 人類的本質不是復讀機,可能是計算機
人類的本質不是復讀機,可能是計算機
約翰霍普金斯大學的最新研究發現:人類可能在像計算機一樣思考。這樣研究的作者、大四學生周正隆等人對1800人做了實驗,結果顯示98%的人傾向于像計算機那樣回答問題。
人類的本質不是復讀機,可能是計算機。
長期以來,人們想方設法研究讓計算機像人類一樣思考,比如做視覺識別。但是,約翰霍普金斯大學的最新研究發現:人類可能在像計算機一樣思考。
不信先來做一組測試。
第一題:你覺得計算機會把下圖認成什么?
A.交通信號燈
B.電話
答案是:
·
·
·
·
·
·
·
·
A
第二題:你覺得計算機會把下圖認成什么?
A.貨運車
B.校車
答案是:
·
·
·
·
·
·
·
·
B
你是不是都選對了?
我們知道,即使是像自動駕駛汽車那樣功能強大的計算機,只要把某些圖像的像素稍作改動,攝像頭就可能被欺騙,例如會把黑人識別成猩猩、把香蕉識別成烤面包機等等,這些機器似乎以人類永遠無法想象的方式錯誤地識別物體。
但真的是這樣嗎?
約翰霍普金斯大學的測試視頻顯示,75%的人其實選的跟計算機一樣,并且他們還對1800人做了八組實驗,發現98%的人傾向于像計算機那樣回答問題。
換句話說:雖然我們看不見,但其實人類知道計算機在想什么,因為人類可能在像計算機一樣思考。
這項研究是由約翰霍普金斯大學大四本科生周正隆(Zhenglong Zhou,音譯)等人提出來,主要證明計算機錯誤識別物體的缺陷可能并不像人們想象的那么糟糕。研究也提供了一個新的視角,以及一個可以探索的新的實驗范式。
這項研究論文發表在最新的Nature Communications上,周正隆是第一作者。
論文地址:
https://www.nature.com/articles/s41467-019-08931-6
機器思維理論:讓人類分辨難倒機器的圖像
計算機視覺領域存在一個關鍵的盲點:有可能故意制造出神經網絡無法正確看到的圖像。這些圖片,被稱為對抗性或愚弄性的圖片。
其中,對抗性圖像中有兩類特別引人注目,它們可以被粗略地稱為“欺騙”圖像(“fooling” image)和“擾動”圖像(“perturbed” image),如下所示:
a.間接編碼的“欺騙”圖像。b.直接編碼“欺騙”圖像。c.擾動對抗圖像。d. LaVAN攻擊可以導致機器對自然圖像進行錯誤分類。e.“魯棒的”對抗性圖像是從多個角度錯誤分類的3D對象的呈現。
欺騙圖像:是毫無意義的模式,被機器視覺系統歸類為熟悉的對象。例如,一組有方向的線條可以被歸類為“棒球”,或者一個彩色的電視靜態圖像可以被稱為“犰狳”。
擾動圖像:通常可以被準確而直接地分類(例如,雛菊的普通照片,或者手寫的數字6),但是被機器稍微擾動一下,就會產生完全不同的分類(例如,美洲虎,或者手寫的數字5)。
對抗性圖像是一個大問題,它們不僅可能被黑客利用,造成安全風險,而且,人們本能地認為,人類不會像機器那樣對圖像進行分類,人類和機器看到的圖像非常不同。
盡管經常有人斷言,對抗性圖像“完全無法被人類眼睛識別”,但很少有研究通過測試人類在這類圖像上的表現來積極探索這一假設。與此同時,在什么條件下可以有效地比較人類和機器的性能,這一點從來都不清楚,特別是因為這類機器視覺系統通常只有有限的標簽可以應用于這類圖像。
為此,周正隆等人引入了一種“機器思維理論(machine-theory-of-mind)”任務,詢問人類是否能夠推斷出機器視覺系統將分配給給定圖像的分類。
