 Tensorflow 2.0版本如何幫助我們快速構建表格數據的神經網絡分類模型
Tensorflow 2.0版本如何幫助我們快速構建表格數據的神經網絡分類模型
以客戶流失數據為例,看 Tensorflow 2.0 版本如何幫助我們快速構建表格(結構化)數據的神經網絡分類模型。
變化
表格數據,你應該并不陌生。畢竟, Excel 這東西在咱們平時的工作和學習中,還是挺常見的。

在之前的教程里,我為你分享過,如何利用深度神經網絡,鎖定即將流失的客戶。里面用到的,就是這樣的表格數據。
時間過得真快,距離寫作那篇教程,已經一年半了。
這段時間里,出現了2個重要的變化,使我覺得有必要重新來跟你談談這個話題。
這兩個變化分別是:
首先,tflearn 框架的開發已經不再活躍。

tflearn 是當時教程中我們使用的高階深度學習框架,它基于 Tensorflow 之上,包裹了大量的細節,讓用戶可以非常方便地搭建自己的模型。
但是,由于 Tensorflow 選擇擁抱了它的競爭者 Keras ,導致后者的競爭優勢凸顯。
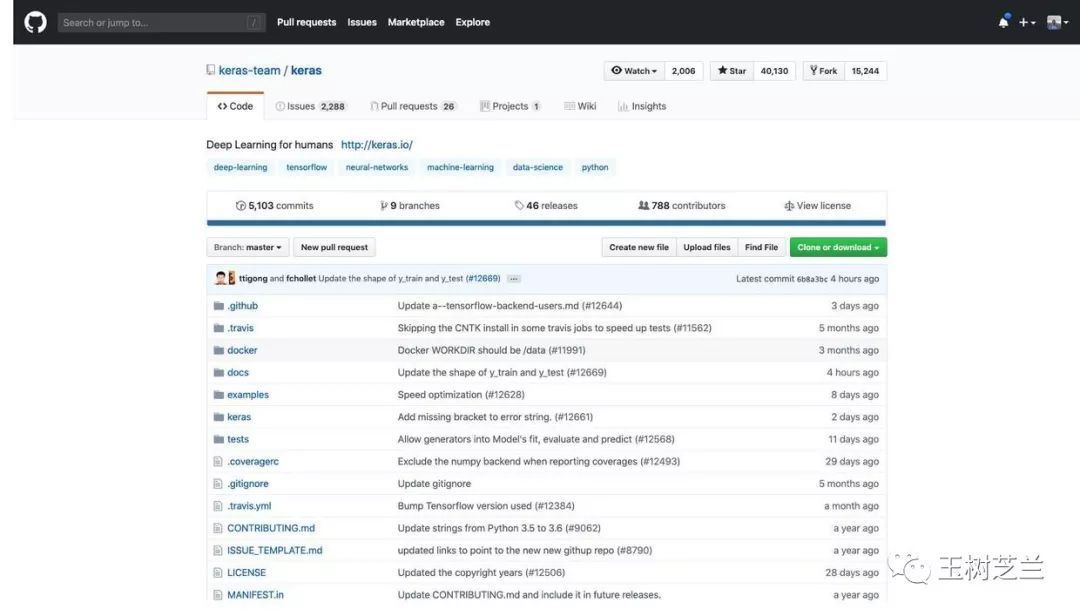
對比二者獲得的星數,已經不在同一量級。
觀察更新時間,tflearn 已經幾個月沒有動靜;而 Keras 幾個小時之前,還有更新。
我們選擇免費開源框架,一定要使用開發活躍、社區支持完善的。只有這樣,遇到問題才能更低成本、高效率地解決。
看過我的《Python編程遇問題,文科生怎么辦?》一文之后,你對上述結論,應該不陌生。
另一項新變化,是 Tensorflow 發布了 2.0 版本。
相對 1.X 版本,這個大版本的變化,我在《如何用 Python 和 BERT 做中文文本二元分類?》一文中,已經粗略地為你介紹過了。簡要提煉一下,就是:
之前的版本,以計算圖為中心。開發者需要為這張圖服務。因此,引入了大量的不必要術語。新版本以人為中心,用戶撰寫高階的簡潔語句,框架自動將其轉化為對應的計算圖。
之前的版本,缺少目前競爭框架(如 PyTorch 等)包含的新特性。例如計算圖動態化、運行中調試功能等。
但對普通開發者來說,最為重要的是,官方文檔和教程變得對用戶友好許多。不僅寫得清晰簡明,更靠著Google Colab的支持,全都能一鍵運行。我嘗試了 2.0 版本的一些教程樣例,確實感覺大不一樣了。

