 一個能通過空間條件坐標和隱變量生成圖像片、并合成完整圖片的網絡模型
一個能通過空間條件坐標和隱變量生成圖像片、并合成完整圖片的網絡模型
我們人類有著豐富的生活經驗和生物直覺,可以在只看到物體的一部分時就能在大腦中補全整個對象的全貌,也可以通過幾次對于目標的部分觀測“拼接”出物體的全貌。人類的這種能力源于我們對于空間坐標的深入理解和把握,可以將不同區域的觀測放置到相應的位置上以識別整體環境。但目前大部分的計算機視覺系統都是以整張圖片作為輸入,隨后利用下采樣和特征抽取來實現一系列視覺任務。但這種方式限制了算法對于大場景高像素圖像的處理。我們不禁要問:“計算機是不是也可以像人類一樣由局部到整體的理解圖像呢?我們能不能訓練出一個生成模型,可以利用坐標信息生成局域圖像并組合成連續的全局圖像呢?”
帶著這個問題,研究人員們對生成對抗網絡進行了深入地探索。典型的GAN通常是將隱空間的分布映射到真實數據空間中去。為了從部分圖片生成高質量的圖像,研究人員在圖像中引入了坐標系統的概念,并將圖像生成分解為一系列并行的子過程。最后得到一個能通過空間條件坐標和隱變量生成圖像片、并合成完整圖片的網絡模型。
這一名為條件坐標生成對抗網絡(COnditional COordinate GAN ,COCO-GAN)的模型目標是學習出一個與隱空間分布流型正交的坐標流型。對隱空間采樣后,生成器以每個空間坐標為條件在每個對應位置生成圖像片。與此同時判別器則學會判斷相鄰圖像片的結構是否合理,在視覺上是否勻稱、在邊緣處是否連續。
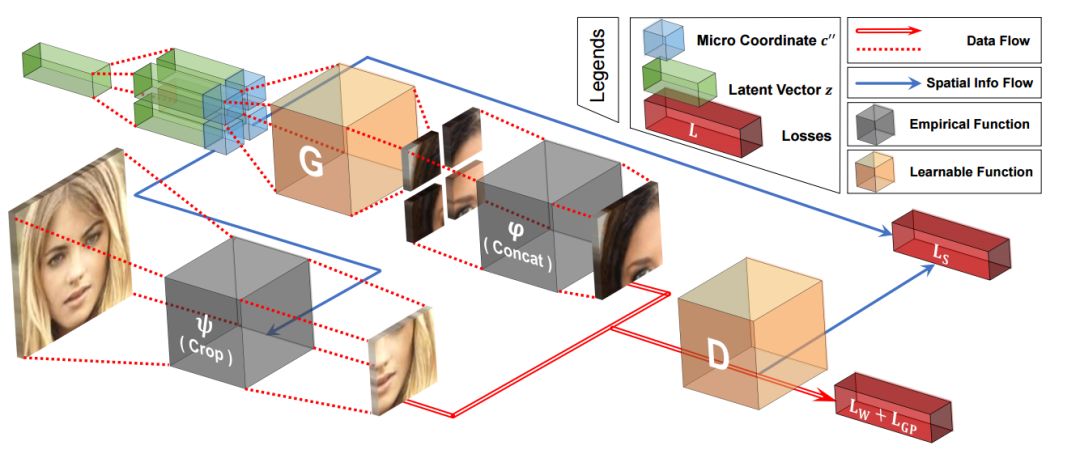
上圖中我們可以看到COCO-GAN的訓練架構,最坐標綠色的隱變量復制后分別與不同的坐標表達銜接,隨后送入生成器中生成微圖像片。而后將多個不同的像素片進行拼接得到宏圖像片。而判別器測復雜分辨真實的和生成的宏圖像片,并在右上角的分支中輔助預測宏圖像片的空間坐標。而完整的圖像則會在測試階段生成。
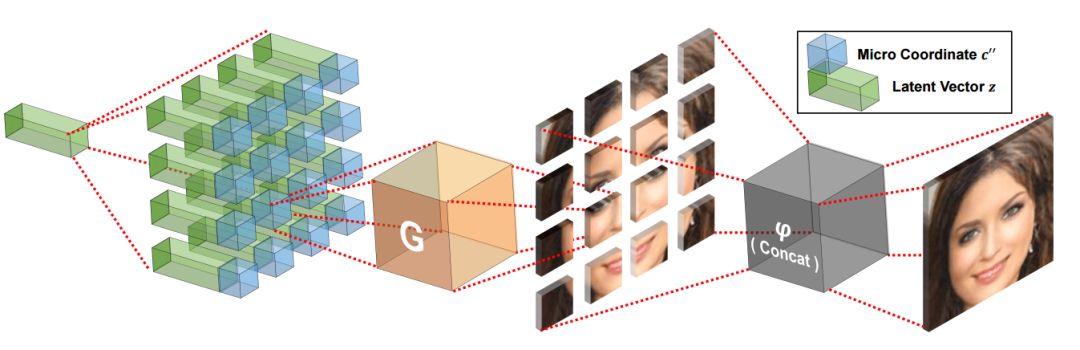
