 決策樹和隨機森林模型
決策樹和隨機森林模型
這是一個系列教程,試圖將機器學習這門深奧的課程,以更加淺顯易懂的方式講出來,讓沒有理科背景的讀者都能看懂。
前情提要:這是一個系列教程。如果你剛好第一次看到這篇文章,那么你可能需要收藏一下本篇文章,然后先看一下這個系列的前一篇《文科生都能看懂的機器學習教程:梯度下降、線性回歸、邏輯回歸》。如果你已經看過了,那么就不再多說,讓我們繼續吧。

本次主要講的是決策樹和隨機森林模型,
決策樹
決策樹是個超簡單結構,我們每天都在頭腦中使用它。它代表了我們如何做出決策的表現形式之一,類似if-this-then-that:
首先從一個問題開始;然后給出這個問題的可能答案,然后是這個答案的衍生問題,然后是衍生問題的答案…直到每個問題都有答案。程序員和PM應該這個流程非常熟悉的。
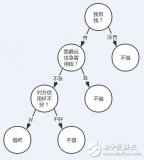
先看一個決策樹的例子,決定某人是否應該在特定的一天打棒球。
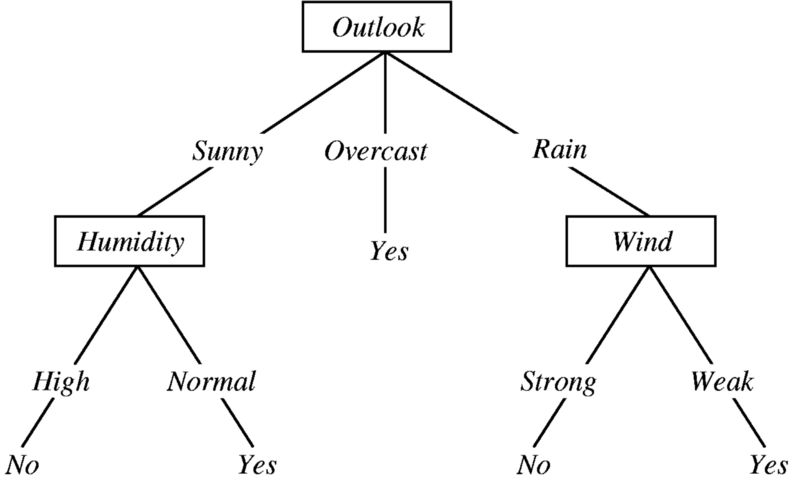
圖片來源:Ramandeep Kaur的 “ 機器學習與決策樹”
這棵樹從上往下,首先提出一個問題:今天的天氣預期如何?接下來會有三種可能的答案:晴;陰;雨。
1. if 天氣=晴天,那么判斷濕度如何
1. if 濕度高,then 取消
2. if 濕度低,then 去玩
2. if 天氣=陰天,then 去
3. if 天氣=下雨,then 取消
一棵簡單的決策樹就出來了。決策樹具備以下特性:
決策樹用于建模非線性關系(與線性回歸模型和邏輯回歸模型相反)
決策樹可以對分類和連續結果變量進行建模,盡管它們主要用于分類任務(即分類結果變量)
決策樹很容易理解! 您可以輕松地對它們進行可視化,并準確找出每個分割點發生的情況。 您還可以查看哪些功能最重要
決策樹容易過擬合。這是因為無論通過單個決策樹運行數據多少次,因為只是一系列if-this-then-that語句,所以總是會得到完全相同的結果。這意味著決策樹可以非常精確地適配訓練數據,但一旦開始傳遞新數據,它可能無法提供有用的預測
決策樹有多種算法,最常用的是ID3(ID代表“迭代二分法”)和CART(CART代表“分類和回歸樹”)。這些算法中的每一個都使用不同的度量來決定何時分割。ID3樹使用信息增益 ,而CART樹使用基尼指數 。
ID3樹和信息增益
基本上ID3樹的全部意義在于最大限度地提高信息收益,因此也被稱為貪婪的樹。
從技術上講,信息增益是使用熵作為雜質測量的標準。好吧。我們先來了解一下熵。
簡單地說,熵是(dis)順序的衡量標準,它能夠表示信息的缺失流量,或者數據的混亂程度。缺失大量信息的東西被認為是無序的(即具有高度熵),反之則是低度熵。
