") CPU Cache Line偽共享問(wèn)題的總結(jié)和分析
CPU Cache Line偽共享問(wèn)題的總結(jié)和分析
1. 關(guān)于本文
本文基于 Joe Mario 的一篇博客改編而成。Joe Mario 是 Redhat 公司的 Senior Principal Software Engineer,在系統(tǒng)的性能優(yōu)化領(lǐng)域頗有建樹,他也是本文描述的perf c2c工具的貢獻(xiàn)者之一。這篇博客行文比較口語(yǔ)化,且假設(shè)讀者對(duì) CPU 多核架構(gòu),Cache Memory 層次結(jié)構(gòu),以及 Cache 的一致性協(xié)議有所了解。故此,筆者決定放棄照翻原文,并且基于原博客文章做了一些擴(kuò)展,增加了相關(guān)背景知識(shí)簡(jiǎn)介。本文中若有任何疏漏錯(cuò)誤,責(zé)任在于編譯者。有任何建議和意見,請(qǐng)回復(fù)內(nèi)核月談微信公眾號(hào),或通過(guò) oliver.yang at linux.alibaba.com 反饋。
2. 背景知識(shí)
要搞清楚 Cache Line 偽共享的概念及其性能影響,需要對(duì)現(xiàn)代理器架構(gòu)和硬件實(shí)現(xiàn)有一個(gè)基本的了解。如果讀者已經(jīng)對(duì)這些概念已經(jīng)有所了解,可以跳過(guò)本小節(jié),直接了解 perf c2c 發(fā)現(xiàn) Cache Line 偽共享的方法。(注:本節(jié)中的所有圖片,均來(lái)自與 Google 圖片搜索,版權(quán)歸原作者所有。)
2.1 存儲(chǔ)器層次結(jié)構(gòu)
眾所周知,現(xiàn)代計(jì)算機(jī)體系結(jié)構(gòu),通過(guò)存儲(chǔ)器層次結(jié)構(gòu) (Memory Hierarchy) 的設(shè)計(jì),使系統(tǒng)在性能,成本和制造工藝之間作出取舍,從而達(dá)到一個(gè)平衡。下圖給出了不同層次的硬件訪問(wèn)延遲,可以看到,各個(gè)層次硬件訪問(wèn)延遲存在數(shù)量級(jí)上的差異,越高的性能,往往意味著更高的成本和更小的容量:

通過(guò)上圖,可以對(duì)各級(jí)存儲(chǔ)器 Cache Miss 帶來(lái)的性能懲罰有個(gè)大致的概念。
2.2 多核架構(gòu)
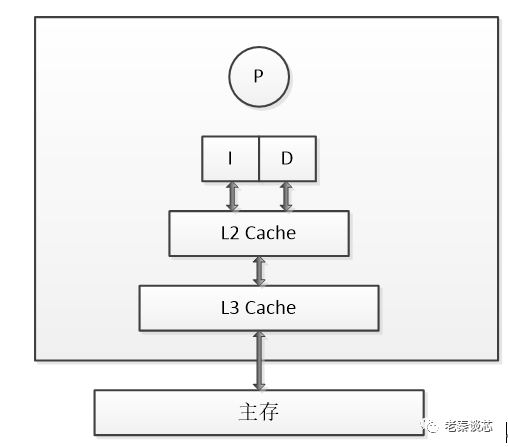
隨著多核架構(gòu)的普及,對(duì)稱多處理器 (SMP) 系統(tǒng)成為主流。例如,一個(gè)物理 CPU 可以存在多個(gè)物理 Core,而每個(gè) Core 又可以存在多個(gè)硬件線程。x86 以下圖為例,1 個(gè) x86 CPU 有 4 個(gè)物理 Core,每個(gè) Core 有兩個(gè) HT (Hyper Thread),
從硬件的角度,上圖的 L1 和 L2 Cache 都被兩個(gè) HT 共享,且在同一個(gè)物理 Core。而 L3 Cache 則在物理 CPU 里,被多個(gè) Core 來(lái)共享。而從 OS 內(nèi)核角度,每個(gè) HT 都是一個(gè)邏輯 CPU,因此,這個(gè)處理器在 OS 來(lái)看,就是一個(gè) 8 個(gè) CPU 的 SMP 系統(tǒng)。
