") ICLR 2019在官網(wǎng)公布了最佳論文獎!
ICLR 2019在官網(wǎng)公布了最佳論文獎!
ICLR 2019今天在官網(wǎng)公布了最佳論文獎!兩篇最佳論文分別來自Mila/加拿大蒙特利爾大學、微軟蒙特利爾研究院和MIT CSAIL,主題分別集中在NLP深度學習模型和神經(jīng)網(wǎng)絡(luò)壓縮。
今天,ICLR 2019在官網(wǎng)公布了最佳論文獎!

兩篇最佳論文分別來自Mila/加拿大蒙特利爾大學、微軟蒙特利爾研究院和MITCSAIL,主題分別集中在NLP深度學習模型和神經(jīng)網(wǎng)絡(luò)壓縮。
ICLR 是深度學習領(lǐng)域的頂級會議,素有深度學習頂會 “無冕之王” 之稱。今年的 ICLR 大會從5月6日到5月9日在美國新奧爾良市舉行。
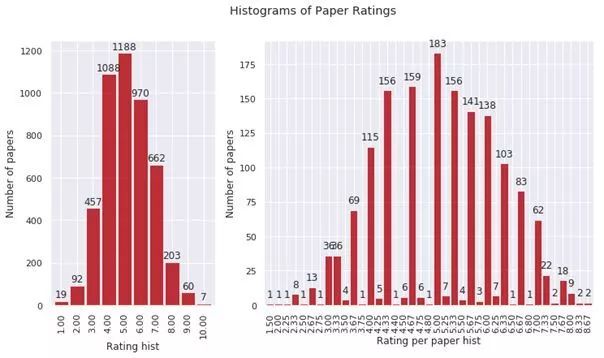
今年 ICLR 共接收 1578 篇投稿,相較去年 981 篇有了很大的增加,錄用結(jié)果如下:1.5% 錄用為 oral 論文(24 篇)、30.2% 錄用為 poster 論文(476 篇),58% 論文被拒(918 篇)、610% 撤回(160 篇)。
與往年一樣,ICLR 2019采用公開評審制度,所有論文會匿名公開在 open review 網(wǎng)站上,接受同行們的匿名評分和提問。
今年論文平均打分是 5.15
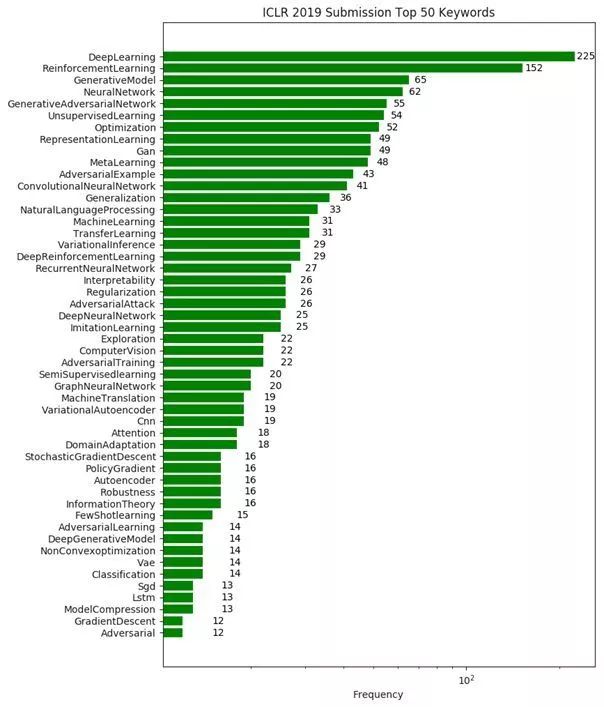
關(guān)鍵詞排序前 50
接下來,新智元帶來兩篇最佳論文的解讀:
最佳論文1:有序神經(jīng)元:將樹結(jié)構(gòu)集成到循環(huán)神經(jīng)網(wǎng)絡(luò)
標題:Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks
《有序神經(jīng)元:將樹結(jié)構(gòu)集成到循環(huán)神經(jīng)網(wǎng)絡(luò)》
作者:Yikang Shen,Shawn Tan,Alessandro Sordoni,Aaron Courville
作者機構(gòu):Mila/加拿大蒙特利爾大學、微軟蒙特利爾研究院
論文地址:https://openreview.net/forum?id=B1l6qiR5F7

摘要:
自然語言是一種分層結(jié)構(gòu):較小的單元(例如短語)嵌套在較大的單元(例如子句)中。當較大的成分結(jié)束時,嵌套在其中的所有較小單元也必須結(jié)束。雖然標準的LSTM架構(gòu)允許不同的神經(jīng)元在不同的時間尺度上跟蹤信息,但它并沒有明確地偏向于對成分層次結(jié)構(gòu)建模。
