 深度學習框架PaddlePaddle在百度內部的戰略地位進行了定調
深度學習框架PaddlePaddle在百度內部的戰略地位進行了定調
深度學習已經推動人工智能進入工業大生產階段,而深度學習框架則是智能時代的操作系統。
在4月23日下午的Wave Summit深度學習開發者峰會上,百度高級副總裁王海峰開場就為深度學習框架PaddlePaddle在百度內部的戰略地位進行了定調。
王海峰表示,人類已經經歷了三次工業革命:機械技術、電器技術以及信息技術,而這些都是從一個行業開始,然后擴展到各行各業,直到我們生活的各個角落。而這些為我們的生活帶來深刻變革的技術往往有很強的通用性,包括標準化、自動化和模塊化。如今,我們正進入第四次工業革命——智能時代,而人工智能是第四次工業革命核心驅動力量。
人工智能經歷了人工規則、機器學習,而深度學習的出現則帶來了很多新的變化,包括語音識別、語音合成、計算機視覺、自然語言處理、機器翻譯等等都因為深度學習取得了更好的效果。王海峰認為,深度學習技術已經具備了很強的通用性,正在推動人工智能進入工業大生產階段,呈現出標準化、自動化和模塊化的特點。深度學習框架承上啟下,下接芯片、大型計算機系統,上承各種業務模型、行業應用,是智能時代的操作系統。
作為最早研究深度學習技術的公司之一,百度早在2013年即設立了深度學習研究院,并于2016年正式開源深度學習框架,而PaddlePaddle也身負百度搶占人工智能時代高地的重要使命。
在發布幾年之后,PaddlePaddle不再與TensorFlow、PyTorch等正面競爭,而是開始強調自己更懂中文,更懂中國開發者,以及更加專注于深度學習模型的工業生產和部署,并給自己取了個中文名「飛槳」。
為籠絡開發者,現場百度深度學習技術平臺部總監馬艷軍還宣布了“1億元” 的AI Studio算力支持計劃,為開發者免費提供昂貴的計算資源。
在此次的技術升級中,PaddlePaddle除了發布了11項新特性及服務,還首次展示了PaddlePaddle的全景圖和未來的Roadmap,更加凸顯了PaddlePaddle的戰略地位。
PaddlePaddle全景圖

PaddlePaddle可以分為核心框架、工具組件、服務平臺。
核心框架支持從開發到訓練到預測,以及智能推薦工具集PaddleRec、NLP工具集PaddleNLP、計算機視覺PaddleCV工具集,并且支持超過60個模型。
工具組件則包括預訓練模型管理框架PaddleHub,強化學習框架PARL,基于PaddlePaddle的AutoDL技術實現AutoDL Design,數據可視化工具庫VisualDL,以及支持彈性深度學習計算的EDL。
服務平臺則主要由可定制化訓練深度學習模型的EasyDL以及一站式開發平臺AI Studio組成。EasyDL目前已經支持圖像識別、文本分類、聲音分類等深度學習模型的訓練,而AI Studio則集合了AI教程、代碼環境、算法算力、數據集和比賽,屬于百度大腦的深度學習實訓平臺。
而此次重磅發布的更新則涉及11項新特性及服務,包含PaddleNLP、視頻識別工具集、Paddle Serving、PaddleSlim、AutoDL Design等多種深度學習開發、訓練、預測環節。
開發環節

PaddleNLP
PaddlePaddle支持CV、NLP以及推薦系統三大類別的一系列模型算法,目前官方能夠支持的模型數量已經超過60個,而且已經經過真實業務場景的驗證。
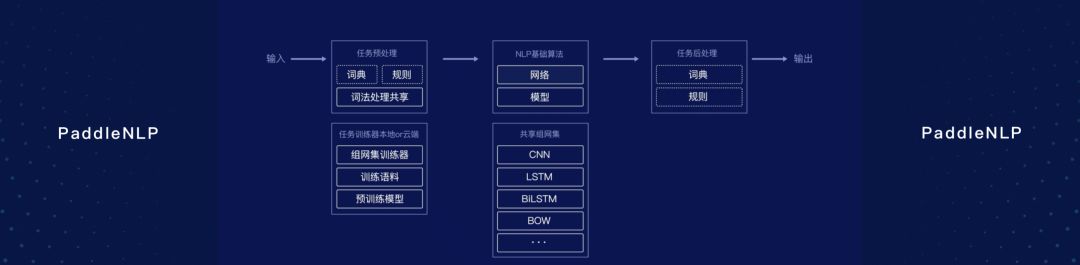
PaddleNLP一直是PaddlePaddle的核心組件,囊括了諸多工業級中文NLP算法和模型庫,涵蓋文本分類、序列標注、語義匹配等多種NLP任務的解決方案,而這一次百度對又PaddleNLP進行了中大升級。
首先,百度把NLP這個領域的模型做了一套共享骨架代碼,每一個模型都可以用同一套API和類似的模式,大大降低了操作的復雜程度;其次,這個工具包可以支持主流的中文處理任務,并且能夠實現工業級的應用效果。

