") 生成對(duì)抗網(wǎng)絡(luò)與其他生成模型之間的權(quán)衡取舍是什么?
生成對(duì)抗網(wǎng)絡(luò)與其他生成模型之間的權(quán)衡取舍是什么?
根據(jù)一些指標(biāo)顯示,關(guān)于生成對(duì)抗網(wǎng)絡(luò)(GAN)的研究在過去兩年間取得了本質(zhì)的進(jìn)步。在圖像合成模型實(shí)踐中的進(jìn)步快到幾乎無法跟上。
但是,根據(jù)其他指標(biāo)來看,實(shí)質(zhì)性的改進(jìn)還是較少。例如,在應(yīng)如何評(píng)價(jià)生成對(duì)抗網(wǎng)絡(luò)(GAN)仍存在廣泛的分歧。鑒于當(dāng)前的圖像合成基線標(biāo)準(zhǔn)已經(jīng)非常高,似乎快達(dá)到了飽和,因此我們認(rèn)為現(xiàn)在思考這一細(xì)分領(lǐng)域的研究目標(biāo)恰逢其時(shí)。
在這篇文章中,谷歌大腦團(tuán)隊(duì)的 Augustus Odena 就針對(duì) GAN 的七大開放性問題作出了介紹。
這些問題分別是:
生成對(duì)抗網(wǎng)絡(luò)與其他生成模型之間的權(quán)衡取舍是什么?
生成對(duì)抗網(wǎng)絡(luò)可以對(duì)哪種分布進(jìn)行建模?
我們?nèi)绾卧趫D像合成外擴(kuò)展生成對(duì)抗網(wǎng)絡(luò)的應(yīng)用?
關(guān)于生成對(duì)抗網(wǎng)絡(luò)訓(xùn)練的全局收斂,我們?cè)撟骱卧u(píng)價(jià)?
我們應(yīng)如何評(píng)估生成對(duì)抗網(wǎng)絡(luò),又該在何時(shí)使用它們?
生成對(duì)抗網(wǎng)絡(luò)的訓(xùn)練是如何調(diào)整批量數(shù)據(jù)的?
對(duì)抗生成網(wǎng)絡(luò)和對(duì)抗樣本的關(guān)系是怎樣的?
生成對(duì)抗網(wǎng)絡(luò)與其他生成模型之間的權(quán)衡取舍是什么?
除了對(duì)抗生成網(wǎng)絡(luò)之外,目前流行的還有另外兩種生成模型:流模型(Flow Models)和自回歸模型(Autoregressive Models)。這個(gè)名詞不必深究其字面含義。它們只是用來描述“模型空間”中模糊聚類的有用術(shù)語(yǔ),但是有些模型很難被簡(jiǎn)單歸類為這些聚類中的哪一個(gè)。我也完全沒有考慮變分自編碼器(VAEs),因?yàn)槠湓谀壳叭魏稳蝿?wù)中都不是最先進(jìn)的。
粗略地講,流模型(Flow Models)先將來自先驗(yàn)的樣本進(jìn)行一系列可逆變換,以便可以精確計(jì)算觀測(cè)值的對(duì)數(shù)似然。另一方面,自回歸模型將觀測(cè)值的分布分解為條件分布并每次只處理觀測(cè)值的一部分(對(duì)于圖像,其每次可能只處理一個(gè)像素)。近期的研究表明,這些模型具有不同的性能特征和權(quán)衡方法。如何準(zhǔn)確地描述這些權(quán)衡并確定它們是否為該類模型簇中所固有的,這是一個(gè)有趣的開放性問題。