本文提出通過對神經(jīng)元進行排序來增加這種歸納偏差;一個主輸入和遺忘門的向量確保當一個給定的神經(jīng)元被更新時,按照順序跟隨它的所有神經(jīng)元也被更新。所提出的新循環(huán)結(jié)構(gòu)稱為有序神經(jīng)元LSTM (ordered neurons LSTM, ON-LSTM),在語言建模、無監(jiān)督句法分析、目標語法評估和邏輯推理四個不同的任務(wù)上都取得了良好的性能。
關(guān)鍵詞:深度學習,自然語言處理,遞歸神經(jīng)網(wǎng)絡(luò),語言建模
一句話概括:本文提出一種新的歸納偏置,將樹結(jié)構(gòu)集成到循環(huán)神經(jīng)網(wǎng)絡(luò)中。
從實用的角度看,將樹結(jié)構(gòu)集成到神經(jīng)網(wǎng)絡(luò)語言模型中有以下幾個重要原因:
深度神經(jīng)網(wǎng)絡(luò)的一個關(guān)鍵特征是獲得抽象層次不斷增加的分層表示;
建模語言的組成效應(yīng),并為梯度反向傳播提供快捷方式,以幫助解決長期依賴問題;
通過更好的歸納偏置改進泛化,同時能夠減少對大量訓練數(shù)據(jù)的需求。

圖1:由模型推斷的二進制解析樹(左)及其對應(yīng)的round-truth(右)。
問題是:具有對學習這種潛在樹結(jié)構(gòu)的歸納偏置的架構(gòu)能否獲得更好的語言模型?
在這篇論文中,我們提出有序神經(jīng)元(ordered neurons),這是一種面向循環(huán)神經(jīng)網(wǎng)絡(luò)的新型歸納偏置。這種歸納偏置增強了存儲在每個神經(jīng)元中的信息的生命周期的分化:高級神經(jīng)元存儲長期信息,這些信息通過大量步驟保存,而低級神經(jīng)元存儲短期信息,這些信息可以很快被遺忘。
為了避免高級和低級神經(jīng)元之間的固定劃分,我們提出一種新的激活函數(shù)——cumulative softmax,或稱為cumax(),用于主動分配神經(jīng)元來存儲長/短期信息。
基于cumax()和LSTM架構(gòu),我們設(shè)計了一個新的模型ON-LSTM,該模型偏向于執(zhí)行類似樹的組合操作。
ON-LSTM模型在語言建模、無監(jiān)督成分句法分析、目標句法評估和邏輯推理四項任務(wù)上都取得了良好的性能。對無監(jiān)督成分句法分析的結(jié)果表明,所提出的歸納偏置比以前模型更符合人類專家提出的語法原則。實驗還表明,在需要捕獲長期依賴關(guān)系的任務(wù)中,ON-LSTM模型的性能優(yōu)于標準LSTM模型。
有序神經(jīng)元
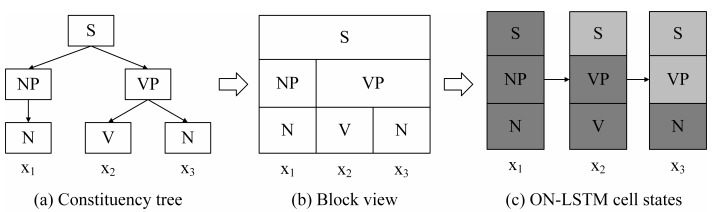