PaddleNLP由基礎網絡層和應用任務層構成。基礎網絡層是表示層,包括語義表示、語言模型、序列標注、文本分類、語義匹配、語言生成與復雜任務等組網集合。
分類組網集:可用于文本分類的深度學習網絡結構,輸入為文本中每個字、詞的ID,輸出為文本屬于各個類別的概率。包括:BOW、CNN、GRU、LSTM、BiLSTM。
語義表示組網集:可用于文本表示的深度學習網絡結構,輸入為文本中每個字、詞的ID,輸出為文本中每個字詞的embedding。包括:BERT、ELMo、ERNIE。
語義匹配組網集:可用于計算短文本相似度的深度學習網絡結構,輸入為兩個文本中每個詞的ID,輸出為二者的相似度得分。包括:BOW、CNN、GRU、LSTM、MMDNN。
序列化標注組網集:可用于計算序列標注的深度學習網絡結構,輸入為文本中每個字的ID,輸出為文本中每個字所屬各個標注的概率。目前主要有BiGRU-CRF。
語言模型組網集:可以用于計算句子概率的深度學習網絡結構,目前主要有LSTM。
復雜模型組網集:可以處理復雜任務的深度學習網絡結構,包括閱讀理解、對話等任務。包括:BERT、BiDAF。
基于這些網絡結構,同時再配套任務相關的工具和數據,PaddleNLP可以實現一系列的應用任務,包括詞法分析、情感分類等,未來百度還會進一步擴充PaddleNLP的能力。

PaddleNLP還集成了百度近期發布的最新語義表示預訓練模型——ERNIE。馬艷軍表示,ERNIE把中文領域處理的一些知識融入到建模的過程當中,從而提升整個語義表示的效果,它很多中文任務上它的Benchmarck都比現在最好的效果要好不少。
此外,PaddleNLP的另一大亮點則是在模型訓練階段可靈活切換基礎網絡結構,在任務預測過程中可靈活組合訓練好的模型,大大提高了模型開發的靈活性。
視頻識別工具集

除了NLP工具集,此次更新的還有視頻識別的工具集。這個工具集覆蓋當前7個經典的視頻分類模型,包括TSN、Non-Local、stNet、TSM、Attention LSTM、Attention Cluster、NextVLAD。這些模型共享同一套配置文件,并且在數據的讀取、評估等方面共享一套代碼,并使用統一的訓練和預測的框架。
據介紹,這些視頻理解的技術已經在很多場景下得到了應用,并且已經在諸多百度產品上廣泛使用。
訓練環節
針對訓練環節,PaddlePaddle也發布了兩項重要升級:第一是大規模分布式訓練的能力升級,第二是工業級數據處理能力的升級。
大規模分布式訓練

