 數據挖掘的任務有哪些
數據挖掘的任務有哪些
數據挖掘的任務有哪些
1、關聯分析(associationanalysis)
關聯分析挖掘是由RakeshApwal等人首先提出的。兩個或兩個以上變量取向價值之間存在某種規律性發掘稱之為關聯。數據關聯是數據庫中存在的一類重要的、可被發現的知識。關聯分為簡單關聯、時序關聯和因果關聯。關聯分析的目的是找出數據庫中隱藏的大量關聯網。一般用支持度和可信度兩個閥值來度量獲取關聯規則的相關性,還有興趣度、相關性等參數,使得所挖掘的規則更符合實質需求。
2、聚類分析(clustering)
聚類是把數據按照相似性歸納成若干類別分類出來,同一類中的數據彼此相似,不同類中的數據則相異。聚類分析可以建立宏觀的概念,發布數據的分布模式,以及可能性的數據屬性之間的相互關系。
3、分類(classification)
分類其實就是找出一個類別的概念描述,代表了數據的整體信息,分類的內涵描述,并用描述來構造模型,一般用作于規則或決策樹模式表示出來。分類是利用訓練數據集中通過一定的算法而求得分類規則。分類可被用于規則描述和數據預測。
4、預測(predication)
通過預測利用歷史數據找出變化規律,建立模型并由該模型對未來數據的種類及特征進行預測。預測關心的是精確度和不確定性因素,通常用預測方差來度量較為適合。
通過時間序列搜索出的重復發生概率比較高的模式。與回歸一樣,它也是用己知的數據預測未來的數據值,但這些數據的區別是變量所處時間的不同而已。
6、偏差分析(deviation)
在偏差中包括很多有用的知識,數據庫中的數據存在很多異常情況,發現數據庫中數據存在的異常情況是非常重要的。偏差檢驗的基本方法就是尋找觀察結果與參照之間的差別。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據挖掘
+關注
關注
1文章
406瀏覽量
24208
發布評論請先 登錄
相關推薦
Linux計劃任務介紹
點定時備份數據。比如:11點開啟網站搶購接口,12點關閉網站搶購接口。 3.計劃任務主要分為以下兩種使用情況: 1.系統級別的定時任務: 臨時文件清理、系統信息采集、日志文件切割?2.用戶級別的定時
中科曙光受邀參加第十屆中國數據挖掘會議
近日,國內數據挖掘領域最主要的學術活動之一—第十屆中國數據挖掘會議(CCDM2024)于山東泰安舉行,中科曙光參與并分享了曙光AI構建產學研用的生態實踐。
如何使用freeRTOS在兩個任務之間傳輸任務數據?
和壓力。 I2C 主控器基于其他演示項目\"硬件抽象層 (HAL):I2C 主控器\"
任務 1:盡可能快地讀取傳感器數值
任務 2:將數據寫入 NAND 閃存或 SD 卡
我
發表于 07-03 07:55
用的cube生成的freertos工程,串口和任務通過郵箱通訊,結果任務反應很慢是怎么回事?
用的是DMA+空閑中斷,將接收數組的指針,通過郵箱發送給任務。
任務通過郵箱得到接收數組的指針,然后逐個復制到任務里建立的數組,再通過串口發送出去。
現在結果是上位機發送數據大概七八
發表于 05-08 08:13
FreeRTOS系統使用xTaskCreate產生的任務與osThreadDef 產生的線程有什么不同?
請教下是要 FreeRTOS系統, 使用 xTaskCreate 產生的任務 與 osThreadDef產生的線程有什么不同?
發表于 04-29 07:20
freertos串口接收數據后如何發送給任務?
正在學freertos。串口中斷接收一幀數據后,放到數組里,如何將數據發送給任務呢?
