 一文讀懂汽車芯片設計!
一文讀懂汽車芯片設計!
時隔一年,終于有機會再攢一顆芯片。這一次,是熱點中的汽車芯片。
記得兩年前,在中國找不出幾家做前裝汽車芯片的公司。而兩年后的今天,突然如雨后春筍般的涌現出十多家,其范圍涵蓋了輔助駕駛,中控,儀表盤,T-Box,網關,車身控制,電池管理,硬件加解密,激光雷達,毫米波雷達,圖像傳感器和圖像信號處理器等,八仙過海各顯神通。
全球范圍內,汽車芯片一年銷售額大致是400億刀,其中數字芯片100億刀:信息娛樂(中控)芯片約25億刀,均價在25刀;MCU約60億刀,30億片,均價2刀;輔助駕駛約17億刀。全球一年大約賣一億輛車,每輛車平均100刀的數字芯片。其中輔助駕駛芯片處于快速增長階段。汽車芯片的主要供應商,恩智浦,瑞薩數字部分較多,英飛凌,德州儀器模擬部分較多。汽車芯片是僅存的幾個利潤還不錯的市場,技術門檻也并非不可逾越,更不存在絕對的生態閉環。只是量沒有消費電子那么大,一年出個幾百萬片就不錯了。在這個領域里,新造車勢力方興未艾,傳統造車勢力追求差異化,又趕上5G,自動駕駛與人工智能的熱點,于是汽車芯片成了繼虛擬現實,礦機,NB-IOT,人工智能之后新的投資方向。
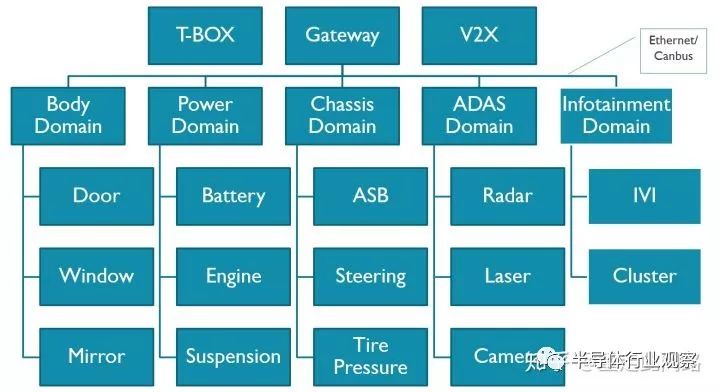
上圖是一個典型的汽車電子系統框架。這個系統分為幾個域,車身,動力總成,底盤,信息娛樂,輔助駕駛,網關和T-Box。每個域有著各自的域控制器,通過車載以太網和Can總線互聯。我們就以架構上最復雜的中控和輔助駕駛芯片為例,展開探討其設計思路與方法。
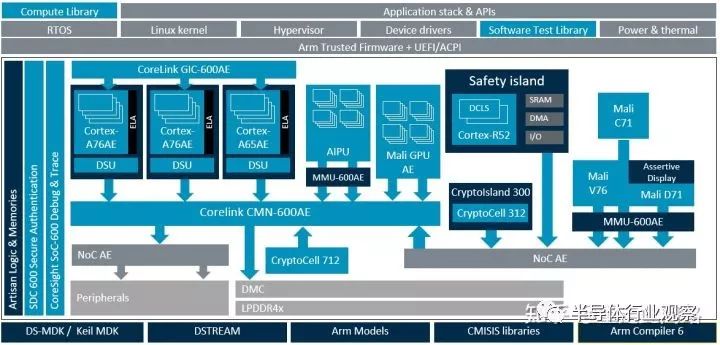
新一代的中控芯片的架構如下圖,主要由處理器,圖形處理器,多媒體,圖像處理,安全(Security)管理,功能安全(Safety),片上調試和總線等子系統構成。它和通常的應用處理器區別主要在于虛擬化,功能安全,實時性和車規級電氣標準。
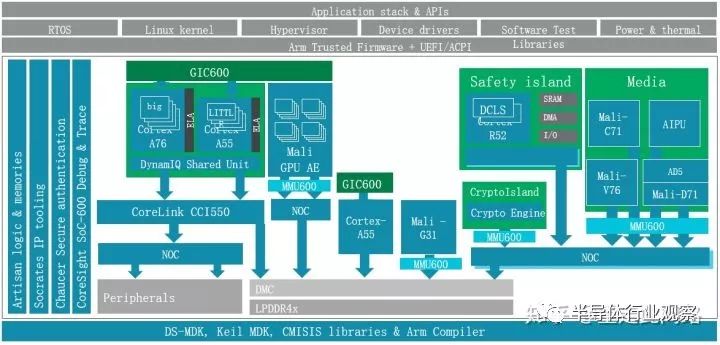
先說虛擬化。虛擬化其實是從服務器來的概念,為什么汽車也會有這個需求?兩點原因:現在的中控芯片有一個趨勢,集成儀表盤,降低成本。以前的儀表盤通常是用微控制器做的,圖形界面也較簡單。而現在的系統越來越炫,甚至需要圖形處理器來參與。很自然的,這就使得中控和儀表盤合到單顆芯片內。它們跑的是不同的操作系統,虛擬化能更好的實現軟件隔離。當然,有些廠商認為虛擬化還不夠,需要靠物理隔離才放心,這是后話,稍后展開。另一個趨勢是中控本身需要同時支持多個屏幕,每個屏幕分屬于不同的虛擬機和操作系統,這樣能簡化軟件設計,提高軟件的可靠性。
虛擬化在硬件上有什么具體要求?這并沒有明確定義。可以依靠處理器自帶的二階內存管理單元(s2MMU),實現軟件虛擬機;也可以在內存控制器前放一個硬件防火墻,對訪問內存的地址進行檢查和過濾,不做地址重映射;還可以使用系統內存管理單元SMMU實現完整的硬件虛擬化,這是我們要重點介紹的。
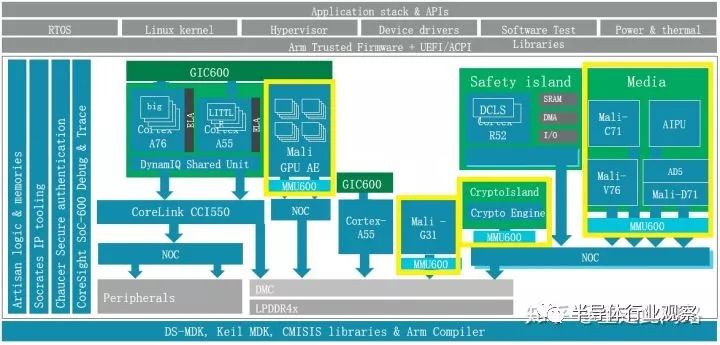
如上圖黃色框所示,每個主設備和總線之間,都加了一個MMU600。為什么每個主設備后都要加?很簡單,如果不加,那必然存在安全漏洞,和軟件虛擬化無異。那為何不用防火墻?防火墻的的實現方法,通常是用一個片上內存來存放過濾表項。如果做到4K字節的顆粒度,那4G字節內存就需要1百萬項,每項8位,總共1MB的片上內存,這是個不小的成本。另外一個原因是,防火墻方案的物理地址空間對軟件是不透明的,采用系統內存管理器SMMU600對上層軟件透明,更貼近虛擬化的需求。
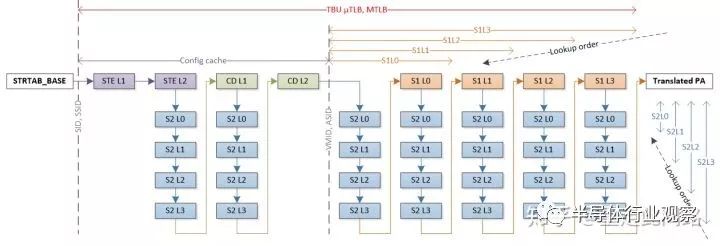
當處理器發起一次地址虛實轉換請求,內存管理單元會在內部的TLB緩存和Table Walk緩存查找最終頁表項和中間表項。如果在內部緩存沒找到,那就需要去系統緩存或者內存讀取。在最差情況下,每一階的4層中間表可能都是未命中,4x4+4=20,最終會需要20次內存讀取。對于系統內存管理器,情況可能更糟。如上圖所示,由于SMMU本身還需引入多級描述符來映射多個頁表,最極端情況需要36次的訪存才能找到最終頁表項。如果所有訪問都是這個延遲,顯然無法接受。
Arm傳統的設計是添加足夠大的多級TLB緩存和table walk緩存,效果如下:
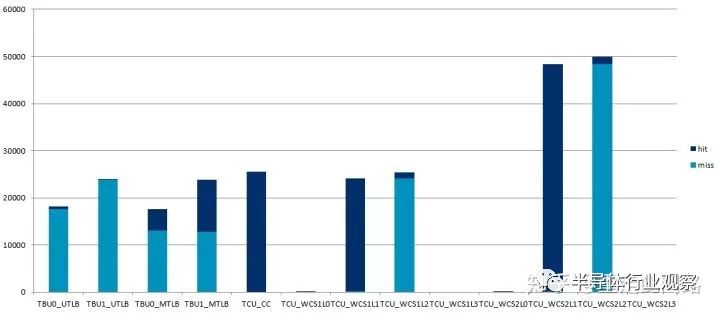
這是啟用2階地址映射后的實測結果,其各項緩存大小均配置成較大,然后把兩個主設備連到接口,進行地址較為隨機的訪問。可以看到,主設備的5萬次訪問,在經過SMMU后,產生了近5萬次未命中。這意味著訪問的平均延遲等于訪存延遲,150ns以上。另一方面,處理器開了虛擬機后,它的隨機訪存效率,和未開虛擬機比,卻能做到80%以上,這是為什么呢?答案很簡單,處理器內部的MMU,會把中間頁表的物理地址繼續發到二級或者三級緩存,利用緩存來減少平均延遲。而SMMU就沒有這么幸運,在Arm先前的手機處理器參考設計中,并沒有系統緩存。這種情況下,即使對于延遲不太敏感的主設備,比如圖形處理器,打開虛擬化也會造成性能損失,可能高達9%,這不是一個小數目。
怎么解決這個問題?在Arm服務器以及下一代手機芯片參考設計中,會引入網狀結構總線,而不是之前的crossbar結構的一致性總線。網狀結構總線的好處,主要是提升了頻率和帶寬,并且,在提供多核一致性的同時,也可以把系統緩存交給各個主設備使用。不需要緩存的主設備還是可以和以前一樣發出非緩存的的數據傳輸,避免額外占用緩存,引起頻繁的緩存替換;同時,SMMU可以把頁表和中間頁表項放在緩存,從而縮短延遲。
