 微軟亞研院提出用于語義分割的結構化知識蒸餾
微軟亞研院提出用于語義分割的結構化知識蒸餾
今天跟大家分享一篇關于語義分割的論文,剛剛上傳到arXiv的CVPR 2019接收論文《Structured Knowledge Distillation for Semantic Segmentation》,通訊作者單位為微軟亞洲研究院。
作者信息:

作者分別來自澳大利亞阿德萊德大學、微軟亞洲研究院、北航、Keep公司、三星中國研究院,該文為第一作者Yifan Liu在微軟亞洲研究院實習期間的工作。
該文研究了在語義分割模型的知識蒸餾中引入結構化信息的損失函數,在不改變模型計算量的情況下,使用該方法在Cityscapes數據集上mIoU精度取得了最高達15.17%的提升。
什么是知識蒸餾?
顧名思義,知識蒸餾是把知識濃縮到“小”網絡模型中。一般情況下,在相同的數據上訓練,模型參數量較大、計算量大的模型往往精度比較高,而用精度高、模型復雜度高的模型即Teacher網絡的輸出訓練Student網絡,以期達到使計算量小參數少的小網絡精度提升的方法,就是知識蒸餾。
知識蒸餾的好處是顯而易見的,使用知識蒸餾后的Student網絡能夠達到較高的精度,而且更有利于實際應用部署,尤其是在移動設備中。
下面兩幅圖中,作者展示了使用該文提出的結構化知識蒸餾的語義分割模型在計算量和參數量不變的情況下,精度獲得了大幅提升。
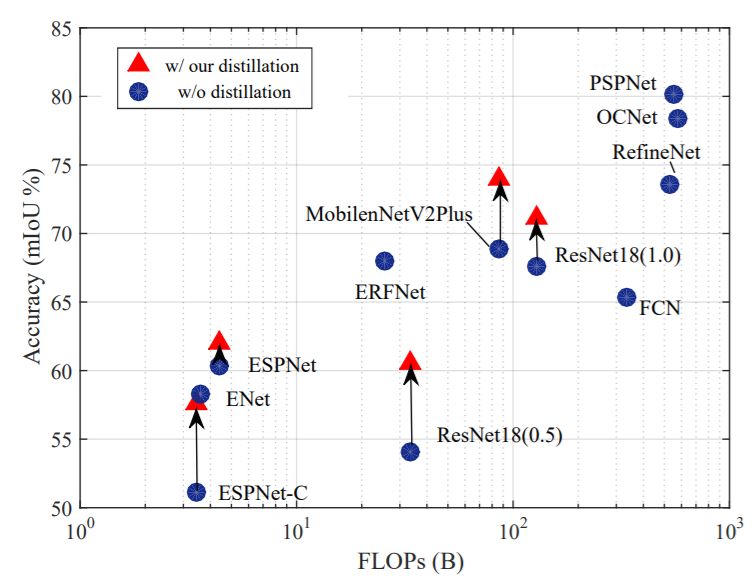
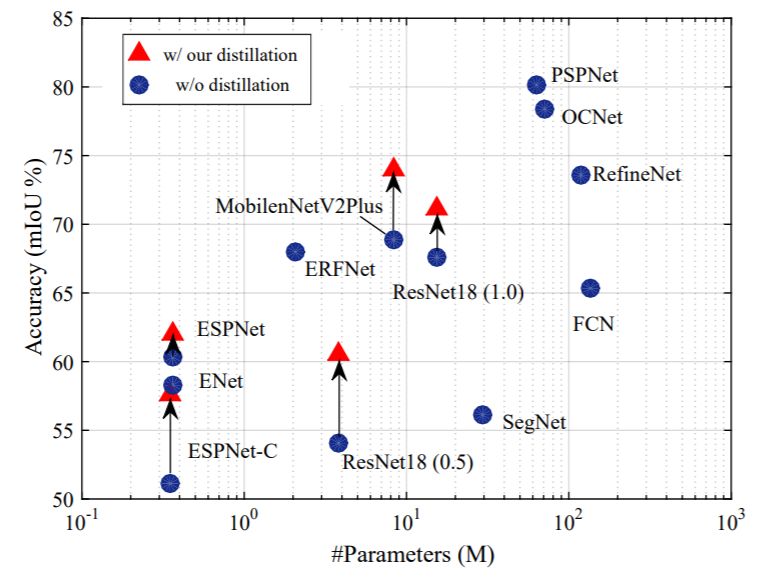
算法原理