人類的任務是“像機器一樣思考”并確定為每個圖像生成了哪個標簽。
周正隆等人對任務進行了八次實驗,探索人類對五種不同對抗性圖像集的理解。在這8個實驗中,涵蓋了各種各樣的對抗性攻擊,以及核心實驗設計的幾個變種。實驗發現,人類受試者能夠預測機器對對抗性刺激的分類。結論是,人類的直覺比機器分類更加可靠。
實驗:98%的人傾向于計算機的回答
由于篇幅有限,本文只介紹八個實驗中的前三個。
實驗1:用foil標簽欺騙圖像
第一個實驗采用48張欺騙圖像來進行“機器思維理論”任務。這些圖像是由進化算法產生的,用來混淆一個極具影響力的圖像識別CNN——AlexNet,并將它們歸類為“Pinwheel(風車)”和“bagel(百吉餅)”等熟悉的對象。
在每一項試驗中,受試者都看到了一張欺騙圖像,并選擇他們認為機器為該圖像生成的兩個標簽中的任何一個,如下圖所示。
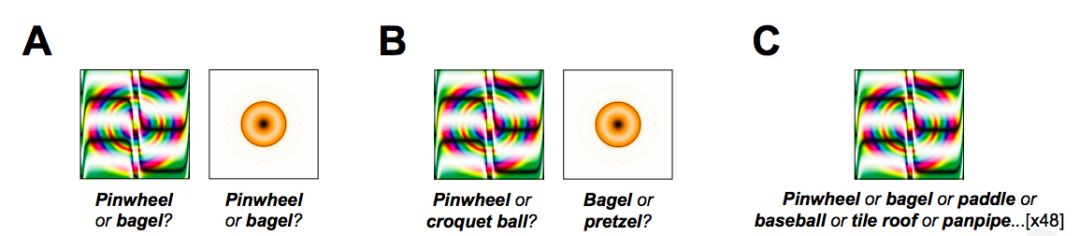
圖2
值得注意的是,人類觀察者強烈傾向于機器所選擇的標簽,而不是foil標簽:分類的“準確性”(即,與機器分類一致)為74%,遠高于50%。
也許更有說服力的是,98%的觀察者選擇機器的標簽的幾率高于隨機比率,這表明人們驚人地對機器的選擇是普遍認同的。
這一初步結果表明,人類觀察者可以大致區分CNN用于將欺騙圖像分類為熟悉對象的特征。
實驗2:首選 vs. 次選
這種能力到底有多強呢?
雖然實驗1中的受試者可以將機器選擇的標簽與隨機標簽區分開來,但是這種實現,可能不是通過辨別圖像與其CNN生成的標簽之間的任何有意義的相似性,而是通過識別它們之間非常膚淺的共性來實現的。
為了詢問人類是否能夠理解機器所做出的微妙區分,實驗2將CNN的首選標簽與隨機標簽進行了對比。
例如,考慮到圖2中的圓形金色斑點,AlexNet在“bagel(百吉餅)”之后的下一個選擇是“pretzel(椒鹽卷餅)”,它同樣意味著彎曲的金色物體。因此,便得到了每個被欺騙的圖像排名第二的選項,并讓實驗2中的觀察者在機器的首選項和次選項之間做出選擇。
同樣,人類觀察者同意機器的分類:91%的觀察者傾向于選擇機器的首選項而不是次選項,71%的圖像顯示人機一致(下圖中間柱形)。
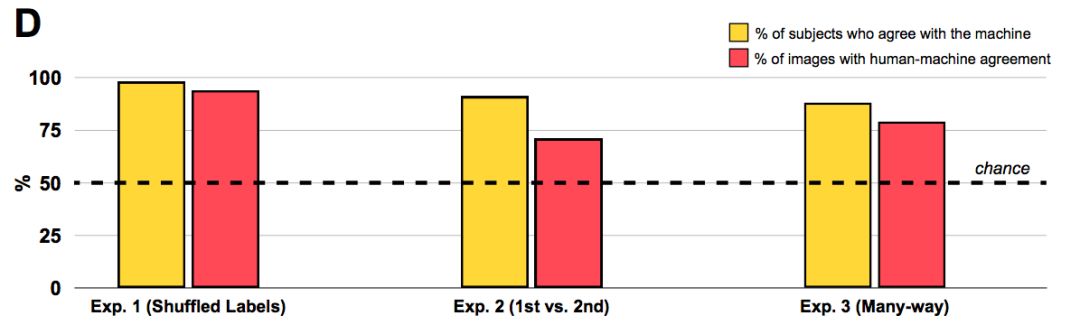
顯然,人類能夠從對抗性圖像中識別出更深層次的特征,從而將CNN的主要分類與替代分類區分開來。
此外,這一結果還表明,即使在圖像標簽的排序上,人類和機器也表現出重疊,這表明,CNN的次選項對人類來說也是比較直觀的。
實驗3a:多種方式分類
上述實驗表明,人類可以從相關備選方案中識別機器的首選標簽。
然而,這兩項研究都涉及僅有兩種選擇的有限情況;相比之下,圖像識別CNN通常在對這樣的圖像進行分類時是從數百或數千個標簽中進行選擇。 若是在更不受約束的情況下,人類在圖像分類時是否會做出與機器一樣的選擇呢?
即使在這些苛刻的條件下,88%的受試者以高于概率的速度選擇了該機器的標簽。此外,在一項受機器學習文獻中排名第5的測量方法啟發的分析中,我們發現63%的圖像中,機器的標簽是人類選擇的前五名中的一員。
換句話說,即使單個最受歡迎的人類選擇標簽不是CNN的首選標簽,第二,第三,第四或第五最受歡迎的人類選擇標簽(48種可能的選擇中)通常與CNN的首選標簽相匹配。
實驗3b:“這是什么?”