Arm的SMMU600還做了一點改進,可以把TLB緩存貼近各個主設備做布局,在命中的情況下,一個時鐘周期就可以完成翻譯;同時,把table walk緩存放到另一個地方,TLB緩存和table walk緩存通過內部總線互聯。幾個主設備可以同時使用一個table walk緩存,減少面積,便于布線的同時,又不失效率。其結構如下圖:
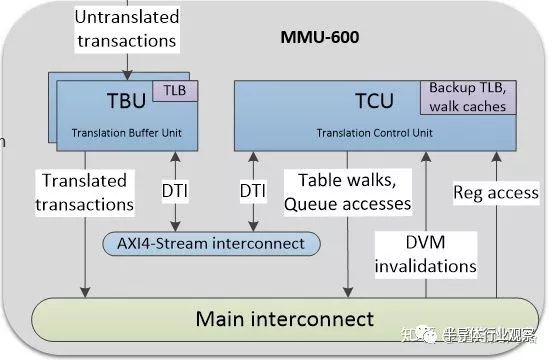
如果我們讀一下Arm的SMMU3.x協議,會發現它是支持雙向頁表維護信息廣播的,這意味著除了緩存數據一致性外,所有的主設備,只要遵循SMMU3.x協議,可以和處理器同時使用一張頁表。在輔助駕駛芯片設計時,如果需要,把重要的加速器加入同一張頁表,可以避免軟件頁表更新操作,進一步提高異構計算的效率。不過就SMU600而言,它僅僅支持單向的廣播,接了SMU600的主設備,本身的緩存和頁表操作并不能廣播到處理器,反過來是可以的。
對于當前的汽車芯片,如果沒有系統緩存,那如何減少設備虛擬化延遲呢?辦法也是有的。汽車的虛擬機應用較為特殊,目前8個虛擬機足夠應付所有的分屏和多系統需求,并且一旦分配,運行階段無需反復刪除和生成。我們完全可以利用這點,把二階段的SMMU頁表變大,比如1GB,固定分配給某個虛擬機。這樣,設備在進行二階段地址映射時,只需少數幾項TLB表項,就可以做到一直命中,極大降低延遲。需要注意的是,一旦把二階映射的物理空間分配給某設備,就不能再收回并分給其他設備。不然,多次回收后,就會出現物理地址離散化,無法找到連續的大物理地址了。
SMMU接受的是從主設備發過來的物理地址,那它是怎么來區分虛擬機呢?靠的是同樣從主設備發送過來的vmid/streamid。如果主設備本身并不支持虛擬化,那就需要對它進行時分復用,讓軟件來寫入vmid/streamid。當然,這個軟件必須運行在hypervisor或者是secure monitor,不然會有安全漏洞。具體的做法,是在虛擬機切換的時候,hypervisor修改寄存器化的vmid/streamid,提供輸入給SMMU即可。如果訪問時的id和預設的不符,SMMU會報異常給hypervisor。
如果主設備要實現硬件的方式支持虛擬化,那本身需要根據多組寄存器設置,主動發出不同的vmid/streamid。為了對軟件兼容,可以把不同組按照4KB邊界分開,這樣在二階地址映射時,可以讓相同的實地址訪問不同組的寄存器,而對驅動透明。同時,對于內部的資源也要做區分,不能讓數據互相影響。如果用到緩存,那緩存還必須對vmid敏感,相同地址不同vmid的情況,必須識別為未命中。
如果主設備本身不支持虛擬化,并且本身特別復雜,那還需要定制驅動。以Arm的圖形處理器為例,到目前為止,硬件上還沒有正式支持虛擬化,如果軟件要支持,可能會有以下幾種方案:
假設我們用的Hypervisor是Xen,它運行于Arm處理器的EL2,虛擬機運行于EL0/1。正常的圖形處理器驅動會分成用戶空間與核心空間兩部分。要實現虛擬化,時分復用圖形處理器,Xen上本身不可能跑驅動,因為目前驅動只支持Linux。所以就只能讓虛擬機來跑原先的驅動,而沒有辦法在hypervisor上再運行一個驅動來進行訪問控制。同時,重映射圖形處理器在CPU上的二階段地址,讓寄存器訪問和數據通路處于‘穿透’的模式,不引起異常,提高效率。相應的,讓虛擬機直接訪問寄存器,那訪問控制就實現不了了。為了實現多虛擬機的調度,我們可以在hypervisor里面實現一個調度器,并且在核心態的驅動部分開放接口,讓hypervisor可以主動調度。示意圖如下:
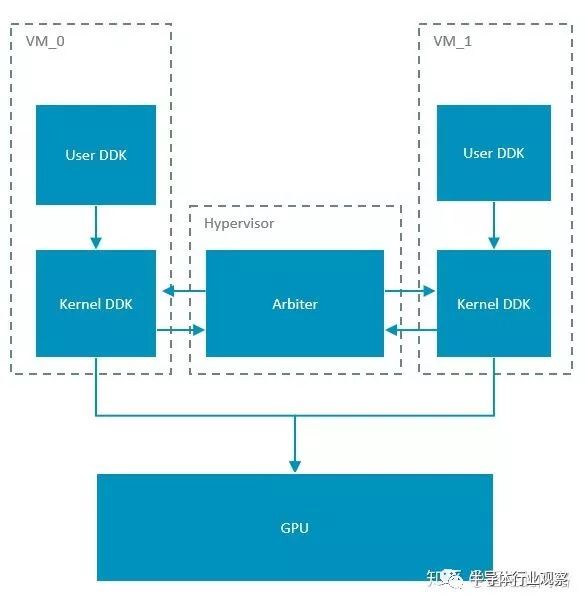
這個實現的優點很明顯,改動較少,實現簡單,無論是Xen和KVM都可以適配。缺點是主動權并不掌握在hypervisor,如果某個虛擬機上渲染任務過于繁重,一直不把控制權交給調度器,那只有強制重啟。另一個明顯的缺點是,無法在圖形處理器同時運行兩個虛擬機上的任務。這就需要另一種虛擬機的實現方式,如下圖:
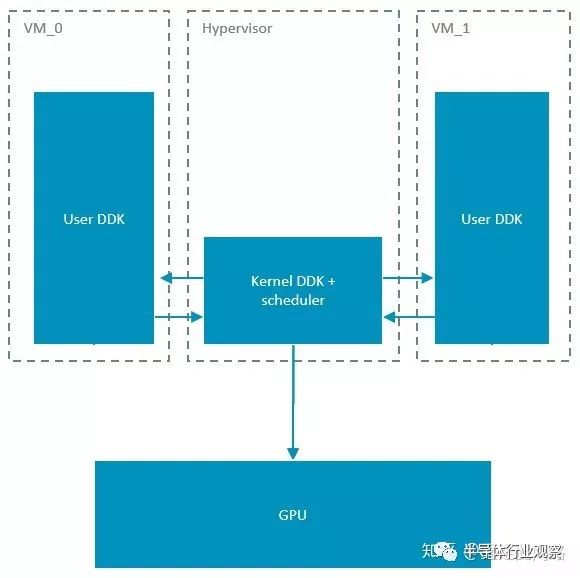
在這種實現下,虛擬機里只跑驅動的用戶空間,所有涉及核心空間的調用全都扔到Hypervisor。這要求hypervisor本身是Linux,只有KVM符合這個要求。Arm的Mali圖形處理器,硬件上是支持指定某個渲染核心跑特定任務的,也就是可以把某個虛擬機的任務運行在特定渲染核心的。這樣,如果有實時性的操縱系統要跑,比如儀表盤,可以保留出一個核來,不被其他虛擬機搶占,來實現一定程度的QoS。此時,圖形處理器是真正同時跑兩個虛擬機任務的,而不是時分復用。至于輸出的frame buffer,不同的任務是可以放到不同物理地址的,只是沒法區分SteamID,沒法做隔離。
Arm支持硬件虛擬化的圖形處理器估計還要一年才會出來。具體到細節,虛擬化除了需要寄存器分組,緩存對vmid敏感之外,通用的一些單元也需要支持分組。
關于虛擬機的效率,還有兩點需要注意:
Arm現有的中斷控制器GIC600,受限于GICv3.x協議,是沒有辦法繞過hypervisor,直接把虛擬中斷送到Guest OS的。外部中斷送進來,還是得經由hypervisor權限設置寄存器,產生一個虛擬中斷到Guest OS。中斷直接送到Guest OS要到GICv4才會改進。