知識蒸餾的目標是希望對于Teacher網絡和Student網絡給定相同的圖像,輸出結果盡量一樣。
所以,知識蒸餾的關鍵,是如何衡量Teacher網絡和Student網絡輸出結果的一致性,也就是訓練過程中的損失函數設計。
該文中作者將語義分割問題看為像素分類問題,所以很自然的可以使用衡量分類差異的逐像素(Pixel-wise)的損失函數Cross entropy loss,這是在最終的輸出結果Score map中計算的。
同時作者引入了圖像的結構化信息損失,如下圖所示。
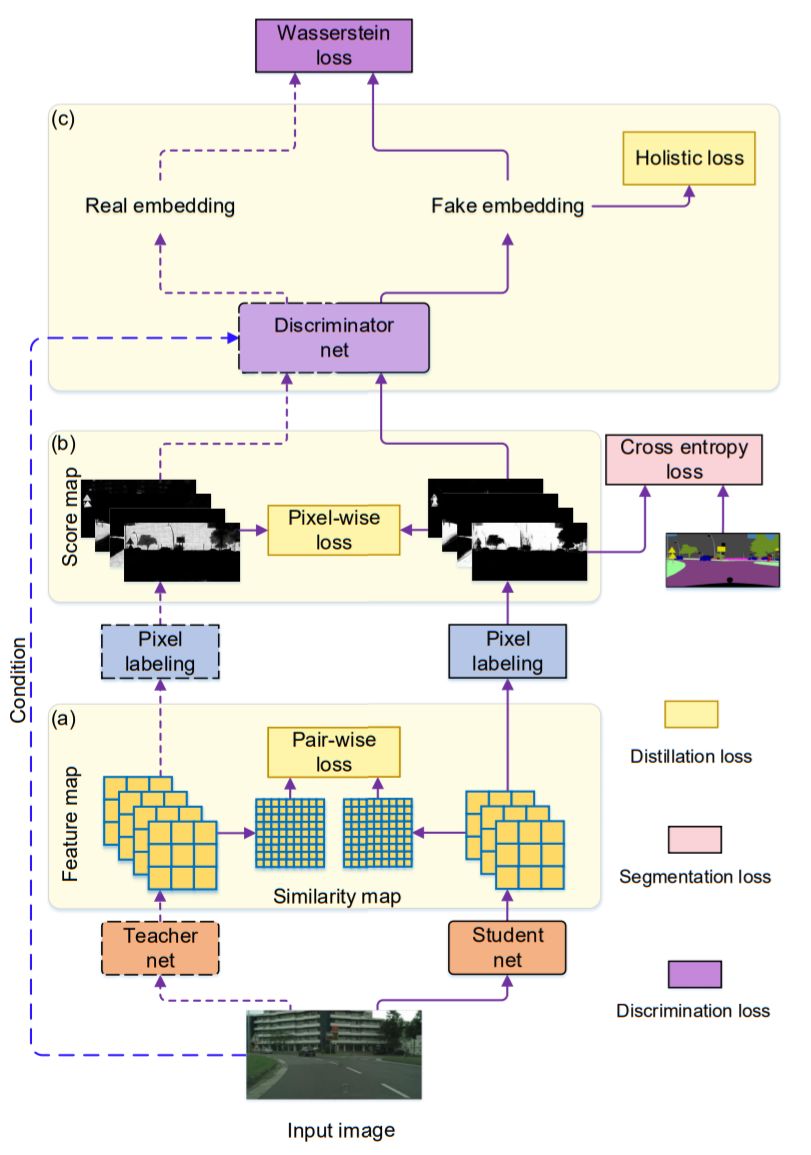
如何理解圖像的結構化信息?一種很顯然的結構化信息即圖像中局部的一致性。在語義分割中,可以簡單理解為,預測結果中存在的自相似性,作者衡量這種結構化信息的方式是Teacher預測的兩像素結果和Student網絡預測的兩像素結果一致。衡量這種損失,作者稱之為Pair-wise loss(也許可以翻譯為“逐成對像素”損失)。
另一種更高層次的結構化信息是來自對圖像整體結構相似性的度量,作者引入了對抗網絡的思想,設計專門的網絡分支分類Teacher網絡和Student網絡預測的結果,網絡收斂的結果是該網絡不能再區分Teacher網絡和Student網絡的輸出。作者稱這塊損失函數為Holistic loss(整體損失)。
仔細想想,作者設計的損失函數的三部分,逐像素的損失(Pixel-wise loss,PI)、逐像素對的損失(Pair-wise loss,PA)、整體損失(Holistic loss,HO)都很有道理,是不是?