之前的研究更接近于CNN在圖像分類中所面臨的任務,即在眾多圖像中選擇一個標簽進行分類。
然而,之前所有的實驗都與CNN的任務有另一個不同之處:CNN選擇一個與圖像最匹配的標簽,而我們的人類受試者被要求預測機器的標簽,而不是自己給圖像貼標簽。如果人類的任務只是簡單地直接對圖像進行分類,他們還會同意CNN的分類嗎?
實驗3b通過改變任務說明來研究這個問題:不是讓受試者“像機器一樣思考”并猜測機器的首選標簽,而是簡單地向他們展示圖片,并問他們“這是什么?”
在每次試驗中,屏幕上都會出現一張圖片,受試者被問到“如果你必須為它選一個標簽,你會選什么?”(有48種標簽)。
再次,人類的判斷和機器的分類融合在一起:90%的受試者同意機器,81%的圖像顯示人機一致。這些結果表明,人類破譯對抗性圖像的能力并不取決于我們的“機器思維理論”任務的特性,而人類的表現反映了對機器(錯誤)分類的普遍認同。
接下來的四個實驗分別是:
電視靜態圖像;
被擾動的數字;
自然圖像和局部擾動;
3D對象。
詳細內容可以查看原文章:
https://www.nature.com/articles/s41467-019-08931-6#rightslink
人類與機器存在某種意義上的相似
目前的研究結果表明,人類的直覺是機器如何對圖像進行分類的可靠信息來源——即使是那些專門用來欺騙機器的對抗圖像。
這意味著,在將圖像與標簽關聯時,人類和機器在優先級的圖像特性上至少存在某種有意義的相似性。
對抗性圖像的存在讓人懷疑,最近開發的機器視覺系統在如何對圖像進行分類方面是否與人類有任何真正的相似之處,以及此類模型是否可以被秘密攻擊。目前的結果表明,這種挑戰人機相似性的概念可能并不像看上去的那么簡單。
更加熟悉對抗性圖像的空間可能會讓人們更好地預測機器的分類,也許未來的工作可能決定如何最好地準備和訓練人類檢測和破譯這些圖像。
以上就是周正隆等人發表在Nature Communications上的論文主要內容。

周正隆等人的研究給人們研究計算機眼中的世界提供了一種新的思路。
實際上,Ian Goodfellow等人在去年的時候也做過探索解決對抗性圖像的研究,在研究中,構建了從計算機視覺模型轉移到人類視覺系統的對抗性示例。

Ian Goodfellow等人的論文
在這篇論文中,Ian Goodfellow等人利用了機器學習、神經科學和心理物理學三個核心思想:
首先,使用最新的黑匣子對抗性示例構造技術,為目標模型創建對抗性示例,而無需訪問模型的體系結構或參數。
其次,調整機器學習模型以模仿人類的初始視覺處理,使得對抗性示例更有可能從模型轉移到人類觀察者。
第三,在時間限制的環境中評估人類觀察者的分類決策,以便甚至可以檢測到對人類感知的微妙影響。
研究發現跨計算機視覺模型傳遞的對抗性例子確實成功地影響了人類觀察者的感知,從而揭示了計算機視覺模型與人類大腦之間共享的一類新幻想。
論文地址:
https://arxiv.org/abs/1802.08195
最近,谷歌與OpenAI共同創建了Activation Atlases(激活地圖),這是一種可視化神經元之間相互作用的新技術。通過使用特征反演(feature inversion)來可視化一個圖像分類網絡中數以百萬計的激活。
換言之,神經網絡圖像分類的黑匣子終于被打開了。
詳細文章請點擊下圖了解Activation Atlases的原理。
你認為人類的本質是什么?