Armv8.1及之后的CPU,都支持一個叫VHE的機制,可以加速2型虛擬機的切換。具體原理是,KVM等2型虛擬機,Hypervisor就在Linux核心里面,而Linux需要完整的2階3/4層頁表。另外一方面,Armv8.1之前的處理器EL2沒有對應的頁表。如果沒有VHE,那這個Hypervisor必須把一部分駐留在EL2做高權限操作,而Host Linux還是運行在EL1。這樣,很多操作需要從EL1陷入EL2,改完再回到EL1的Linux核心,多了一層跳轉。有了VHE,那么Host Linux核心直接運行在EL2,可以操作EL1的4層頁表的頁表寄存器,軟件上不用做修改。硬件上,這些訪問會被重定向到EL2,以保證權限。
對于1型虛擬機,比如Xen,這個改動沒有影響。這里我們要提一下QNX的虛擬機,它是1型虛擬機。QNX是目前唯一一個能達到Asil-D等級的操作系統(包含Hypervisor)。如果需要實現Asil-D級別的系統,必須把現有的軟件從Linux系統移植到QNX。所幸的是,QNX也是符合Posix標準的,尤其是圖形處理器的驅動,移植起來會省事一些。QNX不是所有的模塊都是Asil-D級,移植過去的驅動,其實是沒有安全等級的。QNX依靠Asil-D級的核心軟件模塊和Hypervisor,保證99%以上的失效覆蓋率。如果子模塊出了問題,那只能重啟子模塊。
前面說到,有些廠商認為虛擬化還不夠,有些場景要物理隔離。虛擬化的時候,硬件資源還是共享的,只不過對軟件是透明。這樣其實并不能完全防止硬件的沖突和保證優先級。請注意,硬件隔離是separation,而不是分區partition,Partition是用MPU來做的。在中控的系統框架圖內,我們把采用物理隔離的紅色部分單獨列出來,如下圖:
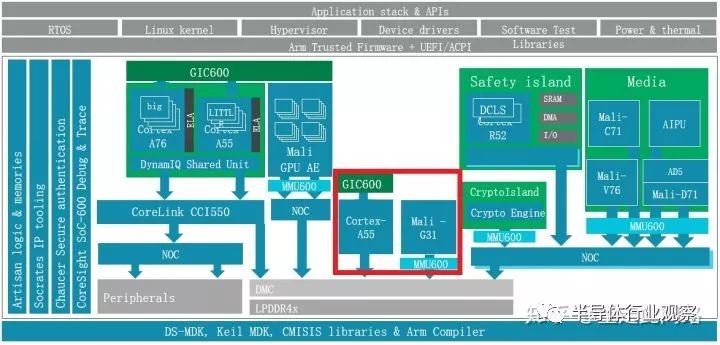
此時的處理器A55和圖形處理器G31,獨立于作為信息娛樂域的處理器A76/A55和圖形處理器G76之外,擁有自己的電源,時鐘和電壓。作為優化,紅色部分可以和其余的處理器用一致性總線連接起來,在不作為儀表盤應用的時候,作為SMP的一部分來使用。而需要隔離的時候,用多路選擇連接到NoC或者內存控制器。這樣既節省了面積,又實現了隔離。
同樣的,圖形處理器也有物理隔離的需求。實現其實并不復雜,比支持硬件虛擬化要直接,如下圖:
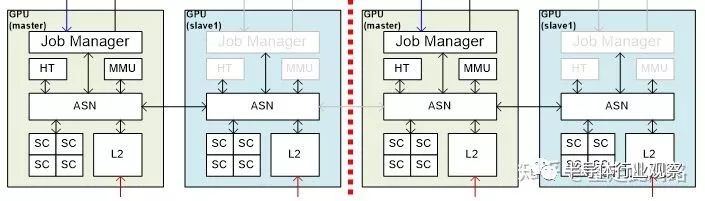
由于圖形處理器面積最大的是渲染核心SC,這部分不動。其余的硬件模塊,每組核都復制一份,組和組之間用內部總線ASN互聯。當拆成多個圖形處理器的時候,每個冗余模塊分別控制自己的資源。此時,每組GPU需要獨立運行一個驅動。而把所有資源融合運行的時候,冗余的部分自動關閉,由一個模塊集中調度。此時,某些公用資源可能會遇到性能瓶頸,但汽車通常只會要求物理隔離兩個組,分別給儀表盤和信息娛樂,并且儀表盤所需資源較少,融合的時候,可以啟用信息娛樂的共享單元,從而避免瓶頸。對于系統中其余的主設備,也可以利用類似的設計思路來實現隔離。
有了同時支持虛擬化和硬件隔離的圖形處理器,我們的中控芯片構架會有如下改動:
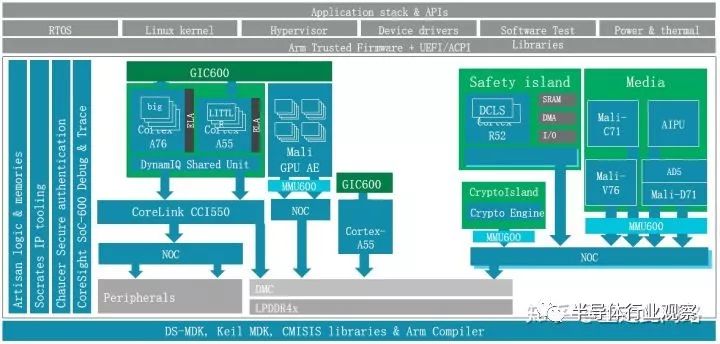
此時圖形處理器的物理隔離和硬件虛擬化可以同時啟用,跑多份驅動,滿足前文的需求。
至此,虛擬化和隔離結束,開始討論車規。
目前我們說的車規分兩個,功能安全和電氣標準。前者由ISO26262定義,后者由AEC-Q100定義。
功能安全在芯片上的設計原則是要盡可能多的找出芯片上的失效場景并糾正。失效又分為系統和隨機兩種,前者依靠設計時的流程規范來保證,后者依賴于芯片設計上采取的種種失效探測機制來保證。我們在這主要談后者。
簡單來說,芯片的失效率,是基于單個晶體管在某個工藝節點的失效概率,推導出片上邏輯或者內存的失效概率。面積越大,晶體管越多,相應的失效率越大。ISO26262把安全等級做了劃分,常見的有ASIL-B和ASIL-D級。ASIL-B要求芯片能夠覆蓋90%的單點失效場景,而ASIL-D則是99%。這其實是個非常高的要求。一個晶體管的失效概率雖低,可是通常一個復雜芯片是上億個晶體管組成的,如果不采取任何措施,那任何一點的錯誤都可能造成功能失效,失效率很高。
ISO26262手冊第五篇的附件D,詳細描述了硬件失效的探測手段。在這部分,硬件系統被分為幾個模塊:輸入端有傳感器,連接件,中繼,數模接口;處理部分包含處理單元,各類內存閃存。系統層面有總線,電源和時鐘。系統框架如下圖:
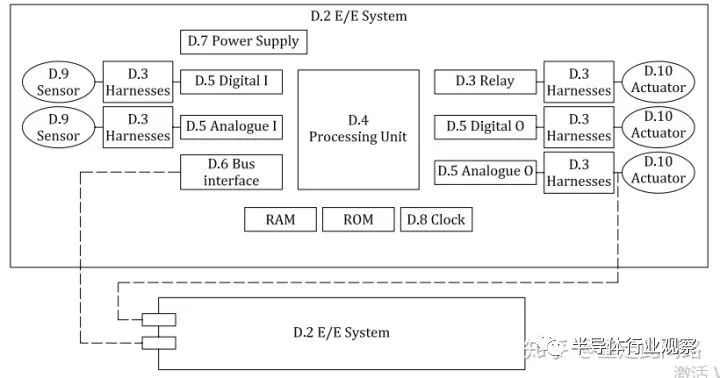
針對每一單元,ISO26262手冊定義了一些方法,來檢測這些單元是否失效,并給出每一種方法的可靠度。比如傳輸線,可以有校驗碼,超時,計數器,發送測試向量等。再比如處理單元,可以使用軟硬件自檢,冗余加比較,額外硬件模塊監測等方法。這些方法并不能簡單的應用于芯片功能安全設計。那芯片上怎么辦?我們采用自底向上的方法,先從晶體管開始分析,再到IP模塊級,然后到芯片系統級,再討論幾個典型場景,最后自頂向下分析。
在芯片的隨機錯誤中,有一類是永久錯誤,比如邏輯或者片上內存的某一位一直粘在0或者1,或者干脆短路及斷路。對于這一類錯誤,在芯片封測的時候,我們可以使用邊界掃描和MBIST來發現壞掉的晶體管。這樣,問題就轉換為怎樣提高DFT的覆蓋率。這一塊,業界已經有成熟的方法了。
僅僅有出廠測試是不夠的,晶體管會在使用過程中慢慢老化損壞。因此,我們需要在每次開機的時候都進行自檢,提前發現問題,減少在系統運行狀態下出錯的可能。此時,我們需要使用LBIST和MBIST。其原理和出廠測試很像,也是利用掃描鏈,不同的是芯片里需要LBIST/MBIST控制器,用來運行測試向量和模板。自然,這會引入額外的成本。覆蓋率越高,成本相應越大。