2.3 NUMA 架構(gòu)
一個(gè) SMP 系統(tǒng),按照其 CPU 和內(nèi)存的互連方式,可以分為 UMA (均勻內(nèi)存訪問(wèn)) 和 NUMA (非均勻內(nèi)存訪問(wèn)) 兩種架構(gòu)。其中,在多個(gè)物理 CPU 之間保證 Cache 一致性的 NUMA 架構(gòu),又被稱做 ccNUMA (Cache Coherent NUMA) 架構(gòu)。
以 x86 為例,早期的 x86 就是典型的 UMA 架構(gòu)。例如下圖,四路處理器通過(guò) FSB (前端系統(tǒng)總線) 和主板上的內(nèi)存控制器芯片 (MCH) 相連,DRAM 是以 UMA 方式組織的,延遲并無(wú)訪問(wèn)差異,
然而,這種架構(gòu)帶來(lái)了嚴(yán)重的內(nèi)存總線的性能瓶頸,影響了 x86 在多路服務(wù)器上的可擴(kuò)展性和性能。
因此,從 Nehalem 架構(gòu)開始,x86 開始轉(zhuǎn)向 NUMA 架構(gòu),內(nèi)存控制器芯片被集成到處理器內(nèi)部,多個(gè)處理器通過(guò) QPI 鏈路相連,從此 DRAM 有了遠(yuǎn)近之分。而 Sandybridge 架構(gòu)則更近一步,將片外的 IOH 芯片也集成到了處理器內(nèi)部,至此,內(nèi)存控制器和 PCIe Root Complex 全部在處理器內(nèi)部了。下圖就是一個(gè)典型的 x86 的 NUMA 架構(gòu):
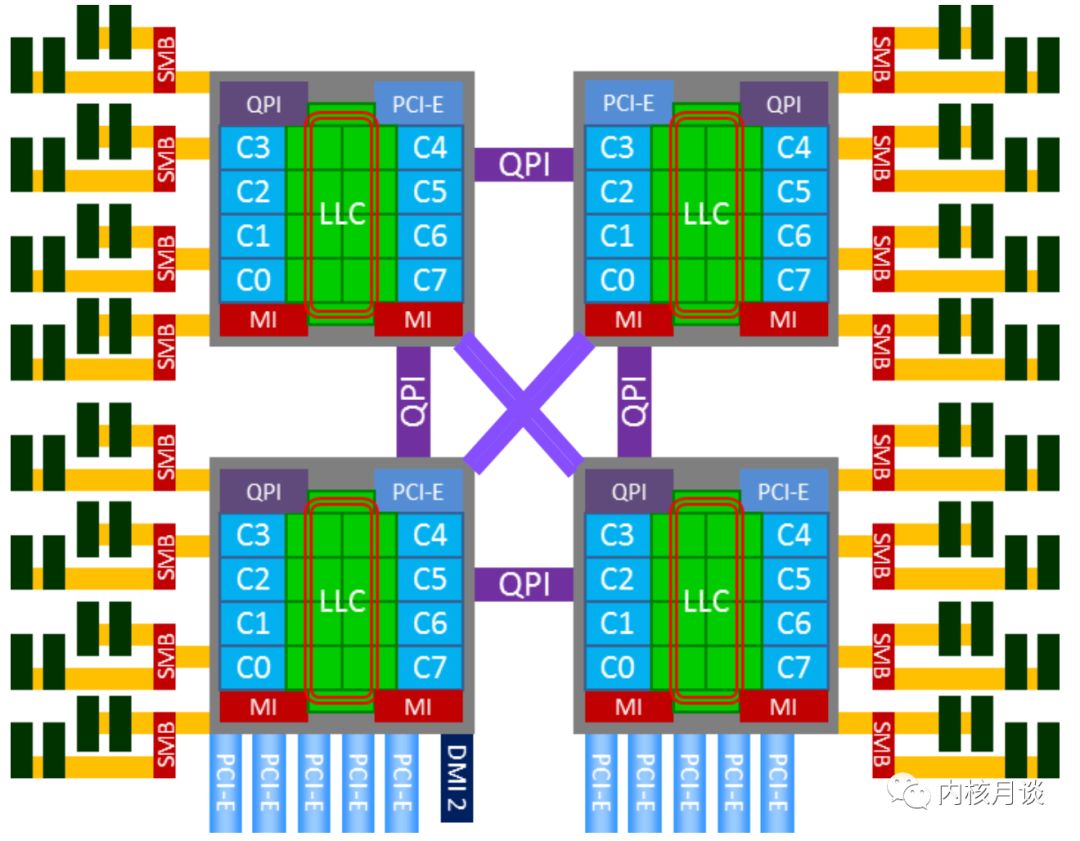
由于 NUMA 架構(gòu)的引入,以下主要部件產(chǎn)生了因物理鏈路的遠(yuǎn)近帶來(lái)的延遲差異:
-
Cache
除物理 CPU 有本地的 Cache 的層級(jí)結(jié)構(gòu)以外,還存在跨越系統(tǒng)總線 (QPI) 的遠(yuǎn)程 Cache 命中訪問(wèn)的情況。需要注意的是,遠(yuǎn)程的 Cache 命中,對(duì)發(fā)起 Cache 訪問(wèn)的 CPU 來(lái)說(shuō),還是被記入了 LLC Cache Miss。
-
DRAM
在兩路及以上的服務(wù)器,遠(yuǎn)程 DRAM 的訪問(wèn)延遲,遠(yuǎn)遠(yuǎn)高于本地 DRAM 的訪問(wèn)延遲,有些系統(tǒng)可以達(dá)到 2 倍的差異。需要注意的是,即使服務(wù)器 BIOS 里關(guān)閉了 NUMA 特性,也只是對(duì) OS 內(nèi)核屏蔽了這個(gè)特性,這種延遲差異還是存在的。
-
Device
對(duì) CPU 訪問(wèn)設(shè)備內(nèi)存,及設(shè)備發(fā)起 DMA 內(nèi)存的讀寫活動(dòng)而言,存在本地 Device 和遠(yuǎn)程 Device 的差別,有顯著的延遲訪問(wèn)差異。
因此,對(duì)以上 NUMA 系統(tǒng),一個(gè) NUMA 節(jié)點(diǎn)通常可以被認(rèn)為是一個(gè)物理 CPU 加上它本地的 DRAM 和 Device 組成。那么,四路服務(wù)器就擁有四個(gè) NUMA 節(jié)點(diǎn)。如果 BIOS 打開了 NUMA 支持,Linux 內(nèi)核則會(huì)根據(jù) ACPI 提供的表格,針對(duì) NUMA 節(jié)點(diǎn)做一系列的 NUMA 親和性的優(yōu)化。