具體來說,先暫時(shí)考慮對(duì)抗生成網(wǎng)絡(luò)和流模型之間計(jì)算成本的差異。乍一看,流模型似乎可以使對(duì)抗生成網(wǎng)絡(luò)變得多余。流模型可以精確得進(jìn)行對(duì)數(shù)似然計(jì)算和精確推理,因此如果訓(xùn)練流模型和對(duì)抗生成網(wǎng)絡(luò)的計(jì)算成本相同,則對(duì)抗生成網(wǎng)絡(luò)可能失去用武之地。而訓(xùn)練對(duì)抗生成網(wǎng)絡(luò)需要花費(fèi)大量精力,因此我們應(yīng)該關(guān)心流模型是否能淘汰對(duì)抗生成網(wǎng)絡(luò)。即使在這種情況下,可能仍有其他理由支持在圖像到圖像翻譯等環(huán)境中使用對(duì)抗訓(xùn)練。將對(duì)抗訓(xùn)練和極大似然訓(xùn)練相結(jié)合可能仍有意義。
然而,訓(xùn)練對(duì)抗生成網(wǎng)絡(luò)和流模型所需的計(jì)算成本之間似乎存在著較大差距。為了估計(jì)這個(gè)差距的大小,我們考慮這兩個(gè)在人臉數(shù)據(jù)庫(kù)上訓(xùn)練的模型。GLOW模型(一種基于流模型的生成模型)使用40個(gè)GPU、約2億參數(shù)值訓(xùn)練,耗時(shí)兩周后生成像素為256x256的名人臉。
相比之下,高效地對(duì)抗生成網(wǎng)絡(luò)采用類似的人臉數(shù)據(jù)庫(kù),使用8個(gè)GPU、約4600萬個(gè)參數(shù)訓(xùn)練,歷時(shí)4天后生成了像素為1024x1024圖像。粗略地說,流模型比生成對(duì)抗網(wǎng)絡(luò)多花費(fèi)了17倍的GPU天數(shù)和4倍的參數(shù)來生成圖像,但其像素卻降低了16倍。這一對(duì)比并不完美。例如,流模型也可以用更好的技術(shù)方法來提高,但是這些方法能讓你有不同的感悟。
為什么流模型的效率較低?我們考慮可能是如下兩個(gè)原因:首先,極大似然訓(xùn)練在計(jì)算上比對(duì)抗訓(xùn)練更難。特別當(dāng)訓(xùn)練集的一些元素被生成模型指定為零概率,會(huì)受到無比嚴(yán)厲的懲罰!另一方面,生成對(duì)抗網(wǎng)絡(luò)的生成器僅在為訓(xùn)練集元素賦予零概率時(shí)而間接受到懲罰,并且這種懲罰不那么嚴(yán)厲。其次,標(biāo)準(zhǔn)化流(Normalizing Flow)可能在表示某些函數(shù)時(shí)較為低效。6.1節(jié)做了一些關(guān)于其效果的小實(shí)驗(yàn),但目前我們尚不知道在這個(gè)問題是否有深入的分析。
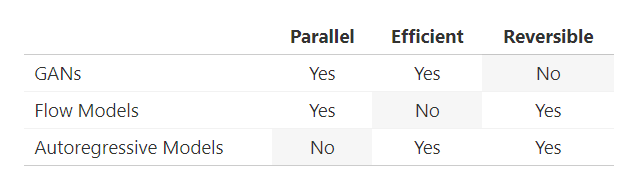
我們已經(jīng)討論過生成對(duì)抗網(wǎng)絡(luò)和流模型之間的權(quán)衡,那么自回歸模型如何?事實(shí)證明,自回歸模型可以表示為不可并行化的流模型(因?yàn)樗鼈兌际强赡娴模T谶@種情況下,可并行化的說法有點(diǎn)不精確。我們的意思是流模型的采樣通常必須按順序進(jìn)行,每次一個(gè)觀測(cè)值。不過,可能有一些方法可以繞過這個(gè)限制。事實(shí)證明,自回歸模型比流模型上在時(shí)間和參數(shù)上效率更高。因此,生成對(duì)抗網(wǎng)絡(luò)是并行、高效但不可逆的,流模型是可逆、并行但不高效,而自回歸模型是可逆的、高效,但非并行的。
回到第一個(gè)開放的問題:

解決這個(gè)問題的一種方法是研究更多模型,這些模型將是多類模型的混合。有考慮將生成對(duì)抗網(wǎng)絡(luò)和流動(dòng)模型混合,但我們認(rèn)為這種方法的研究尚不充分。
