 一份深度學習“人體姿勢估計”全指南,從DeepNet到HRNet
一份深度學習“人體姿勢估計”全指南,從DeepNet到HRNet
從DeepNet到HRNet,這有一份深度學習“人體姿勢估計”全指南
幾十年來,人體姿態估計(Human Pose estimation)在計算機視覺界備受關注。它是理解圖像和視頻中人物行為的關鍵一步。
在近年深度學習興起后,人體姿態估計領域也發生了翻天覆地的變化。
今天,文摘菌就從深度學習+二維人體姿態估計的開山之作DeepPose開始講起,為大家盤點近幾年這一領域的最重要的論文。
什么是人體姿勢估計?
人體姿態估計(Human Pose Estimation,以下簡稱為HPE)被定義為圖像或視頻中,人體關節(也被稱為關鍵點-肘部、手腕等)的定位問題。它也被定義為,在所有關節姿勢組成的空間中搜索特定姿勢。
二維姿態估計-運用二維坐標(x,y)來估計RGB圖像中的每個關節的二維姿態。
三維姿態估計-運用三維坐標(x,y,z)來估計RGB圖像中的三維姿態。
HPE有一些非常酷的應用,在動作識別(action recognition)、動畫(animation)、游戲(gaming)等領域都有著廣泛的應用。例如,一個非常火的深度學習APP —— HomeCourt,可以使用姿態估計(Pose Estimation)來分析籃球運動員的動作。
為什么人體姿勢估計這么難?
靈活、小而幾乎看不見的關節、遮擋、衣服和光線變化都為人體姿態估計增加了難度。
二維人體姿態估計的不同方法
傳統方法
關節姿態估計的傳統方法是使用圖形結構框架。這里的基本思想是,將目標對象表示成一堆“部件(parts)”的集合,而部件的組合方式是可以發生形變的(非死板的)。
一個部件表示目標對象某部分圖形的模板。“彈簧”顯示部件之間的連接方式,當部件通過像素位置和方向進行參數化后,其所得到的結構可以對與姿態估計非常相關的關節進行建模。(結構化預測任務)
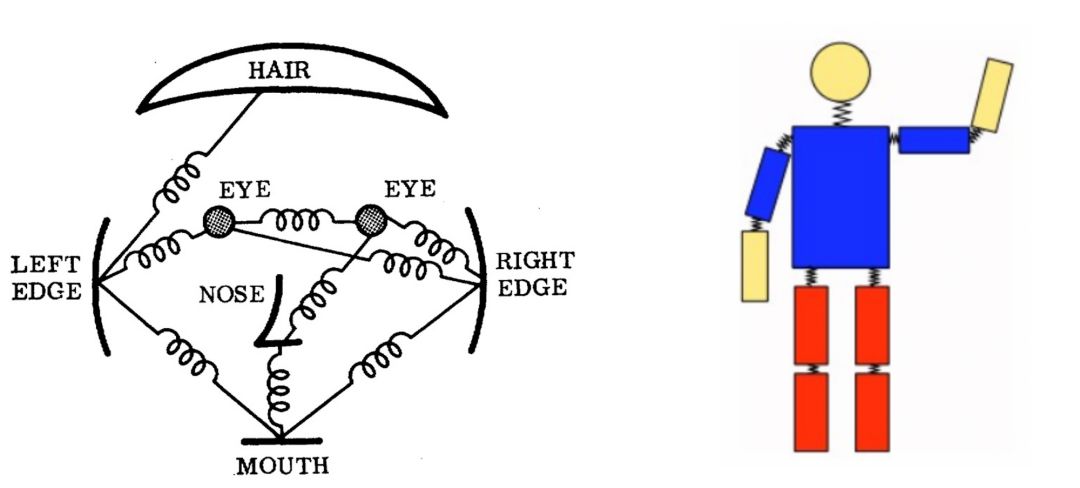
然而,上述方法的局限性在于,姿勢模型并非構建在圖像數據之上。因此,研究者把大部分精力都放在了構建更具表現力的模型上了。