有了LBIST/MBIST也還不夠,我們需要在晶體管失效發生后幾個時鐘周期就探測到錯誤,而不是開機時候發現。對于邏輯來說,為了做到這點,最直接的方法莫過于采用冗余設計,也就是把邏輯復制一份,然后用硬件比較器比較輸出。通常這被稱為鎖步設計(Lock-Step)。理論上,對于有限狀態機,只要輸入一致,時鐘周期一致,輸出一定一致。通常數字部分不存在真隨機單元,哪怕是緩存替換算法,也是偽隨機的,所以上述條件可以滿足。冗余的結果是邏輯面積增加一倍,比較器也會引入一些額外的面積開銷和時序影響。
這么簡單就實現了功能安全?并沒有,有幾個問題需要解決:
第一個問題是,比較器到底比哪些信號?以處理器為例,如果我們只是在對總線的接口上增加比較器,芯片內部的很多模塊,比如寫緩沖,并不能在較短且確定的時間內把影響傳遞到對外接口,被比較器發現。此時,處理器可能是處于失效狀態而并沒有被探測出來。那我們就不能說當前冗余機制能覆蓋此類失效。為此,我們需要把比較器連到內部子模塊接口處,并且分析是不是能在較短時間內看到影響。這需要在設計階段就考慮,具體做法如下圖:
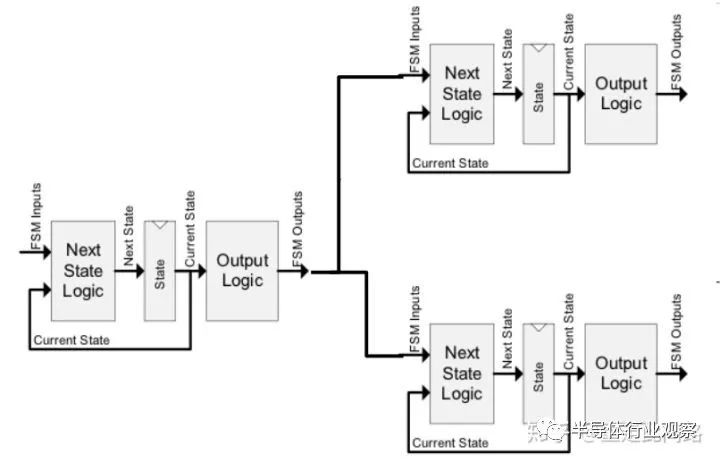
對于任何一個寄存器,一定可以找到影響它的組合邏輯和上一級寄存器。在這條通路上任何一位出了問題,那么在一個時鐘周期后,我們就可以看到寄存器輸出與其冗余的模塊產生不一致。把這個節點記為1,然后再以1的輸入寄存器為新起點,找到節點2。依次類推,我們可以往前找出一條沒有循環的通路,這條通路上的任何一點發生問題,在確定的較短時間內,一定會在最終輸出上反應出來。我們把這個通路記為模塊X。通過一定的EDA工具,我們可以在芯片內找出若干個模塊X,如下圖的例子:
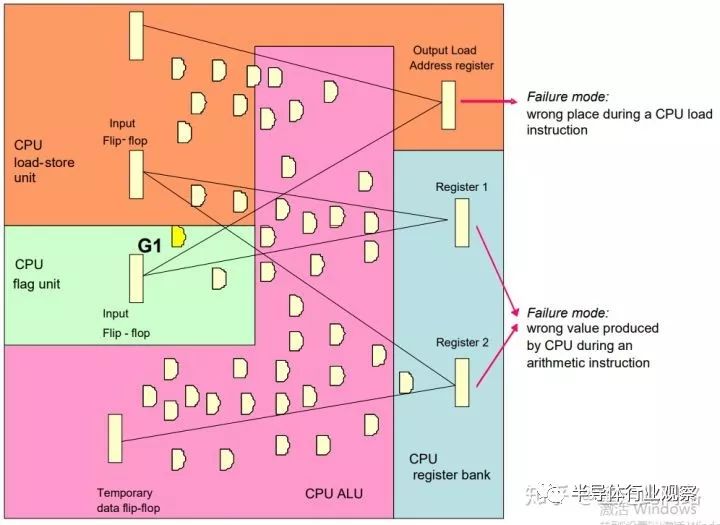
這里,IP模塊被劃為存取單元(A門),標志單元(B門),計算單元(C門)和寄存器組(D門)。從輸出端看,于上一級寄存器間連線所覆蓋的組合邏輯為門數,一個寄存器算10個門。如上圖,存取單元的地址寄存器輸出受24個組合邏輯門外加2個寄存器的影響,那共存在44種單點錯誤會引起失效。依此類推,寄存器組的1號輸出,受28個門影響,而2號受49個門影響。加起來總共121種可能。簡單計算可知,存取單元失效率44/121=36.4%,寄存器組合計77/121=63.6%。是其中有些門被統計了多次,比如圖中的G1,這一點會反映在總的概率里面。
基于上述的思想,我們來看處理器是怎么做的。在EDA工具的幫助下,我們將它劃分為幾個大模塊:內存管理單元,寫緩沖,取指單元,數據處理單元,程序追蹤緩沖, 數據/指令緩存,總線接口單元, 時鐘和重置控制單元, ECC/奇偶校驗控制單元, 中斷接口, 監聽控制單元。此處,我們沒有把片上內存包含進去,即使是討論緩存,也指的是控制邏輯部分。
每一個單元內,又可以細分成很多子模塊。以數據處理單元為例, 又分為通用寄存器組,存取單元,浮點單元,浮點寄存器組,解碼單元,調試單元,控制信號單元,系統寄存器組,分支執行單元等。每一個子單元又可以再一次細分。細分的目的是判斷在晶體管失效時,受其影響的寄存器是不是會失效,并且這個失效能被外部比較器探測到。這就需要把內部信號拉到外面。那到底怎么決定哪些信號拉出去哪些不拉?覆蓋率是不是足夠?工具給的節點和模塊信息只能作為參考,設計人員還是要一個個檢查來做最后決定。通常會有很多信號被拉出來,比如Cortex-R5,20多萬門的邏輯,最終送到比較器的信號數達2000多個,平均每100門就有一個信號。
在芯片過認證的時候,如果IP本身沒有過經過認證,或者以前沒有被廣泛采用,認證機構可能會需要一條條的和芯片公司討論,看看連出來的的管腳是不是能提供足夠的失效檢測覆蓋率。通常這些設計相關的信息,IP公司并不會提供給芯片公司,所以認證公司可能會要和IP設計公司拿這些信息,導致更長的認證時間。相應的,如果是廣泛使用的IP模塊,這個時間可以縮短。
解決了冗余設計覆蓋率的問題,還有第二個問題。如果遭受電磁沖擊或者射線影響,即使用了冗余設計,也可能兩個模塊同一時間產生一樣的錯誤。這個比較容易處理,只要把兩個同樣的邏輯,輸入錯開幾拍就可以。在輸出的時候,錯開相同的拍數,使得比較器還是看到相同的結果。
第三個問題,復制了一份邏輯,并且比較器發現了錯誤,能把他糾正過來嗎?很可惜,不能。除非復制兩分邏輯,三個同時比較。這樣的代價就是再增加原先100%的邏輯部分面積,對于大的處理器設計,基本沒人這么做。如果是小的處理邏輯,比如看門狗電路,倒是可以。
第四,邏輯比較器本身,也是可能出錯的。這類錯誤已經被ISO26262定義,也就是所謂的潛藏錯誤Latent Fault。如果發現比較器本身的失效覆蓋率不夠,那同樣可以對比較器采用冗余設計,做比較器的比較器,提高它的覆蓋率。對于Asil-D來說,潛藏錯誤覆蓋率需要達到90%,而Asil-B是60%。
以上都是對于邏輯錯誤的分析。還有一類是內存錯誤。這里內存指的是片上內存,也包含嵌入式閃存。內存的錯誤比較容易發現,通常ECC就可以做到99%覆蓋率,1位糾正多位報錯。有些內存,比如一級指令緩存,只支持奇偶校驗,不支持糾正。
對于邏輯的冗余和內存的ECC,為了驗證探測機制本身是不是能達到設計的要求,芯片里面需要加入錯誤注入。請注意,錯誤注入機制本身并不是為了驗證芯片里單點錯誤失效和多點錯誤失效率,只是為了驗證錯誤探測機制。