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100539 -
攝像頭
+關注
關注
59文章
4810瀏覽量
95445 -
自動駕駛
+關注
關注
783文章
13684瀏覽量
166147
原文標題:人類的本質是計算機?大四本科生測試1800人:98%的人和機器想法一致
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
四款復讀機電路

jinke-169復讀機開發資料(PCB+原理圖)
索科CP-2300復讀機無聲故障檢修
計算機組成原理系計算機是什么
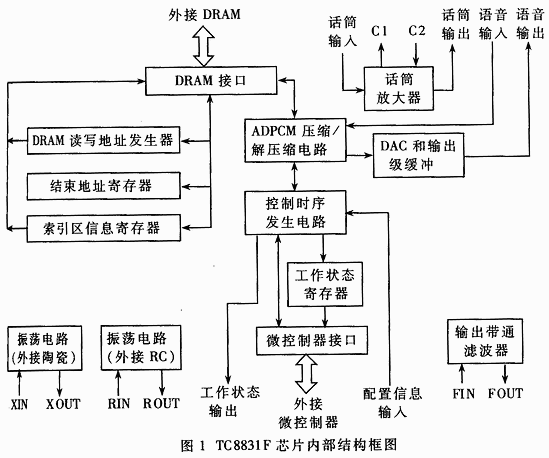
TC8831F系列芯片的語音復讀機的改進方案
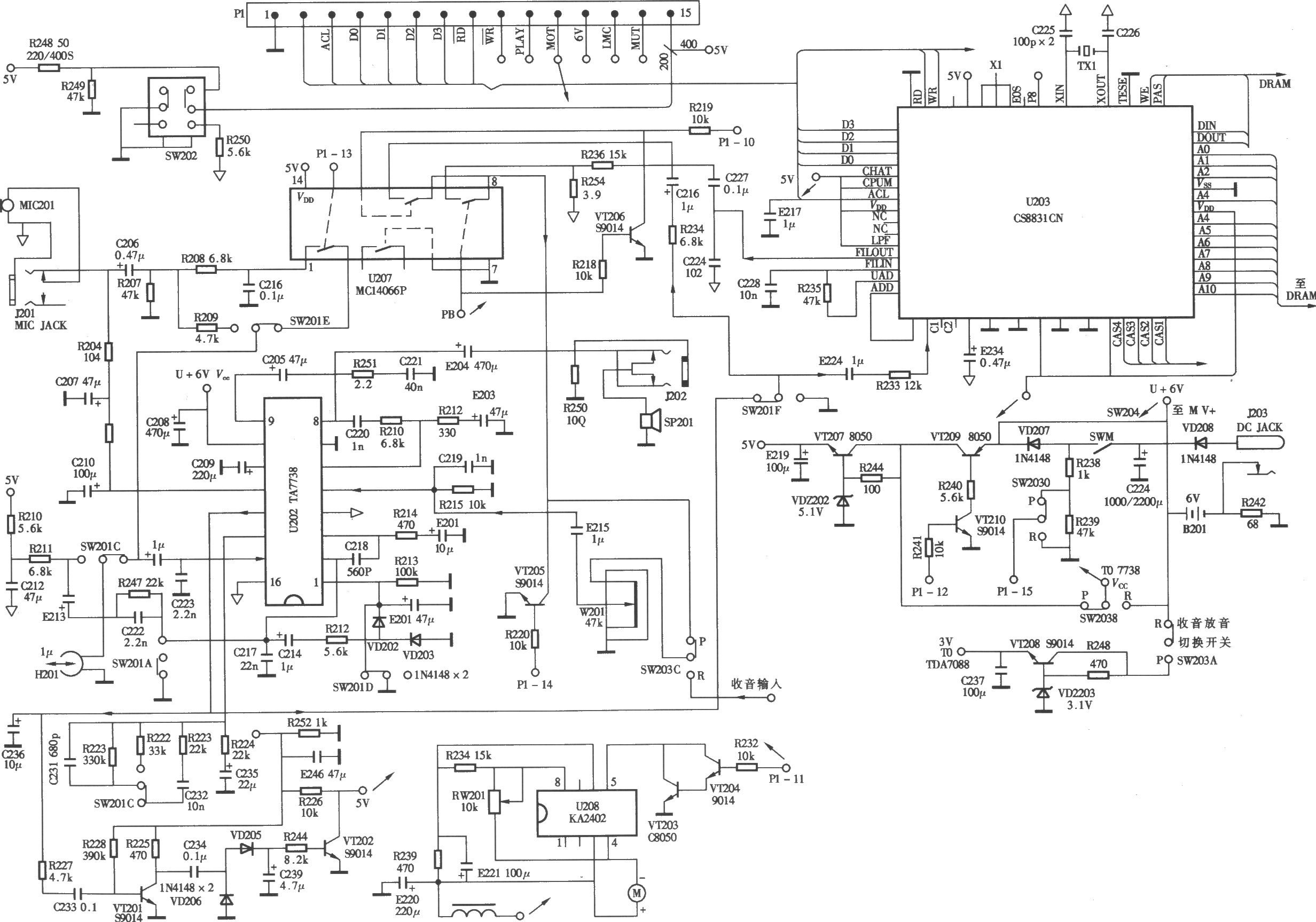
復讀機原理分析
步步高復讀機原理及介紹
步步高復讀機原理及介紹
什么是量子計算機?量子計算機的誕生,人類是否有望被模擬出來?
紐曼U2復讀機:一款多功能的學習機
mp3復讀機BGA芯片底填膠應用






 工商網監
工商網監
評論