可形變部件模型(Deformable part models)- Yang和Ramanan使用表示復雜關節關系的部件混合模型。可形變部件模型是一個模板集合,這些模板的組合方式是可發生形變的,每個模型都有全局模板+部件模板。這些模板與圖像相匹配用以以識別/檢測對象,這種基于部件的模型可以很好地模擬關節。然而,這是以有限的表現力為代價實現的,并沒有用到全局信息。
基于深度學習的方法
傳統姿態估計方法有其難以克服的局限性,但這一局面因為CNN的出現而被打破。隨著Toshev等人對“DeepPose”的引入,人體姿態估計的研究開始從傳統方法轉向深度學習。
近年來,大多數姿態估計系統(pose estimation systems)都普遍采用ConvNets作為其主構模塊,這在很大程度上取代了手工制作的特征和圖形模板;這種方法相比傳統方法取得了巨大提升。
在下一節中,我將按時間順序總結幾篇論文,這些論文代表了HPE的演進,從google的DeepPose開始(這不是一個詳盡的列表,而是一個個人認為能夠顯示該領域最近進展和會議重要成果的論文合集)。
論文涵蓋
1. DeepPose
2. 使用卷積網絡的高效目標定位(Efficient Object Localization Using Convolutional Networks)
3. 卷積姿態機(Convolutional Pose Machines)
4. 基于誤差反饋的人體姿態估計(Human Pose Estimation with Iterative Error Feedback)
5. 用于人體姿態估計的堆疊式沙漏網絡(Stacked Hourglass Networks for Human Pose Estimation)
6. 人體姿態估計和跟蹤的簡單基線(Simple Baselines for Human Pose Estimation and Tracking)
7. 人體姿態估計的高分辨率深度學習(Deep High-Resolution Representation Learning for Human Pose Estimation)
DeepPose:通過深度神經網絡(CVPR'14)進行人體姿態估計
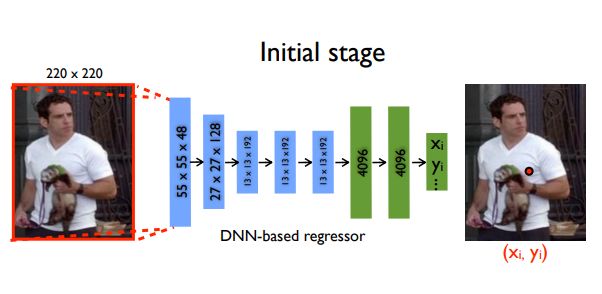
DeepPose是第一篇將深度學習應用于HPE的重要論文。它實現了SOTA(state of the art)性能并擊敗了現有的模型。在這種方法中,姿勢估計被表述為一個基于CNN的身體關節回歸問題。