綜上所述,邏輯冗余和內存ECC是幫助我們達到Asil-B/D等級的必要手段。沒有冗余設計的時候,把一個程序在一個核上運行兩遍,然后比較結果,也是一種通向高等級安全的辦法,但僅僅適用于簡單的,實時性要求不高的運算。如果存在永久錯誤,這個方法就會失效。同樣,用兩個非冗余處理器同時做相同運算,也是一種方法。但如果計算很復雜,這樣做不但會增加系統延遲和帶寬,成本也并不低。
上述兩種方法并不能從本質上改善安全等級,如果最終安全等級需要Asil-D,這兩種方法會要求拆解后也得達到Asil-B。而Asil-B的單點90%覆蓋率,不用冗余機制同樣很難達到。還有一種方法,單路計算,另一路判斷其結果是不是合理。作為監測的這一路提高到Asil-D。這只有在特定場景才有可能應用,我們后面會討論到。
綜上所述,要做通用的Asil-B/D,最好從設計開始就使用邏輯冗余和內存ECC。
實際設計中,特別是對于處理器,在冗余設計之外,還有一套錯誤發現和糾正機制。Arm把它稱作RAS (Reliability,Availability,Serviceability)。RAS并不能代替冗余設計來實現Asilb-B/D,畢竟它的覆蓋率太低。但有些場景,比如ECC報錯,指令報錯,這套機制可以在不重啟核心的情況下糾正錯誤,或者阻止錯誤在糾正前被擴散(Data Poisoning),又或者記錄下錯誤時的上下文。這是它的優點,在沒有冗余設計的芯片里也是有一些用處的。
讓我們結合ISO26262文檔,來看看Arm的面向汽車應用的IP是怎么實現高等級功能安全的。
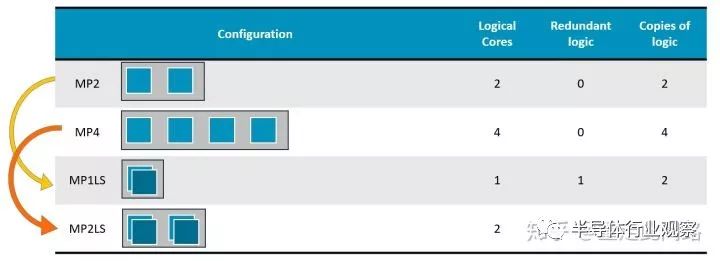
上面是A76AE配置圖,也就是面向汽車的A76,它引入了Split-Lock的設計。正常情況下,可以當4核SMP用,在冗余模式下,核心內所有的邏輯和內存都復制兩份,互為備份。這兩種模式需要重啟來進行切換,不能動態切換,對于汽車應用來說足夠。核心內部添加的比較器,約占5%的面積,頻率也會有5%左右的損失。
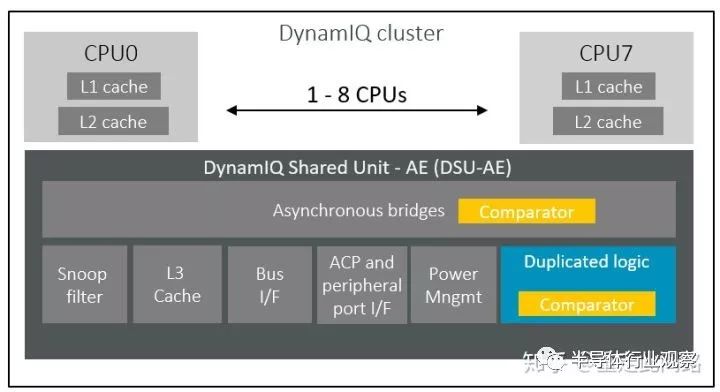
新的A76AE是Armv8.2架構,如上圖所示,一個處理器組之內,包含了DSU做三級緩存和內部互聯。和核心部分不同,這里采用的是傳統的鎖步模式,只復制邏輯,內存還是一份。省了大面積的緩存開銷。通常DSU里面邏輯只占很小一部分,并且面積利用率還很低,所以最終額外的面積并不大,15%左右。
Arm還有一個支持汽車Asil-D等級的處理器A65AE,可以作為小核,放在不同的處理器組,并和大核通過CMN600AE總線互聯,提供高能效比的異構計算。A65AE支持單核雙線程,通過增加一個寄存器組,使得兩個軟件線程可以在一個物理核上共享流水線,并且對軟件透明。這其實最初來自于網絡處理器的需求,執行單元經常等待高延遲的讀傳輸。為了提高流水線利用率,A65AE增加了5%左右的硬件寄存器,提高了20%左右的總性能。
下圖是輔助駕駛芯片里A76AE和A65AE的各種組合。在汽車上,尤其是在輔助駕駛的領域,同樣存在同時需要大小核的場景:大核跑決策,單線程性能要求高;小核跑計算,能效比要求高。
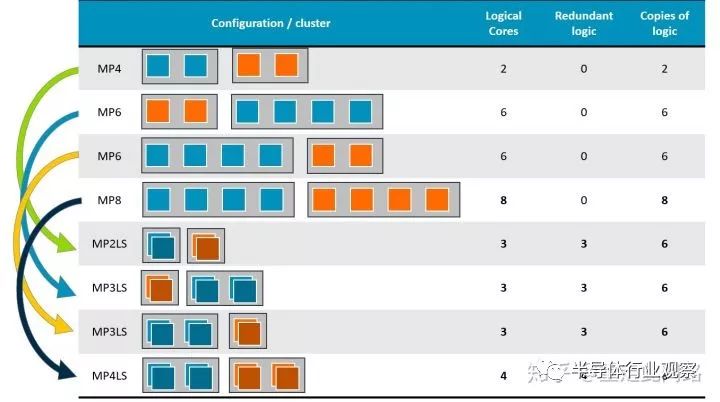
接下來看看Arm新的實時處理器Cortex-R52,通常它被當作安全島來使用,是整個芯片的安全設計基石。在R52上,各種安全機制均有所體現,包括鎖步,實時虛擬化,地址隔離,內存ECC,總線ECC,在線MBIST,LBIST,在線軟件測試庫,RAS,如下圖所示:
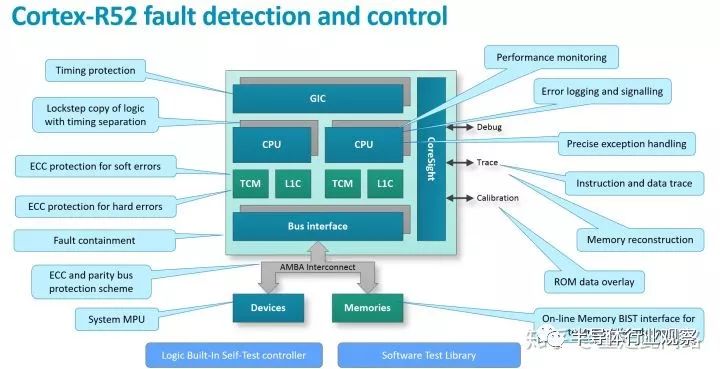
R52的同時支持鎖步和Split-Lock模式。鎖步模式下,只有一個核,冗余部分僅僅復制邏輯,不復制內存,邏輯就是額外的成本,沒法省掉。Split-Lock模式,配置完整的兩套核,包括邏輯與內存,平時作為Split模式使用,相當于兩個AMP,在進入Lock模式時,其中一套的內存不起作用。此外,由于采用的是MPU的虛擬化,地址并沒有重映射,只是多了一層訪問檢查。這也就意味著地址對軟件不透明,不同的虛擬機可以看到別人的地址,只不過沒法訪問。
R52的最大亮點是實現了實時虛擬化,這是為了軟件達到更高的安全等級而準備的。和A系列基于MMU的虛擬化不同,它是在原來的EL1 MPU基礎上,添加了EL2 2MPU。同時,為了保證R系列的實時性,避免我們前文提到的SMMU訪內延遲極大增加的問題,R52沒有采用內存映射,也不轉換地址,而是用片上內存,做兩層的權限檢查。用戶可以指定幾十個區域,顆粒度可以不同,但是沒法做到頁表那么多的條數。在R52上,由于沒有A系列的EL3,安全啟動就需要先進入EL2,然后再建立信任鏈,流程和A系列類似。
另一個重要的安全設計是支持在線的MBIST和SBIST。在線MBIST原理并不復雜,它在片上內存接口前添加控制邏輯,不斷探測是不是有處理器那邊發過來的傳輸。如果沒有,那就趁空閑時間讀寫內存并做測試。SBIST就是針對處理器IP的在線軟件測試。我們可以把這個測試運行在某個虛擬機上,通過中斷來周期性的切換,花5%的時間來不停檢測硬件。當然,必須把虛擬機切軟硬件換時間保證在較小范圍內,不影響實時任務的調度。
這兩種在線測試,可以作為開機自檢的補充,也可以作為在鎖步/ECC機制但點錯誤覆蓋率不夠時的補充,更可以作為發現潛藏錯誤的補充。但是在高等級的安全設計中,尤其是在安全島的設計里,僅僅靠這兩種在線測試發現單點錯誤還是不夠的,也只能作為補充。
其他方面,R52還對MPU編程做了優化,不是像以前需要針對一個CP15寄存器填,填完再用內存壁壘指令確保寫入次序。現在采用多組寄存器方式,基本20-30時鐘周期就可以完成虛擬機切換的寄存器編程。此外中斷寄存器放到了cluster內部,不用再通過AXI口出去,減少一些延遲。