在 Linux 上,numactl --hardware可以返回當(dāng)前系統(tǒng)的 NUMA 節(jié)點(diǎn)信息,特別是 CPU 和 NUMA 節(jié)點(diǎn)的對(duì)應(yīng)信息。
2.4 Cache Line
Cache Line 是 CPU 和主存之間數(shù)據(jù)傳輸?shù)淖钚挝弧.?dāng)一行 Cache Line 被從內(nèi)存拷貝到 Cache 里,Cache 里會(huì)為這個(gè) Cache Line 創(chuàng)建一個(gè)條目。這個(gè) Cache 條目里既包含了拷貝的內(nèi)存數(shù)據(jù),即 Cache Line,又包含了這行數(shù)據(jù)在內(nèi)存里的位置等元數(shù)據(jù)信息。
由于 Cache 容量遠(yuǎn)遠(yuǎn)小于主存,因此,存在多個(gè)主存地址可以被映射到同一個(gè) Cache 條目的情況,下圖是一個(gè) Cache 和主存映射的概念圖:

而這種 Cache 到主存的映射,通常是由內(nèi)存的虛擬或者物理地址的某幾位決定的,取決于 Cache 硬件設(shè)計(jì)是虛擬地址索引,還是物理地址索引。然而,由于索引位一般設(shè)計(jì)為低地址位,通常在物理頁(yè)的頁(yè)內(nèi)偏移以內(nèi),因此,不論是內(nèi)存虛擬或者物理地址,都可以拿來(lái)判斷兩個(gè)內(nèi)存地址,是否在同一個(gè) Cache Line 里。
Cache Line 的大小和處理器硬件架構(gòu)有關(guān)。在 Linux 上,通過(guò)getconf就可以拿到 CPU 的 Cache Line 的大小,

2.5 Cache 的結(jié)構(gòu)
前面 Linuxgetconf命令的輸出,除了*_LINESIZE指示了系統(tǒng)的 Cache Line 的大小是 64 字節(jié)外,還給出了 Cache 類別,大小。其中*_ASSOC則指示了該 Cache 是幾路關(guān)聯(lián) (Way Associative) 的。
下圖很好的說(shuō)明了 Cache 在 CPU 里的真正的組織結(jié)構(gòu),

一個(gè)主存的物理或者虛擬地址,可以被分成三部分:高地址位當(dāng)作 Cache 的 Tag,用來(lái)比較選中多路 (Way) Cache 中的某一路 (Way),而低地址位可以做 Index,用來(lái)選中某一個(gè) Cache Set。在某些架構(gòu)上,最低的地址位,Block Offset 可以選中在某個(gè) Cache Line 中的某一部份。
因此,Cache Line 的命中,完全依靠地址里的 Tag 和 Index 就可以做到。關(guān)于 Cache 結(jié)構(gòu)里的 Way,Set,Tag 的概念,請(qǐng)參考相關(guān)文檔或者資料。這里就不再贅述。
2.6 Cache 一致性
