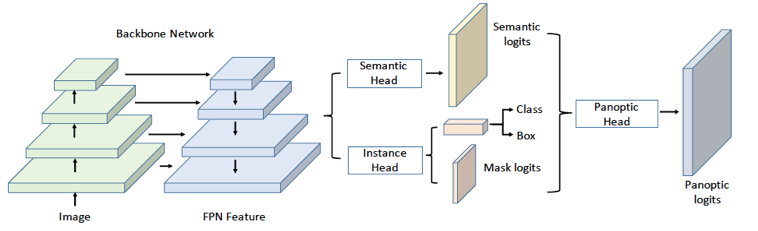
UPSNet網絡結構圖
將 object instance segmentation 子分支與 stuff segmentation 子分支的輸出通過映射變換,可得到全景頭部輸出的特征張量,該張量大小為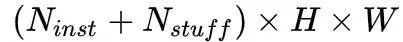
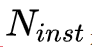 為動態變量,表示一張圖像中實例的數量,
為動態變量,表示一張圖像中實例的數量, 表示 stuff 類別個數,對于每張圖像其數值是相同的,下文使用
表示 stuff 類別個數,對于每張圖像其數值是相同的,下文使用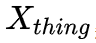 和
和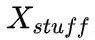 分別表示這兩種特征張量。此外,網絡對像素進行了未知類別的預測(Unknown Prediction),從而使得網絡能夠將部分像素點判斷為未知類別并在測試的時候進行忽略,避免做出錯誤的類別導致 PQ 指標下降。
分別表示這兩種特征張量。此外,網絡對像素進行了未知類別的預測(Unknown Prediction),從而使得網絡能夠將部分像素點判斷為未知類別并在測試的時候進行忽略,避免做出錯誤的類別導致 PQ 指標下降。
在得到 object instance segmentation 子分支與 stuff segmentation 子分支的輸出后,經過如下圖所示的變換,映射成
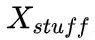

panoptic segmentation head示意圖
 可以直接從不規則類別分割的輸出中提取,
可以直接從不規則類別分割的輸出中提取,
 個實例的掩膜區域可由
個實例的掩膜區域可由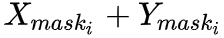 獲得,其中
獲得,其中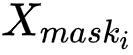 表示第
表示第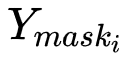 個實例對應的真實標注框與標注類別在 stuff segmentation 子分支輸出截取的掩膜區域,
個實例對應的真實標注框與標注類別在 stuff segmentation 子分支輸出截取的掩膜區域,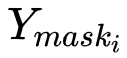 表示第?
表示第? 個實例對應的 instance segmentation 子分支得到的掩膜區域映射到原圖的掩膜區域,最后使用標準的逐像素點的交叉熵損失函數對全景頭部輸出的張量進行監督訓練。
個實例對應的 instance segmentation 子分支得到的掩膜區域映射到原圖的掩膜區域,最后使用標準的逐像素點的交叉熵損失函數對全景頭部輸出的張量進行監督訓練。
Occlusion Aware Network專欄解讀
論文Arxiv鏈接:
https://arxiv.org/abs/1903.05027
Motivation
在全景分割相關實驗中,我們發現,依據現有的啟發式算法進行 object instance segmentation 子分支與 stuff segmentation 子分支的預測合并,會出現不同實例之間的遮擋現象。為了解決不同實例之間的遮擋問題,我們提出了 Occlusion Aware Network (OANet),并設計了空間排序模塊(Spatial Ranking Module),該模塊能夠通過網絡學習得到新的排序分數,并為全景分割的實例分割提供排序依據。
網絡結構設計
我們提出的端到端的全景分割網絡結構如下圖所示,該網絡融合 object instance segmentation 子分支與 stuff segmentation 子分支的基礎網絡特征,在一個網絡中同時實現全景分割的訓練與預測。在訓練過程中,對于 stuff segmentation 我們同時進行了 object 類別與 stuff 類別的監督訓練,實驗表明這種設計有助于 stuff 的預測。