對于大規模分布式訓練,PaddlePaddle推出了三個主要特性:
全方位支持多機多卡,速度提升。
在CPU的應用場景,針對大規模稀疏特征,PaddlePaddle設計并且開放了大規模稀疏參數服務器,開發者可以下載相關的鏡像。
大規模分布式訓練支持在各種容器上高速運行,如今在K8S這個生態下也可以使用PaddlePaddle進行訓練。
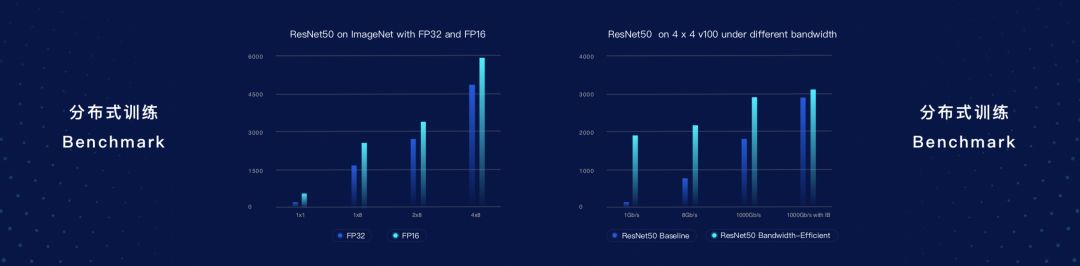
針對多機多卡的訓練場景,在ResNet50數據集上進行測試,保持精度不變的情況下,FP16的訓練速度要比FP32要快很多。此外,PaddlePaddle還做了帶寬不敏感的技術,在ResNet50數據集上,帶寬不敏感相關的技術在性能和效果方面也有非常出色的表現。
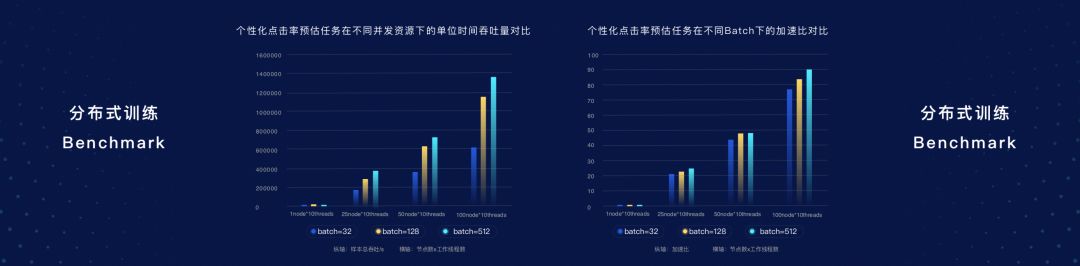
在CPU場景下進行基于個性化點擊率預估任務場景測試,可以發現,不同并發資源下單位時間的吞吐量,不同的Batch Size下面加速比,都呈現線性的增長狀態,可以直接應用到工業場景。
預測環節
模型在訓練和開發完整之后需要部署到各個應用場景,這里面涉及到幾個重要環節。首先,我們需要高速的推理引擎;在這個基礎之上,為了部署在更多的硬件上,我們常常需要做模型壓縮;最后,為了真正投入使用,還需要有相應的硬件。