如前所述,在 SMP 系統(tǒng)里,每個(gè) CPU 都有自己本地的 Cache。因此,同一個(gè)變量,或者同一行 Cache Line,有在多個(gè)處理器的本地 Cache 里存在多份拷貝的可能性,因此就存在數(shù)據(jù)一致性問(wèn)題。通常,處理器都實(shí)現(xiàn)了 Cache 一致性 (Cache Coherence)協(xié)議。如歷史上 x86 曾實(shí)現(xiàn)了MESI協(xié)議以及MESIF協(xié)議。
假設(shè)兩個(gè)處理器 A 和 B, 都在各自本地 Cache Line 里有同一個(gè)變量的拷貝時(shí),此時(shí)該 Cache Line 處于Shared狀態(tài)。當(dāng)處理器 A 在本地修改了變量,除去把本地變量所屬的 Cache Line 置為Modified狀態(tài)以外,還必須在另一個(gè)處理器 B 讀同一個(gè)變量前,對(duì)該變量所在的 B 處理器本地 Cache Line 發(fā)起 Invaidate 操作,標(biāo)記 B 處理器的那條 Cache Line 為Invalidate狀態(tài)。隨后,若處理器 B 在對(duì)變量做讀寫操作時(shí),如果遇到這個(gè)標(biāo)記為Invalidate的狀態(tài)的 Cache Line,即會(huì)引發(fā) Cache Miss,從而將內(nèi)存中最新的數(shù)據(jù)拷貝到 Cache Line 里,然后處理器 B 再對(duì)此 Cache Line 對(duì)變量做讀寫操作。
本文中的 Cache Line 偽共享場(chǎng)景,就基于上述場(chǎng)景來(lái)講解,關(guān)于 Cache 一致性協(xié)議更多的細(xì)節(jié),請(qǐng)參考相關(guān)文檔。
2.7 Cache Line 偽共享
Cache Line 偽共享問(wèn)題,就是由多個(gè) CPU 上的多個(gè)線程同時(shí)修改自己的變量引發(fā)的。這些變量表面上是不同的變量,但是實(shí)際上卻存儲(chǔ)在同一條 Cache Line 里。在這種情況下,由于 Cache 一致性協(xié)議,兩個(gè)處理器都存儲(chǔ)有相同的 Cache Line 拷貝的前提下,本地 CPU 變量的修改會(huì)導(dǎo)致本地 Cache Line 變成Modified狀態(tài),然后在其它共享此 Cache Line 的 CPU 上,引發(fā) Cache Line 的 Invaidate 操作,導(dǎo)致 Cache Line 變?yōu)镮nvalidate狀態(tài),從而使 Cache Line 再次被訪問(wèn)時(shí),發(fā)生本地 Cache Miss,從而傷害到應(yīng)用的性能。在此場(chǎng)景下,多個(gè)線程在不同的 CPU 上高頻反復(fù)訪問(wèn)這種 Cache Line 偽共享的變量,則會(huì)因 Cache 顛簸引發(fā)嚴(yán)重的性能問(wèn)題。
下圖即為兩個(gè)線程間的 Cache Line 偽共享問(wèn)題的示意圖,

3. Perf c2c 發(fā)現(xiàn)偽共享
當(dāng)應(yīng)用在 NUMA 環(huán)境中運(yùn)行,或者應(yīng)用是多線程的,又或者是多進(jìn)程間有共享內(nèi)存,滿足其中任意一條,那么這個(gè)應(yīng)用就可能因?yàn)?Cache Line 偽共享而性能下降。