作者使用ResNet18網絡模型在Cityscapes數據集上研究了作者提出的損失函數各部分對結果的影響。(ImN代表用ImageNet預訓練模型初始化網絡)
結果如下圖。
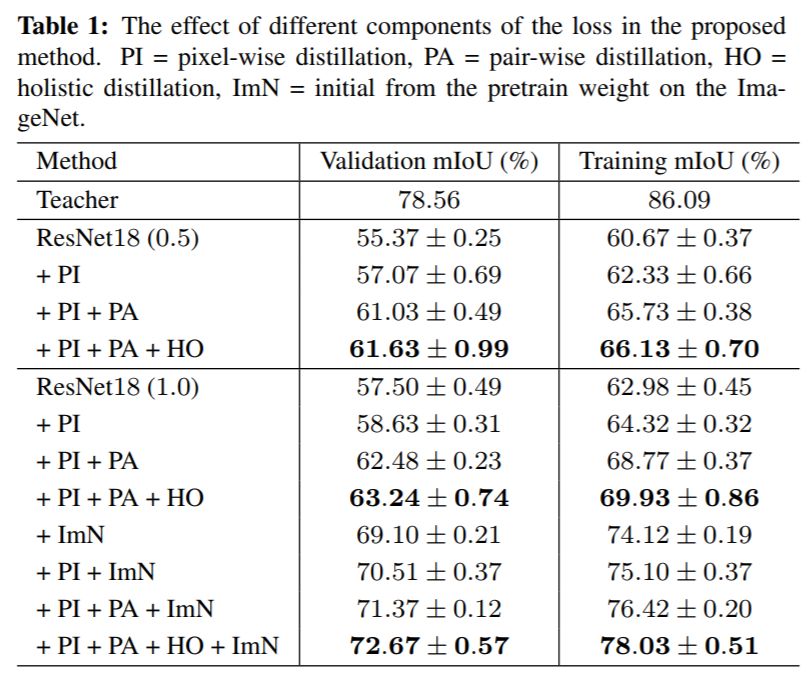
可知,作者提出的損失函數的各個部分都能使得Student網絡獲得精度增益,最高達15.17%!CV君發現逐像素對的損失(Pair-wise loss,PA)獲得的增益最大。
實驗結果
作者使用多個輕量級網絡模型,在三個主流語義分割數據庫上進行了實驗。
下圖為在Cityscapes數據集上的結果,使用該文方法知識蒸餾后Student網絡精度獲得了大幅提升!
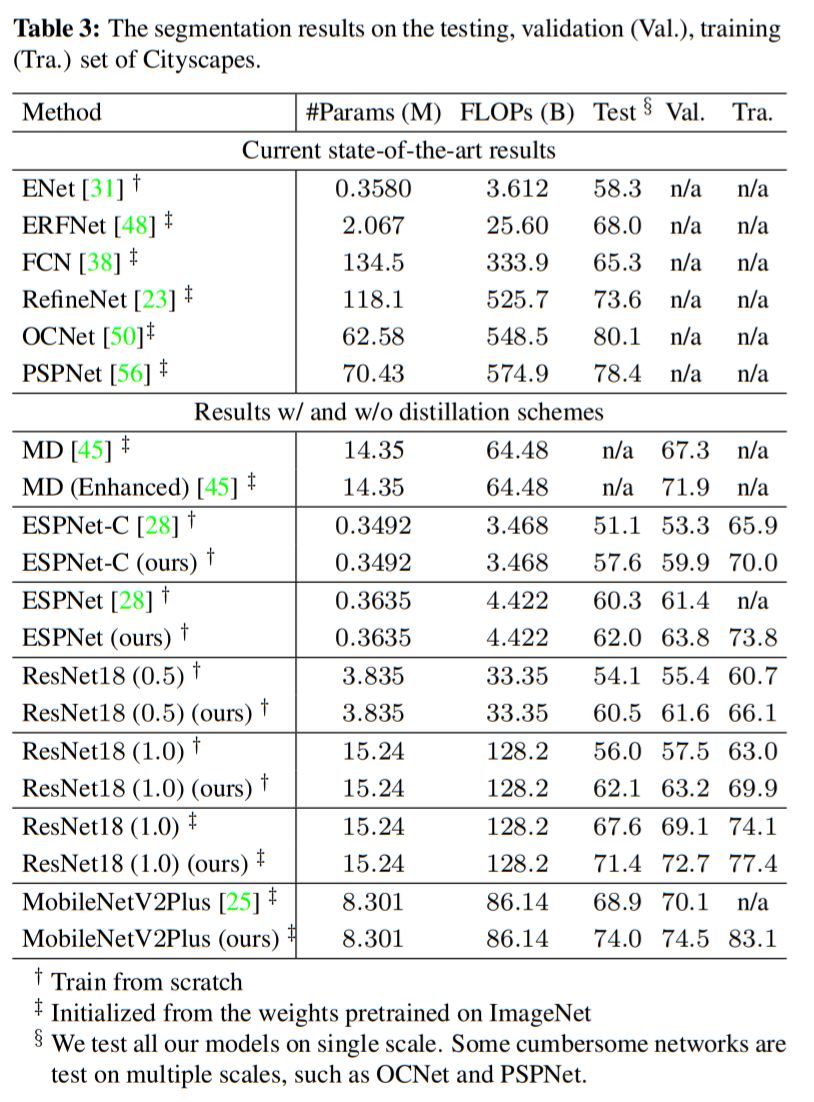
下圖為一些預測結果示例,視覺效果上改進明顯。
下圖為在CamVid數據集上的結果,同樣改進明顯。
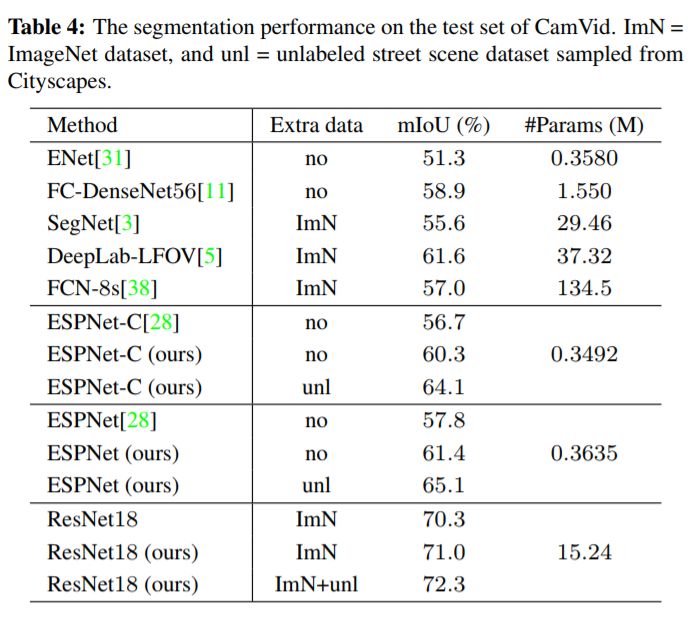
CamVid數據集上的Student網絡預測示例,視覺上也好了很多。

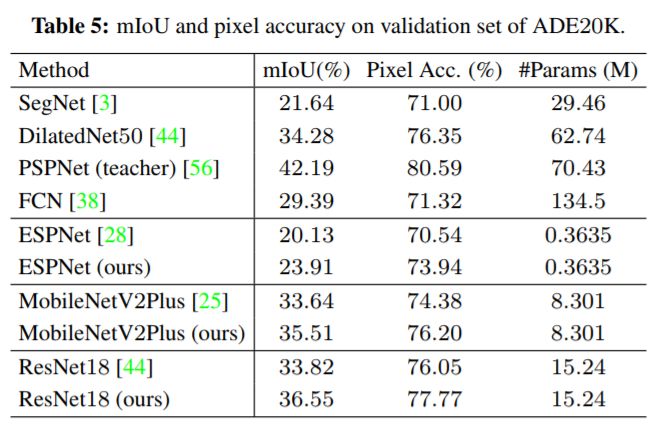
下圖為在ADE20K數據集上的實驗結果,同樣所有網絡模型的精度都獲得了大幅提升!
目前還未發現該文作者公布代碼。
-
微軟
+關注
關注
4文章
6566瀏覽量
103956 -
函數
+關注
關注
3文章
4306瀏覽量
62431 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:微軟亞研院提出用于語義分割的結構化知識蒸餾 | CVPR 2019
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
結構化布線在AI數據中心的關鍵作用
語義分割25種損失函數綜述和展望

圖像語義分割的實用性是什么
圖像分割和語義分割的區別與聯系
圖像分割與語義分割中的CNN模型綜述
定期維護結構化布線對于辦公室得重要性
臺亞半導體再度調整業務結構
阿里達摩院提出“知識鏈”框架,降低大模型幻覺
什么是結構化網絡布線?結構化網絡布線有哪些好處?
結構化布線的好處多嗎
什么是網絡系統中的結構化布線?
科通技術推出基于FPGA的應用設計結構化技術
CFD 設計利器:結構化和非結構化網格的組合使用

使用關系數據庫中的半結構化數據






 工商網監
工商網監
評論