 由淺入深的對其降維原理進行了詳細總結
由淺入深的對其降維原理進行了詳細總結
主成分分析(Principal components analysis,以下簡稱PCA)是最常用的降維方法之一,在數據壓縮和消除冗余方面具有廣泛的應用,本文由淺入深的對其降維原理進行了詳細總結。
目錄
1.向量投影和矩陣投影的含義
2. 向量降維和矩陣降維的含義
3. 基向量選擇算法
4. 基向量個數的確定
5. 中心化的作用
6. PCA算法流程
7. PCA算法總結
1. 向量投影和矩陣投影的含義
如下圖:
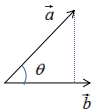
向量a在向量b的投影為:
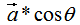
其中,θ是向量間的夾角 。
向量a在向量b的投影表示向量a在向量b方向的信息,若θ=90°時,向量a與向量b正交,向量a無向量b信息,即向量間無冗余信息 。因此,向量最簡單的表示方法是用基向量表示,如下圖:
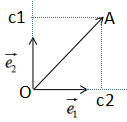
向量表示方法:
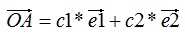
其中,c1是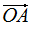 在e1方向的投影,c2是
在e1方向的投影,c2是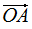 在e2方向的投影,e1和e2是基向量
在e2方向的投影,e1和e2是基向量
我們用向量的表示方法擴展到矩陣,若矩陣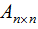 的秩r(A)=n,
的秩r(A)=n,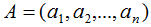
,其中ai(i=1,2,...,n)為n個維度的列向量,那么矩陣A的列向量表示為:
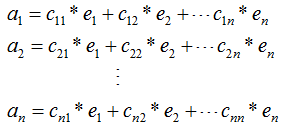
其中,e1,e2,...,en為矩陣A的特征向量 。
若矩陣A是對稱矩陣,那么特征向量為正交向量,我們對上式結合成矩陣的形式:
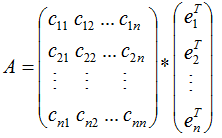
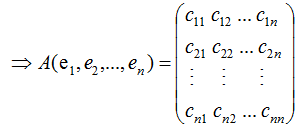
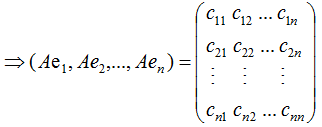
由上式可知,對稱矩陣A在各特征向量的投影等于矩陣列向量展開后的系數,特征向量可理解為基向量。
2. 向量降維和矩陣降維含義
向量降維可以通過投影的方式實現,N維向量映射為M維向量轉換為N維向量在M個基向量的投影,如N維向量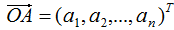 ,M個基向量分別為
,M個基向量分別為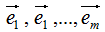 ,
,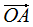 在基向量的投影:
在基向量的投影:
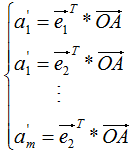
通過上式完成了降維,降維后的坐標為:
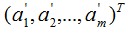
矩陣是由多個列向量組成的,因此矩陣降維思想與向量降維思想一樣,只要求得矩陣在各基向量的投影即可,基向量可以理解為新的坐標系,投影就是降維后的坐標,那么問題來了,如何選擇基向量?
3. 基向量選擇算法
已知樣本集的分布,如下圖:
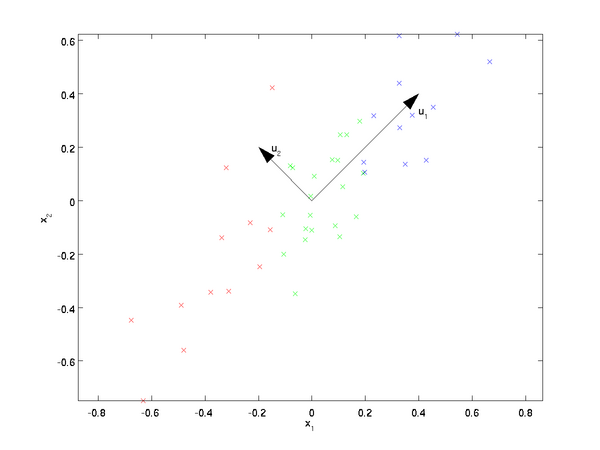
樣本集共有兩個特征x1和x2,現在對該樣本數據從二維降到一維,圖中列了兩個基向量u1和u2,樣本集在兩個向量的投影表示了不同的降維方法,哪種方法好,需要有評判標準:(1)降維前后樣本點的總距離足夠近,即最小投影距離;(2)降維后的樣本點(投影)盡可能的散開,即最大投影方差 。因此,根據上面兩個評判標準可知選擇基向量u1較好。
我們知道了基向量的選擇標準,下面介紹基于這兩個評判標準來推導基向量:
(1)基于最小投影距離
假設有n個n維數據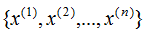 ,記為X。現在對該數據從n維降到m維,關鍵是找到m個基向量,假設基向量為{w1,w2,...,wm},記為矩陣W,矩陣W的大小是n×m。
,記為X。現在對該數據從n維降到m維,關鍵是找到m個基向量,假設基向量為{w1,w2,...,wm},記為矩陣W,矩陣W的大小是n×m。