其實你可能會覺得奇怪—— Tensorflow 大張旗鼓宣傳的大版本改進,其實也無非就是向著 PyTorch早就有的功能靠攏而已嘛。那我干脆去學 PyTorch 好了!
如果我們只說道理,這其實沒錯。然而,還是前面那個論斷,一個框架好不好,主要看是否開發活躍、社區支持完善。這就是一個自證預言。一旦人們都覺得 Tensorflow 好用,那么 Tensorflow 就會更好用。因為會有更多的人參與進來,幫助反饋和改進。
看看現在 PyTorch 的 Github 頁面。
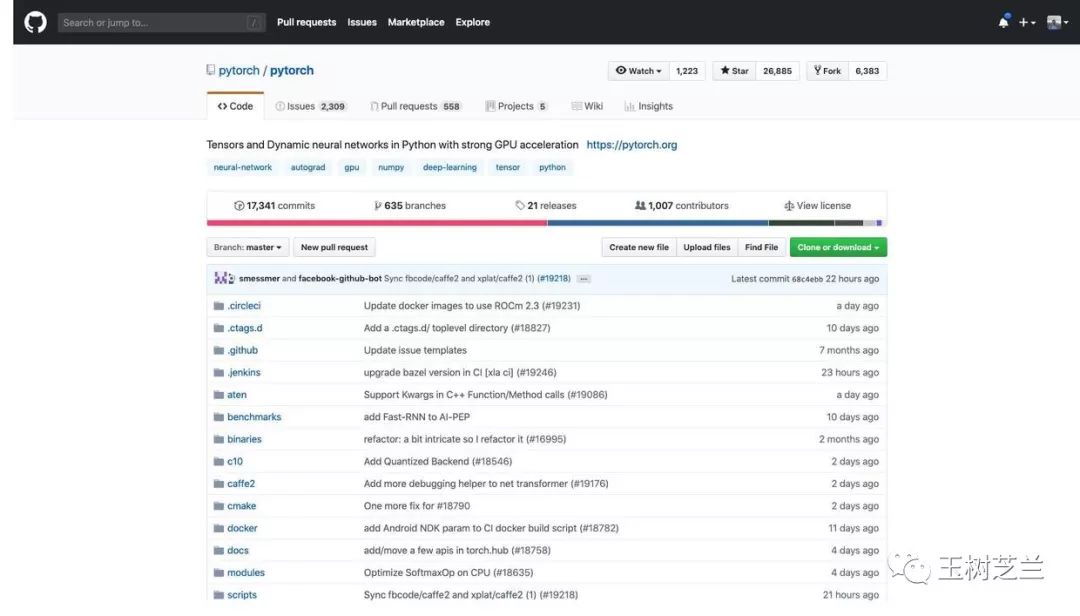
受關注度,確實已經很高了。
然而你再看看 Tensorflow 的。

