 一文講述Quadro RTX 5000帶來的性能提升
一文講述Quadro RTX 5000帶來的性能提升
GPU在傳統圖形可視化領域的應用不斷的擴大,無論是在3D設計,大分辨率多屏拼接顯示,還是特效渲染領域,越來越多的人轉向使用更加穩定的專業圖形卡。深度學習和大數據作為新銳行業也大量地使用專業的GPU,以加速訓練研發的速度。
最新基于Turing架構的NVIDIA Quadro GPU系列從去年就開始上市。本篇開箱評測分享將告訴你最新的Quadro RTX 5000有那些改變,又有哪些提升呢?
開箱
本次顯卡包裝改變了以往的顏色、風格,使用綠白灰搭配,正面的灰色格子采用漸變的顏色很有現代感和立體感。包裝的正面和頂部、側面都有顯卡型號的標識。
RTX幾個字有金屬反光效果,凸顯了這代顯卡最重要的功能之一——實時光線追蹤。
整體拿在手里沉甸甸的,挺有分量,包裝的材質很結實。
顯卡包裝及配件
內部包裝也和以往包裝不一樣,外殼和防震泡沫是一體的,顯卡安置在其中,給人的感覺是堅固、牢靠。
顯卡外面還有一層透明防靜電袋,配線盒里面有用戶手冊、支持手冊、 8pin轉雙6pin電源線、DP轉DVI轉接頭和DP轉HDMI轉接頭。這是眾多使用DVI顯示器或HDMI顯示器的福音,再也不用另外單獨購買轉接頭了。
顯卡正面
顯卡外觀主要采用綠、銀色和黑色搭配,與包裝風格一致。顯卡也是沉甸甸的,質感很不錯。在顯卡正面和脊背上都能看到顯卡型號的標識。
Quadro RTX 5000依然是雙插槽顯卡,1個渦輪風扇,顯卡采用8pin加6pin的供電方式,對于最大功耗為265W的RTX 5000來講是足夠用了。
顯卡頂部接口
顯卡頂部總共有3個接口,NVLink、SYNC、Stereo。
NVLink技術取代了SLI技術,可以配合Quadro NVLink 2-Slot或者3-Slot使用。NVLink技術不但具備多卡同步輸出的功能,在應用支持的情況下,還能實現顯存疊加的功能,使兩塊卡疊加成一個更大的顯存。
SYNC接口要配合Quadro SYNCII卡來使用,實現多卡的顯示信號同步輸出。對于大屏拼接的用戶來講可以延續之前的使用方法。
Stereo接口要配合3D立體檔板來輸出3D立體信號。
總線接口是PCIE 3.0接口,向下兼容PCIE 2.0。目前市場上主板大都是使用這種接口的。
顯卡顯示接口
顯示接口有了新的變化,不是4DP+DVI的配置,改成了4DP+VirtualLink的配置。
DP接口都支持DP 1.4的協議,最高分辨率可以達到7680x4320。而VirtualLink接口則是下一代VR設備使用的標準接口,一個接口可完成供電、顯示傳輸、控制信號多個功能。
性能測試
顯卡參數
測試平臺
測試軟件

測試內容展示
1.
