 Kaggle的座頭鯨識別挑戰比賽在最近落下帷幕
Kaggle的座頭鯨識別挑戰比賽在最近落下帷幕
Kaggle的座頭鯨識別挑戰比賽在最近落下帷幕,全球共2131個團隊參加了比賽。
這是近期Kaggle上頗受歡迎的一次競賽,常用的分類方法無法處理大量的無標注數據,只有對傳統的方法進行創新,才能夠獲得高分。
下面文摘菌為大家介紹比賽中排名TOP10的團隊如何完成比賽,以及其他幾只團隊的相關經驗。
注:該團隊由Vladislav Shakhray,Artsiom Sanakoyeu海德堡大學的博士組成,以及Kaggle Top-5 大神Pavel Pleskov。
本文作者Vladislav Shakhray,文摘菌對其編譯如下。
比賽鏈接:
https://www.kaggle.com/c/humpback-whale-identification
問題描述
在比賽中,主要是構建算法來識別圖像中的鯨魚個體,而難點在于訓練樣本的嚴重不均衡以及存在近三分之一的無標注數據。
訓練數據中的同一條鯨魚的9張照片的示例
在超過2000個鯨魚類別,只有一個訓練樣本,這使得常用的分類方法很難使用。更重要的是,無論鯨魚是否是新的種類,這都是比賽的重要組成部分,結果證明這是非常重要的。
鯨魚種類間照片數量差距很大
競賽的衡量標準是MAP @ 5(平均精度為5),能夠為每個測試圖像提交最多5個預測。 我們在測試集上的最高成績是0.959 MAP @ 5。
驗證和初始設置
在本次比賽前幾個月,同一比賽的另一個版本在Kaggle上舉行,但是,正如競賽發起人所指出的那樣,現在的版本包含更多清潔的數據。我們決定以多種方式利用之前比賽的成果和數據:
1.使用之前競爭對手的數據,我們使用image hashing來收集超過2000個驗證樣本。 當我們稍后驗證我們的成果時,這一方法非常重要。
2.我們從訓練數據集中刪除了new_whale類,因為它不在其元素之間共享任何邏輯圖像特征。
3.有些圖像根本沒有對齊。 幸運的是,在之前一版kaggle比賽的成功解決方案中有一個公開可用的預訓練邊界框模型。我們用它來檢測鯨魚周圍的精確邊界框并相應地裁剪圖像。
4.由于圖像的顏色不同,所有數據在訓練前都轉換為灰色。
方法1:孿生神經網絡Siamese Networks(Vladislav)
我們的第一個架構是一個具有眾多分支架構和自定義損失的孿生神經網絡(Siamese Networks),其中包括許多卷積和密集層。 我們使用的分支架構包括:
ResNet-18, ResNet-34, Resnet-50
SE-ResNeXt-50
Martin Piotte公開分享的類似ResNet的自定義分支
我們通過在每4個時期的分數矩陣上求解線性分配問題來使用顯著陰性(hard-negative mining)和顯著陽性挖掘(hard- positive mining)。 在矩陣中添加了一些隨機化以簡化訓練過程。
使用漸進式學習(Progressive learning),分辨率策略為229x229 - > 384x384 - > 512x512。 也就是說,我們首先在229x229圖像上訓練我們的網絡,幾乎沒有用正則化和更大的學習率。 在收斂之后,我們重置學習速率并增加正則化,從而再次對更高分辨率的圖像(例如384×484)訓練網絡。
此外,由于數據的性質,使用了大量增強,包括隨機亮度,高斯噪聲,隨機剪裁和隨機模糊。