但是,要怎樣才能知道一個(gè)應(yīng)用是不是受偽共享所害呢?Joe Mario 提交的 patch 能夠解決這個(gè)問(wèn)題。Joe 的 patch 是在 Linux 的著名的 perf 工具上,添加了一些新特性,叫做 c2c,意思是“緩存到緩存” (cache-2-cache)。
Redhat 在很多 Linux 的大型應(yīng)用上使用了 c2c 的原型,成功地發(fā)現(xiàn)了很多熱的偽共享的 Cache Line。Joe 在博客里總結(jié)了一下perf c2c的主要功能:
-
發(fā)現(xiàn)偽共享的 Cache Line
-
誰(shuí)在讀寫上述的 Cache Line,以及訪問(wèn)發(fā)生處的 Cache Line 的內(nèi)部偏移
-
這些讀者和寫者分別的 pid, tid, 指令地址,函數(shù)名,二進(jìn)制文件
-
每個(gè)讀者和寫者的源代碼文件,代碼行號(hào)
-
這些熱點(diǎn) Cache Line 上的,load 操作的平均延遲
-
這些 Cache Line 的樣本來(lái)自哪些 NUMA 節(jié)點(diǎn), 由哪些 CPU 參與了讀寫
perf c2c和perf里現(xiàn)有的工具比較類似:
-
先用perf c2c record通過(guò)采樣,收集性能數(shù)據(jù)
-
再用perf c2c report基于采樣數(shù)據(jù),生成報(bào)告
如果想了解perf c2c的詳細(xì)使用,請(qǐng)?jiān)L問(wèn):PERF-C2C(1)
這里還有一個(gè)完整的perf c2c的輸出的樣例。
最后,還有一個(gè)小程序的源代碼,可以產(chǎn)生大量的 Cache Line 偽共享,用以測(cè)試體驗(yàn):Fasle sharing .c src file
3.1 perf c2c 的輸出
下面,讓我們就之前給出的perf c2c的輸出樣例,做一個(gè)詳細(xì)介紹。
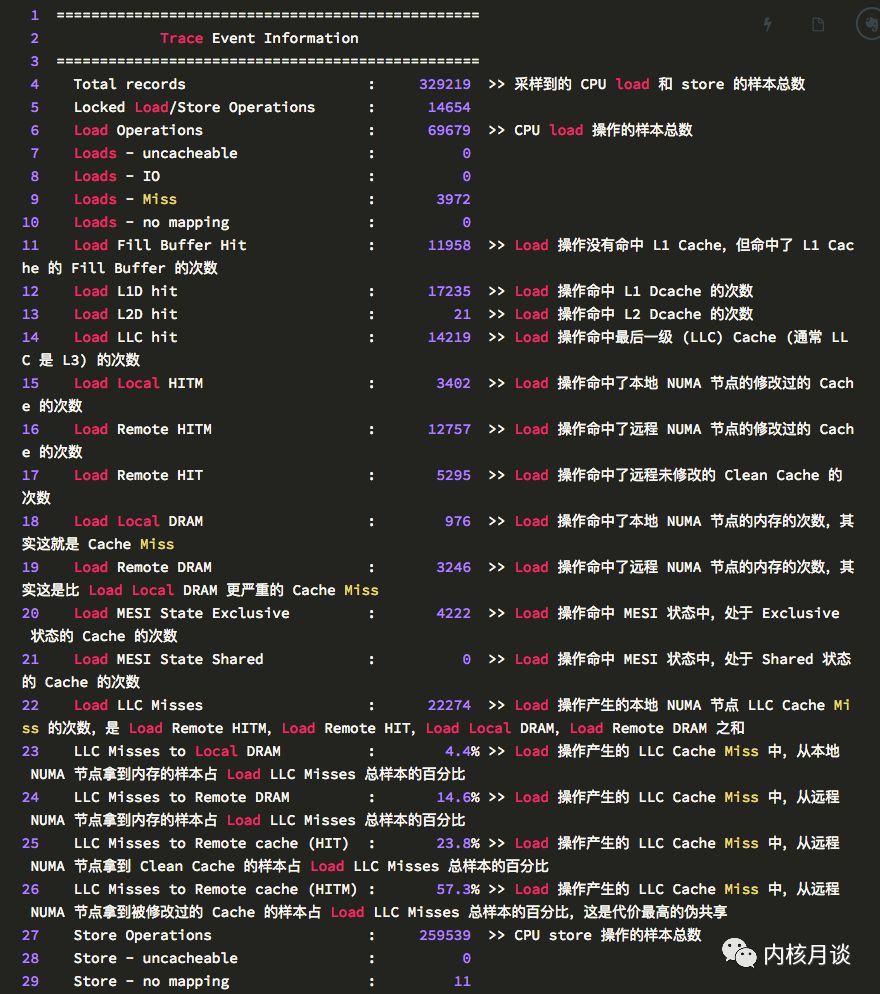
輸出里的第一個(gè)表,概括了 CPU 在perf c2c數(shù)據(jù)采樣期間做的 load 和 store 的樣本。能夠看到 load 操作都是在哪里取到了數(shù)據(jù)。
在perf c2c輸出里,HITM意為 “Hit In The Modified”,代表 CPU 在 load 操作命中了一條標(biāo)記為Modified狀態(tài)的 Cache Line。如前所述,偽共享發(fā)生的關(guān)鍵就在于此。
而Remote HITM,意思是跨 NUMA 節(jié)點(diǎn)的HITM,這個(gè)是所有 load 操作里代價(jià)最高的情況,尤其在讀者和寫者非常多的情況下,這個(gè)代價(jià)會(huì)變得非常的高。
對(duì)應(yīng)的,Local HITM,則是本地 NUMA 節(jié)點(diǎn)內(nèi)的HITM,下面是對(duì)perf c2c輸出的詳細(xì)注解:
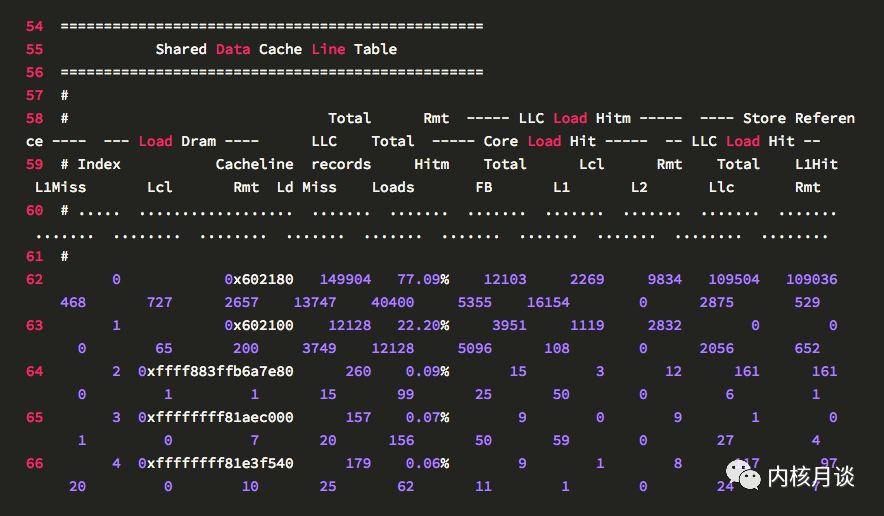