上圖是PaddlePaddle完整的端到端的全流程部署方案。
底層:在服務器端,PaddlePaddle已經支持了比較主流的CPU和GPU;在移動端,PaddlePaddle支持多種CPU和GPU,包括ARM的CPU以及Mali GPU等。對其他硬件的支持也正在快速擴充中。
推理引擎:在底層硬件之上就是推理引擎,一方面是底層的加速庫,另外就是在服務器端和移動端做推理的能力。
多語言支持:PaddlePaddle目前已經支持Python、C++,后續還會支持JaveScript等編程語言。
工具:PaddlePaddle這次正式發布的是一整套壓縮工具,可以不同的端上把模型壓到最小,同時又不損失精度。
方案與服務:此外,PaddlePaddle還提供完整的方案,比如專用的硬件和部署的手冊說明等等,方便開發者部署和使用。
推理引擎
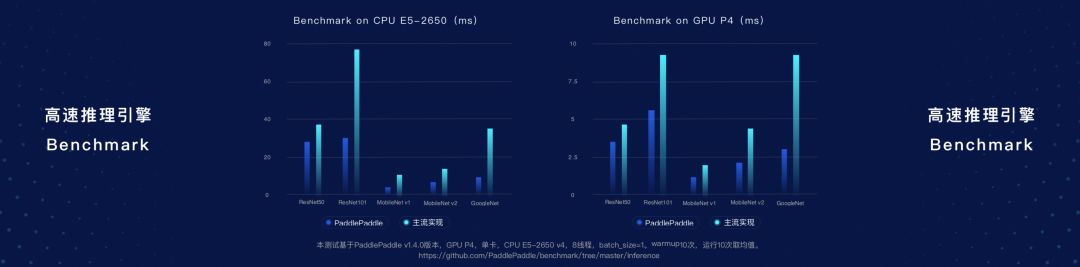
PaddlePaddle在推理引擎方面做了大量工作,能夠實現推理加速,提升用戶的體驗。據介紹,跟某主流框架的對比,在不同的GPU場景下,PaddlePaddle在多個模型推理的速度上展現了非常顯著的加速效果。
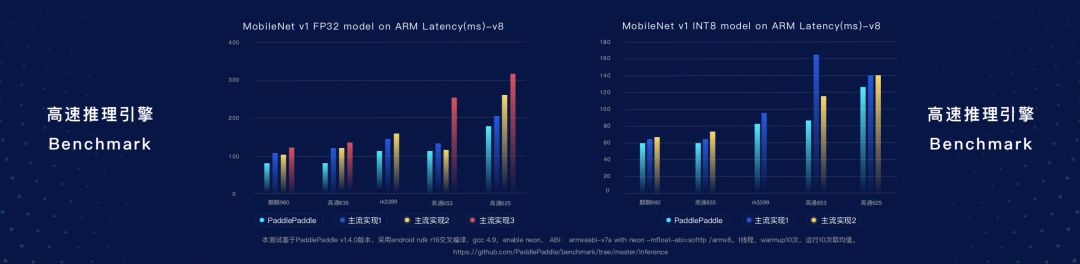
另外,在移動端(ARM處理器),用MobileNet進行測試,PaddlePaddle也實現了很好的效果。
Paddle Serving
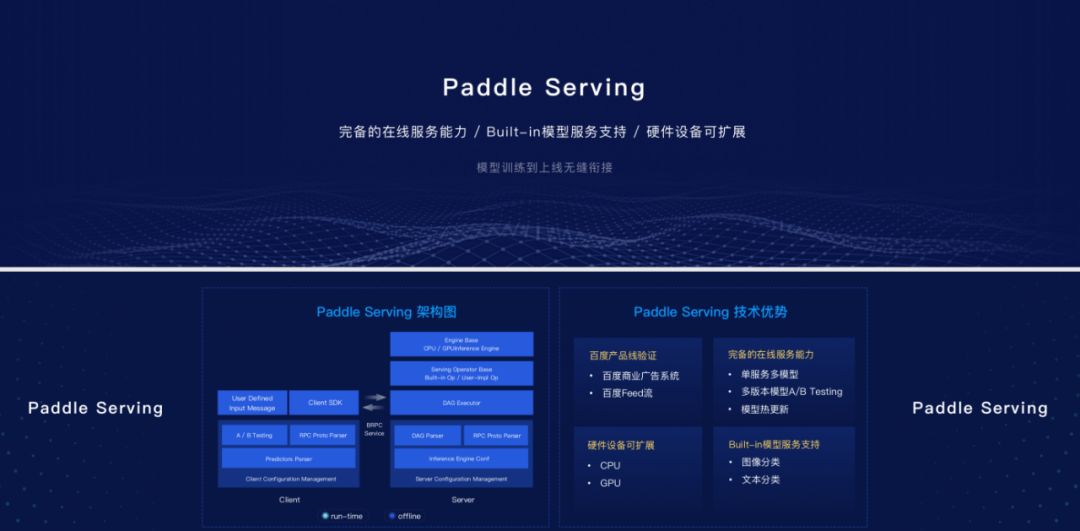
針對服務器端,此次PaddlePaddle也終于開放了Serving的能力,可以實現模型從訓練到上線服務器的無縫對接。Paddle Serving還內置了諸多模型,可以實現批量預測。其架構圖顯示,Paddle Serving有離線的準備和在線的實現,另外還有基本的Built-in的一些預處理執行器。
Paddle Serving可以提供非常完備的在線服務能力,包括單服務多個模型,包括多版本的模型A/B Testing,模型的熱更新等等這些能力。硬件也是可擴展的,包括CPU、GPU。同時,還有內置了多個模型服務,包括圖像分類、文本分類等。
PaddleSlim