此外,我們采用智能翻轉增強策略,極大地幫助創建了更多的訓練數據。 具體地,對于屬于相同的鯨魚X,Y的每對訓練圖像,我們創建了另外一個訓練對翻轉(X),翻轉(Y)。 另一方面,對于每對不同的鯨魚,我們創建了另外三個例子:翻轉(X),Y,Y,翻轉(X)和翻轉(X),翻轉(Y)。
一個顯示隨機翻轉策略不適用于一對相同鯨魚照片的例子。 請注意當我們翻轉圖片時,兩張圖片的翻轉效果不同,因為我們關心鯨魚尾部的寄生藻的位置。
使用Adam優化器優化模型,初始學習率為1e-4,接近訓練結束時減少5倍。 批量大小設置為64。
模型是用Keras編寫的。在單個2080Ti上花費2-3天(取決于圖像分辨率),訓練模型大約400-600個周期。
使用ResNet-50性能最佳的單一模型得分為0.929 LB。
方法2:度量學習Metric Learning(Artsiom)
我們使用的另一種方法是使用保證金損失進行度量學習。 我們使用了許多ImageNet預訓練的架構,其中包括:
ResNet-50, ResNet-101, ResNet-152
DenseNet-121, DenseNet-169
這些網絡主要由448x448 - > 672x672策略逐步訓練。
我們使用了Adam優化器,在100個訓練周期后將學習率降低了10倍。 我們還為整個訓練使用批量大小為96的訓練方法。
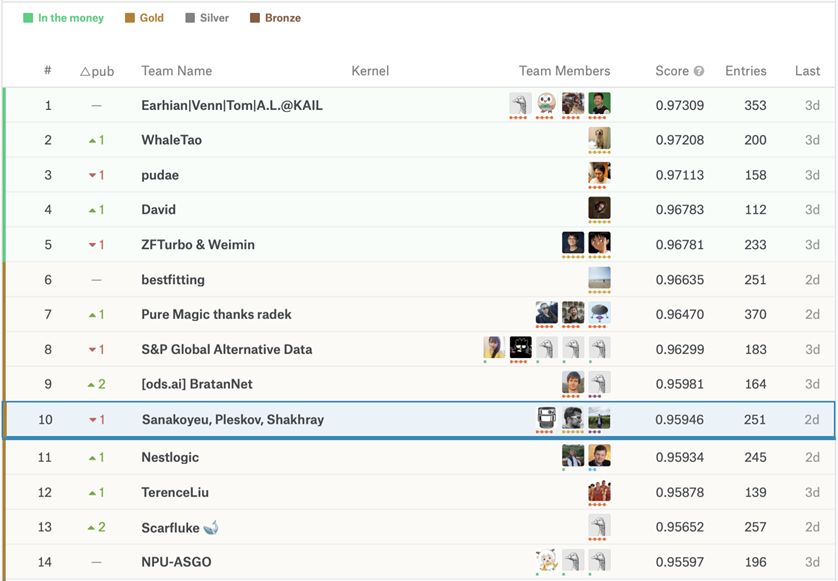
由Sanakoyeu,Tschernezki等人開發的度量學習(metric learning)方法能夠讓成績迅速提升。
度量學習在CVPR 2019上發布,它所做的是每個周期它將訓練數據以及嵌入層分成簇。在訓練組塊和學習者之間建立雙射之后,模型分別訓練它們,同時累積分支網絡的梯度。
代碼及文章鏈接:
https://github.com/CompVis/metric-learning-divide-and-conquer
由于巨大的種類數量不平衡,我們使用了大量的增強,包括隨機翻轉,旋轉,變焦,模糊,光照,對比度,飽和度變化。 之后,計算查詢特征向量和列車庫特征向量之間的點積,并且選擇具有最高點積值的類作為TOP-1預測。 隱含地幫助類不平衡的另一個技巧是對屬于相同鯨魚id的火車圖像的特征向量進行平均。
這些模型使用PyTorch實現,需要單個Titan Xp 2-4天(取決于圖像分辨率)來訓練。 值得一提的是,具有DenseNet-169架構表現最佳的單一模型得分為0.931LB。
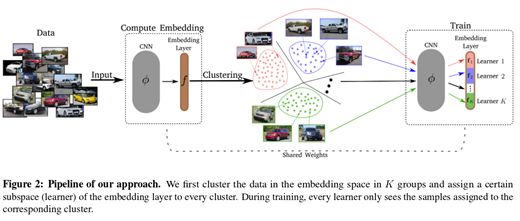
方法3:特征分類(Artsiom)
當我和Artsiom聯手時,我們做的第一件事就是使用從我們所有模型中提取并連接(應用PCA分析)的特征來訓練分類模型。
分類的主要部分由兩個密集的層組成,其間會刪失信息。由于我們使用了預先計算的特征,因此模型訓練得非常快。
通過這種方法我們獲得了0.924 LB,并讓整個集合更富多樣性。
方法4:新鯨魚分類(Pavel)
本次比賽最復雜的部分之一是正確分類新鯨魚(大約30%的圖像屬于新類別鯨魚)。
解決這個問題的流行策略是使用一個簡單的閾值。也就是說,如果給定的圖像X屬于某個已知類別鯨魚的最大概率小于閾值,則將其歸類為新鯨魚。然而,我們認為可能有更好的方法來解決這個問題。