perf c2c輸出的第二個(gè)表, 以 Cache Line 維度,全局展示了 CPU load 和 store 活動(dòng)的情況。這個(gè)表的每一行是一條 Cache Line 的數(shù)據(jù),顯示了發(fā)生偽共享最熱的一些 Cache Line。默認(rèn)按照發(fā)生Remote HITM的次數(shù)比例排序,改下參數(shù)也可以按照發(fā)生Local HITM的次數(shù)比例排序。
要檢查 Cache Line 偽共享問(wèn)題,就在這個(gè)表里找Rmt LLC Load HITM(即跨 NUMA 節(jié)點(diǎn)緩存里取到數(shù)據(jù)的)次數(shù)比較高的,如果有,就得深挖一下。
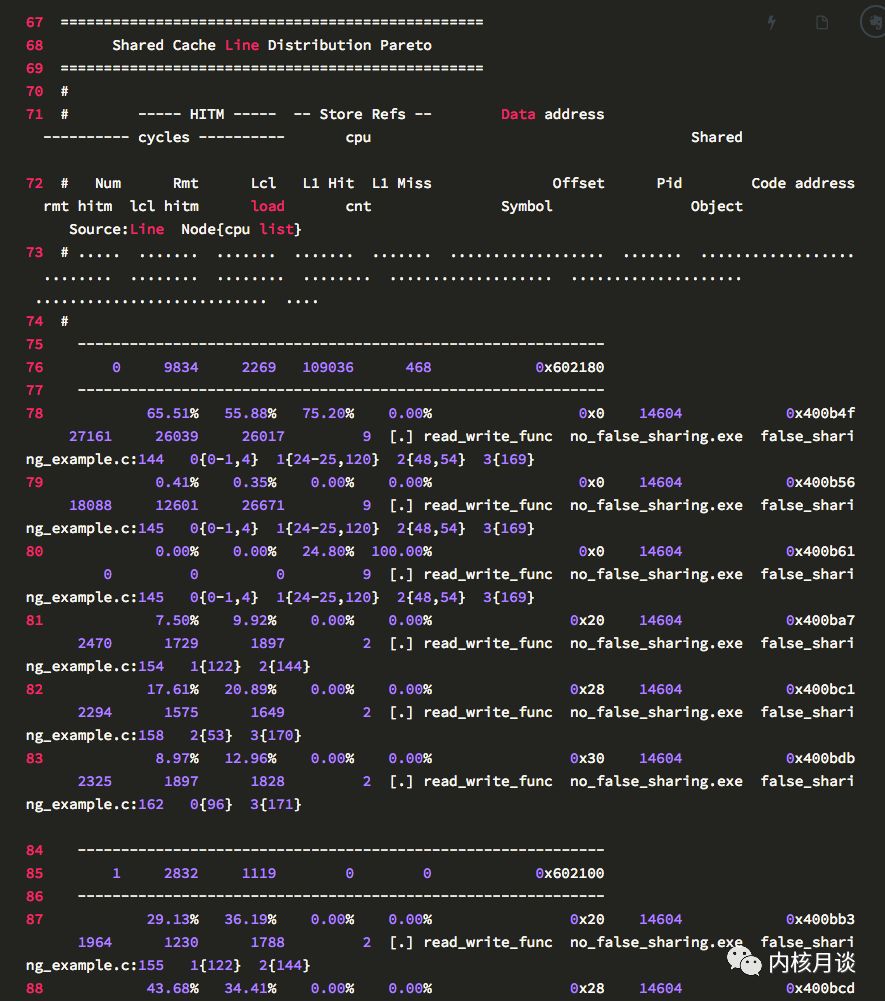
這是最重要的一個(gè)表。為了精簡(jiǎn),這里只展示了三條 Cache Line 相關(guān)的記錄,表格里包含了這些信息:
-
其中 71,72 行是列名,每列都解釋了Cache Line的一些活動(dòng)。
-
標(biāo)號(hào)為 76,85,91 的行顯示了每條 Cache Line 的HITM和 store 活動(dòng)情況: 依次是 CPU load 和 store 活動(dòng)的計(jì)數(shù),以及 Cache Line 的虛擬地址。
-
78 到 83 行,是針對(duì) 76 行 Cache Line 訪問(wèn)的細(xì)目統(tǒng)計(jì),具體格式如下:
-
首先是百分比分布,包含了 HITM 中 remote 和 local 的百分比,store 里的 L1 Hit 和 Miss 的百分比分布。注意,這些百分比縱列相加正好是 100%。
-
然后是數(shù)據(jù)地址列。上面提到了 76 行顯示了 Cache Line 的虛擬地址,而下面幾行的這一列則是行內(nèi)偏移。
-
下一列顯示了pid,或線程id(如果設(shè)置了要輸出tid)。
-
接下來(lái)是指令地址。
-
接下來(lái)三列,展示了平均load操作的延遲。我常看著里有沒(méi)有很高的平均延遲。這個(gè)平均延遲,可以反映該行的競(jìng)爭(zhēng)緊張程度。
-
cpu cnt列展示了該行訪問(wèn)的樣本采集自多少個(gè)cpu。
-
然后是函數(shù)名,二進(jìn)制文件名,源代碼名,和代碼行數(shù)。
-
最后一列展示了對(duì)于每個(gè)節(jié)點(diǎn),樣本分別來(lái)自于哪些cpu
-
以下為樣例輸出:
3.2 如何用perf c2c
下面是常見的perf c2c使用的命令行:

熟悉perf的讀者可能已經(jīng)注意到,這里的-F選項(xiàng)指定了非常高的采樣頻率: 60000。請(qǐng)?zhí)貏e注意:這個(gè)采樣頻率不建議在線上或者生產(chǎn)環(huán)境使用,因?yàn)檫@會(huì)在高負(fù)載機(jī)器上帶來(lái)不可預(yù)知的影響。此外perf c2c對(duì) CPU load 和 store 操作的采樣會(huì)不可避免的影響到被采樣應(yīng)用的性能,因此建議在研發(fā)測(cè)試環(huán)境使用perf c2c去優(yōu)化應(yīng)用。
對(duì)采樣數(shù)據(jù)的分析,可以使用帶圖形界面的 tui 來(lái)看輸出,或者只輸出到標(biāo)準(zhǔn)輸出

默認(rèn)情況,為了規(guī)范輸出格式,符號(hào)名被截?cái)酁槎ㄩL(zhǎng),但可以用 “–full-symbols” 參數(shù)來(lái)顯示完整符號(hào)名。