他們還使用一系列這樣的回歸器來改進姿勢估計并獲得更好的估計結果。這種方法所做的一件重要事情是以整體的方式評估姿勢,也就是說,即使某些關節是隱藏的,如果擺出的姿勢是作為一個整體,也可以對其進行估計。本文認為,CNN很自然地提供了這種推理,并通過結果證明了其強大。
模型
該模型由一個Alexnet后端(7層)和一個額外的最終層組成,這個最終層的輸出為2k關節坐標。(xi,yi)?2fori∈{1,2…k},k為關節數量
使用L2損失對模型進行回歸訓練。
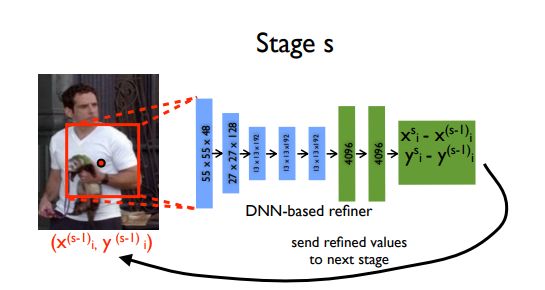
這個模型實現的一個有趣的想法是,使用級聯回歸器(cascaded regressors)對預測進行細化,從而對初始的粗糙預測進行了改進,得到較好的估計。圖像被剪切到預測到的關節周圍,并被送入下一階段,這樣,后續的姿勢回歸器可以看到更高分辨率的圖像,從而學習更細比例的特征,從而最終獲得更高的精度。
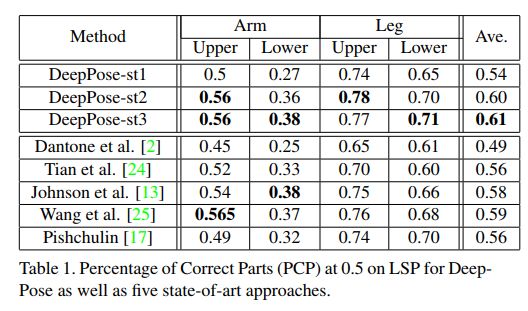
結果
本文使用了LSP(Leeds sports dataset,利茲[2]運動數據集)和FLIC(Frames Labeled In Cinema,電影院標記幀)數據集進行實驗,并以PCP(Percentage of Correct Parts,部件正確率)指標和其他方法進行了比較。查看附錄,可以找到一些主流的評估指標(如PCP&PCK)的定義。
評語
本文將深度學習(CNN)應用于人體姿勢估計(HPE),并在這方面啟發了大量研究。
回歸到XY位置是比較困難的,并且增加了學習復雜性,這削弱了其泛化能力,因此在某些區域表現不佳。
最近的SOTA方法將問題轉化為估算尺寸為W0×H0,{H1,H2,...,Hk} 的K個熱圖(heatmap),其中每個熱圖中Hk表示kth關鍵點的位置置信度(共K個關鍵點)。下一篇論文將重點介紹這一觀點。
使用卷積網絡(CVPR'15)進行有效的目標定位
這種方法通過并行方式對圖像進行多分辨率處理來生成一組熱圖(heatmap),同時在不同的尺度上捕獲特征。輸出的結果是一個離散的熱圖而不是連續回歸。熱圖預測關節在每個像素發生的概率。這個輸出模型是非常成功的,很多后續論文都是預測熱圖而不是直接回歸。
