 用于語音情緒識別的基于對抗學習的說話人無關的表示
用于語音情緒識別的基于對抗學習的說話人無關的表示
1. 用于語音情緒識別的基于對抗學習的說話人無關的表示
嘗試解決的問題:
在語音情緒識別任務中,會面臨到要測試的說話人未出現在訓練集中的這個問題,本文嘗試運用TDNN+LSTM作為特征提取部分,再通過對抗學習的方法來做到讓模型可以對說話人身份不敏感,從模型上來說,該對抗訓練的思想就是將特征提取器提取到的特征同時輸入到說話人身份分類器和情緒識別分類器,對抗訓練的損失函數是讓說話人身份分類器的損失達到最大,讓情緒識別分類器的損失達到最小,這樣以后,無論是哪個說話人的語音,經過特征提取那部分以后,就沒有身份這一區別了。
如果有讀者閱讀過論文《Domain adversarial training of neural networks》,那么對DAT這個名詞就不陌生了,即遷移學習中的跨域學習,比如我現在有A領域的數據,并且該數據已經被標記好類別,同時也有B領域數據,但是未進行標記,如果我希望充分利用B數據,目標是進行分類,該怎么利用呢?我們只需要三個模塊結合對抗學習即可完成,分別是特征提取器+域識別器+分類器,當域識別器已經無法正確判斷的時候,說明特征提取器已經完成了身份融合的效果,這個時候訓練分類器即可。
在本篇語音情緒識別中,作者所提出的模型如下圖所示,輸入音頻的MFCC特征經過TDNN網絡(由卷積神經網絡實現)和BiLSTM網絡得到新的特征分布,再將此特征分布同時輸送到情緒識別器得到情緒種類y和說話人身份識別器得到身份s。
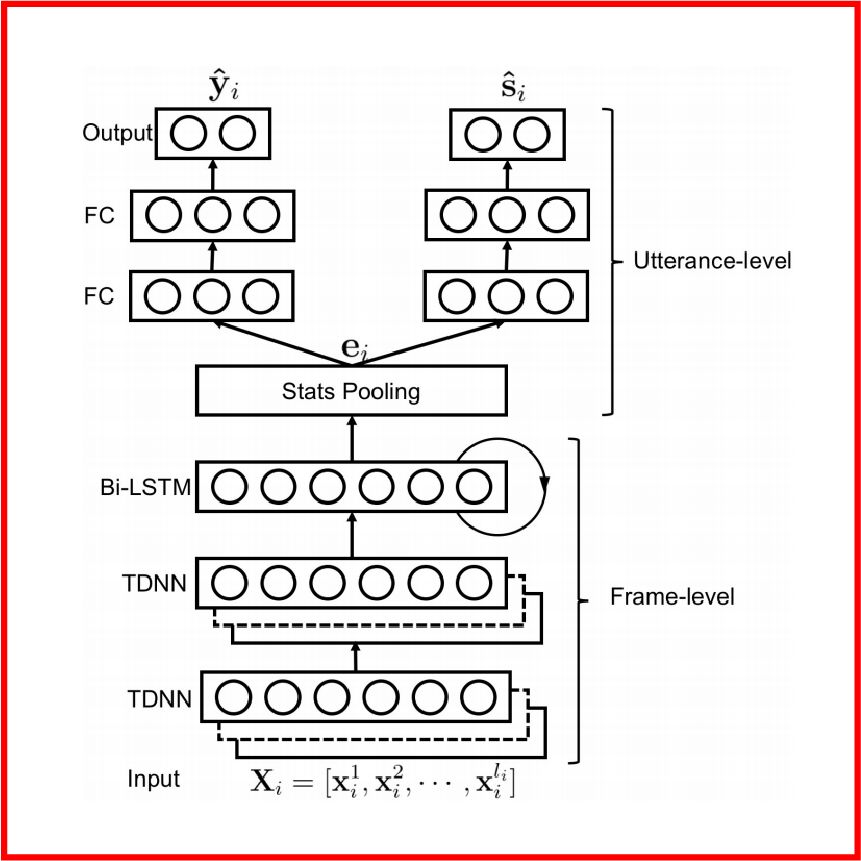
作者嘗試運用了兩種訓練方法,一種是domain adversial training,即DAT;另一種是cross gradient training,即CGT。下面我將分別解釋這兩種訓練算法。
DAT