再來看看中斷控制器GIC600AE。以AE結尾的IP表示在原有的基礎上做了功能安全設計,可以支持到Asil-D。GIC600AE結構如下圖:
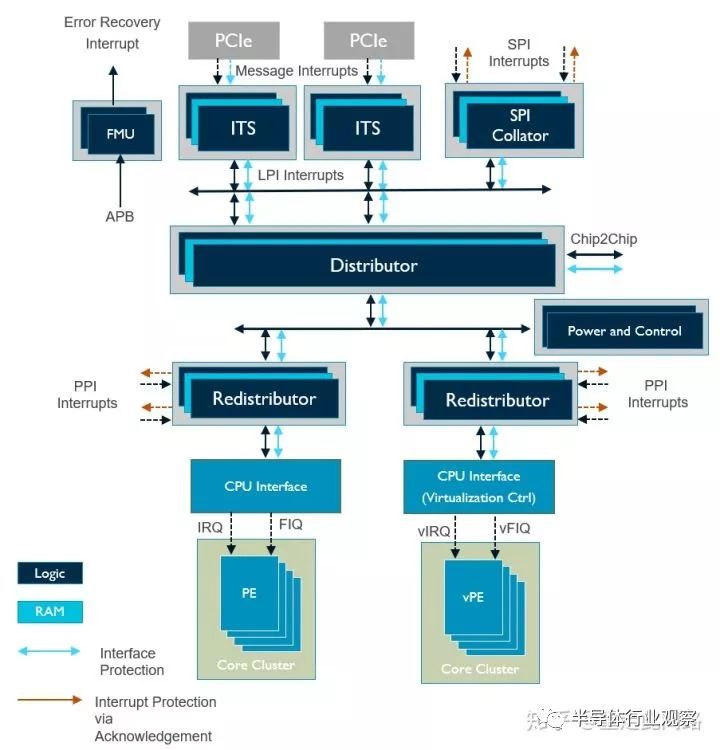
和處理器一樣,GIC600AE的邏輯部分是靠鎖步來支持Asil-B/D,內存部分是ECC。不同的是,不像處理器是一個單一硬核,GIC600AE是一個分布式的結構,布局布線可以分開,只是在中心有個分配器(Distributor)。每個處理器附近的子分配器(Redistributor)和分配器之間,就需要安全總線協議設計,這就是新的AMBA點對點功能安全擴展:
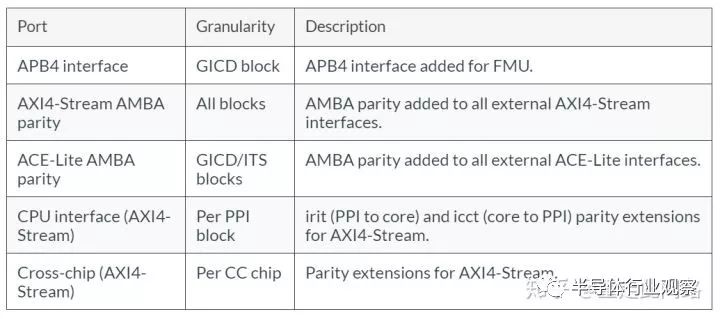
可以看到的是,各類AMBA的地址和數據線,接口上均添加了奇偶校驗,這也是ISO26262所要求的傳輸線安全措施之一;對于重置和時鐘,P/Q通道等信號,大多采用復制的方式來保護;而對于AXIS端口,則采用負載加上CRC的方法,免去添加管腳。由于中斷控制器不像處理器,可以有中斷系統來處理各類錯誤和失效,因此GIC600AE在分配器中添加了一個錯誤管理單元,可以把我們所提及的各類錯誤做集中管理,記錄并上報。此外,在分配器與子分配器之間,GIC600AE還添加了看門狗,防止超時未響應。
由于目前GIC600AE還比較新,對于一些老的設計,可能并沒有與之匹配的中斷控制器可用。這種情況下,就只能把和安全相關的工作用輪詢來完成,避免走中斷通道。輪詢的對象可以是一段ECC保護的內存,也可以是有冗余設計的硬件鎖或者外置exclusive monitor。
MMU600AE也是類似的安全設計,在此我們不深入討論。對于Coresight這樣的片上調試系統,由于本身并不涉及安全,它的錯誤被稱作safe fault,不計入考慮范圍。 我們接下去看看CMN600AE。
CMN600是Arm服務器總線IP,它最大的特點是網狀拓撲結構,對外支持AMBA CHI接口,內部改用路由結構轉發數據,并提供硬件一致性和系統緩存,還支持多芯片互聯。CMN600在T16FFC上可以做到2Ghz,極大的拓展了帶寬,非常適合ADAS這類有大量異構計算的應用。
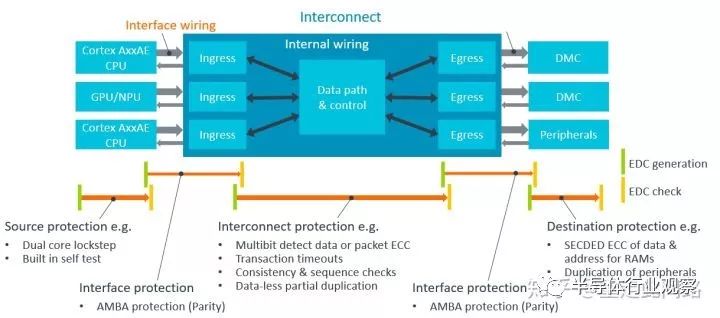
CMN600AE做了功能安全設計,引入了完整的端到端的失效探測機制。如上圖,整個總線被分成三類模塊,主設備,總線,從設備。主設備與總線,總線與從設備之間,總線內部,會有錯誤探測編碼,也就是EDC。各處的EDC策略可以是不同的。
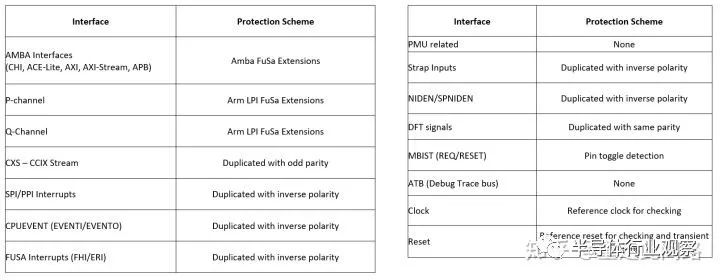
這是主設備與總線,總線與從設備接口處的EDC,和GCI600AE的有些相似,只不過更全。對于一些控制類信號,采用復制的方法,有時候把兩根線正負反轉;對于數據線和地址線,采取添加奇偶位的做法。
在總線內部,由于網狀總線的特點是把傳輸轉成管腳更少的包FLIT傳輸,所以在每個包后面,加了CRC-8數據作為校驗,而不是添加管腳。對于總線處理模塊,仍舊采用邏輯鎖步和內存ECC來做安全設計。此外,CMN600在傳輸上加了計數器,如果從設備端超時不響應,那就報異常。
除了鎖步,ECC和傳輸線保護,有一類IP模塊設計,可以使用簡單一些的方法,來達到一定的安全等級。下圖是一個簡單的圖像信號處理單元,從前到后,流水分別是Raw域,RGB域,YUV域,每個域都包含了各自的子模塊。模塊之間,包括到DDR的傳輸,使用傳輸線安全設計。而子模塊內部,如果輸出結果是單調遞增,單調遞減或者在某一區域內的,就可以用帶冗余的簡單邏輯做硬件監控,來實現Asil-B/D等級。
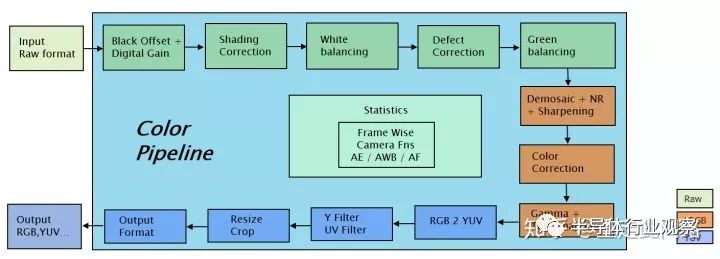
我們取RGB域上的Local Tome Mapping為例。Local Tome Mapping的本意是,對于高動態HDR或者標準動態范圍SDR的圖,可以把局部的亮度調整到一個合適范圍內,效果如下圖。基于這個假設,我們可以寫簡單邏輯,看某個區域的像素是不是顏色保持不變,而亮度和原來比有合理提高。這個簡單的邏輯,可以使用鎖步來確保高等級功能安全。根據功能安全的功能分解原則,Asil-D可以分解為Asil-D的監控模塊和QM的功能模塊,這樣,還是能保證整個Local Tome Mapping子模塊的高安全等級。
以上是IP模塊級別對于安全設計的考量,接下來我們談下模塊級實時性設計。
所謂實時性,是在一個確定的,比較小的時間內處理完任務。很多時候,我們其實并不是真的需要實時性,而只是需要一個比較高的平均性能。Arm的R系列專門為嚴格的實時性設計:確定的幾十ns的中斷響應時間;緊耦合內存保證流水線在一個時鐘周期就能訪問指令和數據;內部總線具有QoS保證優先級;不存在頁表,MPU做在核心內部,無需外部訪問。真實的應用場景可能并不需要納秒級的響應時間,哪怕是馬達控制,系統響應在毫秒級也足夠了。而毫秒與納秒差了1百萬倍。這就給了Arm的A系列機會。
A系列最大的不確定性來自于訪問外部內存時的延遲。我們前面在討論虛擬機的時候分析過,最差情況下,一次頁表讀取,可能需要20倍的訪存時間,差不多是3us。為了使A系列有可能用于實時性任務,軟件上的優化是必須的,包括虛擬機上下文切換等。硬件上,可以縮短特權級切換時間,也可以采取固定分配來提高頁表查找命中率,還可以固定分配某塊緩存或者片上內存給某處理器。方法很多,不一一列出。