我們也不確定極大似然訓(xùn)練是否一定比生成對(duì)抗網(wǎng)絡(luò)訓(xùn)練更難。確實(shí),在生成對(duì)抗網(wǎng)絡(luò)訓(xùn)練損失下,沒有明確禁止在訓(xùn)練數(shù)據(jù)上設(shè)置一些零質(zhì)量的數(shù)據(jù),但是如果生成器這么做了,那么強(qiáng)大的鑒別器將能夠做得更好。因此,看起來生成對(duì)抗網(wǎng)絡(luò)似乎在實(shí)踐中會(huì)學(xué)習(xí)低支持的分布。
最后,我們懷疑流模型在每個(gè)參數(shù)上的表達(dá)能力上不如任意解碼器函數(shù),我們還認(rèn)為這在一些假設(shè)條件下是可以被證明的。
生成對(duì)抗網(wǎng)絡(luò)模型可以對(duì)哪種分布進(jìn)行建模?
大多數(shù)生成對(duì)抗網(wǎng)絡(luò)的研究側(cè)重于圖像合成。人們通常使用深度學(xué)習(xí)社區(qū)中幾個(gè)標(biāo)準(zhǔn)的圖像數(shù)據(jù)集上訓(xùn)練生成對(duì)抗網(wǎng)絡(luò):MNIST、CIFAR-10、STL-10、CelebA、和ImageNet。
關(guān)于這些數(shù)據(jù)集中哪一個(gè)是“最容易建模”的數(shù)據(jù),有一些觀點(diǎn)認(rèn)為MNIST和CelebA被認(rèn)為比ImageNet、CIFAR-10或STL-10更容易,因?yàn)樗鼈儭胺浅3R?guī)”。另有人認(rèn)為,“大量的類別使生成對(duì)抗網(wǎng)絡(luò)很難訓(xùn)練ImageNet圖片”。這些結(jié)果是有事實(shí)證明的,即CelebA上的最先進(jìn)圖像合成模型生成的圖像似乎比ImageNet上的最先進(jìn)圖像合成模型更令人信服。
然而,我們必須通過復(fù)雜的實(shí)踐來得出這些結(jié)論,并試圖在更大,更復(fù)雜的數(shù)據(jù)集上訓(xùn)練生成對(duì)抗網(wǎng)絡(luò)。我們特別研究了生成對(duì)抗網(wǎng)絡(luò)如何對(duì)恰好用于物體識(shí)別的數(shù)據(jù)集進(jìn)行處理。
與任何科學(xué)一樣,我們希望能夠有一個(gè)簡(jiǎn)單的理論來解釋我們的實(shí)驗(yàn)觀察結(jié)果。理想情況下,我們可以查看數(shù)據(jù)集,在不訓(xùn)練生成模型的情況下進(jìn)行一些計(jì)算,然后說“此數(shù)據(jù)集對(duì)于生成對(duì)抗網(wǎng)絡(luò)建模比變分自編碼器容易”。我們?cè)诖艘呀?jīng)取得了一些進(jìn)展,但我們認(rèn)為還有可更多的工作需要做。現(xiàn)在的問題是:

我們也可能會(huì)問以下相關(guān)問題:“給分布建模”是什么意思?我們是否對(duì)低支持率表示滿意,還是需要真正的密度模型?是否存在生成對(duì)抗網(wǎng)絡(luò)永遠(yuǎn)無法學(xué)習(xí)建模的分布?對(duì)于某些合理的資源消耗模型,是否存在理論上生成對(duì)抗網(wǎng)絡(luò)可學(xué)習(xí),但是實(shí)際上并不能有效學(xué)習(xí)的分布?對(duì)于生成對(duì)抗網(wǎng)絡(luò)而言,這些問題的答案是否與其他生成模型的有所不同?