例如:
3.3 找到 Cache Line 訪問(wèn)的調(diào)用棧
有的時(shí)候,很需要找到讀寫這些 Cache Line 的調(diào)用者是誰(shuí)。下面是獲得調(diào)用圖信息的方法。但一開始,一般不會(huì)一上來(lái)就用這個(gè),因?yàn)檩敵鎏啵y以定位偽共享。一般都是先找到問(wèn)題,再回過(guò)頭來(lái)使用調(diào)用圖。
3.4 如何增加采樣頻率
為了讓采樣數(shù)據(jù)更可靠,會(huì)把perf采樣頻率提升到-F 60000或者-F 80000,而系統(tǒng)默認(rèn)的采樣頻率是 1000。
提升采樣頻率,可以短時(shí)間獲得更豐富,更可靠的采樣集合。想提升采樣頻率,可以用下面的方法。可以根據(jù)dmesg里有沒(méi)有perf interrupt took too long …信息來(lái)調(diào)整頻率。注意,如前所述,這有一定風(fēng)險(xiǎn),嚴(yán)禁在線上或者生產(chǎn)環(huán)境使用。
然后運(yùn)行前面講的perf c2c record命令。之后再運(yùn)行,
3.5 如何讓避免采樣數(shù)據(jù)過(guò)量
在大型系統(tǒng)上(比如有 4,8,16 個(gè)物理 CPU 插槽的系統(tǒng))運(yùn)行perf c2c,可能會(huì)樣本太多,消耗大量的CPU時(shí)間,perf.data文件也可能明顯變大。 對(duì)于這個(gè)問(wèn)題,有以下建議(包含但不僅限于):
-
將ldlat從 30 增加大到 50。這使得perf跳過(guò)沒(méi)有性能問(wèn)題的 load 操作。
-
降低采樣頻率。
-
縮短perf record的睡眠時(shí)間窗口。比如,從sleep 5改成sleep 3。
3.6 使用 c2c 優(yōu)化應(yīng)用的收獲
一般搭建看見性能工具的輸出,都會(huì)問(wèn)這些數(shù)據(jù)意味著什么。Joe 總結(jié)了他使用c2c優(yōu)化應(yīng)用時(shí),學(xué)到的東西,
-
perf c2c采樣時(shí)間不宜過(guò)長(zhǎng)。Joe 建議運(yùn)行perf c2c3 秒、5 秒或 10 秒。運(yùn)行更久,觀測(cè)到的可能就不是并發(fā)的偽共享,而是時(shí)間錯(cuò)開的 Cache Line 訪問(wèn)。
-
如果對(duì)內(nèi)核樣本沒(méi)有興趣,只想看用戶態(tài)的樣本,可以指定--all-user。反之使用--all-kernel。
-
CPU 很多的系統(tǒng)上(如 >148 個(gè)),設(shè)置-ldlat為一個(gè)較大的值(50 甚至 70),perf可能能產(chǎn)生更豐富的C2C樣本。
-
讀最上面那個(gè)具有概括性的Trace Event表,尤其是LLC Misses to Remote cache HITM的數(shù)字。只要不是接近 0,就可能有值得追究的偽共享。
-
看Pareto表時(shí),需要關(guān)注的,多半只是最熱的兩三個(gè) Cache Line。
-