模型
采用多分辨率CNN結構(粗糙熱圖模型)實現滑動窗口探測器,從而產出粗糙熱圖。
本文的主要目的是恢復初始模型中,由于池化而造成的空間精度損失。他們通過使用一個額外的“姿態優化”——ConvNet來實現這一點,ConvNet可以優化粗糙熱圖的定位結果。
但是,與標準的級聯模型不同,它們重用現有的卷積特性。這不僅減少了級聯中可訓練參數的數量,而且由于粗糙模型和精細模型是聯合訓練的,因此可以作為粗熱圖模型的調節器。
從本質上講,該模型包括用于粗定位的基于熱圖的部件模型、用于在每個關節的指定(x,y)位置采樣和裁剪卷積特征的模塊以及用于微調的附加卷積模型。
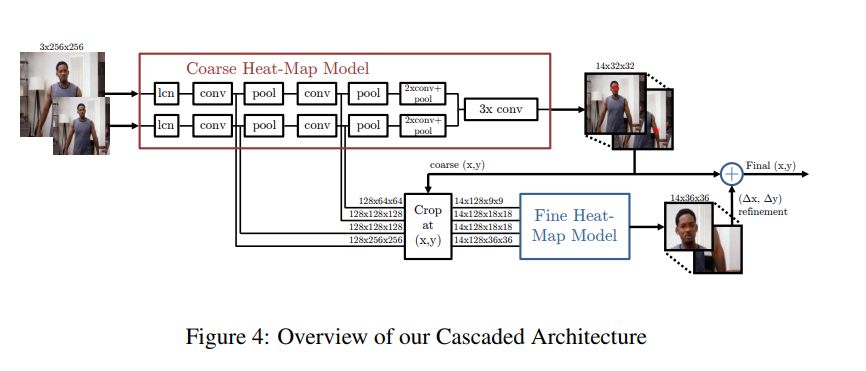
這種方法的一個關鍵特征是聯合使用一個ConvNet和一個圖形模型,圖形模型學習關節之間的典型空間關系。
訓練
該模型通過最小化我們的預測熱圖到目標熱圖的均方誤差(MSE,Mean Squared-Error)距離進行訓練(目標是以標準真值(x,y)關節位置為中心的二維常方差高斯(σ≈1.5像素))。
結果
評論
熱圖比直接關節回歸更有效。
聯合使用CNN和圖形模型(Graphical Model)
然而,這些方法缺乏結構建模。由于受限于身體部位比例、左右對稱性、穿插限制、關節限制(例如肘部不向后彎曲)和物理連接(例如手腕與肘部的精確相關)等約束,二維人體姿勢呈現出高度結構化。對這種結構約束進行建模,應該可以更容易地確定可見的關鍵點,并使咬合處關鍵點估計成為可能。接下來的幾篇論文,他們將用一些新穎方式來解決這個問題。
卷積擺位機(CVPR'16)(Convolutional Pose Machines)
摘要
這是一篇有趣的論文,使用了一種稱為姿態機(Pose Machine)的東西。姿態機由圖像特征計算模塊和預測模塊組成。卷積式姿態機是完全可微分的,其多級結構可以進行端到端的訓練。它們為學習豐富的隱式空間模型提供了一個連續的預測框架,其對人體姿勢的預測效果非常好。
本文的一個主要動機是學習長范圍的空間關系,它們表明,這可以通過使用更大的感受野(receptive fields)來實現。
模型
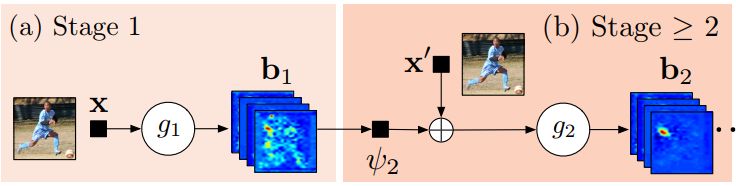