我們提出了回答這些問題的兩種策略:
合成數(shù)據(jù)集-我們可以研究合成數(shù)據(jù)集,以探討哪些特征會(huì)影響其可學(xué)習(xí)性。例如,作者創(chuàng)建了合成三角形數(shù)據(jù)集。我們認(rèn)為這方面尚未被探索。合成數(shù)據(jù)集甚至可以根據(jù)關(guān)注的數(shù)量(例如連通性或平滑性)進(jìn)行參數(shù)化,以便進(jìn)行系統(tǒng)研究。這種數(shù)據(jù)集也可用于研究其他類型的生成模型。
修改現(xiàn)有理論結(jié)果-我們可以采用現(xiàn)有的理論結(jié)果并嘗試修改假設(shè),以考慮數(shù)據(jù)集的不同屬性。例如,我們可以獲得適用于給定單峰數(shù)據(jù)分布的生成對(duì)抗網(wǎng)絡(luò)的結(jié)果,并查看當(dāng)數(shù)據(jù)分布變?yōu)槎喾鍟r(shí)會(huì)發(fā)生什么情況。
我們?nèi)绾卧趫D像合成外擴(kuò)展生成對(duì)抗網(wǎng)絡(luò)的應(yīng)用?
除了圖像翻譯和遷移學(xué)習(xí)等應(yīng)用,大多數(shù)生成對(duì)抗網(wǎng)絡(luò)的成功都是在圖像合成中取得的。嘗試在圖像領(lǐng)域外使用生成對(duì)抗網(wǎng)絡(luò),主要集中于以下三個(gè)領(lǐng)域:
文本-文本的離散性使得我們難以應(yīng)用生成對(duì)抗網(wǎng)絡(luò)。這是因?yàn)樯蓪?duì)抗網(wǎng)絡(luò)依賴將鑒別器中的信號(hào)通過生成的文本反向傳播到發(fā)生器。解決這一困難有兩種方法。第一種是僅對(duì)離散數(shù)據(jù)的連續(xù)表示進(jìn)行生成對(duì)抗網(wǎng)絡(luò)行為。第二種是使用實(shí)際離散模型,并嘗試使用梯度估計(jì)訓(xùn)練生成對(duì)抗網(wǎng)絡(luò)。還有其它更復(fù)雜的改進(jìn)方法,但據(jù)我們所知,沒有一種方法的結(jié)果能與基于似然的語(yǔ)言模型相比較。
結(jié)構(gòu)化數(shù)據(jù)-那么其他非歐幾里得的結(jié)構(gòu)化數(shù)據(jù),如圖的應(yīng)用會(huì)怎樣?這類數(shù)據(jù)的研究稱為幾何深度學(xué)習(xí)。生成對(duì)抗網(wǎng)絡(luò)在這里取得的成果有限,但其他深度學(xué)習(xí)技術(shù)也是如此,因此很難判斷生成對(duì)抗網(wǎng)絡(luò)在這里能發(fā)揮多大作用。我們嘗試在這個(gè)領(lǐng)域中使用生成對(duì)抗網(wǎng)絡(luò),使發(fā)生器(和鑒別器)隨機(jī)游走(隨機(jī)行走等是指基于過去的表現(xiàn),無法預(yù)測(cè)將來的發(fā)展步驟和方向。),目的是盡量類似于從源圖取樣的隨機(jī)游走。
音頻-音頻是生成對(duì)抗網(wǎng)絡(luò)最可能像圖像應(yīng)用那樣大獲成功的領(lǐng)域。首次將生成對(duì)抗網(wǎng)絡(luò)應(yīng)用于無監(jiān)督音頻合成的重大嘗試是,作者在處理音頻數(shù)據(jù)時(shí)做了各種特殊寬松設(shè)置。最近的研究表明,生成對(duì)抗網(wǎng)絡(luò)在某些感知指標(biāo)上甚至能優(yōu)于自回歸模型。
盡管進(jìn)行了這些嘗試,圖像顯然是生成對(duì)抗網(wǎng)絡(luò)應(yīng)用最容易的領(lǐng)域。這使得我們思考以下問題:

擴(kuò)展到其他領(lǐng)域是需要新的訓(xùn)練技術(shù),還是僅僅需要在每個(gè)領(lǐng)域更好的隱式先驗(yàn)信息?
