 基于條件概率分類的兩種模型算法:logistic回歸模型與最大熵模型。
基于條件概率分類的兩種模型算法:logistic回歸模型與最大熵模型。
條件概率是機器學習模型的一種表現形式,應用這一模型,對于給定的輸入X,得到各輸出類的概率,選擇最大概率的類為輸出類,如下圖:

本文介紹基于條件概率分類的兩種模型算法:邏輯斯蒂(logistic)回歸與最大熵模型,其中,logistic回歸模型和最大熵模型分別是基于最大似然函數和熵來估計模型P(y|x)。公眾號已有logistic回歸模型的文章介紹,本文重點分析最大熵模型算法。
目錄
1. 最大熵模型算法
2. 最大熵模型例子
4. logsitic回歸模型算法
5. 總結
1.最大熵模型算法
熵是衡量隨機變量不確定性的指標,熵越大,隨機變量的不確定性亦越大。假設X是一個離散型隨機變量,其概率分布為:
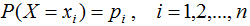
隨機變量X的熵定義為:
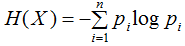
熵滿足下列不等式:

式中,|X|是x的取值個數,當且僅當X的分布是均勻分布時,右邊的等號成立,也就是說,當X服從均勻分布時,熵最大。
1.1 最大熵模型的定義
最大熵原理是概率模型學習的一個準則,最大熵原理認為,學習概率模型時,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。條件概率是機器學習模型的一種表現形式,學習該模型的一種方法是最大化該條件概率的熵,即最大化下式:

其中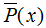 表示變量X的經驗分布:
表示變量X的經驗分布:
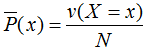
其中v(X=x)表示訓練數據中輸入x出現的頻數,N表示樣本容量。
(1)式的未知變量 就是需要學習的模型。
就是需要學習的模型。
我們在構建分類模型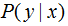 的過程中假設訓練數據集的聯合概率分布與真實模型的聯合概率分布相等,這一假設用特征函數f(x,y)的期望來描述,特征函數的定義:
的過程中假設訓練數據集的聯合概率分布與真實模型的聯合概率分布相等,這一假設用特征函數f(x,y)的期望來描述,特征函數的定義:

特征函數f(x,y)關于訓練數據集的聯合概率分布的期望值,用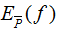 表示:
表示:
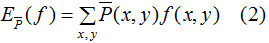
其中,
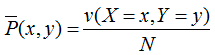
,v(X=x,Y=y)表示訓練數據中樣本(x,y)出現的頻數。
特征函數f(x,y)關于模型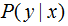 與經驗分布
與經驗分布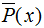 的期望值,用
的期望值,用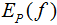 表示:
表示:

假設兩者期望相等,即:

或

結合(1)(4)式,得到最大熵模型:
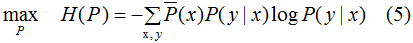
約束條件:
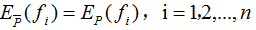
1.2 最大熵模型的學習
我們求解(5)式在約束條件下的最大值,其對應的模型P(Y|X)就是所學習的最優模型。
對于給定的訓練數據集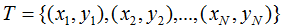 以及特征函數
以及特征函數 ,i=1,2,...,n,最大熵模型的學習等價于約束最優化問題:
,i=1,2,...,n,最大熵模型的學習等價于約束最優化問題:

將最大值問題轉化為等價的求最小值問題:
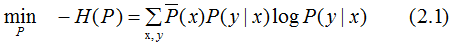
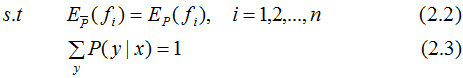
引入拉格朗日乘子 將約束的最優化問題轉換為無約束最優化的對偶問題,通過求解對偶問題求解原始問題。
將約束的最優化問題轉換為無約束最優化的對偶問題,通過求解對偶問題求解原始問題。
定義拉格朗日函數L(P,w):
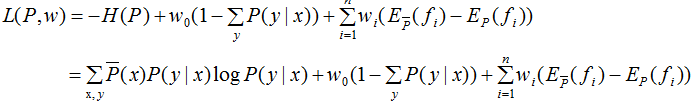
最優化的原始問題:
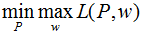
對偶問題:

令

得:
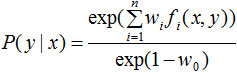
由于 ,對上式進行歸一化得:
,對上式進行歸一化得:
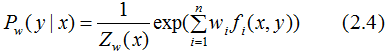
其中,
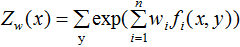
令
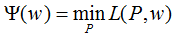
易知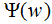 對偶問題外部的極大化問題:
對偶問題外部的極大化問題:
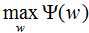
根據上式求解的 代入(2.4)式,得到最終的學習模型P(y|x)。
代入(2.4)式,得到最終的學習模型P(y|x)。
2. 最大熵模型例子
假設隨機變量Y有5個取值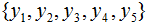 ,假設隨機變量Y的條件概率分布滿足如下條件:
,假設隨機變量Y的條件概率分布滿足如下條件:
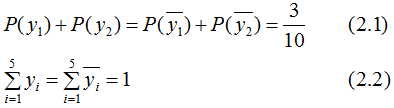
求最大熵模型對應的概率分布P(Y)。
最大熵模型的目標函數:
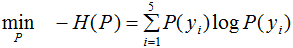
引進拉格朗日乘子 ,定義拉格朗日函數:
,定義拉格朗日函數:
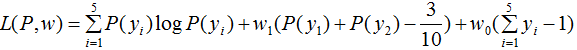
令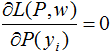 ,得:
,得:
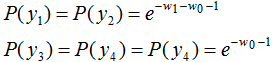
將上式代入函數L(P,w)得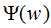 ,令
,令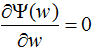 ,得:
,得:
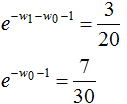
于是最大熵模型對應的概率分布:
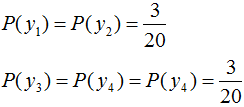
3. 熵模型在信號檢測的應用
由第一節我們知道,熵是描述事物不確定性的指標。我們將熵的這一性質應用在信號檢測領域,當信號包含了較強的隨機噪聲時或被噪聲完全掩蓋時,信號的隨機性大大的增加了,其對應的熵也較大,根據這一原理對信號的質量進行檢測,下圖是用熵檢測心電信號質量的效果圖:

黑色表示較好的心電信號質量,紅色表示較差的心電信號質量。
4. logistic回歸算法
logistic回歸是一種概率分類模型,對于二分類任務來說,其條件概率分布:

我們用最小化損失函數去估計上式的模型參數。對于給定的訓練數據集 ,其中,
,其中,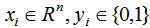 。
。
設:
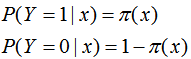
似然函數為:

對數似然函數為:
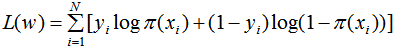
損失函數為:
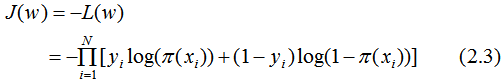
用梯度下降法求解w的估計值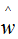 :
:

代入(2.1)(2.2)式,得到邏輯斯蒂回歸模型P(y|x),其中向量包含了b值。
5. 小結
本文介紹基于條件概率分類的兩種模型算法:logistic回歸模型與最大熵模型,其中,logistic回歸模型是基于最大似然函數估計模型P(y|x),最大熵模型是基于熵這一指標估計模型P(y|x)。
-
模型
+關注
關注
1文章
3178瀏覽量
48730 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444 -
Logistic
+關注
關注
0文章
11瀏覽量
8847
原文標題:最大熵模型算法總結
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
回歸算法有哪些,常用回歸算法(3種)詳解
使用KNN進行分類和回歸
LTL概率模型檢驗工具的實現與優化
基于Wasserstein距離概率分布模型的非線性降維算法
基于概率主題模型的景點主題模型
掌握logistic regression模型,有必要先了解線性回歸模型和梯度下降法
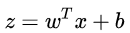
如何使用概率模型進行非均勻數據聚類算法的設計介紹
基于交叉熵算法的跟馳模型標定






 工商網監
工商網監
評論