對于每個表現最佳的模型和集合,我們選取了TOP-4預測,按降序排序。然后,對于其他的每個模型,我們將他們的概率用于所選擇的這4個類。目標是根據這些特征來預測鯨魚是否屬于新類別。
Pavel創建了一個非常強大的包含LogRegression,SVM,幾個k-NN模型和LightGBM的混合模型。這個混合模型在交叉驗證中給出了0.9655 的ROC-AUC值,并且將LB得分提高了2%。
綜合
由我們的模型構建混合模型相當不容易。難度在于我的模型的輸出是非標準化概率矩陣(從0到1),而Artsiom提供的輸出矩陣由歐幾里德距離組成(范圍從0到無窮大)。
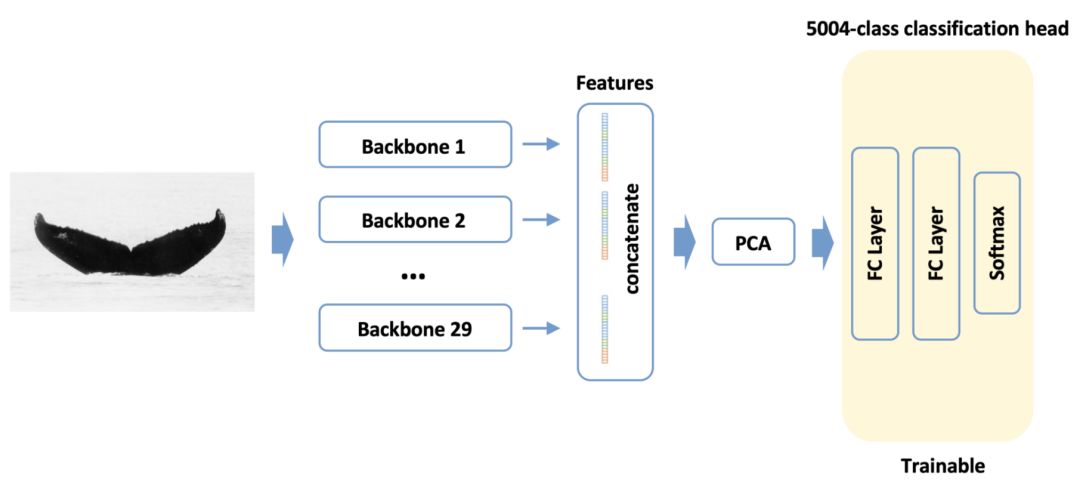
我們嘗試了許多方法將Artsiom的矩陣轉換為概率,其中包括:
1、類似tSNE的轉換:
2、Softmax
3、通過應用函數1 / (1 + distances)簡單地反轉范圍
4、其他可以反轉矩陣范圍的函數
不幸的是,前兩種方法根本不起作用,而使用大多數函數將范圍剪切至[0,1]的結果大致相同。我們最終選擇在驗證集上具有最高mAP @ 5的函數。
令人驚訝的是,最好的是1 / (1 + log(1 + log(1 + distances)))。
其他團隊使用的方法
大衛現在是Kaggle Grandmaster(等級為12),在Private LB上排名第四,并在Kaggle Discussions論壇上分享了他的解決方案。
https://www.kaggle.com/c/humpback-whale-identification/discussion/82356
他使用全分辨率圖像并使用傳統的關鍵點匹配技術,利用SIFT和ROOTSIFT。為了解決假陽性問題,大衛訓練了一個U-Net從背景分割鯨魚。有趣的是,他使用后期處理給只有一個訓練樣本的類別更多的機會躋身TOP-1預測。
我們也考慮過嘗試基于SIFT的方法,但我們確信它肯定會比頂級神經網絡表現得差。
在我看來,我們能從中學會的是,永遠不應被深度學習的力量所蒙蔽,從而低估了傳統方法的能力。
單純分類
由Dmytro Mishkin,Anastasiia Mishchuk和Igor Krashenyi組成的Pure Magic thanks radek團隊(第7名),追求將metric learning(triplet loss)和分類結合起來,正如Dmytro在他的文章中描述的那樣。
在訓練分類模型一段時間時,他們嘗試使用Center Loss來減少過擬合,并在應用softmax之前進行temperature scaling。在使用的眾多主干架構中,最好的是SE-ResNeXt-50,它能夠達到0.955LB。
temperature scaling:
https://arxiv.org/pdf/1706.04599.pdf
他們的解決方案比這更加多樣化,我強烈建議你參考原文。
正如Ivan Sosin在文章中(他的團隊BratanNet在本次比賽中排名第9)所述,他們使用了CosFace和ArcFace方法。下面是來自于原文:
Cosface和Arcface作為面部識別任務新近發現的SOTA脫穎而出。其主要思想是在余弦相似空間中將同類的例子相互拉近并分開不同的類別。通常是分類任務使用cosface或arcface,因此最終的損失函數是CrossEntropy