OANet網絡結構圖
采用一種類似語義分割的方法,我們提出一個簡單但非常有效的算法,稱作Spatial Ranking Module,能夠較好地處理遮擋問題,其網絡結構如下所示:
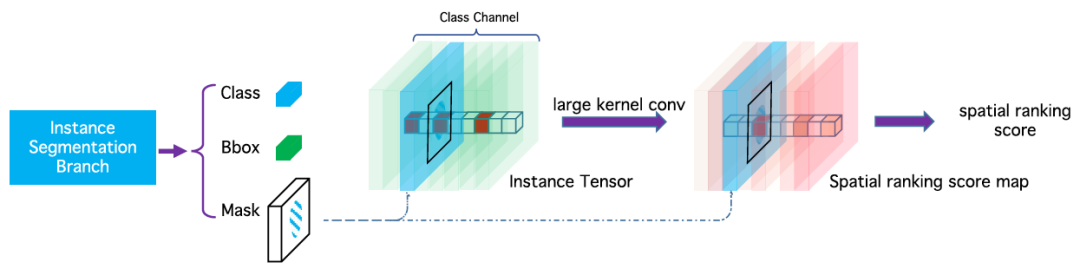
Spatial Ranking Module網絡結構圖
我們首先將輸入的實例分割結果映射到原圖大小的張量之中,該張量的維度是實例物體類別的數量,不同類別的實例分割掩膜會映射到對應的通道上。張量中所有像素點位置的初始化數值為零,實例分割掩膜映射到的位置其值設為1;在得到該張量后,使用大卷積核 [16] 進行特征提取,得到空間排序得分圖;最后,我們計算出每個實例對象的空間排序得分,如下所示:
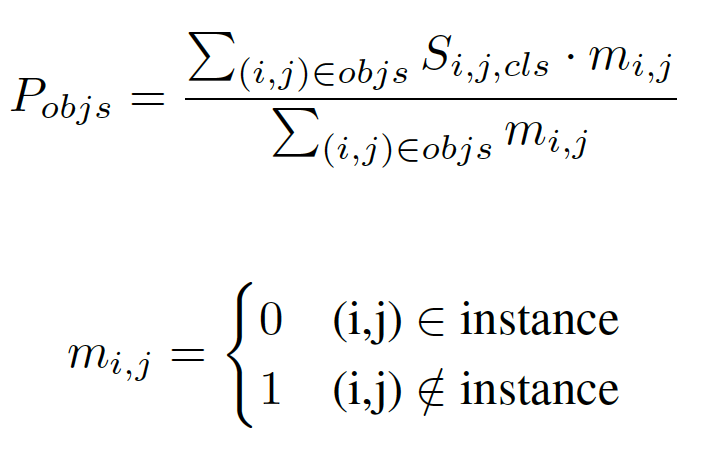
這里,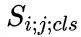 表示類別為
表示類別為 的、像素點?
的、像素點?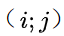 中的得分值,需要注意的是
中的得分值,需要注意的是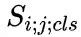 已被歸一化為概率,
已被歸一化為概率, 是掩膜像素點指示符,表示像素點
是掩膜像素點指示符,表示像素點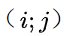 是否屬于實例,每個實例的空間排序得分由預測的掩碼區域所有像素點的排序分數平均得到,
是否屬于實例,每個實例的空間排序得分由預測的掩碼區域所有像素點的排序分數平均得到,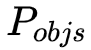 表示最終得到的每個實例的排序得分,并將此得分用于全景輸出。
表示最終得到的每個實例的排序得分,并將此得分用于全景輸出。
如下圖所示,若使用目前通用的啟發式融合算法,即僅基于實例分割的檢測框的置信度作為遮擋處理依據,如圖所示,行人檢測框的置信度要明顯高于領帶檢測框的置信度,當兩個實例發生重疊時,領帶的實例會被行人實例遮擋;當加入空間排序得分模塊后,我們通過該模塊可以預測得到兩個實例的空間排序分數,依據空間排序分數得到的排序會更可靠,PQ 會有更大改善。