圖2:一個成分解析樹和ON-LSTM的隱藏狀態(tài)之間的對應(yīng)關(guān)系
ON-LSTM
ON-LSTM模型與標準LSTM的架構(gòu)類似:
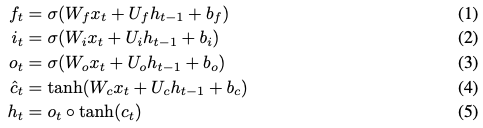
與LSTM的不同之處在于,這里用了一個新函數(shù)替換cell state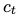 的?update?函數(shù)。
的?update?函數(shù)。
實驗
語言建模
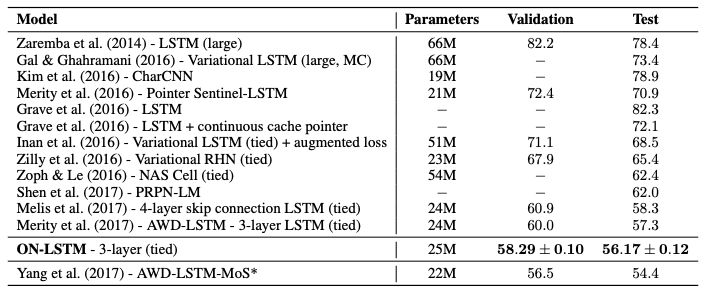
表1:Penn Treebank語言建模任務(wù)驗證集和測試集上的單模型困惑度。
如表1所示,ON-LSTM模型在共享相同的層數(shù)、嵌入維數(shù)和隱藏狀態(tài)單元的情況下,比標準的LSTM性能更好。值得注意的是,我們可以在不添加skip connection或顯著增加參數(shù)數(shù)量的情況下提高LSTM模型的性能。
無監(jiān)督成分句法分析(ConstituencyParsing)
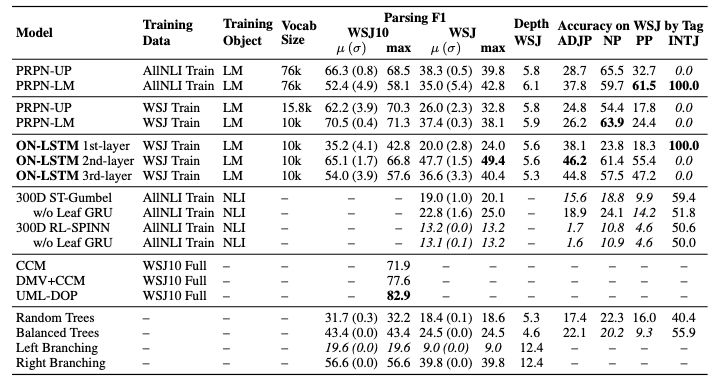
表2:在full WSJ10和WSJ test兩個數(shù)據(jù)集上評估的成分句法分析結(jié)果
目標句法評估
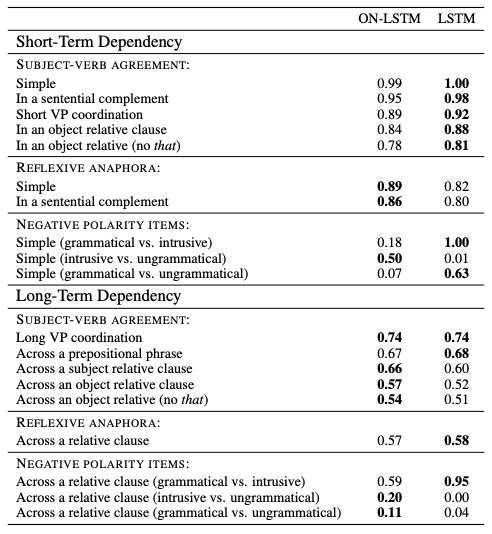
表3:ON-LSTM和LSTM在每個測試用例中的總體精度
表3顯示,ON-LSTM在長期依賴情況下表現(xiàn)更好,而基線LSTM在短期依賴情況下表現(xiàn)更好。不過,ON-LSTM在驗證集上實現(xiàn)了更好的困惑度。
邏輯推理
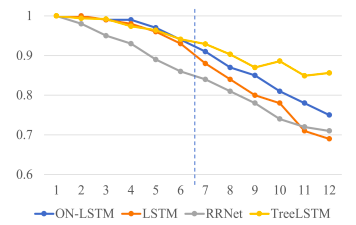
圖3:模型的測試準確性,在邏輯數(shù)據(jù)的短序列(≤6)上訓練。
圖3顯示了ON-LSTM和標準LSTM在邏輯推理任務(wù)上的性能。
最佳論文2:彩票假設(shè)
標題:The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
《彩票假設(shè):尋找稀疏的、可訓練的神經(jīng)網(wǎng)絡(luò)》
作者:Jonathan Frankle,Michael Carbin
作者機構(gòu):MIT CSAIL
論文地址:https://openreview.net/forum?id=rJl-b3RcF7

摘要:
神經(jīng)網(wǎng)絡(luò)剪枝技術(shù)可以在不影響精度的前提下,將訓練網(wǎng)絡(luò)的參數(shù)數(shù)量減少90%以上,降低存儲需求并提高推理的計算性能。然而,當前的經(jīng)驗是,剪枝產(chǎn)生的稀疏架構(gòu)從一開始就很難訓練,這同樣可以提高訓練性能。