如前所述,DAT是通過對抗學習來使得網絡具備跨域的能力,其損失函數如下,可以看到,對于身份識別器而言,它的損失函數前面乘了一個因子并且取了負號,這使得網絡可以具備身份融合的作用,從而專注于情緒分類。
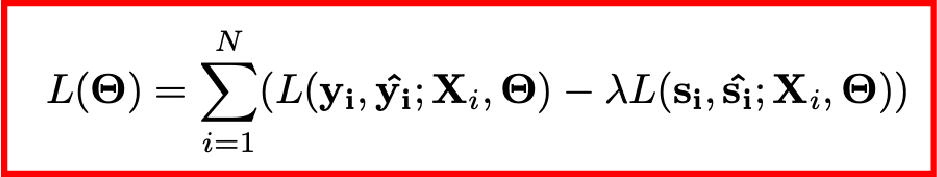
CGT
CGT是另外一種解決跨域學習的數據增強技巧,它通過將梯度傳到輸入數據上,于是情緒識別網絡可以訓練原數據和增強后的數據,這樣就可以使得模型具備學習跨域的變化特征進而可以適應未知的測試數據集。CGT的數據增強技巧和損失函數如下,其中前兩項是增強后的新數據,最后是參數更新公式。
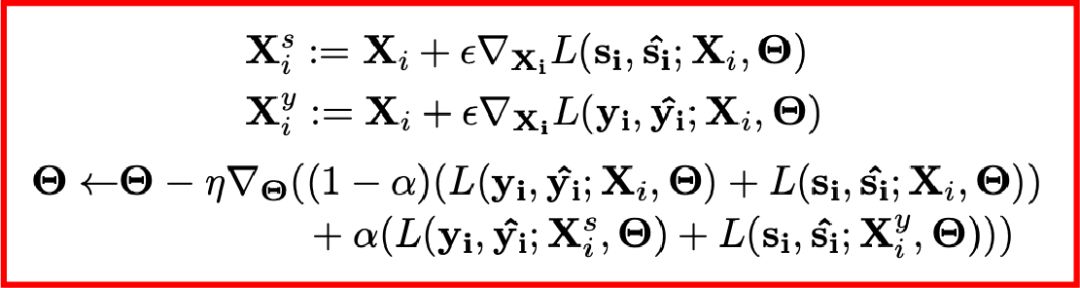
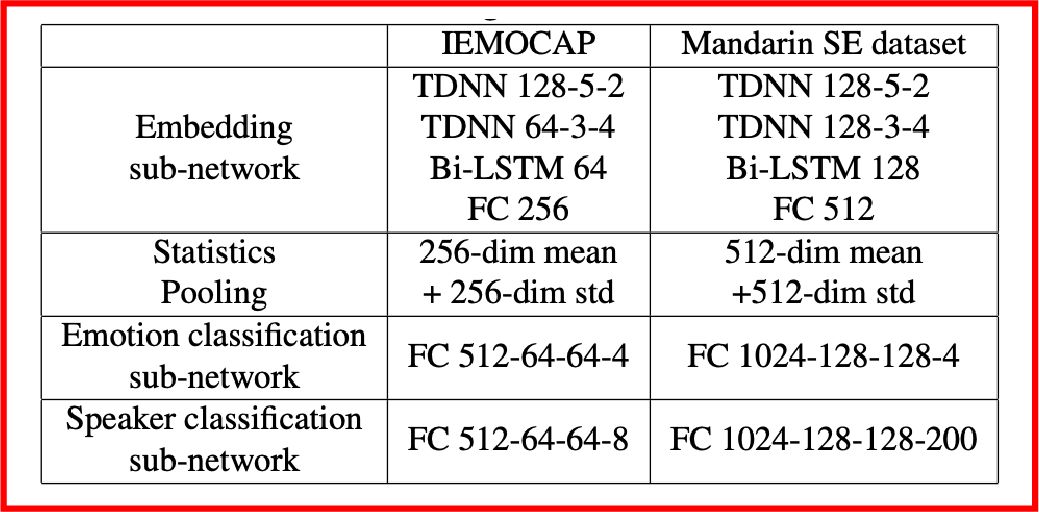
作者基于本模型和兩種訓練技巧分別在IEMOCAP數據集和SpeechOcean中文大數據集上做了測試,所用的具體模型結構如下所示,實驗結果表明,在IEMOCAP小數據集上,相比于基線模型,DAT提高了5.6%,CGT提高了7.4%;但是在SpeechOcean 250說話人的中文大數據集上,DAT提高了9.8%,CGT的性能不及基線模型。
同時,作者畫出了通過DAT訓練的經過特征提取器得到的特征分布的t-SNE降維表示,如下圖所示,左邊是情緒類別,右邊是身份類別,可以看到身份標簽已經很好地被融合在一起。
2. 基于濾波和深度神經網絡的聲源增強
參考文獻:
data-driven design of perfect reconstruction filterbank for dnn-based sound source enhancement
鏈接:
https://arxiv.org/abs/1903.08876
單位:
早稻田大學 & 日本電話電報公司
嘗試解決的問題:
傳統的聲源增強(Sound-source enhancement,SSE)的做法是首先將含噪音的信號進行STFT變換得到時頻圖,再借助深度神經網絡進行特征變換,將得到的新的時頻圖與目標時頻圖進行求均方差,基于此均方差來訓練神經網絡的參數。訓練好網絡以后,將推理得到的時頻圖通過ISTFT變換到音頻,即可得到增強的音頻信號。這種做法的缺點按照文中的描述就是:
For example, MSE assumes that the error of all frequency bins has zero means and uniform variance, which cannot be met in usual situations, unfortunately.
按照筆者的理解就是訓練均方差目標函數得確保數據中每個頻率倉的均值和方差一樣,因為只有這樣訓練才比較有效參數才可以穩定地更新,但是實際上,我們在計算STFT的時候,并沒有考慮到所有音頻的個體差異,本文嘗試解決的就是這里的維度上的統計均勻的問題,DNN的框架是沒有變的,整體框架可以參見下圖的對比:

首先,傳統的STFT算法作用到一個信號x上可以用如下公式描述:
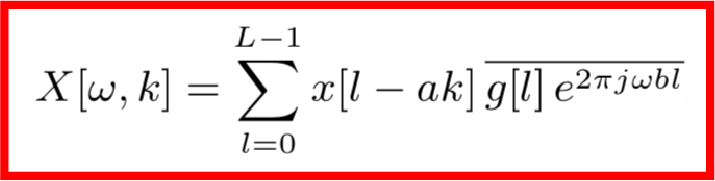
這里得到的X就是該信號的時頻信息,其中ω是頻率索引,k是幀索引。我們知道,X是由目標信號和噪音信號共同組成的,根據傅里葉變換的可加性,可知:
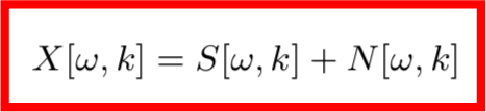
為了得到目標時頻,我們在X[ω,k]的基礎上作用一個T-F遮罩G[ω,k],該T-F遮罩一般使用深度神經網絡M來實現,于是整個模型的損失函數可以寫成如下形式:
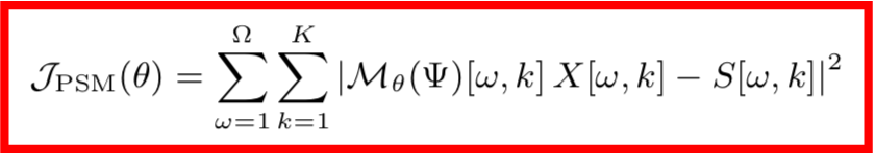
但是基于MSE的訓練算法有一個數據上的缺陷,因為MSE的前提假設是各個維度的數據分布要保持一致,但這在實際中是很難保證的,因無論是聲源還是噪聲都有著不均勻的頻譜分布,舉個例子,由于高頻區域音頻較少,功率譜較小,誤差變化比較小,因而高頻區域要比低頻區域更難訓練。這個時候,對損失函數做一個加權是合理的想法,該權重應該是自適應頻率的,并且與頻率誤差的標準差成反比,也就是說誤差標準差越小的頻率,我們需要多重視一下它的損失函數。