如果用消息隊列,是否建立的消息隊列需要是數組類型的?還是說消息列表建立成uint8類型的,列表長度設為接收
發表于 04-18 06:36
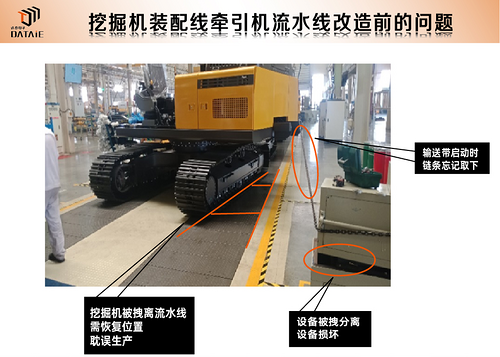
挖掘機生產裝配線無線通訊應用
一、應用背景 山東某挖掘機機械有限公司主要產品有裝載機、挖掘機、道路機械及核心關鍵零部件等系列工程機械產品。為加速新舊動能轉換,全新挖掘機整機裝配線配合勞動組合的調整,提高裝配水平和生
iBeLink KS MAX 10.5T大算力領跑KAS新領域
Kaspa是一種基于DAG(有向無環圖)技術的加的密的貨的幣,它擁有高速、安全、可擴展的特點,是未來區的塊的鏈領域的新星。為了挖掘Kaspa,我們需要一款專門的挖掘機,能夠適應Kaspa的特殊算法
發表于 02-20 16:11
verilog中函數和任務對比
對比,方便學習理解。 比較 函數 任務 輸入 函數至少需要包含一個輸入,端口類型不能包含inout類型 任務可以沒有或者有多個輸入,且端口聲明可以為inout類型 輸出 函數無輸出 任務
數據挖掘的應用領域,并舉例說明
數據挖掘(Data Mining)是一種從大量數據中提取出有意義的信息和模式的技術。它結合了數據庫、統計學、機器學習和人工智能等領域的理論和方法,通過高效的算法和工具,對大