空間排序模塊流程示意圖
實驗分析
我們對 stuff segmentation 分支的監督信號進行了剝離實驗,如下表所示,實驗表明,同時進行 object 類別與 stuff 類別的監督訓練,能夠為 stuff segmentation 提供更多的上下文信息,并改進預測結果。
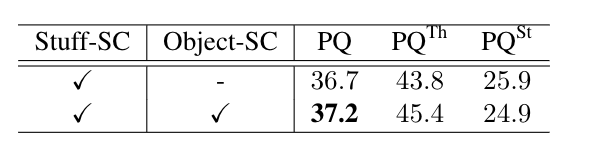
為了探究object instance segmentation 子分支與 stuff segmentation 子分支的共享特征方式,我們設計了不同的共享結構并進行實驗,如下表所示,實驗表明,共享基礎模型特征與FPN 結構的連接處特征,能夠提高全景分割指標 PQ 。
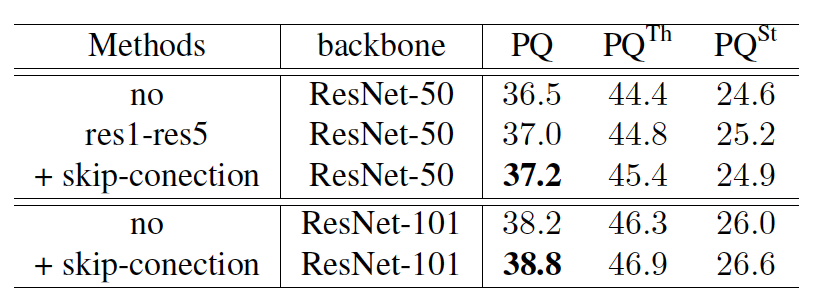
為了探究我們提出的 spatial ranking module 算法的有效性,我們在不同基礎模型下進行了實驗,如下表所示,其中,w/ spatial ranking module 表示使用我們提出的空間排序模塊得到的結果,從實驗結果中可以看到,空間排序模塊能夠在不同的基礎模型下大幅提高全景分割的評測結果。

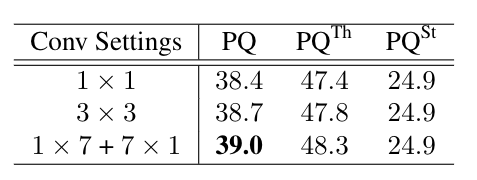
為了測試不同卷積設置對學習處理遮擋的影響,進行了如下實驗,結果表明,提高卷積的感受也可以幫助網絡學習獲得更多的上下文特征,并取得更好的結果。
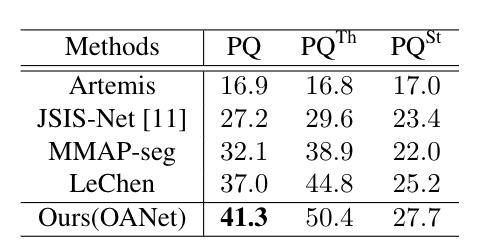
下表是本文提出的算法與現有公開指標的比較,從結果中可以看到,本文提出的算法能夠取得最優的結果。
2018 COCO 全景分割比賽冠軍解讀
曠視研究院 Detection 組參與的全景分割 COCO 比賽項目與 Mapillary 比賽項目中,以大幅領先第二名的成績實力奪魁,在全景分割指標 PQ 上取得了 0.532 的成績,超越了 human consistency 。