SPECviewperf 13
SPECviewperf 13是基于專業應用上衡量圖形性能被廣泛應用的測試軟件。該軟件對基于OpenGL和DirectX的專業繪圖軟件進行基準評測,SPECviewperf 13帶來了全新的9個專業圖形測試場景,SPECviewperf13測試更加貼近真實的工作應用, 其中一些測試場景甚至包含有超過6,000萬個定點數據,能夠充分反映出顯卡的專業圖形性能,此次測試我們使用軟件默認配置進行評測。
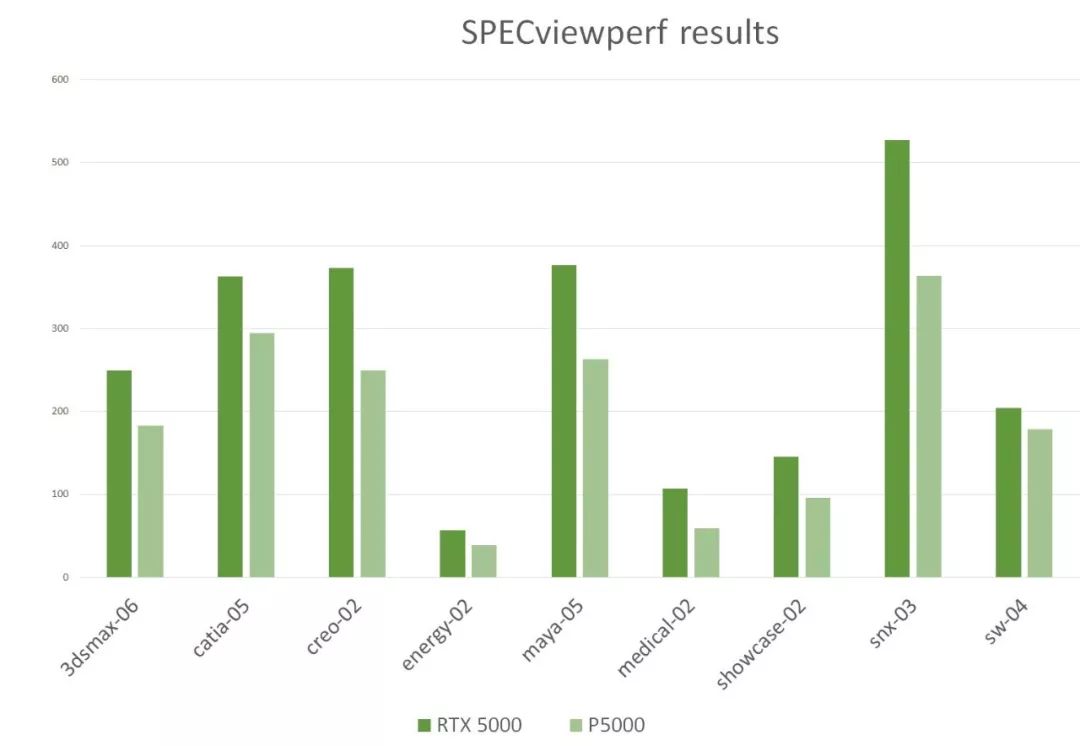
測試結果
從測試結果來看,RTX 5000在所有項目上普遍超越了Quadro P5000,snx的性能甚至增加了40%以上。看來Turing架構增加的不僅僅是光線追蹤和深度學習的效率,在專業應用的性能上增加的幅度也是很大的。
2.
SuperPosition Benchmark
這款軟件更像是在一個復雜的游戲環境,在不同的光場效果中對顯卡DX和OpenGL渲染性能及穩定性的評測。
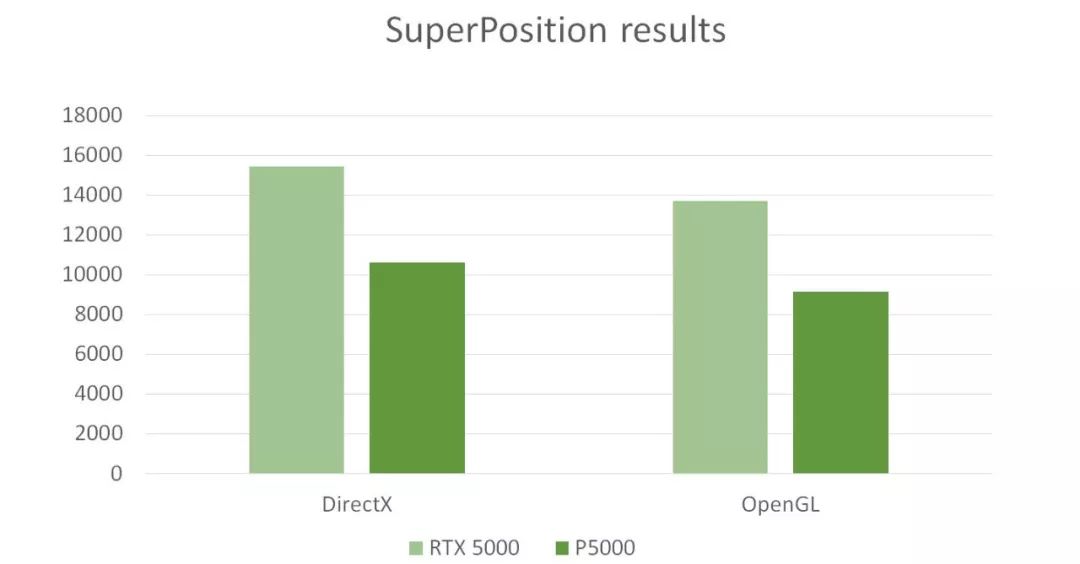
測試結果
在DirectX的性能方面,RTX 5000比P5000提高了近45%,在OpenGL方面,RTX 5000比P 5000提高了性能提高了50%左右。兩個主要的圖形API的性能都增加了很多,相信RTX 5000在專業3D可視化領域有了更高的可用性。
3.