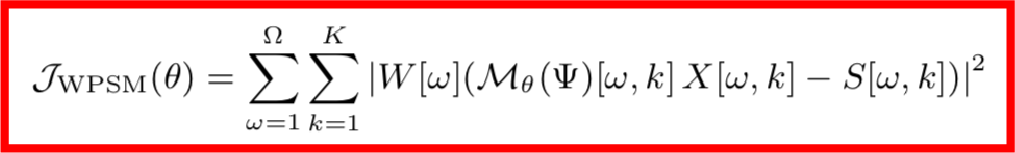
其中,權重的計算公式如下:
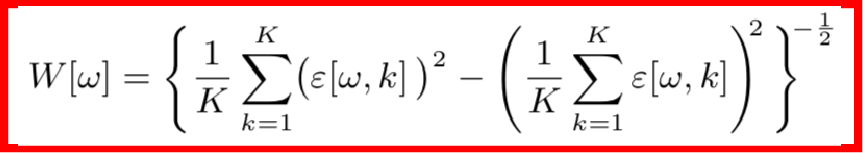
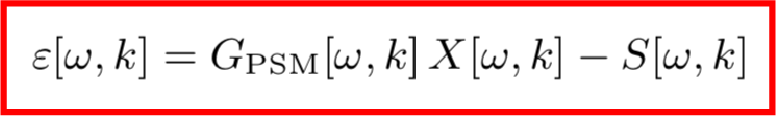

但是這樣又帶來一個問題,因為功率譜較小的頻率區域權重比較大,故模型對那些區域的噪聲特別敏感,那么,算法的有效性就降低了。
本文作者提出的改進的思路是保持損失函數不變,而對STFT部分進行改進,公式如下,作者將原公式中的ω定義成了φ(ω)的倒數的形式,這樣就可以自定義頻率的量級,這里的φ函數稱之為頻率扭曲函數。
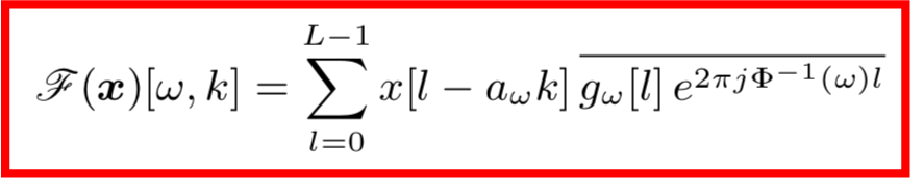
那么如何設計這里的頻率扭曲函數φ呢?通過對誤差的功率譜密度進行累計求和,依次從低頻到高頻,并加上一個規則化因子:

本文中所用的特征變換網絡的結構如下表所示,分別是全連接神經網絡+兩層雙向LSTM循環神經網絡+全連接分類網絡,以輸出目標頻譜。

最后作者將此模型運用到以WSJ-0作為目標數據集,以CHiME-3作為噪聲來源所構成的四套數據上,即通過構建含噪音頻-清晰音頻配對來作為訓練樣本,得到的實驗結果如下,圖中的數值代表信噪比,數值越大,表明信噪比越高,即增強效果越好。
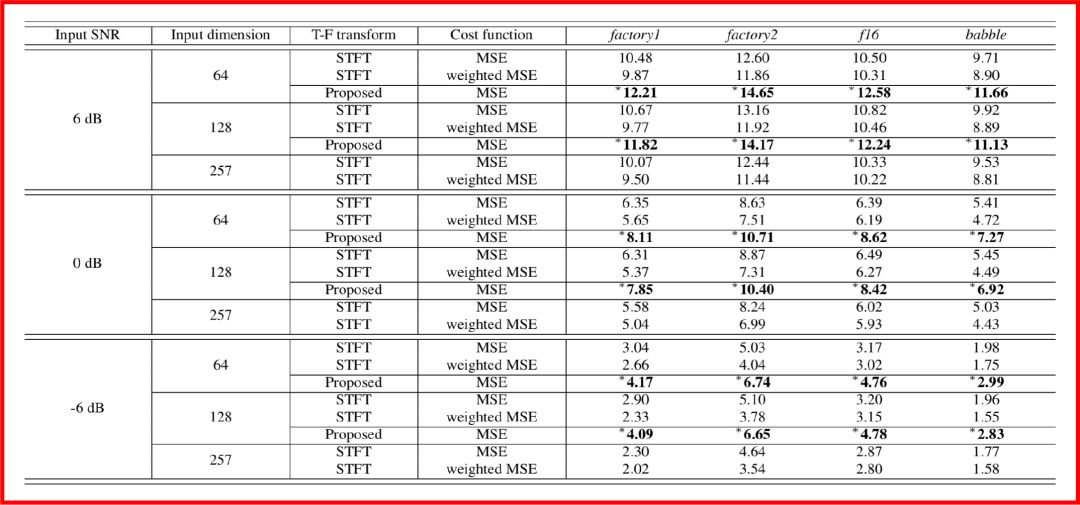
總體而言,這篇文章是基于平行語料和深度神經網絡,對語音增強中的輸入頻譜的預處理算法進行改進,以解決基于均方差訓練中可能會出現的訓練不穩定的問題。以后的推送中將會看到,對于語音增強或語音分離,我們甚至可以采用非平行語料來做。