我們期望生成對(duì)抗網(wǎng)絡(luò)最終在其他連續(xù)數(shù)據(jù)上能實(shí)現(xiàn)類似圖像合成水平的成功,但它需要更好的隱式先驗(yàn)信息。要找到這些先驗(yàn)信息,就需要認(rèn)真思考什么是合理的、并在特定領(lǐng)域計(jì)算上是可行的。
對(duì)于結(jié)構(gòu)化數(shù)據(jù)或不連續(xù)數(shù)據(jù),我們尚不能確定。一種方法是使發(fā)生器和鑒別器都成為經(jīng)過強(qiáng)化學(xué)習(xí)訓(xùn)練的代理。但要使這種方法起作用可能需要大規(guī)模的計(jì)算資源。最后,這個(gè)問題可能只需要基礎(chǔ)研究的進(jìn)展就能解決。
關(guān)于生成對(duì)抗網(wǎng)絡(luò)訓(xùn)練的全局收斂,我們?cè)撟骱卧u(píng)價(jià)?
訓(xùn)練生成對(duì)抗網(wǎng)絡(luò)與訓(xùn)練其他神經(jīng)網(wǎng)絡(luò)不同,因?yàn)槲覀兺瑫r(shí)優(yōu)化發(fā)生器和辨別器以達(dá)到相反的目的。在某些假設(shè)下,該同步優(yōu)化是局部漸近穩(wěn)定的。
不幸的是,我們很難證明一般情況下的令人感興趣的信息。這是因?yàn)殍b別器/發(fā)生器的損失是其參數(shù)的非凸函數(shù)。但所有神經(jīng)網(wǎng)絡(luò)模型都存在此問題!我們希望能以某種方式來解決同步優(yōu)化產(chǎn)生的問題。這促使我們開始思考以下問題:

我們?cè)谶@個(gè)問題上得到了突出進(jìn)展。廣義而言,現(xiàn)有3種技術(shù),所有這些技術(shù)均呈現(xiàn)出了有前景的成果,但均未研究完成:
簡(jiǎn)化假設(shè)-第一種策略是簡(jiǎn)化關(guān)于發(fā)生器和鑒別器的假設(shè)。例如,如果采用特殊技術(shù)和一些額外假設(shè)進(jìn)行優(yōu)化,則可以證明簡(jiǎn)化的LGQ GAN(線性發(fā)生器、高斯數(shù)據(jù)和二次判別器)能夠全局收斂。如果逐漸放寬這些假設(shè),結(jié)果可能會(huì)很可觀。例如,我們可以遠(yuǎn)離單峰分布。這是很自然的就能想到的研究方式,因?yàn)椤澳J剿荨笔菢?biāo)準(zhǔn)GAN的常見問題。
使用常規(guī)神經(jīng)網(wǎng)絡(luò)技術(shù)-第二種策略是應(yīng)用用于分析常規(guī)神經(jīng)網(wǎng)絡(luò)(也是非凸型)的技術(shù)來回答有關(guān)生成對(duì)抗網(wǎng)絡(luò)收斂的問題。例如,有人認(rèn)為深度神經(jīng)網(wǎng)絡(luò)的非凸性不是問題,因?yàn)殡S著網(wǎng)絡(luò)越來越大,損失函數(shù)的較差局部極小值會(huì)在指數(shù)變化中漸漸被忽略。該分析能否“引入生成對(duì)抗網(wǎng)絡(luò)中?事實(shí)上,對(duì)用作分類器的深部神經(jīng)網(wǎng)絡(luò)進(jìn)行分析,并觀察其是否適用于生成對(duì)抗網(wǎng)絡(luò),似乎是一種具有普適性的啟發(fā)方法。
博弈論-最終策略是使用博弈論的概念對(duì)生成對(duì)抗網(wǎng)絡(luò)訓(xùn)練建模。這些技術(shù)產(chǎn)生了可證明收斂到某種近似納什均衡的訓(xùn)練過程,但卻使用了不合理的大資源約束。在這種情況下,下一步的工作是嘗試減少這些資源限制。
我們應(yīng)如何評(píng)估生成對(duì)抗網(wǎng)絡(luò),又該在何時(shí)使用它們?
