 自然語言基礎技術之命名實體識別相對全面的介紹
自然語言基礎技術之命名實體識別相對全面的介紹
本文對自然語言基礎技術之命名實體識別進行了相對全面的介紹,包括定義、發展歷史、常見方法、以及相關數據集,最后推薦一大波 Python 實戰利器,并且包括工具的用法。
01
定義
先來看看維基百科上的定義:Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify named entity mentions in unstructured text into pre-defined categories such as the person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
命名實體識別(Named Entity Recognition,簡稱NER),又稱作“專名識別”,是指識別文本中具有特定意義的實體,主要包括人名、地名、機構名、專有名詞等。簡單的講,就是識別自然文本中的實體指稱的邊界和類別。
02
發展歷史
命名實體識別這個術語首次出現在 MUC-6(Message Understanding Conferences),這個會議關注的主要問題是信息抽取(Information Extraction),第六屆 MUC 除了信息抽取評測任務還開設了新評測任務即命名實體識別任務。
除此之外,其他相關的評測會議包括CoNLL(Conference on Computational Natural Language Learning)、ACE(Automatic Content Extraction)和IEER(Information Extraction-Entity Recognition Evaluation)等。
在MUC-6之前,大家主要是關注人名、地名和組織機構名這三類專業名詞的識別。自MUC-6起,后面有很多研究對類別進行了更細致的劃分,比如地名被進一步細化為城市、州和國家,也有人將人名進一步細分為政治家、藝人等小類。
此外,一些評測還擴大了專業名詞的范圍,比如CoNLL某年組織的評測中包含了產品名的識別。一些研究也涉及電影名、書名、項目名、研究領域名稱、電子郵件地址、電話號碼以及生物信息學領域的專有名詞(如蛋白質、DNA、RNA等)。甚至有一些工作不限定“實體”的類型,而是將其當做開放域的命名實體識別和分類。
03
常見方法
早期的命名實體識別方法基本都是基于規則的。之后由于基于大規模的語料庫的統計方法在自然語言處理各個方面取得不錯的效果之后,一大批機器學習的方法也出現在命名實體類識別任務。宗成慶老師在統計自然語言處理一書粗略的將這些基于機器學習的命名實體識別方法劃分為以下幾類:
有監督的學習方法:這一類方法需要利用大規模的已標注語料對模型進行參數訓練。目前常用的模型或方法包括隱馬爾可夫模型、語言模型、最大熵模型、支持向量機、決策樹和條件隨機場等。值得一提的是,基于條件隨機場的方法是命名實體識別中最成功的方法。
半監督的學習方法:這一類方法利用標注的小數據集(種子數據)自舉學習。
無監督的學習方法:這一類方法利用詞匯資源(如 WordNet)等進行上下文聚類。
混合方法:幾種模型相結合或利用統計方法和人工總結的知識庫。
值得一提的是,由于深度學習在自然語言的廣泛應用,基于深度學習的命名實體識別方法也展現出不錯的效果,此類方法基本還是把命名實體識別當做序列標注任務來做,比較經典的方法是 LSTM+CRF、BiLSTM+CRF。
04
相關數據集
1. CCKS2017 開放的中文的電子病例測評相關的數據。
評測任務一:
https://biendata.com/competition/CCKS2017_1/
評測任務二:
https://biendata.com/competition/CCKS2017_2/
2. CCKS2018 開放的音樂領域的實體識別任務。
評測任務:
https://biendata.com/competition/CCKS2018_2/
3. (CoNLL 2002)Annotated Corpus for Named Entity Recognition。
地址:
https://www.kaggle.com/abhinavwalia95/entity-annotated-corpus
4. NLPCC2018 開放的任務型對話系統中的口語理解評測。
地址:
http://tcci.ccf.org.cn/conference/2018/taskdata.php
5. 一家公司提供的數據集,包含人名、地名、機構名、專有名詞。
下載地址:
https://bosonnlp.com/dev/resource
05
工具推薦
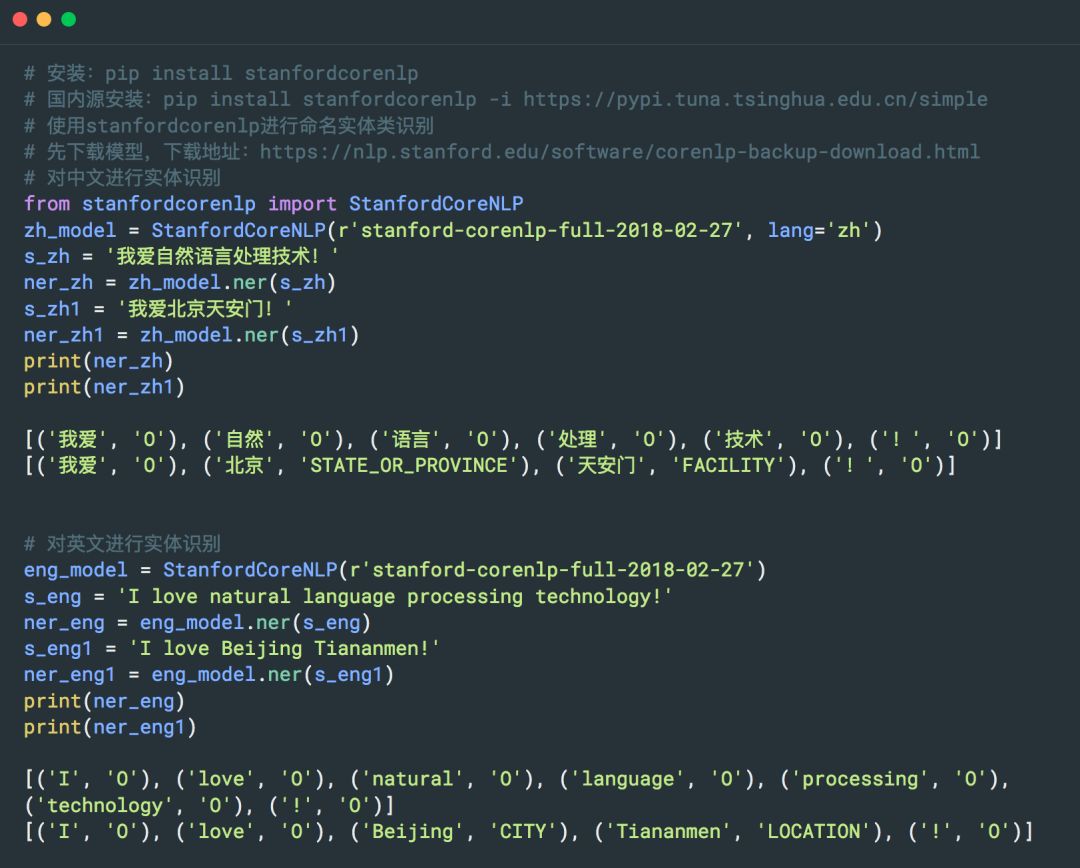
1. Stanford NER
斯坦福大學開發的基于條件隨機場的命名實體識別系統,該系統參數是基于 CoNLL、MUC-6、MUC-7 和 ACE 命名實體語料訓練出來的。
地址:
https://nlp.stanford.edu/software/CRF-NER.shtml
Python 實現的 Github 地址:
https://github.com/Lynten/stanford-corenlp