在測試時,生成的微圖像片直接拼接成最后的圖像輸出。
具體實現
在前文的架構圖中我們已經看到它由生成器和判別器兩個網絡和兩套坐標系統組成,其中包括了細粒度的局域圖像片坐標系統和粗粒度的宏圖像片坐標系統。整個過程中包含了三種圖像,整幅圖、宏圖像片層、微圖像片層構成。其中生成器主要基于空間條件,從隱變量中生成出維圖像片,并將多個圖像片拼接生成高質量的輸出。并通過判別器對于宏圖像片的判斷來指導生成器對于圖像片的生成。最終生成器的損失包含了空間連續性損失和Wasserstein損失,而判別器還增加了一項梯度懲罰損失。
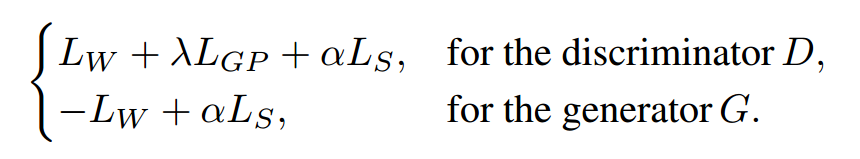
生成器和判別器其都是基于殘差塊和卷積實現的。
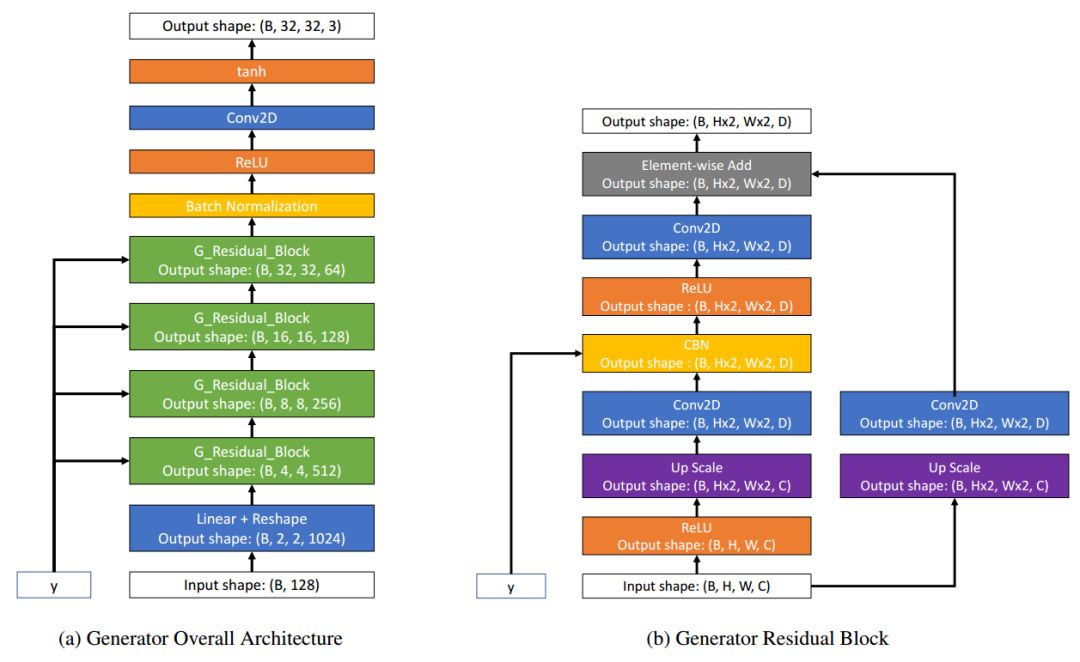
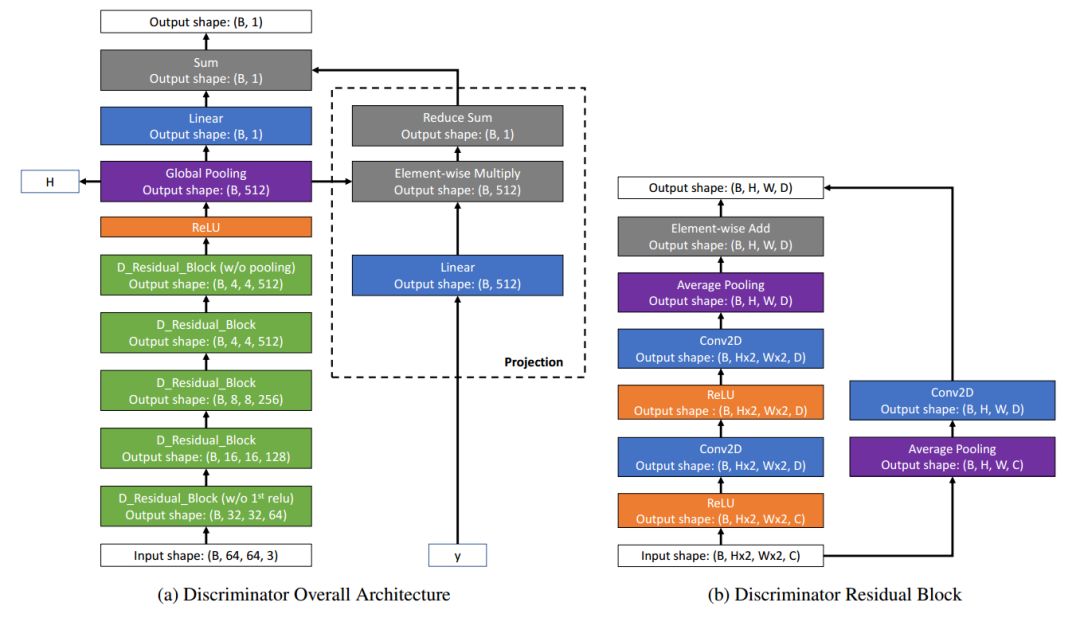
生成器和判別器的架構
基于這樣的損失,生成器生成的每個圖像片邊緣會變得更加平滑,基于空間坐標生成更為連續的結果。下圖是一些網絡得到的結果。這些全局連續平滑的圖像直接由網絡輸出,其中最頂一行是完整的圖像,中間一行是宏圖像片,而最下一行是生成器得到的為圖像片。每一列(同一個圖像)都是利用同一個隱變量得到的結果。由于大小不均,所以排列有些錯位。我們用不同顏色的箭頭分別標出。
研究人員基于這一網絡模型還進行了一系列實驗,都達到了十分優秀的結果。研究人員在CelebA和LSUN上分別將原始圖像分成2*2個宏圖像片,將每個宏圖像片分成了2*2個微圖像片,每個微圖像片由32*32個像素組成,這樣的配置記為:(N2,M2,S32)。下圖展示了不同配置的效果,宏圖像片可以由不同大小的微圖像片構成。
我們可以看到在不同像素配置下的微圖像片都可以生成較為完整的圖像。
甚至達到4*4時(N16,M16,S4)生成的圖像還比較合理。將1024個獨立圖像片進行拼接同樣可以保持輸出人臉的連續性。
空間連續性
