 開源鑒黃AI新鮮出爐:代碼+預訓練模型,附手把手入門教學
開源鑒黃AI新鮮出爐:代碼+預訓練模型,附手把手入門教學
要入門機器學習,一個自己感興趣又有豐富數據的領域再好不過了。
今天我們就來學習用Keras構建模型,識別NSFW圖片,俗稱造個鑒黃AI。
資源來自一名印度小哥Praneeth Bedapudi,涉及圖像分類和目標檢測兩個科目。他在GitHub上最新發布了NudeNet項目,包含代碼和兩個預訓練模型:負責識別露不露的圖像分類模型和負責找出關鍵部位(以便打碼)的目標檢測模型。
圖像分類模型很簡單,能區分兩個類別:nude和safe,也就是露和不露,堪比經典的hotdog/not hotdog。
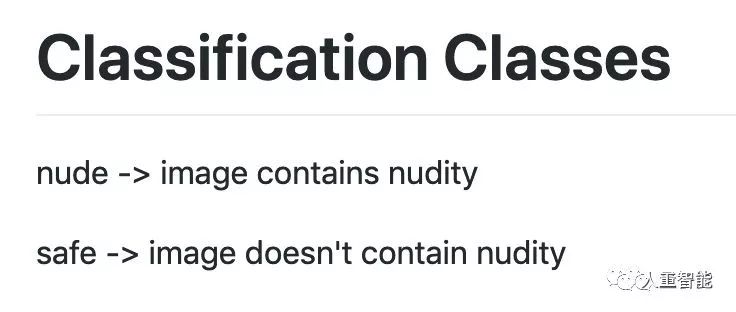
目標檢測模型則能檢測6個類別:不分性別的腹部、臀部,和區分了性別的不可描述部位。