3. 用于語音韻律、頻譜可視化的在線網頁平臺
參考文獻:
CRAFT: A Multifunction Online Platform for Speech Prosody Visualisation
鏈接:
https://arxiv.org/abs/1903.08718
單位:
比勒費爾德大學
demo體驗網址:
http://wwwhomes.uni-bielefeld.de/gibbon/CRAFT/
嘗試解決的問題:
提供一個更加友好的基頻(各種不同的實現算法)、頻譜包絡可視化對比的在線平臺。
這里我們先回顧幾個聲學頻譜分析中的概念:
基頻:一般我們對一個音頻作短時傅里葉變化并畫出時頻圖的時候,時頻圖上會出現很多條橫條紋,而頻率范圍最小的那個橫條紋一般可以認為就是基頻的值;
諧波:除了基頻那個橫條紋以外,其他橫條紋就是各次諧波;
共振峰:頻譜上包絡的峰值;
本文中介紹的demo如下圖所示,其中包含基頻估計的參數設計、振幅和頻率調制、頻率解調制、濾波等可視化窗口。

-
分類器
+關注
關注
0文章
152瀏覽量
13174 -
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
遷移學習
+關注
關注
0文章
74瀏覽量
5557
原文標題:語音情緒識別|聲源增強|基頻可視化
文章出處:【微信號:DeepLearningDigest,微信公眾號:深度學習每日摘要】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
說話人識別和驗證系統解決方案

會物體識別和語音識別的nao機器人
請問電銷機器人智能語音識別的原理是什么?
基于TMS320C6701EVM板的快速說話人識別系統
基于TMS320C6701EVM板的快速說話人識別系統
基于CS的說話人識別算法
如何使用多特征i-vector進行短語音說話人識別算法說明





 工商網監
工商網監
評論