g1()和g2()預測熱圖(即論文中的信念圖(belief maps)),整體架構如上圖所示。Stage1是圖像特征計算模塊,Stage2是預測模塊;下面是一個詳細的架構。
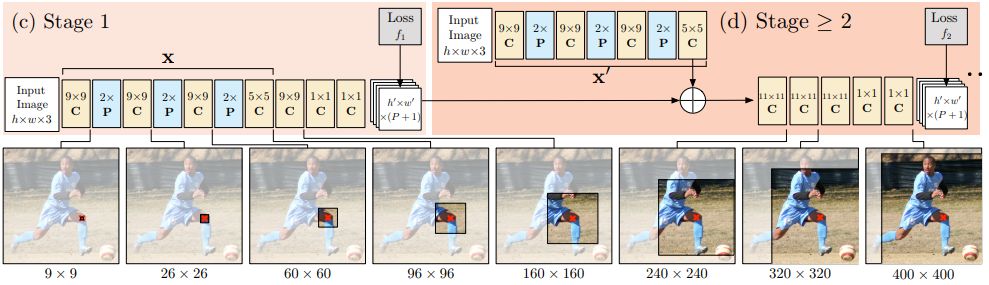
CPM(卷積姿態機)通常包含不止兩個階段,階段數目一般來講都是超參數,通常取3。第一階段是固定的,大于2的階段一般都只是階段2的重復。第2階段將熱圖和圖像證據作為輸入。輸入的熱圖為下一個階段增添了空間背景。(已經在論文中進行了詳細的闡述與討論)
總體來說,CPM通過后續階段來對熱圖進行細化。
論文在每一個階段都會使用中間監督學習,從而來避免梯度消失的問題,這是一個深度多層神經網絡的常見問題。
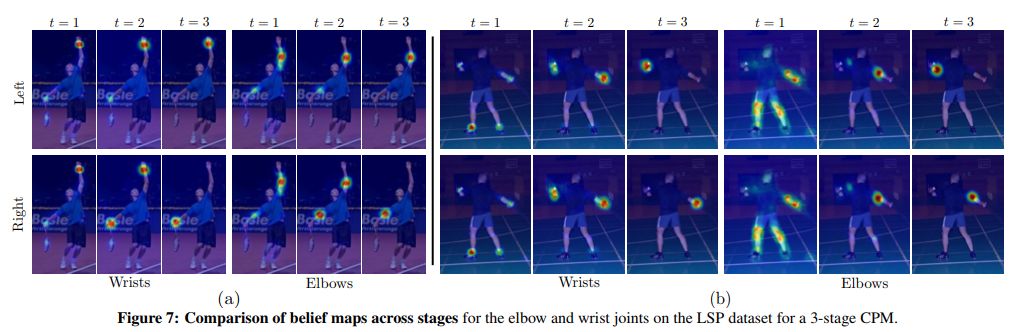
結論/結果
MPII:PCKh-0.5得分達到87.95%的水平狀態,比最接近的競爭者高出6.11%,值得注意的是,在腳踝(最具挑戰性的部分),我們的PCKh@0.5得分是78.28%,這比最接近的競爭對手高出了10.76%。
LSP:模型達到84.32%的水平狀態(添加MPII訓練數據時為90.5%)。
評論
介紹了一種新穎的CPM框架,該框架顯示了MPII,FLIC和LSP數據集的SOTA性能。
基于誤差反饋的人體姿態估計(CVPR’16)
摘要
這是一篇內容豐富并非常復雜的論文,我試圖簡單地總結一下,希望不會遺漏太多。整個工作的思想非常直接:預測當前估計的錯誤并迭代糾正。引用作者的論述,他們不是一次性直接預測輸出,而是使用自校正模型,通過反饋誤差預測逐步改變初始解決方案,這個過程稱為迭代誤差反饋(IEF)。
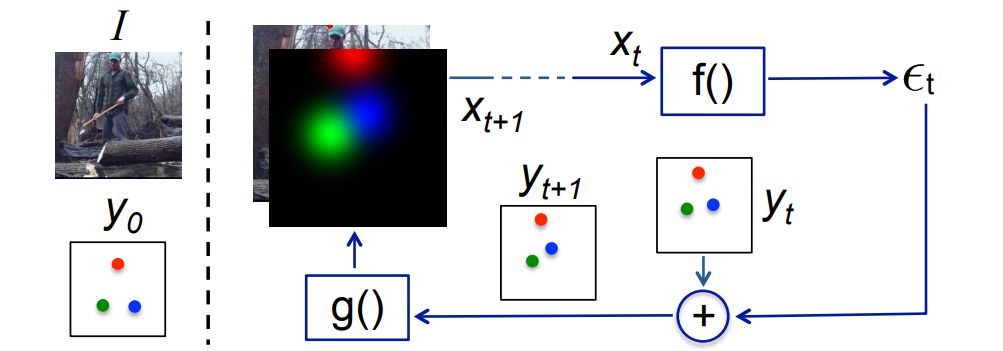
讓我們來看看模型吧。
輸入由圖像I和前一輸出yt?1的表示組成。請記住,這是一個迭代的過程,相同的輸出在不斷地迭代過程中會慢慢地得到改進。
輸入,xt=I⊕g(yt-1) 其中I是圖像,而yt-1是前一個輸出。
f(yt)輸出校正εt,并將其添加到當前輸出yt,以生成yt+1,并且這里面還包含了校正更新的過程。
g(yt+1)中的每個關鍵點yt+1轉換為熱圖通道,以便它們可以堆疊到圖像I中,進而也是為了形成下一個迭代過程的輸入。這個過程重復T次,直到我們得到一個精煉的yt+1,并通過添加εt,進而來更接近標準真值。