原始數據在基向量的投影: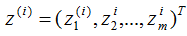
投影坐標計算公式:
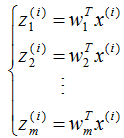
根據投影坐標和基向量,得到該樣本的映射點:
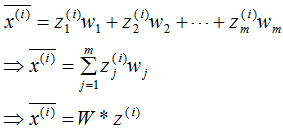
最小化樣本和映射點的總距離:
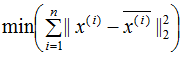
推導上式,得到最小值對應的基向量矩陣W,推導過程如下:
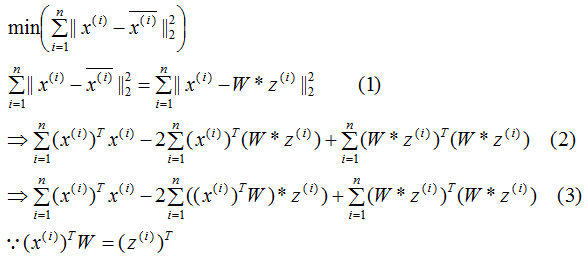
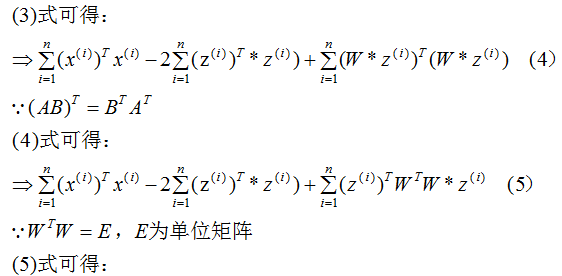
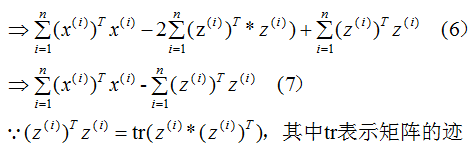
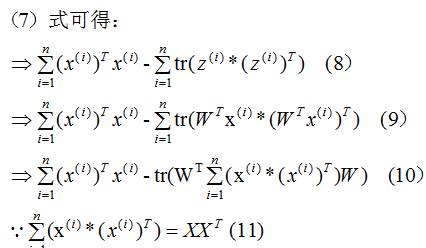
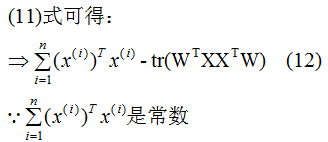

所以我們選擇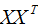 的特征向量作為投影的基向量?。
的特征向量作為投影的基向量?。
(2) 基于最大投影方差
我們希望降維后的樣本點盡可能分散,方差可以表示這種分散程度。
如上圖所示,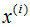 表示原始數據,
表示原始數據,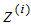 表示投影數據,
表示投影數據,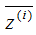 表示投影數據的平均值。所以最大化投影方差表示為:
表示投影數據的平均值。所以最大化投影方差表示為:
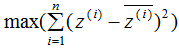
下面推導上式,得到相應的基向量矩陣W,推導過程如下:

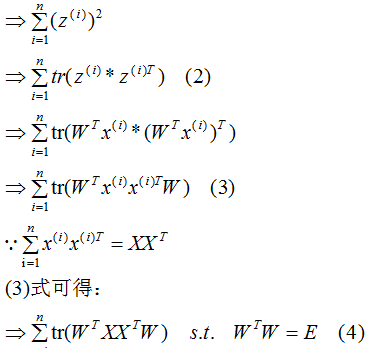
我們發現(4)式與上一節的(13)式是相同的。
因此,基向量矩陣W滿足下式:
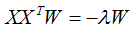
小結:降維通過樣本數據投影到基向量實現的,基向量的個數等于降維的個數,基向量是通過上式求解的。
4. 基向量個數的確定
我們知道怎么求解基向量,但是我們事先確定了基向量的個數,如上節的m個基向量,那么怎么根據樣本數據自動的選擇基向量的個數了?在回答這一問題前,簡單闡述下特征向量和特征值的意義。
假設向量wi,λi分別為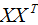 的特征向量和特征值,表達式如下:
的特征向量和特征值,表達式如下:
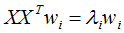
對應的圖:
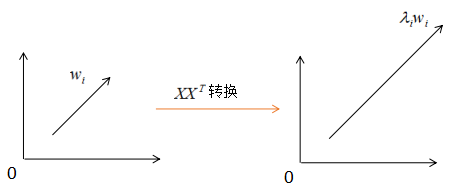
由上圖可知,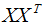 沒有改變特征向量wi的方向,只在wi的方向上伸縮或壓縮了λi倍。特征值代表了
沒有改變特征向量wi的方向,只在wi的方向上伸縮或壓縮了λi倍。特征值代表了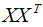 在該特征向量的信息分量。特征值越大,包含矩陣
在該特征向量的信息分量。特征值越大,包含矩陣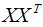 的信息分量亦越大。因此,我們可以用λi去選擇基向量個數。我們設定一個閾值threshold,該閾值表示降維后的數據保留原始數據的信息量,假設降維后的特征個數為m,降維前的特征個數為n,m應滿足下面條件:
的信息分量亦越大。因此,我們可以用λi去選擇基向量個數。我們設定一個閾值threshold,該閾值表示降維后的數據保留原始數據的信息量,假設降維后的特征個數為m,降維前的特征個數為n,m應滿足下面條件:
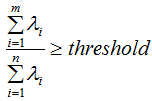
因此,通過上式可以求得基向量的個數m,即取前m個最大特征值對應的基向量。
投影的基向量:
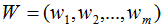
投影的數據集:
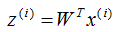
5. 中心化的作用
我們在計算協方差矩陣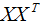 的特征向量前,需要對樣本數據進行中心化,中心化的算法如下:
的特征向量前,需要對樣本數據進行中心化,中心化的算法如下:
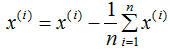
中心化數據各特征的平均值為0,計算過程如下:
對上式求平均:
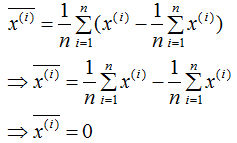
中心化的目的是簡化算法,我們重新回顧下協方差矩陣,以說明中心化的作用 。
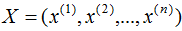 ,X表示共有n個樣本數。
,X表示共有n個樣本數。
每個樣本包含n個特征,即:
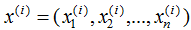
展開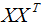 :
:
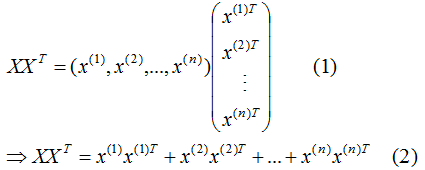
為了閱讀方便,我們只考慮兩個特征的協方差矩陣:
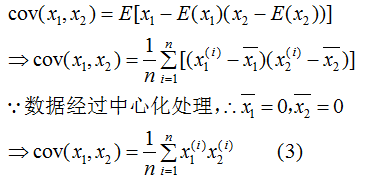
由(3)式推導(2)式得:
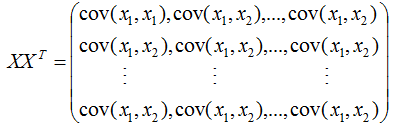
所以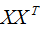 是樣本數據的協方差矩陣,但是,切記必須事先對數據進行中心化處理?。
是樣本數據的協方差矩陣,但是,切記必須事先對數據進行中心化處理?。
6. PCA算法流程
1)樣本數據中心化。
2)計算樣本的協方差矩陣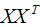 。
。
3)求協方差矩陣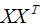 的特征值和特征向量,并對該向量進行標準化(基向量)。
的特征值和特征向量,并對該向量進行標準化(基向量)。
3)根據設定的閾值,求滿足以下條件的降維數m。
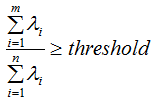
4)取前m個最大特征值對應的向量,記為W。
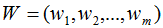
5)對樣本集的每一個樣本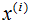 ,映射為新的樣本
,映射為新的樣本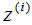 。
。
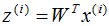
6)得到映射后的樣本集D'。
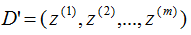
7. 核主成分分析(KPCA)介紹
因為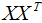 可以用樣本數據內積表示:
可以用樣本數據內積表示:
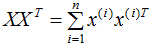
由核函數定義可知,可通過核函數將數據映射成高維數據,并對該高維數據進行降維:
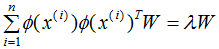
KPCA一般用在數據不是線性的,無法直接進行PCA降維,需要通過核函數映射成高維數據,再進行PCA降維。
8. PCA算法總結
PCA是一種非監督學習的降維算法,只需要計算樣本數據的協方差矩陣就能實現降維的目的,其算法較易實現,但是降維后特征的可解釋性較弱,且通過降維后信息會丟失一些,可能對后續的處理有重要影響。
-
PCA
+關注
關注
0文章
89瀏覽量
29559 -
向量
+關注
關注
0文章
55瀏覽量
11660 -
降維
+關注
關注
0文章
10瀏覽量
7643
原文標題:主成分分析(PCA)原理總結
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
求助,SVM分類時要不要先進行PCA降維呢?
HV857已針對各種應用進行了優化
對結構體成員進行了賦值
使用STlinkUtility v 4.5.0對閃存進行了不受保護的讀取和寫入操作,無法擦除閃存怎么解決?
最全最詳細LTC6803使用筆記總結
美格智能已對其官方網站進行了全新的改版和升級
Google對Google Camera進行了改進
Ascent和IBM合作進行了一項人工智能試驗
三星對其Bixby服務進行了重大改進
TDK Corporation對其Micronas嵌入式電機控制器系列產品進行了擴展
淺析卷積降維與池化降維的對比





 工商網監
工商網監
評論