V-Ray Benchmark
Chaos Group的V-Ray在渲染領域早已被廣大用戶認可了,由于GPU渲染性能的提升,Chaos Group在V-Ray Next上推出了V-Ray GPU NEXT版本,支持調用NVIDIA CUDA核心進行渲染,隨著技術的不斷更新,GPU渲染的質量上幾乎和CPU沒有區別。GPU算力強勁渲染時間成本會更低,并且支持多卡加速渲染,所以很多渲染器都在增加自己的GPU渲染功能。本次評估僅測試單卡的渲染性能,時間越短性能越好。
測試截圖
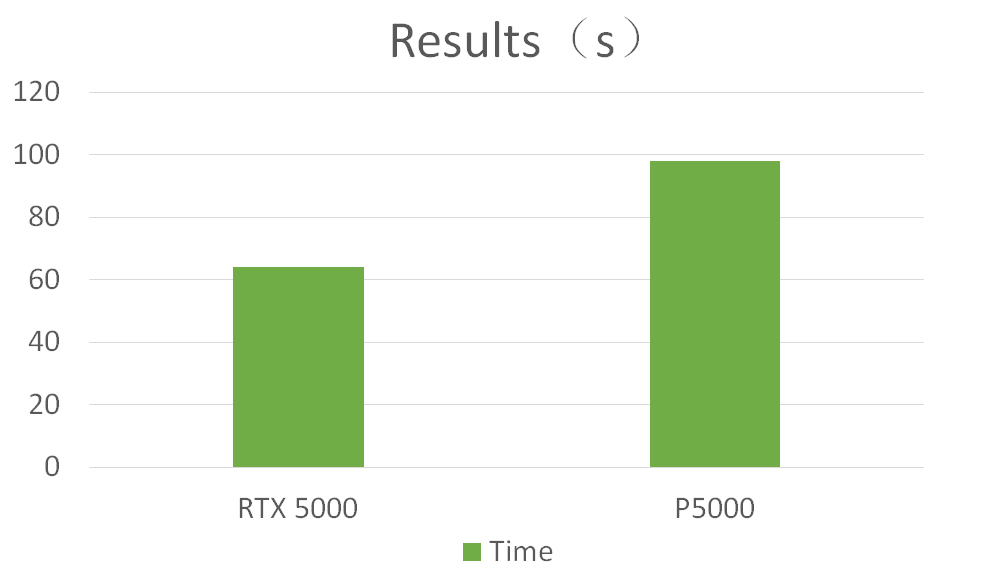
測試結果
從測試結果看,使用最新的RTX 5000比P5000節省了35%的時間。在V-Ray渲染中RTX 5000的效率會更高一些。
4.