任務調度系統設計的核心邏輯
Redis的讀寫性能極好,分布式鎖也比Quartz數據庫行級鎖更輕量級。當然Redis鎖也可以替換成Zookeeper鎖,也是同樣的機制。
在小型項目中,使用:定時任務框架(Quartz/Spring Schedule)和 分布式鎖(redis/zookeeper)
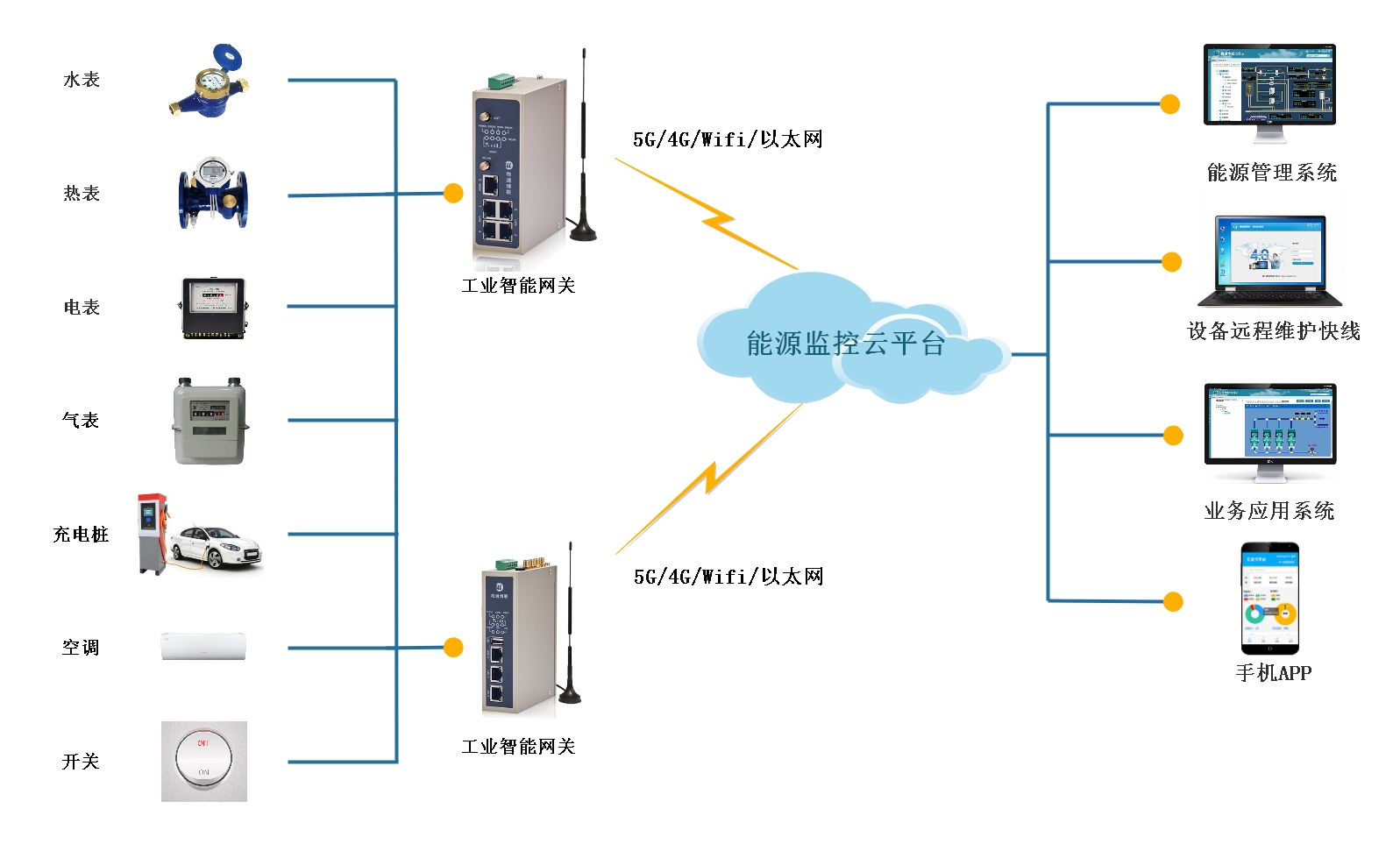
如何通過能源數據管理挖掘智慧樓宇的節能空間
性能的同時優化能耗,對此我們需要了解建筑內各種能源的使用結構、使用時間等信息。對此,物通博聯提供智慧樓宇的能源數據管理系統,實現樓宇內各種能源的數據采集與可視化監控,并建立能源全面數據視圖,幫助確定可以
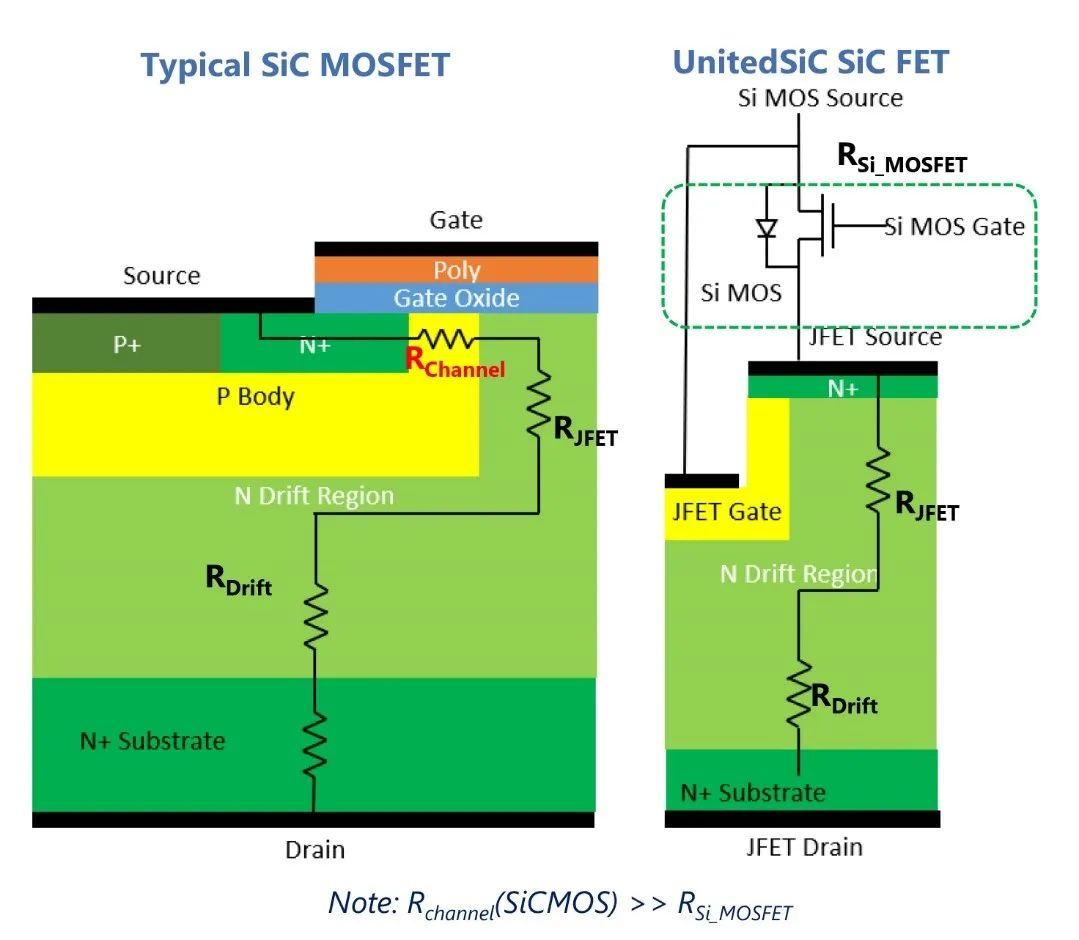
數據挖掘示波器與傳統示波器的區別在哪里?
數據采集方式:傳統示波器通過將模擬信號轉換為數字信號進行采集和顯示。而數據挖掘示波器主要用于數字信號的采集和分析,例如從數字通信系統、傳感器網絡等獲取的數字信號進行處理和分析。
FreeRTOS中的任務管理
任務是 FreeRTOS 中最基本的調度單元,它是一段可執行的代碼,可以獨立運行。FreeRTOS 中的任務是基于優先級的搶占式調度,優先級高的任務可以搶占優先級低的任務的 CPU 資





 工商網監
工商網監
評論