在移動端部署深度學習模型常常要考慮模型的大小,因此模型壓縮的能力在移動端的場景下是一個剛需。PaddleSlim做了參數集中管理,可以對模型進行自動壓縮,并且提升了操作的便利程度,開發者只需要兩行Python代碼就可以調自動化的模型壓縮能力。目前PaddleSlim支持三種主要的壓縮能力,包括剪枝、量化以及蒸餾的方法。
工具
除了從開發到訓練到部署的全流程,PaddlePaddle還更新了幾款工具組件:自動化網絡設計工具AutoDL Design,強化學習工具PARL,以及預訓練一站式管理工具PaddleHub。
AutoDL Design
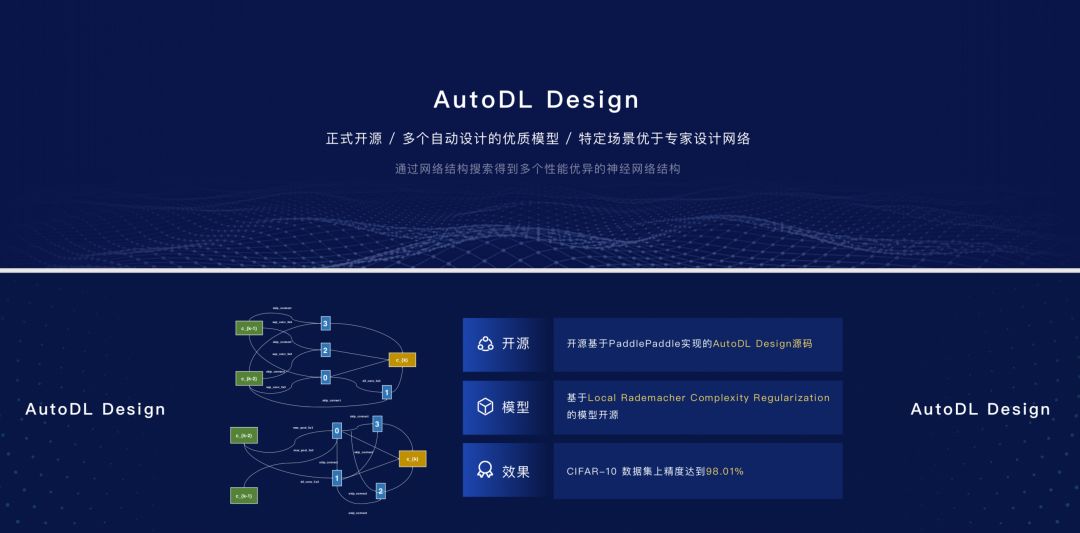
AutoDL是一種高效的自動搜索構建最佳網絡結構的方法,通過增強學習在不斷訓練過程中得到定制化高質量的模型。系統由兩部分組成,第一部分是網絡結構的編碼器,第二部分是網絡結構的評測器。這次PaddlePaddle發布的AutoDL Design的版本,主要是基于PaddlePaddle和PARL來實現,并且已經開源。
PARL

PaddlePaddle針對強化學習的工具PARL進行了諸多升級,在算法覆蓋、高性能通訊以及并行訓練方面做了大量的支持和擴展。百度前一段時間在NeurIPS獲得AI假尸挑戰賽冠軍的模型,運用了Target Driven DDPG + Bootstrapping的方法實現,并取得了很好地效果。
PaddleHub