我們發(fā)現(xiàn),一種標準的剪枝技術(shù)可以自然地揭示子網(wǎng)絡(luò),這些子網(wǎng)絡(luò)的初始化使它們能夠有效地進行訓練。基于這些結(jié)果,我們提出了“彩票假設(shè)”(lottery ticket hypothesis):包含子網(wǎng)絡(luò)(“中獎彩票”,winning tickets)的密集、隨機初始化的前饋網(wǎng)絡(luò),這些子網(wǎng)絡(luò)在單獨訓練時,經(jīng)過類似次數(shù)的迭代達到與原始網(wǎng)絡(luò)相當?shù)臏y試精度。我們找到的“中獎彩票”中了初始化彩票:它們的連接具有初始權(quán)重,這使得訓練特別有效。
我們提出一個算法來確定中獎彩票,并激進型了一系列實驗來支持彩票假說以及這些偶然初始化的重要性。我們發(fā)現(xiàn),MNIST和CIFAR10的中獎彩票的規(guī)模始終比幾個全連接架構(gòu)和卷積前饋架構(gòu)小10-20%。超過這個規(guī)模的話,我們發(fā)現(xiàn)中獎彩票比原來的網(wǎng)絡(luò)學習速度更快,達到了更高的測試精度。
關(guān)鍵詞:神經(jīng)網(wǎng)絡(luò),稀疏性,剪枝,壓縮,性能,架構(gòu)搜索
一句話概括:可以在訓練后剪枝權(quán)重的前饋神經(jīng)網(wǎng)絡(luò),也可以在訓練前剪枝相同的權(quán)重。
本文證明了,始終存在較小的子網(wǎng)絡(luò),它們從一開始就進行訓練,學習速度至少與較大的子網(wǎng)絡(luò)一樣快,同時能達到類似的測試精度。
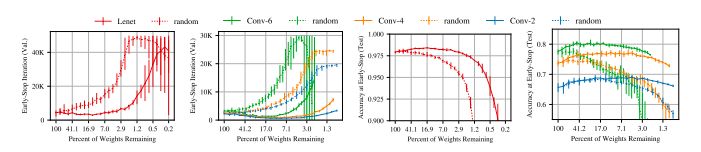
圖1:早期停止發(fā)生的迭代(左邊)和用于MNIST的Lenet架構(gòu)以及用于CIFAR10的conv2、conv4和conv6架構(gòu)的迭代(右邊)的測試精度。虛線是隨機抽樣的稀疏網(wǎng)絡(luò)。實線是中獎彩票。
圖1中的實線顯示了我們找到的網(wǎng)絡(luò),即winning tickets。
論文提出了幾個新概念,首先是“彩票假設(shè)”(The Lottery Ticket Hypothesis)。
彩票假設(shè):將一個復雜網(wǎng)絡(luò)的所有參數(shù)當作一個獎池,獎池中存在一組子參數(shù)所對應(yīng)的子網(wǎng)絡(luò)(代表中獎號碼,文中的wining ticket),單獨訓練該子網(wǎng)絡(luò),可以達到原始網(wǎng)絡(luò)的測試精度。
那么怎樣找到中獎彩票呢?