在評(píng)估生成對(duì)抗網(wǎng)絡(luò)方面目前有很多方案,但幾乎沒有共識(shí)。建議包括:
Inception Score and FID——這兩個(gè)因素都使用預(yù)訓(xùn)練的圖像分類器,并且都有已知的問題。常見批評(píng)是,這些因素衡量的是“樣本質(zhì)量”,而不是“樣本多樣性”。
MS-SSIM——使用MS-SSIM來單獨(dú)評(píng)估多樣性,但這種技術(shù)存在一些問題,而且還沒有真正廣泛使用。
AIS——在生成對(duì)抗網(wǎng)絡(luò)輸出上建立高斯觀測(cè)模型,并使用退火算法重要性采樣來預(yù)估該模型下的對(duì)數(shù)似然,但如果生成對(duì)抗網(wǎng)絡(luò)發(fā)生器也是流模型的話,以這種方式計(jì)算的估計(jì)就是不準(zhǔn)確的了。
幾何評(píng)分——計(jì)算生成的數(shù)據(jù)流形的幾何特性,并將這些特性與實(shí)際數(shù)據(jù)進(jìn)行比較。
精確性和召回——嘗試測(cè)量生成對(duì)抗網(wǎng)絡(luò)的“精確性”和“召回率”。
技能等級(jí)——表明訓(xùn)練過的生成對(duì)抗網(wǎng)絡(luò)鑒別器可以包含有用的信息,以便進(jìn)行評(píng)估。
這些只是大家提議的生成對(duì)抗網(wǎng)絡(luò)評(píng)估方案的一小部分。雖然IS和FID相對(duì)比較流行,但是生成對(duì)抗網(wǎng)絡(luò)評(píng)估問題顯然還未解決。最后,我們認(rèn)為“如何評(píng)價(jià)生成對(duì)抗網(wǎng)絡(luò)”這一問題源于“何時(shí)使用生成對(duì)抗網(wǎng)絡(luò)”這一問題。因此,我們將這兩個(gè)問題合并為一個(gè)問題:

我們應(yīng)該用生成對(duì)抗網(wǎng)絡(luò)做什么?如果你想要的是一個(gè)真實(shí)的密度模型,生成對(duì)抗網(wǎng)絡(luò)可能不是最好的選擇。現(xiàn)在有很好的實(shí)驗(yàn)證據(jù)表明,生成對(duì)抗網(wǎng)絡(luò)只能學(xué)習(xí)目標(biāo)數(shù)據(jù)集的“低支持度”表示,這意味著生成對(duì)抗網(wǎng)絡(luò)測(cè)試集的絕大部分(隱含地)被指定為零概率。
與其擔(dān)心太多這個(gè)方面的事情,我們認(rèn)為把生成對(duì)抗網(wǎng)絡(luò)的研究重點(diǎn)放在那些好的甚至有用的任務(wù)上更有意義。生成對(duì)抗網(wǎng)絡(luò)很可能非常適合感知任務(wù),圖像合成、圖像轉(zhuǎn)換、圖像填充和屬性操作等圖形應(yīng)用程序都均屬于這一概念。
我們應(yīng)該如何評(píng)價(jià)這些感知任務(wù)上的生成對(duì)抗網(wǎng)絡(luò)?理想情況下,我們只需要一個(gè)測(cè)試評(píng)判員,但這非常昂貴。一個(gè)便宜的測(cè)試評(píng)論員只需要看分類器是否可以區(qū)分樣本中的真實(shí)和虛假。這叫做分類器雙樣本測(cè)試(C2STs)。雙樣本測(cè)試的主要問題是,哪怕發(fā)生器有一個(gè)小小的缺陷(比如說是樣本的系統(tǒng)性),它都會(huì)嚴(yán)重影響評(píng)估。