以上的優化可以減少單個處理單元的延遲。但是復雜系統里有很多主設備,它們之間共享內存和其他從設備,是有可能產生阻塞和死鎖的。死鎖可以在設計流程過程中通過充分的驗證來發現,而阻塞就得靠優先級QoS設計來避免了。下面我們看看CMN600AE是如何處理的。
實時處理最簡單的方案是給傳輸分優先級。芯片中的總線和從設備根據優先級來決定先后處理。但是僅僅采用優先級會有個問題,就是某些內部資源,比如緩沖,表項已經被低優先級的傳輸占用了。此時如果來一個高優先級的傳輸,由于之前的還沒有完成,就會出現高優先級被低優先級阻塞的情況。怎么辦?可以預先保留相應的資源給高優先級。
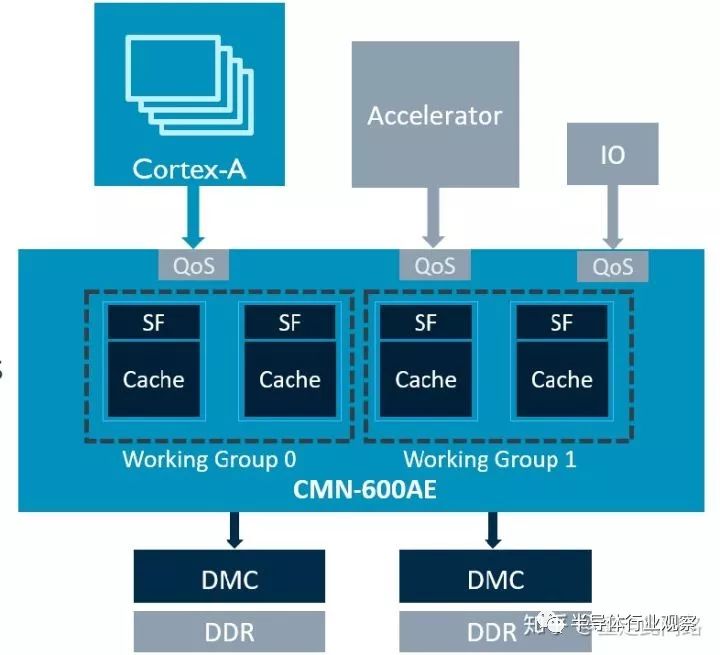
如上圖,在每個與主設備的接口處,都有一個QoS模塊,里面包含了一個優先級定義,可以被軟件編程。這個優先級會隨著傳輸到總線的每一個部分,每個部分都根據優先級來給它相應的資源。有時候,同樣高優先級的請求過多,超過了系統資源的承受范圍。這時候,CMN600AE的內部模塊,會告訴請求傳輸的模塊重傳,并給它一個籌碼。每請求一次,籌碼加一。下次這個籌碼就會隨著新的請求一起傳過來,只要資源有空閑,那么擁有最高籌碼的請求將被允許。QoS模塊還負責統計它所管理的傳輸,看看平均延遲是多少,傳輸間隔是多少,然后動態調整其優先級。
CMN600AE另一個很重要的特性是支持片間硬件一致性互聯。對于輔助駕駛芯片,當面積大到一定程度,比如400mm^2@16nm,良率會迅速下跌。這時候,進一步增加面積不是一個好的選擇。應對的辦法是實現片間互聯,減少單個die的面積。當然,實現高速的PHY本身也會引入相當大的面積,TSMC16FFC上一個支持PCIe Gen4x16的PHY就要6個平方毫米,相當于四核A55加DSU,這里需要做好取舍。片間互聯也會引入額外的片間延遲,可能會達到50ns。
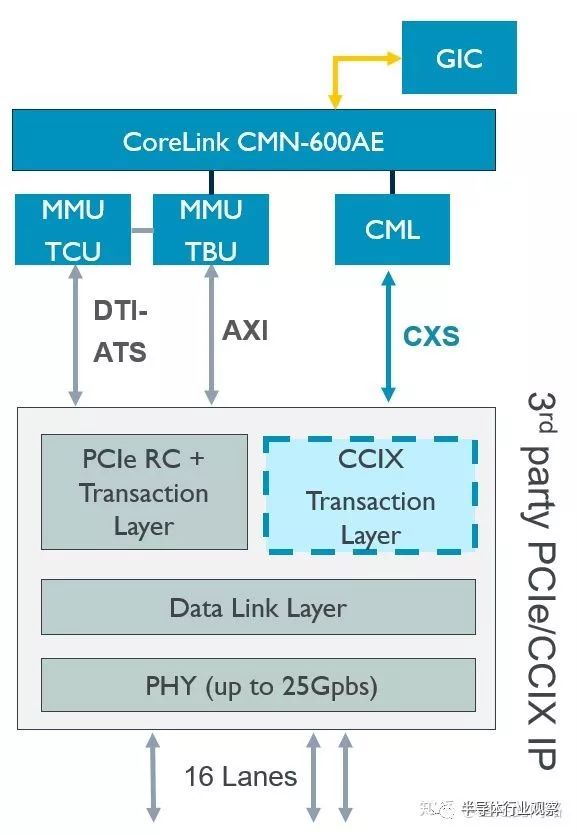
如上圖,有了CMN600AE和片間互聯協議CML,我們就可以把MMU600AE和GIC600AE全部串聯起來,實現片間虛擬化和中斷系統,對軟件完全透明。其中,MMU600AE訪存的實時性靠固定分配虛擬機,以及使用大頁表來保證,目的是消除頁表項的未命中。對于中斷系統的實時性,片內的話使用傳統的SPI/PPI,問題不大,片外的話,只能使用PCIe的消息中斷機制MSI了。支持消息中斷需要ITS表,類似于頁表,也存放在內存中,也有類似緩存的設計。只要保證ITS緩存條目足夠多,映射的設備數量不太多,也是可以消除未命中,提高實時性的。
以上是關于保證實時性的一些考量。接著來看看AEC-Q100,和芯片設計相關的是溫度和電壓。
溫度設計相對簡單,只要工藝允許,標準庫和內存單元支持,那只需在做后端時加入溫度限制條件即可。現在新的中控和輔助駕駛多用TSMC16FFC,可以支持-40C~150C的節溫,相當于環境-40C~125C,其代價是犧牲一定的頻率和面積。
ESD測試是對接口的要求,包括2000V+的HBM和6A+的CDM。和封裝相關,也和芯片IO設計相關。和數字部分IP一樣,PHY和GPIO也需要使用IP來支持AEC-Q100。此處的GPIO指的是200Mhz以下的低速IO,包括但并不限于SPI/PWM/I2C等接口協議。
以GPIO為例,車載設備通常需要支持3.3V和1.8V。為了符合AEC-Q100,GPIO在設計時就能承受額外的電流,并分析各種情況,看看是不是每一條電路分支都能被覆蓋到。通常對于車用GPIO,僅僅用仿真來保證設計的可靠度還不夠,還必須真正流片,用測試芯片做HTOL/LTOL測試,不斷變化溫度,做滿2600小時。否則,會發生仿真通過但是測試芯片過不了測試的問題。一旦測試失效,那必須做失效分析,看看是哪里的電流承載不了,然后修bug重新流片測試。
同時,GPIO本身同樣需要支持功能安全,也就是要加入探測電路,對各類可能產生的失效報警。相對來說,模擬電路失效種類較少,比較容易做到Asil-D。相應的,IP還得提供FMEA和FMEDA報告,供芯片公司過認證。
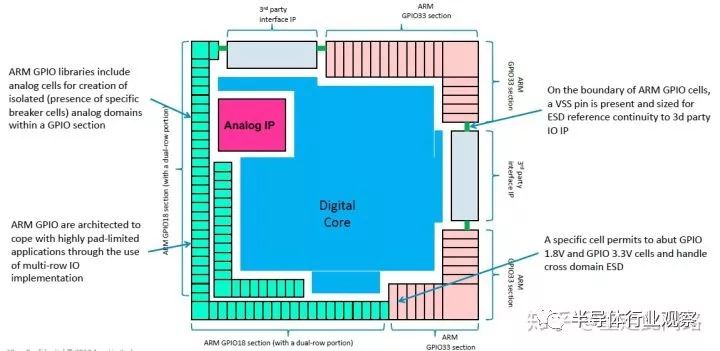
上圖是集成在芯片內部的GPIO,集成時,除了要插入一些特殊的單元來完成不同電壓的IO模塊隔離,還需要注意一定的IO上電次序。
至此,IP模塊分析完畢。接下去我們從芯片系統層面開始分析中控和輔助駕駛芯片。
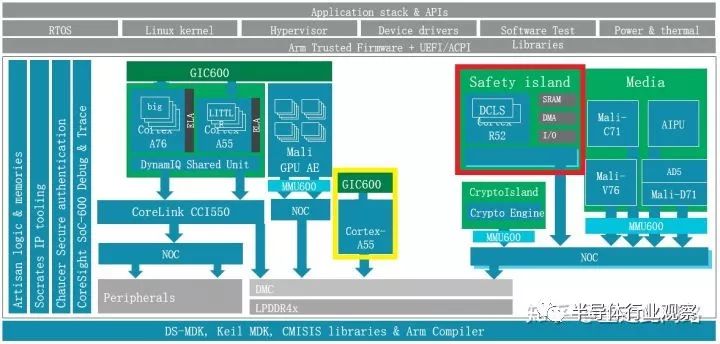
讓我們回頭看看上面的中控芯片結構圖。最重要的是紅色框內的安全島,由R52和緊耦合內存,中斷控制器,總線,內存控制器,以及DMA控制器,硬件鎖,SRAM等組成。理想情況下,每一個模塊都需要是Asil-B/D的。如果做不到,那么至少R52,緊耦合內存和硬件鎖做到。由它們構成安全的基石,用來輪詢其余模塊是否發生故障。同時,這個安全島還可以作為系統控制器,來控制其余模塊的電源,電壓和時鐘狀態;否則,還需要一個Asil-B/D的電源管理的有限狀態機來做這件事情,具體可以參考CMN600AE里時鐘,P/Q通道和重置信號的設計。
作為信息娛樂域的處理器,多媒體,加解密,總線,中斷控制器,調試系統等均無需安全等級,出錯不影響駕駛。需要安全等級的是儀表盤,Asil-B級。由于我們這里已經做了隔離設計,所以不需要考慮信息娛樂域的大小核以及其他主設備對其產生的影響。內存控制器雖然是共享的,但只要做好了類似CMN600AE的QoS,保留出相應的資源,也不用擔心被低優先級阻塞。