COCO 2018 Panoptic Leaderboard
全景分割預測可視化圖例
在比賽中,我們使用了如下圖所示的流程,首先分別預測 stuff semantic segmentation 與 object instance segmentation,然后通過后處理的操作得到全景分割的結果。
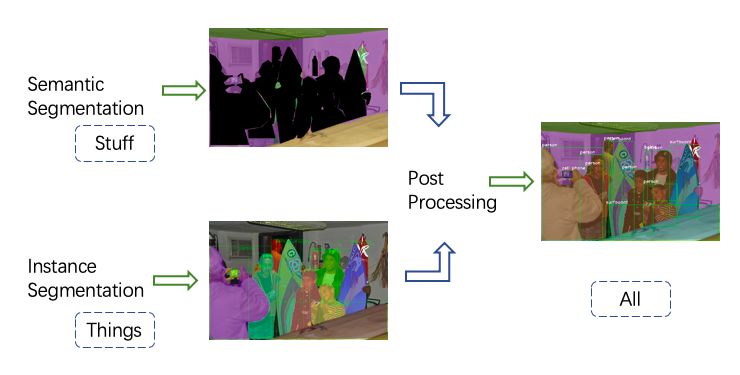
全景分割算法流程圖
在 stuff semantic segmentation 預測階段,首先我們對網絡結構進行了部分調整以得到更好的分割效果。首先,網絡最終的下采樣倍數設為 8 ,保證輸出結果的分辨率;然后,由于網絡的 encoder 不會擴大網絡的感受野, 因此我們在標準 ResNet 之后使用了若干層 Res-Block。
另外,實驗發現 stuff 類別和 object 類別之間的上下文對于 stuff 分割較為重要,因此我們在網絡預測中融入了上下文信息,并通過多階段、多種監督的方式實現,網絡結構如下圖所示:
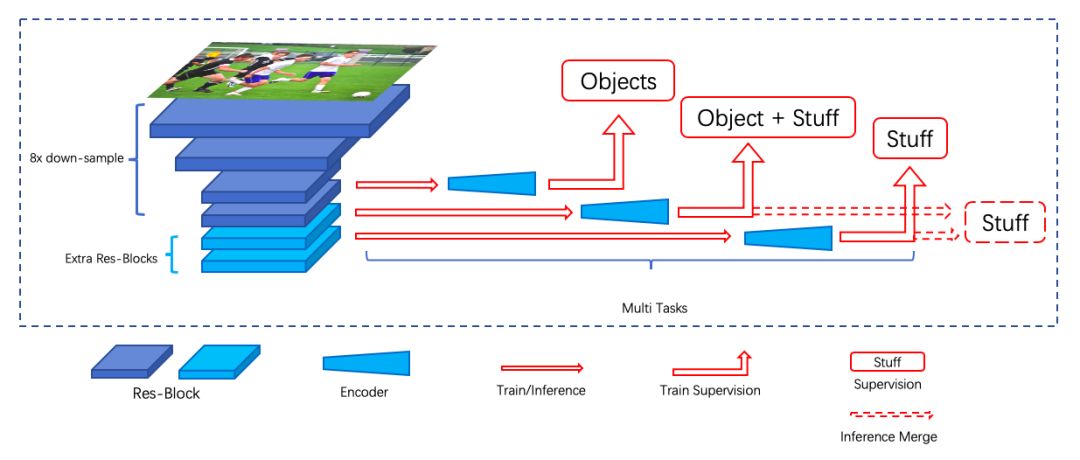
stuff semantic segmentation 結構圖
對于 object instance segmentation,我們使用了與 Mask RCNN 相同的網絡結構及訓練配置。最后,通過使用更大的網絡基礎模型,multi scale + flip 的測試方法,以及多模型的ensemble操作,我們取得了最終的預測結果,如下圖所示:

Panoptic Results on COCO test-dev Dataset
總結與分析
從上文的文獻分析來看,全景分割任務的不同重要問題均得到了廣泛探究,但是全景分割任務依然是有挑戰性、前沿的場景理解問題,目前仍存在一些問題需要進行探究:
第一,由于全景分割可通過分別預測實例分割子任務與不規則類別分割子任務、兩個子任務預測結果融合得到,整個算法流程中包含較多的細節與后處理操作,包括segments的過濾、啟發式融合算法、ignore 像素點的判斷等。這些細節對全景分割指標有較大的影響,在一定程度上也阻礙了不同算法的對比與評測;
第二,全景分割評測指標雖然能夠較好地評測全景分割中實例物體檢測準確度,以及實例物體與不規則類別的分割準確度,但是該評測指標更側重每個實例,并沒有關注每個實例之間的區別。文獻 [6] 提出了對大物體有更好的評測指標PC (Parsing Covering),使得大物體的分割效果對最終的評測指標影響更大,在一些關注大物體的任務如肖像分割、自動駕駛中更為有效;
第三,全景分割中子任務的融合問題,目前研究依然較多地將全景分割看做是 object instance segmentation 與 stuff segmentation 兩個子任務的合集,如何從全局、統一的分割問題出發,針對性設計符合全景分割的統一網絡,具有重要的意義。
-
網絡結構
+關注
關注
0文章
48瀏覽量
11068 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927 -
識別技術
+關注
關注
0文章
202瀏覽量
19684
原文標題:漫談全景分割
文章出處:【微信號:megvii,微信公眾號:曠視MEGVII】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
曠視科技face++股東名單_曠視科技face++歷史幾輪融資情況
曠視科技怎么樣?曠視科技最新估值多少
曠視河圖重磅亮相CeMAT ASIA 2019 為智慧供應鏈打造生態底座
曠視斬獲6冠 彰顯深度學習算法引擎優勢
曠視科技正在大舉推進香港IPO計劃
IPO申請獲批 AI實力雄厚的曠視科技未來可期
曠視深度學習框架曠視天元宣布開源
曠視科技宣布開源新一代AI生產力平臺Brain++的核心深度學習框架曠視天元
曠視開源深度學習框架 覆蓋AI全流程研發
曠視的重構城市物聯網生態方案
曠視科技科創板開啟上市輔導 曠視科技股票要來了

西安交通大學與曠視科技獲批共建人機混合增強智能全國重點實驗室
曠視 FaceID 金融級 KYC驗證服務守護業務安全





 工商網監
工商網監
評論