 一種新的、更精細的對象表示方法 ——RepPoints ,比邊界框更好用的目標檢測方法
一種新的、更精細的對象表示方法 ——RepPoints ,比邊界框更好用的目標檢測方法
來自北京大學、清華大學和微軟亞洲研究院的研究人員提出一種新的、更精細的對象表示方法RepPoints,拋棄了流行的邊界框表示,結果與最先進的基于 anchor 的檢測方法同樣有效。
目標檢測是計算機視覺中最基本的任務之一,也是許多視覺應用的關鍵組成部分,包括實例分割、人體姿態分析、視覺推理等。
目標檢測的目的是在圖像中定位目標,并提供目標的類別標簽。
近年來,隨著深度神經網絡的快速發展,目標檢測問題也取得了長足的進展。
當前先進的目標檢測器很大程度上依賴于矩形邊界框來表示不同識別階段的對象,如 anchors、proposals 以及最終的預測。
邊界框使用方便,但它只提供目標的粗略定位,導致對目標特征的提取也相當粗略。
近日,來自北京大學、清華大學和微軟亞洲研究院的楊澤、王立威、Shaohui Liu 等人在他們的最新論文中,提出了一種新的、更精細的對象表示方法 ——RepPoints (representative points),這是一組對定位和識別都很有用的樣本點 (sample points)。

論文地址:
https://arxiv.org/pdf/1904.11490.pdf
給定訓練的 ground truth 定位和識別目標,RepPoints 學會自動以限制目標的空間范圍的方式來排列自己,并表示在語義上重要的局部區域。此外,RepPoints 不需要使用 anchor 來對邊界框的空間進行采樣。
作者展示了一個基于 RepPoints 的、anchor-free 的目標檢測器,不需要多尺度訓練和測試就可以實現,而且與最先進的基于 anchor 的檢測方法同樣有效,在 COCO test-dev 檢測基準上達到了42.8 AP 和 65.0 AP??。
拋棄邊界框,更細粒度的目標表示RepPoints
在目標檢測過程中,邊界框是處理的基本元素。邊界框描述了目標檢測器各階段的目標位置。
雖然邊界框便于計算,但它們僅提供目標的粗略定位,并不完全擬合對象的形狀和姿態。因此,從邊界框的規則單元格中提取的特征可能會受到包含少量語義信息的背景內容或無信息的前景區域的嚴重影響。這可能導致特征質量降低,從而降低了目標檢測的分類性能。
本文提出一種新的表示方法,稱為 RepPoints,它提供了更細粒度的定位和更方便的分類。
如圖 1 所示,RepPoints 是一組點,學習自適應地將自己置于目標之上,其方式限定了目標的空間范圍,并表示語義上重要的局部區域。
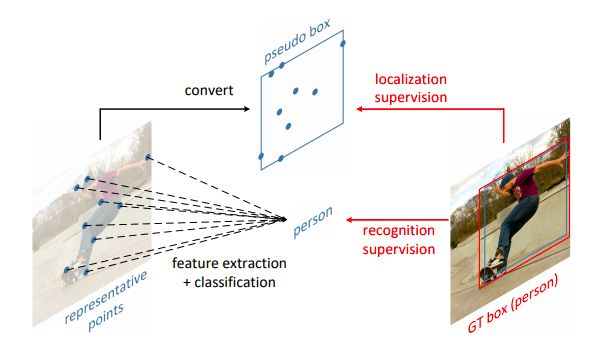
圖 1:RepPoints 是一種新的目標檢測表示方法
RepPoints 的訓練由目標定位和識別目標共同驅動,因此,RepPoints 與 ground-truth 的邊界框緊密相關,并引導檢測器正確地分類目標。
這種自適應、可微的表示可以在現代目標檢測器的不同階段連貫地使用,并且不需要使用 anchors 來對邊界框空間進行采樣。
RepPoints 不同于用于目標檢測現有的非矩形表示,它們都是以自底向上的方式構建的。這些自底向上的表示方法會識別單個的點 (例如,邊界框角或對象的末端)。此外,它們的表示要么像邊界框那樣仍然是軸對齊的,要么需要 ground truth 對象掩碼作為額外的監督。
相反,RepPoints 是通過自頂向下的方式從輸入圖像 / 對象特征中學習的,允許端到端訓練和生成細粒度的定位,而無需額外的監督。
為了證明 RepPoints 表示的強大能力,我們提出了一種基于可變形 ConvNets 框架的實現,該框架在保證特征提取方便的同時,提供了適合指導自適應采樣的識別反饋。
我們發現,這個無 anchor 的檢測系統在對目標進行精確定位的同時,具有較強的分類能力。在沒有多尺度訓練和測試的情況下,我們的檢測器在 COCO 基準上實現了 42.8 AP 和 65.0 AP?? 的精度,不僅超過了所有現有的 anchor-free 檢測器,而且性能與最先進的 anchor-based 的基線模型相當。
RepPoints vs 邊界框
本節將描述 RepPoints,以及它與邊界框的區別。
邊界框表示
邊界框是一個 4-d 表示,編碼目標的空間位置,即 B = (x, y, w, h), x, y 表示中心點,w, h 表示寬度和高度。
由于其使用簡單方便,現代目標檢測器嚴重依賴于邊界框來表示檢測 pipeline 中各個階段的對象。
性能最優的目標檢測器通常遵循一個 multi-stage 的識別范式,其中目標定位是逐步細化的。其中,目標表示的角色如下:
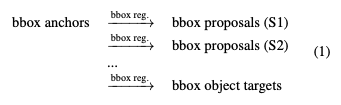
RepPoints
如前所述,4-d 邊界框是目標位置的一個粗略表示。邊界框表示只考慮目標的矩形空間范圍,不考慮形狀、姿態和語義上重要的局部區域的位置,這些可用于更好的定位和更好的目標特征提取。
為了克服上述限制,RepPoints 轉而對一組自適應樣本點進行建模:
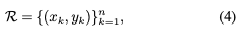
其中 n 為表示中使用的樣本點的總數。在這項工作中,n 默認設置為 9。
Learning RepPoints
RepPoints 的學習是由目標定位損失和目標識別損失共同驅動的。為了計算目標定位損失,我們首先用一個轉換函數 T 將 RepPoints 轉換為偽框 (pseudo box)。然后,計算轉換后的偽框與 ground truth 邊界框之間的差異。
圖 3 顯示,當訓練由目標定位損失和目標識別損失組合驅動時,目標的極值點和語義關鍵點可以自動學習。
圖 3: 學習的 RepPoints 的可視化和來自 COCO minival set 的幾個例子的檢測結果。通常,學習的 RepPoints 位于目標的端點或語義關鍵點上。
RPDet: 無需 Anchor 的目標檢測器
我們設計了一種不使用 anchor 的對象檢測器,它利用 RepPoints 代替邊界框作為基本表示。
目標表示的演化過程如下:

RepPoints Detector (RPDet) 由兩個基于可變形卷積的識別階段構成,如圖 2 所示。
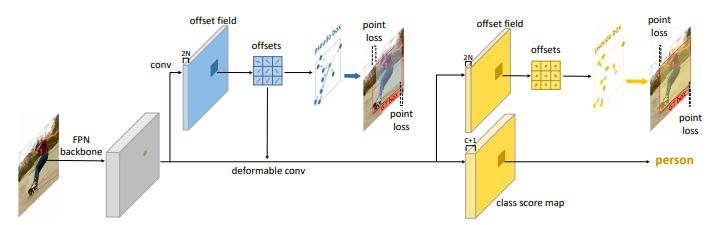
圖 2:RPDet (RepPoints detector) 的概覽,以特征金字塔網絡 (FPN) 為主干
可變形卷積與 RepPoints 很好地結合在一起,因為它的卷積是在一組不規則分布的采樣點上計算的,反之,它的識別反饋可以指導訓練這些點的定位。
實驗和結果
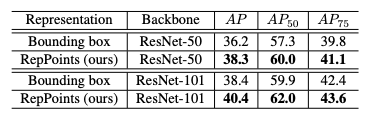
表 1:目標檢測中 RepPoints 與邊界框表示的比較。除了處理給定的目標表示之外,網絡結構是相同的。
從表 1 可以看出,將目標表示從邊界框變為 RepPoints,可以帶來一定程度的性能提升,如使用 ResNet-50 作為主干網絡時提升了 2.1 mAP,使用 ResNet-101 時提升了 2.0 mAP。這表明相對于邊界框,RepPoints 表示在對象檢測方面具有優勢。
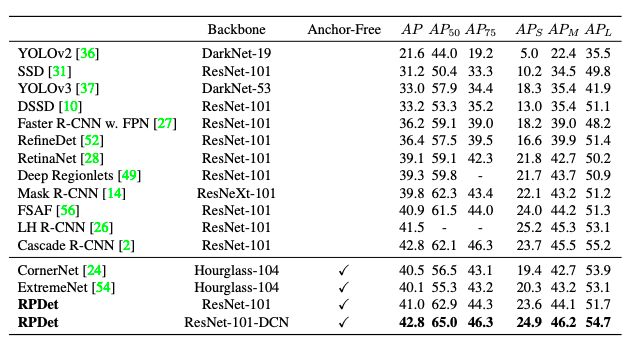
表 7:將所提出的 RPDet 與 COCO test-dev 上最先進的檢測器進行比較。
如表 7 所示,在沒有 multi-scale 訓練和測試的情況下,所提出的框架使用 ResNet-101-DCN 主干網絡實現了 42.8 AP,與基于 anchor 的 Cascade R-CNN 方法相當,性能優于現有的所有不采用 anchor 的檢測器。此外,RPDet 獲得了 65.0 的 AP??,大大超過了所有基線。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
目標檢測
+關注
關注
0文章
204瀏覽量
15590 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927
原文標題:北大、清華、微軟聯合提出RepPoints,比邊界框更好用的目標檢測方法
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
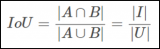
一種基于圖像平移的目標檢測框架
一種目標飛機分割提取方法
一種非靜止背景下的運動目標檢測方法

基于稀疏表示的可變形部件模型目標檢測
一種圖像拼接的運動目標檢測方法
關于一種基于動態規劃的機動目標檢測前跟蹤方法

如何使用級聯網絡進行行人檢測的方法說明

RepPoints 比邊界框更好用的目標檢測方法

一種基于邊界和中心關系的顯著性檢測方法






 工商網監
工商網監
評論