黃色框內作為儀表盤處理器的A55,很難被替換成R52,因為圖形處理器通常需要支持MMU的操作系統。此處的操作系統,可以是Asil-B/D級的QNX等,也可以是Asil-B/D級虛擬機之上建立的實時操作系統。另一方面,A55雖然有ECC和RAS機制,但并不支持鎖步,很難做到通用場景下的Asil-B等級。至于同樣被隔離的圖形處理器G31,更沒有安全設計。那怎么把儀表盤做到Asil-B?一旦發生故障,比如儀表盤畫不出正確的圖層,或者干脆不響應,我們可以把A55和G31排除在安全狀態之外,讓R52驅動外置LED燈告知駕駛員錯誤信息。這樣,就把問題歸到了怎樣用Asil-D級的安全島探測錯誤。這個就相對要簡單多了。可以計算每一幀r的CRC,看看是不是連續幾幀不變;也可以定期讓A55響應中斷或者喂狗,又或者同時采用。
在這里,我們引入了一個概念,出錯處理。在失效發生后,系統需要在失效容忍時間間隔(FTTI)內進入安全狀態。所謂的安全狀態,可以是之前的正常運行狀態,也可以是應急的處理狀態。之前儀表盤的錯誤警告LED就是一種應急處理的安全狀態。
對于鎖步設計,最簡單的做法就是重置整個邏輯。如果是處理器,那就需要重啟相應的處理器核心。而這個重啟,必須在失效容忍時間間隔內完成,否則,還是要被視作失效。通常,這個最短容忍時間是10毫秒到100毫秒,和系統應用場景有關。
對于簡單的微控制器,100毫秒甚至10毫秒重啟并不困難。但對于一個復雜的處理器,重啟就是麻煩事了。如果按照傳統的開機流程,那幾秒鐘是需要的,沒法符合要求。那我們就只剩下兩條路,第一個是使用虛擬機。如果發生失效的并不是Hypervisor所運行的處理器核,可以只重啟某個虛擬機來實現加速。對于重要的高實時任務,還可以兩個虛擬機跑同一個業務,互為備份,一個出問題那立刻切另外一路;也可以用一個虛擬機待機,看其余哪個虛擬機重啟,立刻開始接手那個虛擬機的業務。如果是Hypervisor所運行的處理器核重啟,那優化重啟過程,保存當前上下文環境至內存,并且盡量調整驅動啟動步驟,做到最先使用的主設備優先初始化。可以參考手機上的Suspend To Ram機制,手機基本上可以做到休眠時全芯片下電,數據保留在DDR,喚醒時處理器起來調用顯示模塊,先顯示之前保存的圖層,再啟動圖形處理器渲染新的幀,做到無明顯感覺。利用這種機制,對于儀表盤失效,可以先告警,然后在毫秒級的時間內完成相應子系統重啟。
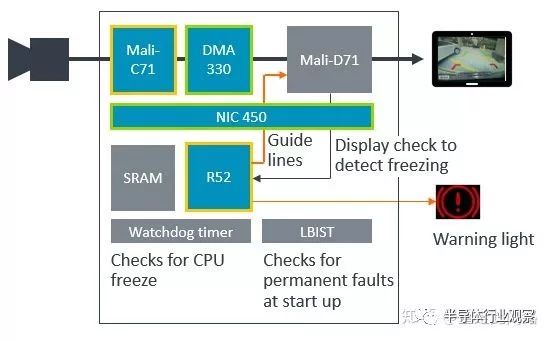
再來看看媒體部分的安全設計問題。上圖中是倒車后視的子系統,圖像信號處理是C71(Asil-B),R52(Asil-D),總線NIC450(QM),DMA330(QM),SRAM(帶ECC),顯示模塊D71(QM)。子系統要求做到Asil-B等級。由于并不是所有模塊都做到了Asil-B,我們需要對其做失效樹分析。真正出現失效的場景,在于顯示畫面凍結在某一幀。瞬時錯誤引起的一些問題,比如某幀畫面有壞點,并不構成失效。因此,我們要做的事情就變成兩件:先用R52從顯示模塊獲取每一幀的CRC,看看是不是連續多幀都不變,如果出錯,立刻亮燈告警,這個計算必須在失效容忍時間間隔內完成;其次,開機或者周期性運行LBIST/MBIST,看看是不是存在永久錯誤,有的話也需要告警。只要圖像的源頭C71有Asil-B,R52高于Asil-B,我i們可以放松對其余幾個模塊探測瞬時錯誤的要求。
接下來我們看輔助駕駛的芯片框架圖,和中控不同,輔助駕駛需要感知和決策,是一個復雜的實時運算過程,沒有辦法通過安全島監測來達到高等級安全,只能通過處理器本身來保證。所以這里的處理器全部換成了帶冗余設計的A76AE和A65AE。虛擬化在這個系統里并不是必須,MMU600AE僅僅是為了虛實地址轉換。由于沒有采用虛擬機,各個處理單元之間的數據隔離可以靠CMN600AE的MPU來完成。沒有經過CMN600AE的設備,需要在和總線之間添加MPU來實行地址保護,并且所有的MPU配置要保持一致。另一方面,使用MPU也限制了分區不能太多,否則就需要映射到內存。到底使用虛擬機還是MPU進行隔離需要看應用來決定。另外,如果需要片間互聯,那所有主設備都應該通過NoC AE形成子網連到CMN600AE。
這個框架的計算流是這樣的:C71(Asil-B)把數據從傳感器收集,做固定的圖像信號處理,把結果放到DDR;A65AE讀取數據,進行車道檢測等傳統的矢量運算。相對于大核,A65AE提供了高能效比的運算能力,適合多路并行計算。也可以把任務丟到圖形處理器來運算,延遲稍大,能效比也很高。如果涉及神經網絡運算,那A76AE會把任務調度到AI加速器上,同時在算子不足的情況下負責部分計算。也可以調度到圖形處理器,不存在算子不支持的問題。當然,對于神經網絡計算,能效比還是趕不上專用加速器。A76AE作為大核,具有很高的單線程性能,可以用來做決策。
CMN600AE作為橋梁,連接了所有設備,并提供高帶寬,硬件一致性以及系統緩存。受布局布線的限制,還是需要NoC把帶寬和延遲需求不高的設備通過子網連到CMN600AE。
最后劃一下重點。汽車芯片的關鍵是實時性,功能安全,電氣,虛擬化。功能安全最復雜,需要IP級就開始支持。如果不符合,那需要場景分析做分解,用最少的代價實現安全。
-
處理器
+關注
關注
68文章
19165瀏覽量
229130 -
圖像傳感器
+關注
關注
68文章
1883瀏覽量
129453 -
汽車芯片
+關注
關注
10文章
833瀏覽量
43354
原文標題:行業 | 一文讀懂汽車芯片設計!
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

一文讀懂汽車芯片—圖像傳感器芯片
一文讀懂汽車芯片—圖像傳感器芯片

一文讀懂汽車芯片—激光雷達








 工商網監
工商網監
評論