2 .MALLET
麻省大學開發的一個統計自然語言處理的開源包,其序列標注工具的應用中能夠實現命名實體識別。
官方地址:
http://mallet.cs.umass.edu/
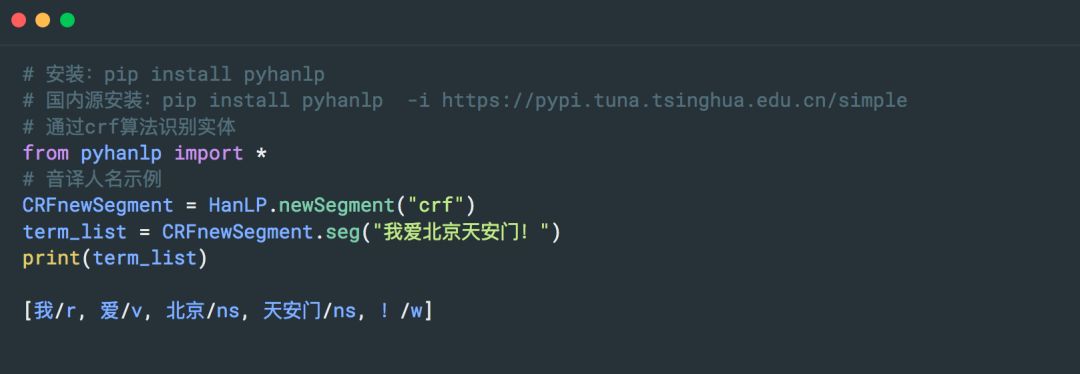
3. Hanlp
HanLP 是一系列模型與算法組成的 NLP 工具包,由大快搜索主導并完全開源,目標是普及自然語言處理在生產環境中的應用。支持命名實體識別。
Github 地址:
https://github.com/hankcs/pyhanlp
官網:
http://hanlp.linrunsoft.com/
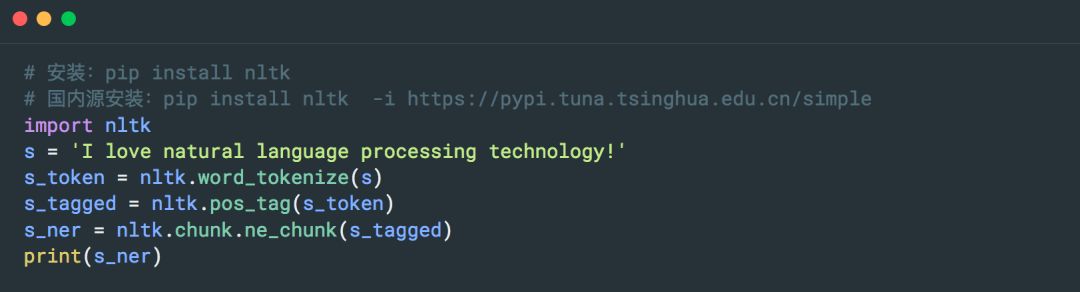
4. NLTK
NLTK 是一個高效的 Python 構建的平臺,用來處理人類自然語言數據。
Github 地址:
https://github.com/nltk/nltk
官網:
http://www.nltk.org/
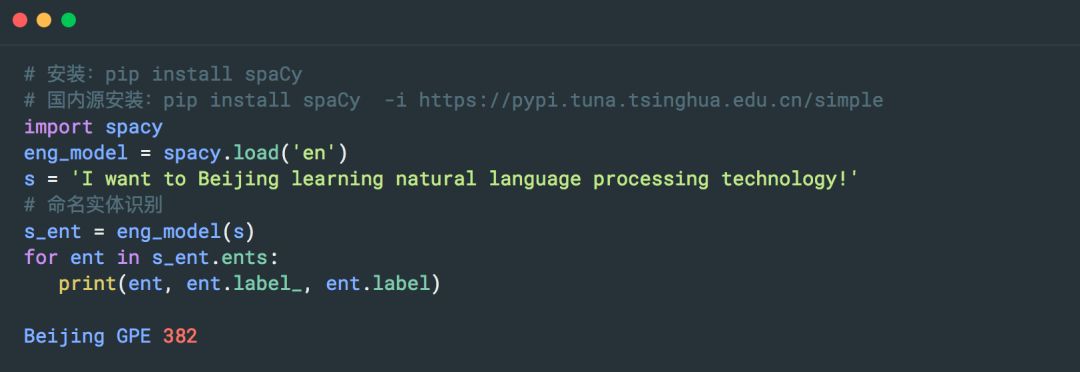
5. SpaCy
工業級的自然語言處理工具,遺憾的是不支持中文。
Gihub 地址:
https://github.com/explosion/spaCy
官網:https://spacy.io/
6. Crfsuite
可以載入自己的數據集去訓練 CRF 實體識別模型。
文檔地址:
https://sklearn-crfsuite.readthedocs.io/en/latest/?badge=latest
代碼已上傳:
https://github.com/yuquanle/StudyForNLP/blob/master/NLPbasic/NER.ipynb
-
機器學習
+關注
關注
66文章
8382瀏覽量
132444 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
自然語言處理
+關注
關注
1文章
614瀏覽量
13513
原文標題:一文讀懂命名實體識別
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
hanlp漢語自然語言處理入門基礎知識介紹
HanLP分詞命名實體提取詳解
HanLP-命名實體識別總結
【推薦體驗】騰訊云自然語言處理
基于神經網絡結構在命名實體識別中應用的分析與總結

思必馳中文命名實體識別任務助力AI落地應用
命名實體識別的遷移學習相關研究分析

基于字語言模型的中文命名實體識別系統






 工商網監
工商網監
評論