PaddleHub是基于PaddlePaddle開發的預訓練模型管理工具,可以借助預訓練模型更便捷地開展遷移學習工作。利用這個平臺,只需10行左右的代碼就可以實現遷移學習,從而在自己的任務場景下使用。
架構圖顯示,PaddleHub封裝了一系列的NLP和CV領域的數據集,同時還在數據的處理方面做了Reader封裝。PaddleHub目前已經支持5大類的預訓練模型,包括Transformer分析等等,還有幾類模型會在后續陸續開放。同時,PaddleHub還支持文本分類、序列標注等任務場景下的遷移,并提供了兩種優化策略來提升遷移學習的效果。最后,PaddleHub還提供Finetune API和命令行,保證開發者可以快速使用PaddleHub來做遷移學習。
Roadmap
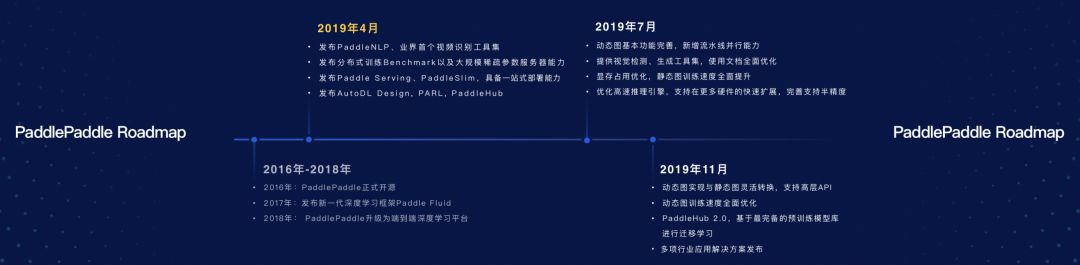
在2016年百度開源了PaddlePaddle,并且在2017年、2018年的時間內陸續把PaddlePaddle Fluid新一代的深度學習框架做了完善,并發布了穩定的1.0版本。根據PaddlePaddle的Roadmap,7月PaddlePaddle還會發布Fluid動態圖分布式訓練的功能,以及會新增流水線并行的能力,分布式訓練會變得更快。11月PaddlePaddle會實現動態圖的能力與靜態圖的靈活轉換,讓開發更加便捷,兼顧效率和性能。
2019年7月:
動態圖基本功能完善,新增流水線并行能力
提供視覺檢測、生成工具集,使用文檔全面優化
顯存占用優化,靜態圖訓練速度全面提升
優化高速推理引擎,支持在更多硬件的快速擴展,完善支持半精度
2019年11月:
動態圖實現與靜態圖靈活轉換,支持高層 API
動態圖訓練速度全面優化
PaddleHub 升級到 2.0,基于最完備的預訓練模型庫進行遷移學習
多項行業應用解決方案發布
“1億元” 籠絡人心
想要籠絡開發者的心,單靠這些功能更新顯然不行,畢竟TensorFlow、PyTorch等已經十分強大。因此百度還推出了“1億元”的AI Studio算力支持計劃。

馬艷軍介紹,開發者可以免費申請使用工業級應用的一些旗艦型的GPU硬件,這次主要是V100,另外還提供免費、免安裝的集成環境,直接上手使用。
具體的使用模式有兩種,第一種是一人一卡的模式,包括16G的顯存,最高2T的存儲空間。第二種是遠程集群模式,開發者只要登錄AI Studio做預測,就可以免費使用上面的算力資源。
除了免費算力,PaddlePaddle還會提供各種深度學習的培訓、認證等等,壯大自己的朋友圈,打造自己的開發者生態,讓更多開發者來使用百度云服務,最終實現AI的商業化落地。
2018年7月,李彥宏在百度AI開發者上喊出了要讓“Everyone Can AI”的口號,PaddlePaddle具有重要的戰略地位。不過,CSDN的《2018-2019中國開發者調查報告》顯示,目前國內絕大部分的開發者依然選擇主流的深度學習開發框架,PaddlePaddle依然任重道遠。
-
人工智能
+關注
關注
1791文章
46863瀏覽量
237587 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45928 -
深度學習
+關注
關注
73文章
5493瀏覽量
120979
原文標題:薅百度GPU羊毛!PaddlePaddle大升級,比Google更懂中文,打響AI開發者爭奪戰
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
李彥宏宣布:百度文心大模型日調用量超15億
TensorFlow與PyTorch深度學習框架的比較與選擇
百度推出全新智能代碼助手文心快碼,引領編碼效率新革命
百度發布文心大模型4.0 Turbo與飛槳框架3.0,引領AI技術新篇章
百度WAVE SUMMIT深度學習開發者大會,文心大模型4.0 Turbo震撼發布
2024百度移動生態萬象大會:百度新搜索11%內容已AI生成
百度與特斯拉探討Robotaxi合作新機遇
現代汽車、起亞與百度簽署智能網聯汽車戰略合作框架協議
百度智能云與全球知名咨詢服務機構畢馬威簽署戰略合作協議
百度智能云正式發布了《百度智能云水業大模型白皮書》






 工商網監
工商網監
評論