CUDA-Z
就像我們熟知的CPU-Z 、GPU-Z一樣,CUDA-Z是對NVIDIA GPU處理器的一些基本信息的采集,GeForce、Quadro、Tesla卡都可以配合使用。
測試截圖
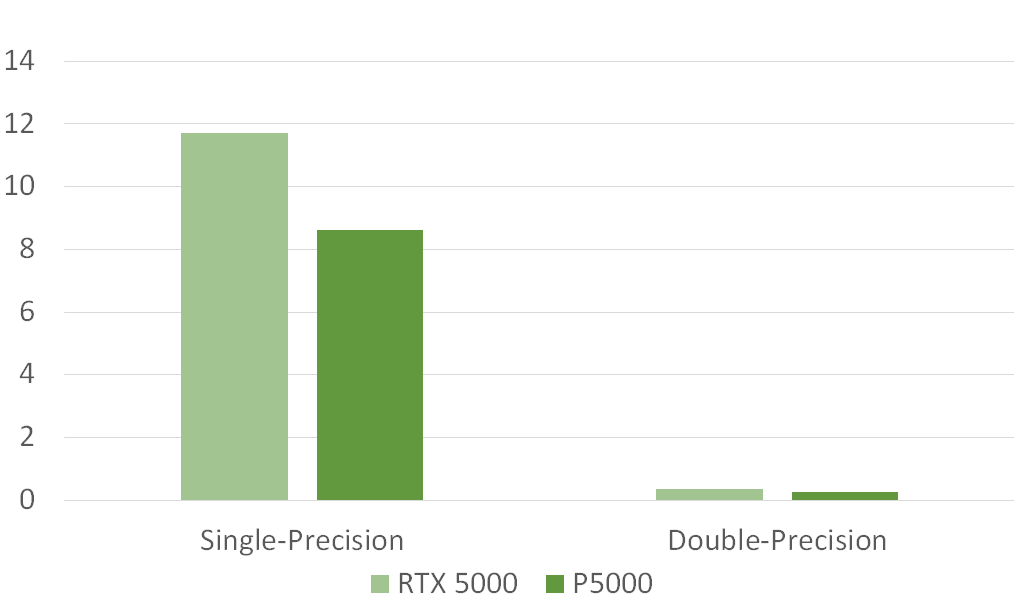
CUDA計算能力
在CUDA-Z的測試項目中,我們實際用到最多的是單精度浮點運算,如果有使用到雙精度科學計算的,推薦使用GV100或者GP100雙精計算能力高的GPU。
RTX 5000單精計算的能力達到了11.7T,相對于前一臺P5000提高了36%,提升幅度很大。這么強的單晶浮點數是CPU不能匹敵的,這也是越來越多的應用把計算從CPU轉向了GPU的原因。
5.
3DMark Port Royal
測試場景
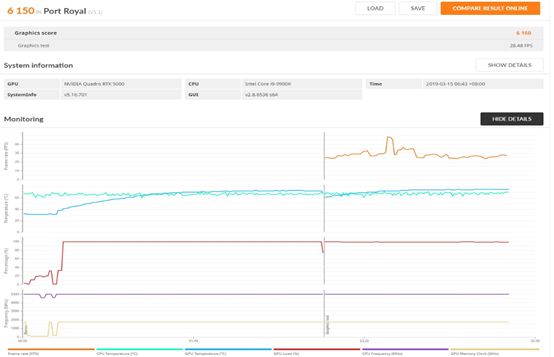
測試結果
目前NVIDIA的RTX渲染的Benchmark功能,3DMark的Port Royal可以支持性能測試。Quadro P5000由于沒有RT Core所以無法使用這個評測軟件。
測試場景里帶了大量金屬的材質,反射效果驚艷。RTX 5000渲染FPS達到了28左右幀,還算流暢。目前游戲行業已經有BF5使用這種技術,相信未來在工業制造領域和影視后期領域都會被廣泛的使用。
6.