至少在目前,二者根本不在一個數量級。
Tensorflow 的威力,不只在于本身構建和訓練模型是不是好用。那其實只是深度學習中,非常小的一個環節。不信?你在下圖里找找看。
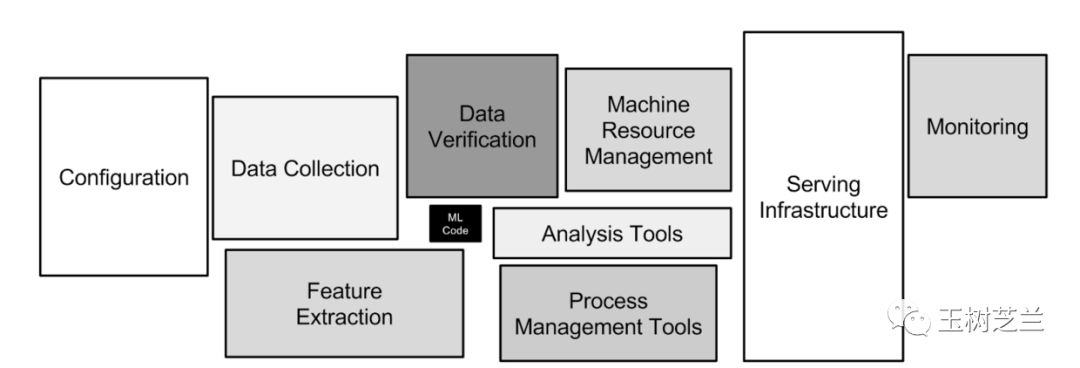
真正的問題,在于是否有完整的生態環境支持。其中的邏輯,我在《學 Python ,能提升你的競爭力嗎?》一文中,已經為你詳細分析過了。
而 Tensorflow ,早就通過一系列的布局,使得其訓練模型可以直接快速部署,最快速度鋪開,幫助開發者占領市場先機。

如果你使用 PyTorch ,那么這樣的系統,是相對不完善的。當然你可以在 PyTorch 中訓練,然后轉換并且部署到 Tensorflow 里面。畢竟三巨頭達成了協議,標準開放,這樣做從技術上并不困難。

但是,人的認知帶寬,是非常有限的。大部分人,是不會選擇在兩個框架甚至生態系統之間折騰的。這就是路徑依賴。
所以,別左顧右盼了,認認真真學 Tensorflow 2.0 吧。
這篇文章里面,我給你介紹,如何用 Tensorflow 2.0 ,來訓練神經網絡,對用戶流失數據建立分類模型,從而可以幫你見微知著,洞察風險,提前做好干預和防范。
數據
你手里擁有的,是一份銀行歐洲區客戶的數據,共有10000條記錄。客戶主要分布在法國、德國和西班牙。

數據來自于匿名化處理后的真實數據集,下載自 superdatascience 官網。
從表格中,可以讀取的信息,包括客戶們的年齡、性別、信用分數、辦卡信息等。客戶是否已流失的信息在最后一列(Exited)。
這份數據,我已經上傳到了這個地址,你可以下載,并且用 Excel 查看。
環境
本文的配套源代碼,我放在了這個 Github 項目中。請你點擊這個鏈接(http://t.cn/EXffmgX)訪問。

如果你對我的教程滿意,歡迎在頁面右上方的 Star 上點擊一下,幫我加一顆星。謝謝!
注意這個頁面的中央,有個按鈕,寫著“在 Colab 打開” (Open in Colab)。請你點擊它。
然后,Google Colab 就會自動開啟。
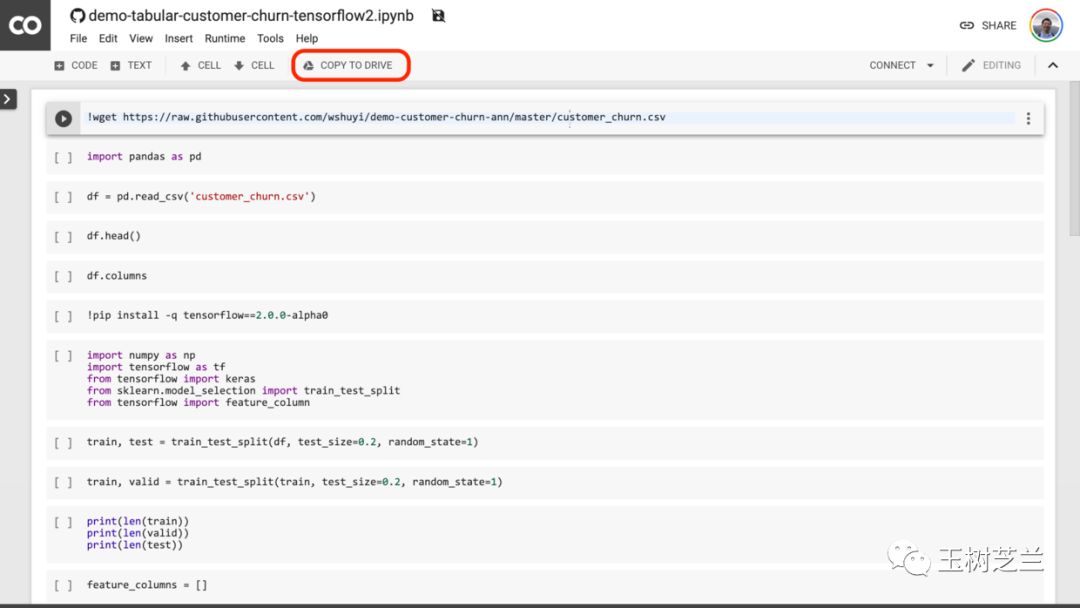
我建議你點一下上圖中紅色圈出的 “COPY TO DRIVE” 按鈕。這樣就可以先把它在你自己的 Google Drive 中存好,以便使用和回顧。