當使用像InceptionV3或SE-ResNeXt-50這樣的較大主干網絡時,他們注意到了過擬合,因而他們切換到較輕量的網絡,如ResNet-34,BN-Inception和DenseNet-121。
文章鏈接:
https://www.kaggle.com/c/humpback-whale-identification/discussion/82427
該團隊還使用了精心挑選的擴充和眾多網絡修正方法,如CoordConv和GapNet。
他們方法中特別有趣的是他們處理新類別鯨魚的方式。下面是原文:
一開始我們就意識到必須對新鯨魚做一些處理,以便將它們納入訓練中。簡單的方法是給每個新鯨魚分配一個1/5004的可能屬于每一類別的概率。在加權采樣方法的幫助下,它帶來了一些提升。
但后來我們意識到可以使用softmax預測來自于訓練集中的新鯨魚。所以我們想到了distillation。我們選擇distillation代替偽標簽,因為新鯨魚的標簽應該與訓練的標簽不同,雖然它可能不是真的。
為了進一步提升模型性能,我們將帶有偽標簽的測試圖片添加到訓練集中。最終,我們的單一模型可以通過snapshot ensembling達到0.958。不幸的是,以這種方式訓練的ensembling并沒有在分數上有任何的提高。也許是因為偽標簽和distillation造成的多樣性減少。
最后的思考
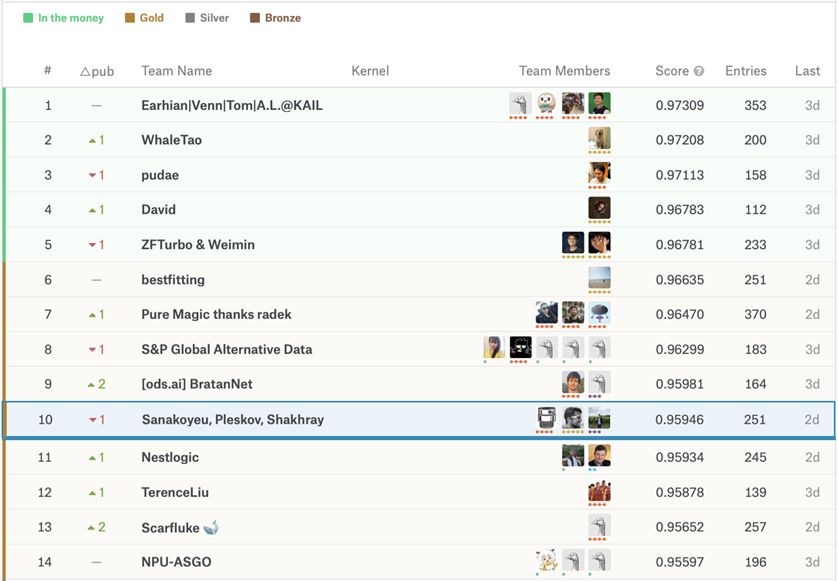
最后的排名
令人驚訝的是,盡管私人測試集占到全部測試集的近80%,但是最終結果幾乎沒有大的改變。我相信比賽的主辦方已經提供了一個非常有趣的問題,以及經過很好地處理的數據。
這是我參加的第一場Kaggle比賽,毫無疑問,它表現出了Kaggle比賽的有趣,迷人,激勵和教育性。我要祝賀由于這次比賽而成為Expert,Master和Grandmaster的人。我還要感謝ODS.ai社區提供的精彩討論和支持。
最后,我要再一次特別感謝我的隊友Artsiom Sanakoyeu和Pavel Pleskov,為我帶來了一次難忘的Kaggle比賽經歷。
-
模型
+關注
關注
1文章
3178瀏覽量
48731 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
pytorch
+關注
關注
2文章
803瀏覽量
13152
原文標題:Kaggle座頭鯨識別賽,TOP10團隊的解決方案分享
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
公安特警在團隊作戰過程中該如何保證和隊員間的實時通訊-TIKOOL太酷公網全雙工內通

PC機不能識別AIC3254EVM-K的原因?
人流量檢測識別攝像頭

電動車亂停放識別攝像頭
康謀分享 | 在基于場景的AD/ADAS驗證過程中,識別挑戰性場景!

AI4Science黑客松光子計算挑戰賽成功舉辦
解析Type-C母座與Type-C公頭:特點與區別

攝像頭模塊突然無法顯示!!!可能是什么原因?
多鯨信息獲500萬元天使輪融資
云天勵飛首屆渠道大會落下帷幕,多家企業現場簽約
車內語音識別數據在智能駕駛中的應用與挑戰
淺談ADAS前置攝像頭設計挑戰





 工商網監
工商網監
評論