OctaneBench 2019 Preview
OC渲染器是做3D設計及動畫的一款支持GPU渲染的渲染器,可以配合很多3ds Max、CINEMA 4D、NUKE、MODO等3D建模及特效的軟件。OC渲染器是可以支持Out of Core的渲染軟件,最新的OctaneBench 2019 Preview是可以支持RT Core加速光線追蹤渲染的軟件。我們可以看一下使用和關閉RTX在渲染速度上的區別。
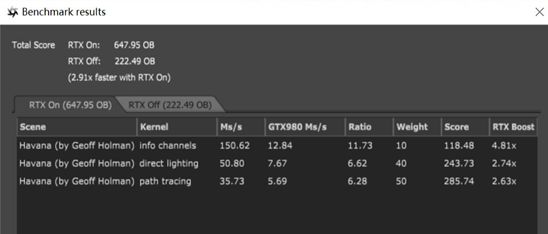
測試截圖
軟件分別在開啟RTX和關閉RTX狀態下對相同場景進行渲染,從測試成績上可以看出,開啟了RTX On渲染之后,渲染的速度比關閉RTX渲染速度快了近3倍。可見在RT Core的加成下,渲染速度有了很大的提升。
7.
NVIDIA Tensorflow example
我們選擇NVIDIA Tensorflow的一個示例來測試顯卡的性能。在相同參數設置的情況下,顯卡在一秒內訓練的圖片數越多,說明顯卡在實例深度學習方面的性能越好。
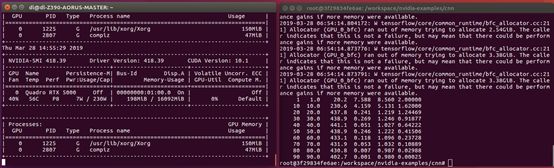
上圖可以看到,RTX 5000在滿載時候每秒處理的數量最多為441張。
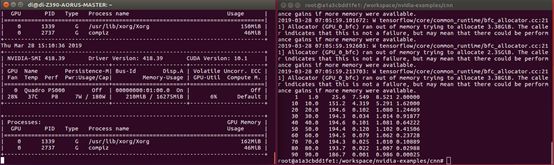
P5000在上圖此示例中每秒處理的圖片數最多為194張。
從每秒處理數據的性能上看,RTX 5000處理速度是P5000的2.2倍。速度快了很多,這是由于調用了Tensor Core進行計算的原因。可見Tensor Core在深度學習的加速上還是有很大作用的。Quadro RTX高端顯卡都具有Tensor Core,基于這種顯卡可以實現圖像加AI的一些應用。例如在渲染的同時可以實現去AI噪點,圖像AI識別,或者其他AI推理的一些工作。
總結
RTX 5000顯卡最大的特點是:
具有RT Core支持RTX實時光線追蹤渲染,能渲染出具有流光溢彩真實感的畫面。渲染速度非常快,在諸多行業可視化的工業設計流程上會有很好的推動作用。
具有Tensor Core,可以加速深度學習和AI推理。在人工智能大力發展的今天,有了Tensor Core的加持,很多應用會變得如虎添翼。
傳統的圖形應用性能優化和穩定性都繼承了下來,并且性能表現的更好。使用Fermi 、Kepler、Maxwell架構的用戶可以考慮RTX系列顯卡進行更新換代了。
-
NVIDIA
+關注
關注
14文章
4793瀏覽量
102434 -
gpu
+關注
關注
27文章
4593瀏覽量
128171 -
深度學習
+關注
關注
73文章
5422瀏覽量
120597
原文標題:NVIDIA Quadro RTX 5000評測 | 體驗RTX加持下的創意工作改變
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英偉達發布新一代 GPU 架構圖靈和 GPU 系列 Quadro RTX
如何提升EMC性能?