為了更好地研究空間連續性,研究人員還進行了兩項插值實驗,分別是全圖插值和坐標插值。
在全圖插值中,研究人員隨即的從隱空間中選取兩個隱變量,在兩個隱變量之間的差值隱變量可以生成連續的全圖。在這一過程中所有的微圖像片都在同時改變以適應隱變量的變化。
在坐標插值的實驗中,利用固定的隱變量在空間坐標從[-1,1]區間變化的過程中生成微圖像片,在下圖中可以看到空間連續性在微圖像片中依然表現良好。一個有趣的現象是模型沒有真正的學習到眉間的結構,而是通過對左右眼直接變形來實現左眼到右眼的變化,這說明模型沒有真正的理解場景背后的內在聯系。
由于這一網絡學習到了圖像片的坐標流型,在坐標條件下進行外插生成器可以生成超過原始圖像大小的結果。基于256*256訓練的模型可以得到384*384的生成圖像,實現超越原始圖像邊界的生成,并且生成的都是新的樣本。下圖中紅色框外的是外插的結果,提高了原有圖像的分辨率。
隨后,研究人員還探索了如何利用這種方法生成全景圖像、如何利用局部信息并行化地生成整體圖像、實現圖像片引導的生成。
COCO-GAN從新的角度揭示了GAN在條件坐標下的強大生成能力,不僅拓展了GAN的生成能力同時并行化的處理和分治設計十分適用于計算受限設備的使用。相信COCO-GAN將為為GAN的研究帶來更寬廣的視野!
-
圖像
+關注
關注
2文章
1083瀏覽量
40414 -
生成器
+關注
關注
7文章
313瀏覽量
20976 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927
原文標題:國立清華與谷歌AI聯合提出新型生成模型COCO-GAN,讓計算機像人類一樣由局部到整體理解圖像
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

基于改進空間約束貝葉斯網絡模型的圖像分割
面向評分數據中用戶偏好發現的隱變量模型構建
探討條件GAN在圖像生成中的應用
基于隱馬爾科夫模型和卷積神經網絡的圖像標注方法






 工商網監
工商網監
評論