理想情況下,我們會(huì)有一個(gè)不受單一因素決定的整體評(píng)估。一種方法可能讓判別器對(duì)其顯性缺陷視而不見,但是一旦我們這樣做了,其他一些缺陷就有可能占主導(dǎo)地位,我們就又需要一個(gè)新的判別器,等等。如果我們反復(fù)這樣做,我們可以得到一種“格蘭姆-施密特步驟”,該步驟創(chuàng)建一個(gè)寫有最重要的缺陷和忽略它們的判別器的有序列表。也許這可以通過在判別器激活值上進(jìn)行PCA(主成分分析),以及逐步剔除高方差成份來實(shí)現(xiàn)。
最后,我們可以在不考慮費(fèi)用的情況下人為評(píng)估。這能夠驗(yàn)證我們真正關(guān)心的事情。另外,我們可以通過預(yù)測(cè)人類的答案、只在預(yù)測(cè)不確定時(shí)與真人互動(dòng)這種方法來降低成本。
生成對(duì)抗網(wǎng)絡(luò)的訓(xùn)練是如何調(diào)整批量數(shù)據(jù)的Large。
較大的批量數(shù)據(jù)(minibatch)有助于擴(kuò)大圖像分類,那么它們也能幫助我們擴(kuò)大生成對(duì)抗網(wǎng)絡(luò)嗎?對(duì)于有效地使用高度類似的硬件加速器,較大的批量數(shù)據(jù)可能尤其重要。
乍一看,似乎答案應(yīng)該是贊同,畢竟大多數(shù)生成對(duì)抗網(wǎng)絡(luò)中的鑒別器只是一個(gè)圖像分類器。如果在梯度噪聲上遇到障礙,更多的批處理(batch)可以加速訓(xùn)練。然而,生成對(duì)抗網(wǎng)絡(luò)有一個(gè)分類器沒有的障礙:訓(xùn)練過程可能會(huì)出現(xiàn)偏差。所以,我們可以提出一些問題:

有證據(jù)表明,增加批訓(xùn)練的數(shù)量可以提高定量結(jié)果并縮短訓(xùn)練時(shí)間。如果這種現(xiàn)象很魯棒,那就表明梯度噪聲是一個(gè)主導(dǎo)因素。然而,這一點(diǎn)還沒有得到系統(tǒng)的研究,所以我們相信答案依然是開放的。
其它的訓(xùn)練過程能更好地利用大批量批處理嗎?理論上,最佳傳輸生成對(duì)抗網(wǎng)絡(luò)比普通生成對(duì)抗網(wǎng)絡(luò)的收斂性更好,但由于它嘗試將批處理的樣本和訓(xùn)練數(shù)據(jù)相對(duì)應(yīng)地對(duì)齊,所以需要較大的批處理量。因此,它似乎很有希望成為大批量處理的備選項(xiàng)。
最后,異步SGD可能成為充分利用新硬件的好選擇。在此設(shè)置中,限制因素主要是得根據(jù)之前的參數(shù)來計(jì)算梯度更新。但是,GAN實(shí)際上應(yīng)該是受益于對(duì)之前參數(shù)的訓(xùn)練,所以我們可能會(huì)問異步SGD是否以一種特殊的方式與生成對(duì)抗網(wǎng)絡(luò)訓(xùn)練模型相互作用的。
對(duì)抗生成網(wǎng)絡(luò)和對(duì)抗樣本的關(guān)系是怎樣的?