Turing架構NVIDIA Quadro? RTX? ,適用于廣電傳媒娛樂領域
英偉達專業顯卡Quadro RTX 4000發布 優化了VR應用程序的性能
英偉達宣布正式推出其最新款圖靈架構專業顯卡Quadro RTX 4000
宏碁發布一款可以翻轉屏幕的筆記本 搭配酷睿i9及RTX5000顯卡
NVIDIA經典品牌“Quadro”似乎已棄之不用
RTX A6000專業卡性能首曝:僅提升11%
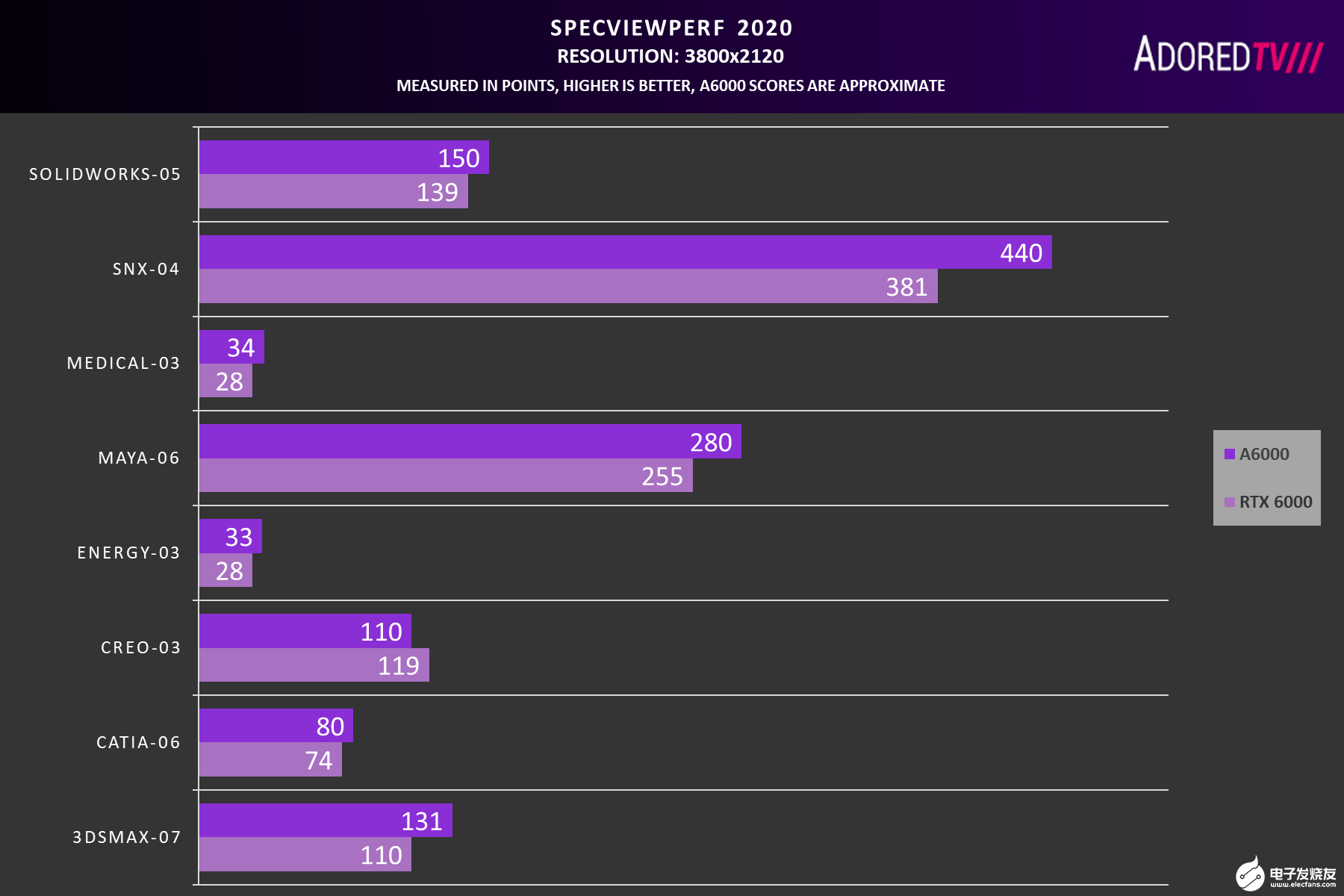
RTX30游戲本光追性能首曝:有點失望
RTX 3060大約比RTX 2060提升了19%,比RTX 2070提升了9%
NVIDIA RTX 6000工作站GPU將為企業工作流帶來性能提升
NVIDIA RTX 5000 Ada顯卡性能實測報告






 工商網監
工商網監
評論