舉例說明:
假設一個凌亂的房間,地板上是臟衣服,也許還有一些樂高積木,或者switch、iPad等等。總之房間非常亂,那么它就是熵很高、信息增益很低。
現在你開始清理這個房間,把散落各處的東西意義歸類。那么就是低熵和高信息增益。
好,回到決策樹。ID3樹將始終做出讓他們獲得最高收益的決定,更多信息、更少的熵。
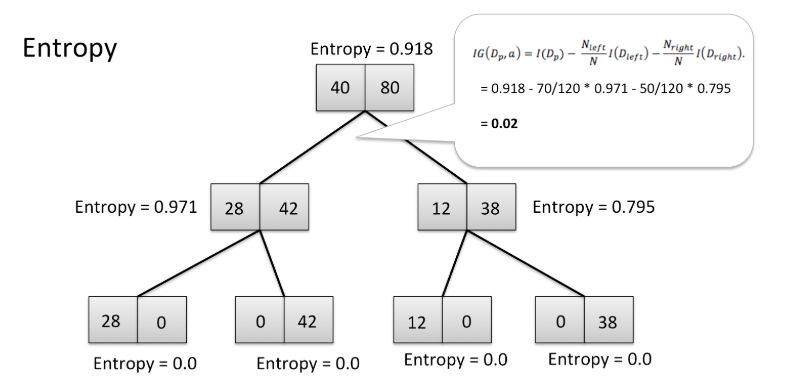
在決策樹中的可視化的熵
在上面的樹中,你可以看到起始點的熵為0.918,而停止點的熵為0.這棵樹以高信息增益和低熵結束,這正是我們想要的。
除了向低熵方向發展外,ID3樹還將做出讓他們獲得最高純度的決定。 因為ID3希望每個決定都盡可能清晰,具有低熵的物質也具有高純度,高信息增益=低熵=高純度。
其實結合到現實生活中,如果某些事情令人困惑和混亂(即具有高熵),那么對該事物的理解就會是模糊的,不清楚的或不純的。
CART樹和基尼指數
和ID3算法不同,CART算法的決策樹旨在最小化基尼指數。
基尼指數可以表示數據集中隨機選擇的數據點可能被錯誤分類的頻率。 我們總是希望最小化錯誤標記數據可能性對吧,這就是CART樹的目的。
線性模型下線性函數的可視化
隨機森林
隨機森林可以說是初學數據科學家最受歡迎的集合模型。
集合模型顧名思義。是許多其他模型的集合。
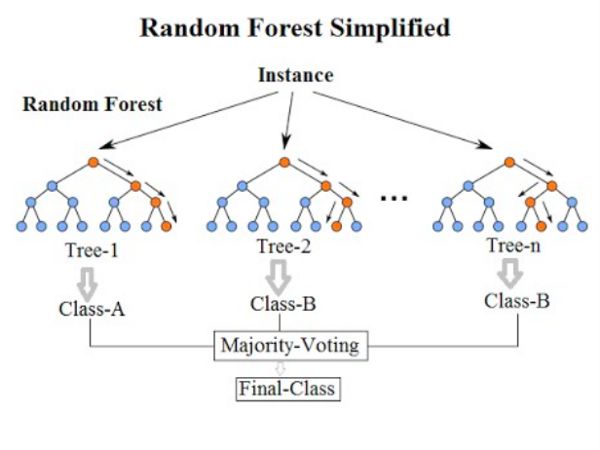
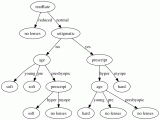
來自KDNuggets的隨機森林結構。
正如你在左邊的圖表中看到的3個決策樹,像Random Forest這樣的集合模型只是一堆決策樹。
像隨機森林這樣的集合模型,旨在通過使用引導聚集算法(裝袋算法)來減少過度擬合和方差。
我們知道決策樹容易過擬合。換句話說,單個決策樹可以很好地找到特定問題的解決方案,但如果應用于以前從未見過的問題則非常糟糕。俗話說三個臭皮匠賽過諸葛亮,隨機森林就利用了多個決策樹,來應對多種不同場景。
然而在數據科學領域,除了過度擬合,我們還要解決另一個問題叫做方差。具有“高方差”的模型,盡管輸入最微小的位改變,其結果也會有很大的變化,類似于失之毫厘謬以千里,這意味著具有高方差的模型不能很好地概括為新數據。
裝袋算法
在深入研究隨機森林依賴的裝袋算法之前,仍然了解一個概念:learner。
在機器學習中,分為弱learner和強learner,裝袋算法主要用于處理弱learner。
弱learner
弱learner構成了隨機森林模型的支柱,它是一種算法,可以準確地對數據進行預測/分類!