眾所周知,圖像分類器會(huì)受到對(duì)抗樣本的攻擊:也就是人類無法察覺的干擾,這些干擾添加到圖像中時(shí)會(huì)導(dǎo)致分類器錯(cuò)誤輸出。我們還知道,分類問題通常是可以有效地學(xué)習(xí)的,但難以進(jìn)行可靠的指數(shù)方式學(xué)習(xí)。
由于生成對(duì)抗網(wǎng)絡(luò)鑒別器是一種圖像分類器,所以人們可能會(huì)擔(dān)心它遇到對(duì)抗樣本。盡管有大量關(guān)于生成對(duì)抗網(wǎng)絡(luò)和對(duì)抗樣本的文獻(xiàn),但它們之間似乎沒有多少聯(lián)系。因此,我們可以問這樣一個(gè)問題:

我們可以從何開始考慮這個(gè)問題呢?我們先假設(shè)一個(gè)固定的鑒別器為D。如果有一個(gè)生成器得到的樣本G(z) 被認(rèn)為是假,而一個(gè)小的干擾項(xiàng)p,比如 G(z) + p被認(rèn)為是真,那么這里將會(huì)存在一個(gè)對(duì)抗樣本D。對(duì)于生成對(duì)抗網(wǎng)絡(luò),我們關(guān)注的則是,生成器的梯度更新將生成一個(gè)新的生成器 G’,滿足G’(z) = G(z) + p。
這種擔(dān)心現(xiàn)實(shí)嗎?這說明對(duì)生成模型的蓄意攻擊可能會(huì)起作用,但我們更擔(dān)心的是某些稱為“意外攻擊”的東西。我們有理由相信這些意外攻擊存在的可能性較小。首先,生成器只允許在鑒別器再次更新之前進(jìn)行一次梯度更新;相反,當(dāng)前的對(duì)抗樣本通常會(huì)進(jìn)行數(shù)十次的更新。
第二,根據(jù)先驗(yàn)的批處理樣本,發(fā)生器進(jìn)行了優(yōu)化,而它的批處理樣本在每次梯度步驟中都是不同的。最后,優(yōu)化是在生成器的參數(shù)下,而不是像素下進(jìn)行的。然而,這些論點(diǎn)中沒有一個(gè)能夠真正排除產(chǎn)生對(duì)抗樣本的發(fā)生器。我們認(rèn)為這是一個(gè)意義重大的課題,有待進(jìn)一步探索。
-
圖像
+關(guān)注
關(guān)注
2文章
1083瀏覽量
40418 -
GaN
+關(guān)注
關(guān)注
19文章
1919瀏覽量
73015
原文標(biāo)題:關(guān)于GAN的靈魂七問
文章出處:【微信號(hào):smartman163,微信公眾號(hào):網(wǎng)易智能】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Llama 3 模型與其他AI工具對(duì)比
火山引擎推出豆包·視頻生成模型
聲智完成多項(xiàng)生成式算法和大模型服務(wù)備案

生成對(duì)抗網(wǎng)絡(luò)(GANs)的原理與應(yīng)用案例
如何用C++創(chuàng)建簡(jiǎn)單的生成式AI模型
生成式AI與神經(jīng)網(wǎng)絡(luò)模型的區(qū)別和聯(lián)系
生成式 AI 進(jìn)入模型驅(qū)動(dòng)時(shí)代

聯(lián)想攜手京東,緊扣大模型和生成式AI技術(shù)
深度學(xué)習(xí)生成對(duì)抗網(wǎng)絡(luò)(GAN)全解析
KOALA人工智能圖像生成模型問世
谷歌Gemini AI模型因人物圖像生成問題暫停運(yùn)行
生成式人工智能和感知式人工智能的區(qū)別
Stability AI試圖通過新的圖像生成人工智能模型保持領(lǐng)先地位






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論