資源鏈接全在文末,我們先來學習一番。
圖像分類從數據集開始
構建一個圖像二分類模型,需要數據集當然也要包含兩類圖像。所以,第一項任務就是分別搜集露的圖片(nude)和不露的圖片(safe)。
不安全的nude圖片來自三處:
一是用RipMe從website scrolller下載,這些圖片來自Reddit論壇的各種NSFW板塊;
圖片來源:https://scrolller.com/nsfw(打開請慎重)
下載工具:https://github.com/RipMeApp/ripme
二是P站的縮略圖。引入這些縮略圖是為了平衡圖片質量——上邊的的Reddit圖片質量太高了,而一個鑒黃AI,在現實中遇到的圖片大多是渣品質,這就需要分辨率很低的縮略圖來平衡。
三是之前廣為流傳的同類數據集,來自alexkimxyz。
原數據集的5個類別,被映射到現在的兩類之中。hentai和porn屬于nude,而drawings、neutral和sexy屬于safe。
搜集好數據之后,進行標準化和去重:
#Resizingandremovingduplicatesmogrify-geometryx320*fdupes-rdN./
最終得到的不安全圖片1,78,601張P站圖片、1,21,644張Reddit圖片和1,30,266張前輩數據集圖片。
安全的圖片則有三個來源,一是alexkimxyz數據集中的普通圖片;二是Facebook資料;三是Reddit論壇上那些老少皆宜的板塊。
為什么已經有了現成的數據集,還需要去后兩個來源抓取呢?
因為小哥發現,前輩收集的安全圖片,有很多根本就不包含人。用這樣的數據訓練,模型很可能學到錯誤的特征,沒學會判斷“露不露”,直接變成了一個“有沒有人”分類器。
最終得到的安全圖片中,有68,948張來自Facebook資料、98,359張來自前輩數據集、55,137張來自Reddit。
數據收集完畢,接下來要進行數據增強。這里用的是Augmentor和Keras自帶的fit_generator。
Augmentor地址:https://github.com/mdbloice/Augmentor
使用的代碼如下:
#Randomrotation,flips,zoom,distortion,contrast,skewandbrightnesspipeline.rotate(probability=0.2,max_left_rotation=20,max_right_rotation=20)pipeline.flip_left_right(probability=0.4)pipeline.flip_top_bottom(probability=0.8)pipeline.zoom(probability=0.2,min_factor=1.1,max_factor=1.5)pipeline.random_distortion(probability=0.2,grid_width=4,grid_height=4,magnitude=8)pipeline.random_brightness(probability=0.2,min_factor=0.5,max_factor=3)pipeline.random_color(probability=0.2,min_factor=0.5,max_factor=3)pipeline.random_contrast(probability=0.2,min_factor=0.5,max_factor=3)pipeline.skew(probability=0.2,magnitude=0.4)
訓練與評估
小哥為這個任務選擇了谷歌出品的Xception模型,直接從Keras使用,輸入256x256尺寸的圖片,批次大小設為32。
而訓練的設備,是從vast.ai租來的云服務器,帶一塊GTX 1080Ti顯卡。
Keras提供的圖像分類模型有個問題:不帶正則化。所以,還要用下面的代碼,為每一層加上正則化(dropout或L2)。
#Forl2forlayerinmodel.layers:layer.W_regularizer=l2(..)#OrfordropoutadddropoutbetweenthefullyconnectedlayersandredefinethemodelusingfunctionalAPI.
使用SGD with momentum訓練,模型可以在alexkimxyz數據集上收斂到0.9347的準確率。
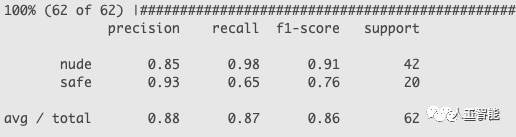
訓練完成后,他選擇了Towards Data Science之前構建的一個測試集來測試模型性能。
測試集:https://drive.google.com/drive/folders/18SY4oyZgTD_dh8-dc0wmsl1GvMsA7woY
測試成績如下:
目標檢測還是從數據集開始
訓練目標檢測模型需要的數據集,和圖片分類可不一樣。分類只需要圖片和類別,而目標檢測需要的,是用邊界框標注了某樣東西位置的圖片。
因此,上邊講過的數據集不能用了,新科目的數據集來自Jae Jin的團隊,包含5789張圖片,各種標注的分布如下:
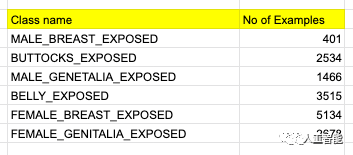
其實也就是模型能檢測出的六類目標。
數據集沒有公開,作者在這里:https://github.com/Kadantte
有了數據,還是要做一些圖像增強工作,隨機加入一些模糊、翻轉。使用的工具是albumentations:
https://github.com/albu/albumentations
訓練與評估
這里的檢測模型,選擇的是FAIR推出的RetinaNet,它使用焦點損失(交叉熵損失的一種變體)來增強一階目標檢測的性能。
檢測模型的基干使用了ResNet-101,在測試集上的成績如下:
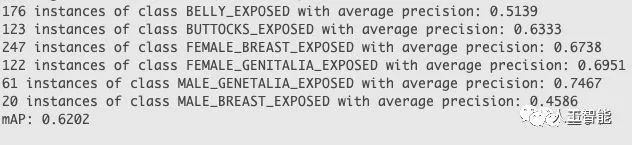
除了用來指出某個部位究竟出現在了圖中什么位置之外,這個模型其實還可以當成分類器來用:
如果在圖中檢測到了BUTTOCKS_EXPOSED、*_GENETALIA_EXPOSED、F_BREAST_EXPOSED這四類,就可以判定圖片NSFW,如果沒有,這張圖就是安全的。
所以,也可以用分類器的測試集來檢測這個模型的性能。
得到的成績,比純粹的分類器好不少:

當然,目標檢測更適合實現的功能,是打碼。比如說見到一張NSFW圖片,它就可以根據檢測到的關鍵部位,自動遮擋:
預訓練模型怎么用?
如果你想先用預訓練模型看看效果,可以按照下面的安裝指南來:
安裝:
pipinstallnudenetorpipinstallgit+https://github.com/bedapudi6788/NudeNet
使用分類器:
fromnudenetimportNudeClassifier
-
AI
+關注
關注
87文章
30239瀏覽量
268480 -
開源
+關注
關注
3文章
3256瀏覽量
42420
原文標題:開源鑒黃AI新鮮出爐:代碼+預訓練模型,還附手把手入門教
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
手把手教你學單片機之AVR入門視頻教程
【原創】小草手把手教你LabVIEW視頻系列匯總帖(12.22更新)
手把手教你SIMULINK代碼生成
手把手教你安裝Quartus II
手把手教你學LabVIEW視覺設計
51單片機手把手教學(二)—— 點亮 LED 燈(GPIO 操作)

51單片機手把手教學 (一)—— 開發環境搭建





 工商網監
工商網監
評論