在數學上,
?t=f(xt)
yt+1=yt+?t
xt+1=I⊕g(yt+1)
f和g是可學習的,f 是一個CNN。
需要注意的一點是,當ConvNet f() 將I⊕g(t)作為輸入時,它能夠學習關節輸入- 輸出空間的特征,這是非常酷的。
參數 Θg和Θf是通過優化以下等式來學習:
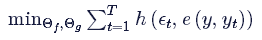
其中,?t和(y,yt)是被預測出來的,并且分別是修正的目標。函數(h)是距離的度量,例如二次損失。T是模型采取的修正步驟的數目。
案例
如你所見,姿勢在校正步驟中得到了改進。
結果
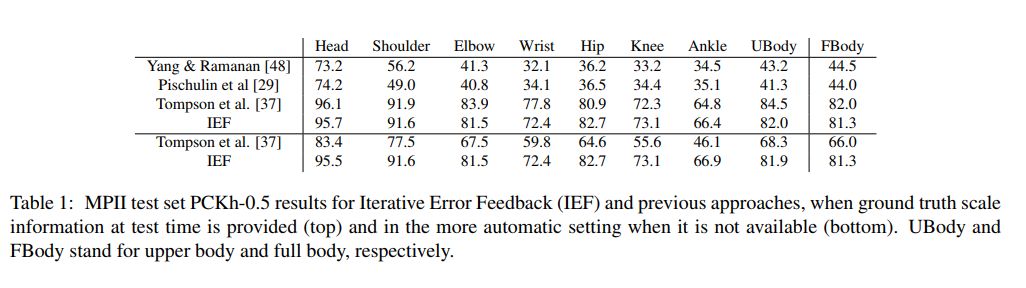
評論
這是一篇非常好的論文,它介紹了一個新穎的算法,并且運作良好。
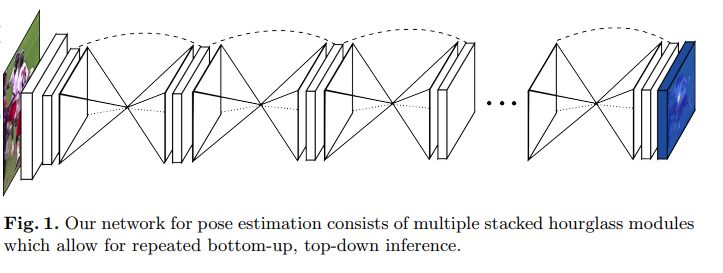
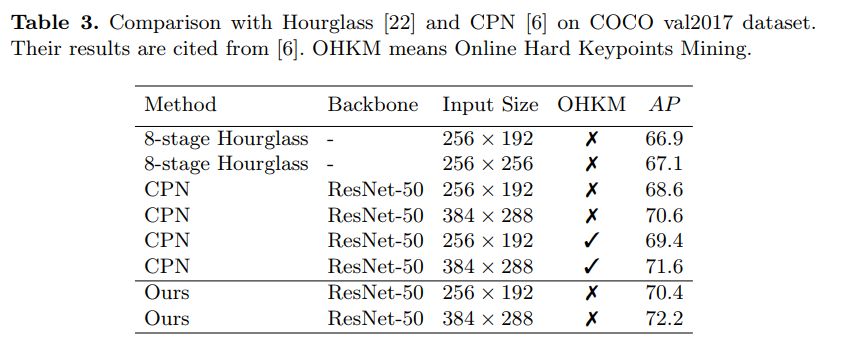
用于人體姿態估計的堆疊式沙漏網絡
這是一篇具有里程碑意義的論文,它引入了一種新穎而直觀的架構,并擊敗了以往的所有方法。它被稱為堆疊式沙漏網絡,因為網絡包括池化和上采樣層的步驟,這些層看起來像沙漏,并且這些被堆疊在一起。沙漏的設計是由于需要捕獲各種規模的信息。
雖然本地證據對于識別面部手等特征至關重要,但最終的姿勢估計需要全局背景。用于識別人的方向,肢體的排列以及相鄰關節的關系等內容的線索,最好是在圖像的不同尺度中尋找(較小的分辨率捕獲更高階的特征和全局背景)。
網絡通過中間監督執行自下而上,自上而下的處理
自下而上處理(從高分辨率到低分辨率)自上而下處理(從低分辨率到高分辨率)
網絡使用skip connection來保留每個分辨率的空間信息,并將其傳遞給上采樣,進一步沿著沙漏進行傳遞。
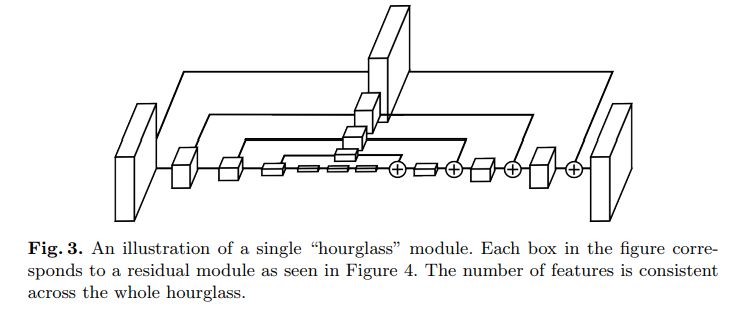
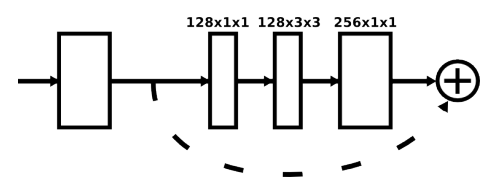
每個盒子都是一個殘留模塊,如下圖所示;
中間監督
中間監督被應用于每個沙漏階段的預測,即監督堆棧中每個沙漏的預測,而不僅僅是最終的沙漏預測。
結果
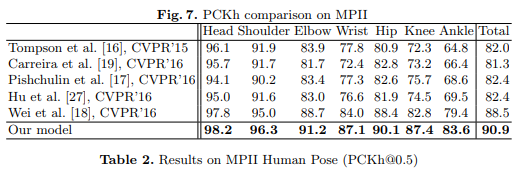
它為什么這么好用呢?