Colab 為你提供了全套的運行環境。你只需要依次執行代碼,就可以復現本教程的運行結果了。
如果你對 Google Colab 不熟悉,沒關系。我這里有一篇教程,專門講解 Google Colab 的特點與使用方式。
為了你能夠更為深入地學習與了解代碼,我建議你在 Google Colab 中開啟一個全新的 Notebook ,并且根據下文,依次輸入代碼并運行。在此過程中,充分理解代碼的含義。
這種看似笨拙的方式,其實是學習的有效路徑。
代碼
首先,我們下載客戶流失數據集。
!wgethttps://raw.githubusercontent.com/wshuyi/demo-customer-churn-ann/master/customer_churn.csv
載入 Pandas 數據分析包。
importpandasaspd
利用 read_csv 函數,讀取 csv 格式數據到 Pandas 數據框。
df=pd.read_csv('customer_churn.csv')
我們來看看前幾行顯示結果:
df.head()

顯示正常。下面看看一共都有哪些列。
df.columns

我們對所有列,一一甄別。
RowNumber:行號,這個對于模型沒用,忽略
CustomerID:用戶編號,這個是順序發放的,忽略
Surname:用戶姓名,對流失沒有影響,忽略
CreditScore:信用分數,這個很重要,保留
Geography:用戶所在國家/地區,這個有影響,保留
Gender:用戶性別,可能有影響,保留
Age:年齡,影響很大,年輕人更容易切換銀行,保留
Tenure:當了本銀行多少年用戶,很重要,保留
Balance:存貸款情況,很重要,保留
NumOfProducts:使用產品數量,很重要,保留
HasCrCard:是否有本行信用卡,很重要,保留
IsActiveMember:是否活躍用戶,很重要,保留
EstimatedSalary:估計收入,很重要,保留
Exited:是否已流失,這將作為我們的標簽數據
確定了不同列的含義和價值,下面我們處理起來,就得心應手了。
數據有了,我們來調入深度學習框架。
因為本次我們需要使用 Tensorflow 2.0 ,而寫作本文時,該框架版本尚處于 Alpha 階段,因此 Google Colab 默認使用的,還是 Tensorflow 1.X 版本。要用 2.0 版,便需要顯式安裝。
!pipinstall-qtensorflow==2.0.0-alpha0
安裝框架后,我們載入下述模塊和函數,后文會用到。
importnumpyasnpimporttensorflowastffromtensorflowimportkerasfromsklearn.model_selectionimporttrain_test_splitfromtensorflowimportfeature_column
這里,我們設定一些隨機種子值。這主要是為了保證結果可復現,也就是在你那邊的運行結果,和我這里盡量保持一致。這樣我們觀察和討論問題,會更方便。
首先是 Tensorflow 中的隨機種子取值,設定為 1 。
tf.random.set_seed(1)
然后我們來分割數據。這里使用的是 Scikit-learn 中的 train_test_split 函數。指定分割比例即可。
我們先按照80:20的比例,把總體數據分成訓練集和測試集。
train,test=train_test_split(df,test_size=0.2,random_state=1)
然后,再把現有訓練集的數據,按照80:20的比例,分成最終的訓練集,以及驗證集。
train,valid=train_test_split(train,test_size=0.2,random_state=1)
這里,我們都指定了 random_state ,為的是保證咱們隨機分割的結果一致。
我們看看幾個不同集合的長度。
print(len(train))print(len(valid))print(len(test))