有的時(shí)候,一段代碼,它不在某一行 Cache Line 上競(jìng)爭(zhēng)嚴(yán)重,但是它卻在很多 Cache Line 上競(jìng)爭(zhēng),這樣的代碼段也是很值得優(yōu)化的。同理還有多進(jìn)程程序訪問(wèn)共享內(nèi)存時(shí)的情況。
-
在Pareto表里,如果發(fā)現(xiàn)很長(zhǎng)的 load 操作平均延遲,常常就表明存在嚴(yán)重的偽共享,影響了性能。
-
接下來(lái)去看樣本采樣自哪些節(jié)點(diǎn)和 CPU,據(jù)此進(jìn)行優(yōu)化,將哪些內(nèi)存或 Task 進(jìn)行 NUMA 節(jié)點(diǎn)鎖存。
最后,Pareto表還能對(duì)怎么解決對(duì)齊得很不好的Cache Line,提供靈感。 例如:
-
很容易定位到:寫地很頻繁的變量,這些變量應(yīng)該在自己獨(dú)立的 Cache Line。可以據(jù)此進(jìn)行對(duì)齊調(diào)整,讓他們不那么競(jìng)爭(zhēng),運(yùn)行更快,也能讓其它的共享了該 Cache Line 的變量不被拖慢。
-
很容易定位到:沒(méi)有 Cache Line 對(duì)齊的,跨越了多個(gè) Cache Line 的熱的 Lock 或 Mutex。
-
很容易定位到:讀多寫少的變量,可以將這些變量組合到相同或相鄰的 Cache Line。
3.7 使用原始的采樣數(shù)據(jù)
有時(shí)直接去看用perf c2c record命令生成的perf.data文件,其中原始的采樣數(shù)據(jù)也是有用的。可以用perf script命令得到原始樣本,man perf-script可以查看這個(gè)命令的手冊(cè)。輸出可能是編碼過(guò)的,但你可以按load weight排序(第 5 列),看看哪個(gè) load 樣本受偽共享影響最嚴(yán)重,有最大的延遲。
-
處理器
+關(guān)注
關(guān)注
68文章
19160瀏覽量
229119 -
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7452瀏覽量
163605 -
cpu
+關(guān)注
關(guān)注
68文章
10825瀏覽量
211146
原文標(biāo)題:CPU Cache Line偽共享問(wèn)題的總結(jié)和分析
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
cpu與cache內(nèi)存交互的過(guò)程
多核DSP共享空間CACHE問(wèn)題
關(guān)于cache和cache_line的一個(gè)概念問(wèn)題
為什么需要cache?cache是如何影響code的呢
嵌入式CPU指令Cache的設(shè)計(jì)與實(shí)現(xiàn)
淺談tms320c6748最小系統(tǒng)設(shè)計(jì)和cache配置
CPU是如何調(diào)度任務(wù)的?
cache的排布與CPU的典型分布
CPU Cache偽共享問(wèn)題
CPU設(shè)計(jì)之Cache存儲(chǔ)器
CPU CACHE策略的初始化
多個(gè)CPU各自的cache同步問(wèn)題





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論