像隨機森林這樣的集合模型使用裝袋算法來避免高方差和過度擬合的缺陷,而單個決策樹等更簡單的模型更容易出現。
當算法通過隨機數據樣本建立決策樹時,所有數據都是可以被利用起來的。

綜上所述: 隨機森林模型使用裝袋算法來構建較少的決策樹,每個決策樹與數據的隨機子集同時構建。
隨機森林模型中的每個樹不僅包含數據的子集,每個樹也只使用數據的特征子集。
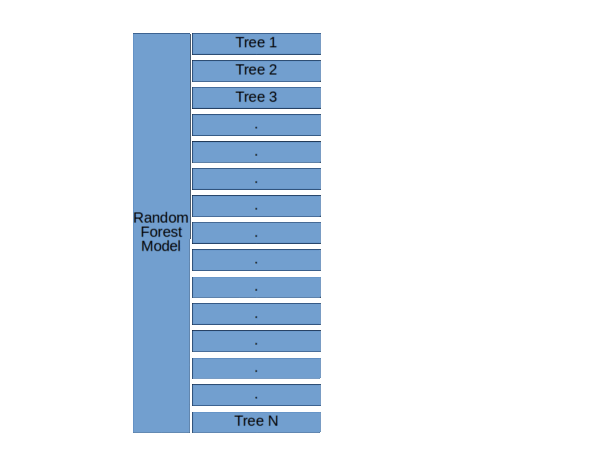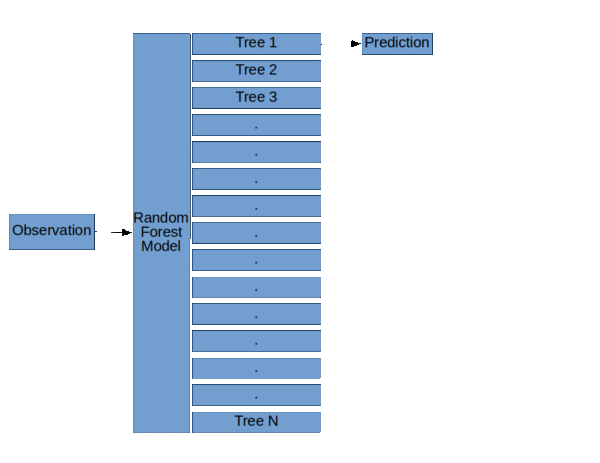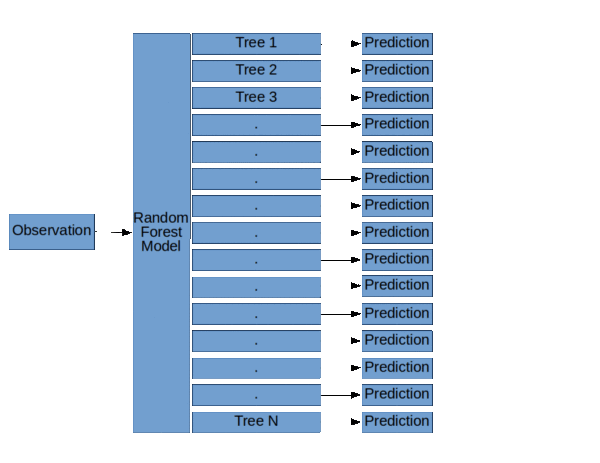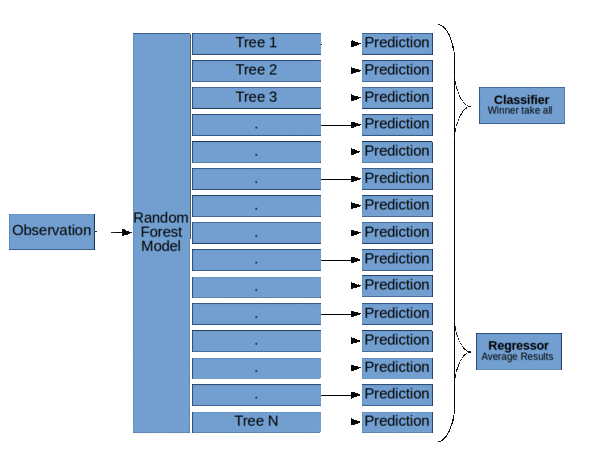
隨機森林模型的基本結構( 隨機森林,決策樹和集合方法由Dylan Storey 解釋 )
通過這篇文章,我們學習了所有關于決策樹、過度擬合和方差以及隨機森林等集合模型。第三部分將介紹兩個線性模型:SVM和樸素貝葉斯。
-
機器學習
+關注
關注
66文章
8306瀏覽量
131838 -
數據集
+關注
關注
4文章
1197瀏覽量
24535 -
決策樹
+關注
關注
2文章
96瀏覽量
13513
原文標題:文科生也能看懂的機器學習教程2:決策樹和隨機森林
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于決策樹,這些知識點不可錯過
介紹支持向量機與決策樹集成等模型的應用
決策樹的生成資料
決策樹的構建設計并用Graphviz實現決策樹的可視化
人工智能機器學習之隨機森林(RF)
決策樹的原理和決策樹構建的準備工作,機器學習決策樹的原理
什么是決策樹模型,決策樹模型的繪制方法
大數據—決策樹
什么是隨機森林?隨機森林的工作原理





 工商網監
工商網監
評論