驗證無誤。下面我們來做特征工程(feature engineering)。
因為我們使用的是表格數據(tabular data),屬于結構化數據。因此特征工程相對簡單一些。
先初始化一個空的特征列表。
feature_columns=[]
然后,我們指定,哪些列是數值型數據(numeric data)。
numeric_columns=['CreditScore','Age','Tenure','Balance','NumOfProducts','EstimatedSalary']
可見,包含了以下列:
CreditScore:信用分數
Age:年齡
Tenure:當了本銀行多少年用戶
Balance:存貸款情況
NumOfProducts:使用產品數量
EstimatedSalary:估計收入
對于這些列,只需要直接指定類型,加入咱們的特征列表就好。
forheaderinnumeric_columns:feature_columns.append(feature_column.numeric_column(header))
下面是比較講究技巧的部分了,就是類別數據。
先看看都有哪些列:
categorical_columns=['Geography','Gender','HasCrCard','IsActiveMember']
Geography:用戶所在國家/地區
Gender:用戶性別
HasCrCard:是否有本行信用卡
IsActiveMember:是否活躍用戶
類別數據的特點,在于不能直接用數字描述。例如 Geography 包含了國家/地區名稱。如果你把法國指定為1, 德國指定為2,電腦可能自作聰明,認為“德國”是“法國”的2倍,或者,“德國”等于“法國”加1。這顯然不是我們想要表達的。
所以我這里編了一個函數,把一個類別列名輸入進去,讓 Tensorflow 幫我們將其轉換成它可以識別的類別形式。例如把法國按照 [0, 0, 1],德國按照 [0, 1, 0] 來表示。這樣就不會有數值意義上的歧義了。
defget_one_hot_from_categorical(colname):categorical=feature_column.categorical_column_with_vocabulary_list(colname,train[colname].unique().tolist())returnfeature_column.indicator_column(categorical)
我們嘗試輸入 Geography 一項,測試一下函數工作是否正常。
geography=get_one_hot_from_categorical('Geography');geography

觀察結果,測試通過。
下面我們放心大膽地把所有類別數據列都在函數里面跑一遍,并且把結果加入到特征列表中。
forcolincategorical_columns:feature_columns.append(get_one_hot_from_categorical(col))
看看此時的特征列表內容:
feature_columns

6個數值類型,4個類別類型,都沒問題了。
下面該構造模型了。
我們直接采用 Tensorflow 2.0 鼓勵開發者使用的 Keras 高級 API 來拼搭一個簡單的深度神經網絡模型。
fromtensorflow.kerasimportlayers
我們把剛剛整理好的特征列表,利用 DenseFeatures 層來表示。把這樣的一個初始層,作為模型的整體輸入層。
feature_layer=layers.DenseFeatures(feature_columns);feature_layer

下面,我們順序疊放兩個中間層,分別包含200個,以及100個神經元。這兩層的激活函數,我們都采用 relu 。
relu 函數大概長這個樣子:

model=keras.Sequential([feature_layer,layers.Dense(200,activation='relu'),layers.Dense(100,activation='relu'),layers.Dense(1,activation='sigmoid')])
我們希望輸出結果是0或者1,所以這一層只需要1個神經元,而且采用的是 sigmoid 作為激活函數。
sigmoid 函數的長相是這樣的:

模型搭建好了,下面我們指定3個重要參數,編譯模型。
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
這里,我們選擇優化器為 adam 。
因為評判二元分類效果,所以損失函數選的是 binary_crossentropy。
至于效果指標,我們使用的是準確率(accuracy)。
模型編譯好之后。萬事俱備,只差數據了。
你可能納悶,一上來不就已經把訓練、驗證和測試集分好了嗎?
沒錯,但那只是原始數據。我們模型需要接收的,是數據流。
在訓練和驗證過程中,數據都不是一次性灌入模型的。而是一批次一批次分別載入。每一個批次,稱作一個 batch;相應地,批次大小,叫做 batch_size 。
為了方便咱們把 Pandas 數據框中的原始數據轉換成數據流。我這里編寫了一個函數。
defdf_to_tfdata(df,shuffle=True,bs=32):df=df.copy()labels=df.pop('Exited')ds=tf.data.Dataset.from_tensor_slices((dict(df),labels))ifshuffle:ds=ds.shuffle(buffer_size=len(df),seed=1)ds=ds.batch(bs)returnds
這里首先是把數據中的標記拆分出來。然后根據把數據讀入到 ds 中。根據是否是訓練集,我們指定要不要需要打亂數據順序。然后,依據 batch_size 的大小,設定批次。這樣,數據框就變成了神經網絡模型喜聞樂見的數據流。
train_ds=df_to_tfdata(train)valid_ds=df_to_tfdata(valid,shuffle=False)test_ds=df_to_tfdata(test,shuffle=False)
這里,只有訓練集打亂順序。因為我們希望驗證和測試集一直保持一致。只有這樣,不同參數下,對比的結果才有顯著意義。
有了模型架構,也有了數據,我們把訓練集和驗證集扔進去,讓模型嘗試擬合。這里指定了,跑5個完整輪次(epochs)。
model.fit(train_ds,validation_data=valid_ds,epochs=5)

你會看到,最終的驗證集準確率接近80%。
我們打印一下模型結構:
model.summary()

雖然我們的模型非常簡單,卻也依然包含了23401個參數。
下面,我們把測試集放入模型中,看看模型效果如何。
model.evaluate(test_ds)

依然,準確率接近80%。
還不錯吧?
……
真的嗎?
疑惑
如果你觀察很仔細,可能剛才已經注意到了一個很奇特的現象:

訓練的過程中,除了第一個輪次外,其余4個輪次的這幾項重要指標居然都沒變!
它們包括:
訓練集損失
訓練集準確率
驗證集損失
驗證集準確率
所謂機器學習,就是不斷迭代改進啊。如果每一輪下來,結果都一模一樣,這難道不奇怪嗎?難道沒問題嗎?
我希望你,能夠像偵探一樣,揪住這個可疑的線索,深入挖掘進去。
這里,我給你個提示。
看一個分類模型的好壞,不能只看準確率(accuracy)。對于二元分類問題,你可以關注一下 f1 score,以及混淆矩陣(confusion matrix)。
如果你驗證了上述兩個指標,那么你應該會發現真正的問題是什么。
下一步要窮究的,是問題產生的原因。
回顧一下咱們的整個兒過程,好像都很清晰明了,符合邏輯啊。究竟哪里出了問題呢?
如果你一眼就看出了問題。恭喜你,你對深度學習已經有感覺了。那么我繼續追問你,該怎么解決這個問題呢?
歡迎你把思考后的答案在留言區告訴我。
對于第一名全部回答正確上述問題的讀者,我會邀請你作為嘉賓,免費(原價199元)加入我本年度的知識星球。當然,前提是你愿意。
小結
希望通過本文的學習,你已掌握了以下知識點:
Tensorflow 2.0 的安裝與使用;
表格式數據的神經網絡分類模型構建;
特征工程的基本流程;
數據集合的隨機分割與利用種子數值保持一致;
數值型數據列與類別型數據列的分別處理方式;
Keras 高階 API 的模型搭建與訓練;
數據框轉化為 Tensorflow 數據流;
模型效果的驗證;
缺失的一環,也即本文疑點產生的原因,以及正確處理方法。
希望本教程對于你處理表格型數據分類任務,能有幫助。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975 -
tensorflow
+關注
關注
13文章
328瀏覽量
60498
原文標題:怎樣搞定分類表格數據?有人用TF2.0構建了一套神經網絡 | 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論