確定中獎彩票:通過訓練一個網(wǎng)絡(luò)并修剪它的最小量級權(quán)重來確定中獎彩票。其余未修剪的連接構(gòu)成了中獎彩票的架構(gòu)。
具體來說,有以下4步:
隨機初始化一個復雜神經(jīng)網(wǎng)絡(luò)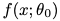
訓練復雜網(wǎng)絡(luò)j次,得到網(wǎng)絡(luò)參數(shù)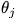
對模型按p%進行修剪,得到一個mask m;將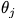
對留下來的模型,重新用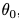
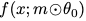
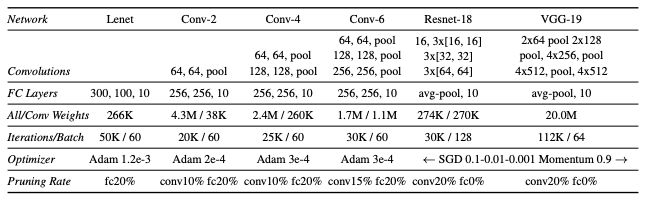
圖2:本文測試的架構(gòu)
本文的貢獻
我們證明剪枝可以揭示可訓練的子網(wǎng)絡(luò),這些子網(wǎng)絡(luò)達到了與原始網(wǎng)絡(luò)相當?shù)臏y試精度;
我們證明剪枝發(fā)現(xiàn)的中獎彩票比原始網(wǎng)絡(luò)學習更快,同時具有更高的測試精度和更好的泛化能力。
我們提出“彩票假設(shè)”,作為神經(jīng)網(wǎng)絡(luò)組成的新視角,可以解釋這些發(fā)現(xiàn)。
應(yīng)用
本文對彩票假設(shè)進行了實證研究。既然我們已經(jīng)證明了中獎彩票的存在,我們希望利用這一知識:
提高訓練性能。由于中獎彩票可以從一開始就單獨進行訓練,我們希望能夠設(shè)計出能夠搜索中獎彩票并盡早進行修剪的訓練方案。
設(shè)計更好的網(wǎng)絡(luò)。中獎彩票揭示了稀疏架構(gòu)和特別擅長學習的初始化的組合。我們可以從中獲得靈感,設(shè)計有助于學習的新架構(gòu)和初始化方案。我們甚至可以把為一項任務(wù)發(fā)現(xiàn)的中獎彩票遷移到更多其他任務(wù)。
提高對神經(jīng)網(wǎng)絡(luò)的理論理解。我們可以研究為什么隨機初始化的前饋網(wǎng)絡(luò)似乎包含中獎彩票,以及增加對優(yōu)化和泛化的理論理解。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4764瀏覽量
100541 -
論文
+關(guān)注
關(guān)注
1文章
103瀏覽量
14950 -
深度學習
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120979
原文標題:ICLR 2019最佳論文揭曉!NLP深度學習、神經(jīng)網(wǎng)絡(luò)壓縮成焦點
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
摩爾斯微電子榮獲2024年WBA行業(yè)大獎最佳Wi-Fi創(chuàng)新獎等多項殊榮
華銳捷榮獲第六屆金輯獎“最佳技術(shù)實踐應(yīng)用獎”
安富利榮獲第六屆金輯獎“最佳技術(shù)實踐應(yīng)用獎”
類比半導體榮獲第六屆金輯獎“最佳技術(shù)實踐應(yīng)用獎”
賽卓電子榮獲2024金輯獎——最佳技術(shù)實踐應(yīng)用獎

愛芯元速榮膺最佳技術(shù)實踐應(yīng)用獎
安波福蘇州榮獲“2024大蘇州最佳雇主”及“2024最佳HR團隊獎”
2024年上海海思MCU開發(fā)者體驗官招募,手機/MatePad大獎等你拿!
中科馭數(shù)聯(lián)合處理器芯片全國重點實驗室獲得“CCF芯片大會最佳論文獎”
南芯科技榮獲OPPO 2024 年度“最佳交付獎”和“優(yōu)秀質(zhì)量獎”
千視榮獲2023年度DAV數(shù)字音視工程網(wǎng)年度最佳解決方案獎!

沙特stc和華為商用核心網(wǎng)自動化實踐榮獲“年度最佳自動化項目獎”
ICLR 2024高分投稿:用于一般時間序列分析的現(xiàn)代純卷積結(jié)構(gòu)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論