沙漏可以捕獲各種規模的信息。通過這種方式,全局和本地信息都可以被完全捕獲并被網絡用于學習預測。
人體姿勢估計和跟蹤的簡單基線
以前的方法運行的效果很好但是都很復雜。這項工作伴隨著提出來這樣一個問題。為啥不用一個簡單的模型?該模型在COCO上實現了73.7%的mAP創紀錄水平。網絡結構非常簡單,最后由一個ResNet 和幾個反卷積層組成。(可能是估算熱圖的最簡單方法)
雖然沙漏網絡使用上采樣來增加特征圖分辨率并將卷積參數放入其他塊中,但此方法以非常簡單的方式將它們組合為反卷積層。令人驚訝的是,這樣一個簡單的架構比具有skip connections的架構表現更好,并且保留了每個分辨率的信息。
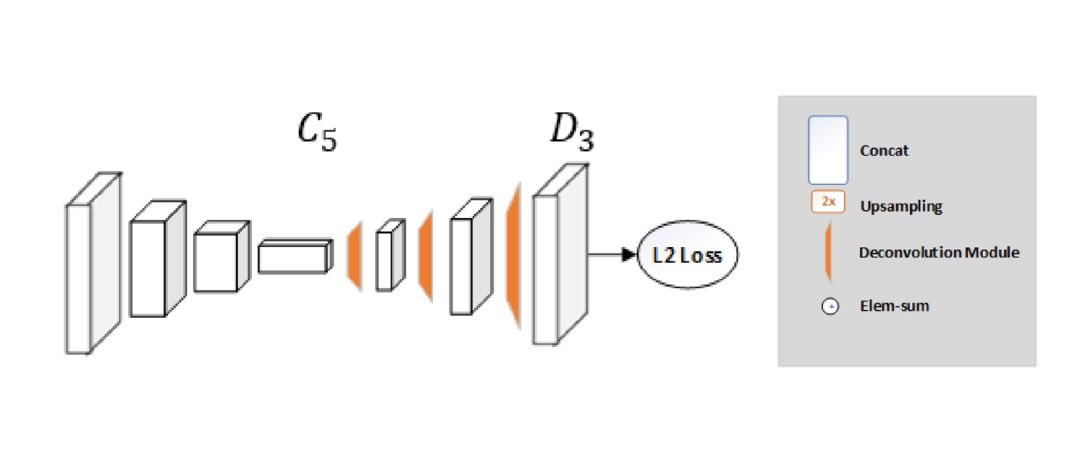
均方誤差(MSE)用作預測的熱圖和目標熱圖之間的損失。關節k的目標熱圖Hk是通過在第k個關節的標準真值位置上以std dev = 1像素為中心應用2D高斯來生成的。
結果
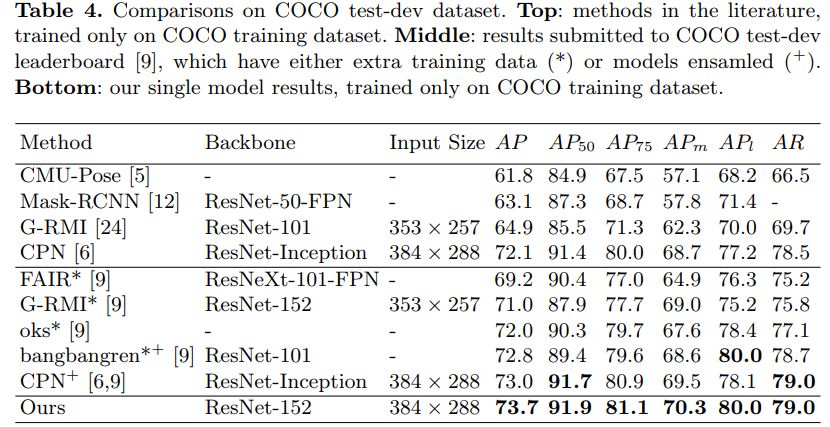
用于人體姿勢估計的深度高分辨率表示學習[HRNet] (CVPR’19)
HRNet(高分辨率網絡)模型在COCO數據集中的關鍵點檢測,多人姿態估計和姿態估計等任務上的表現均優于現有方法,它是最新的。
HRNet遵循一個非常簡單的想法。以前的大多數論文都來自高→低→高分辨率表示。HRNet 在整個過程中都保持高分辨率的表示,并且這非常有效。
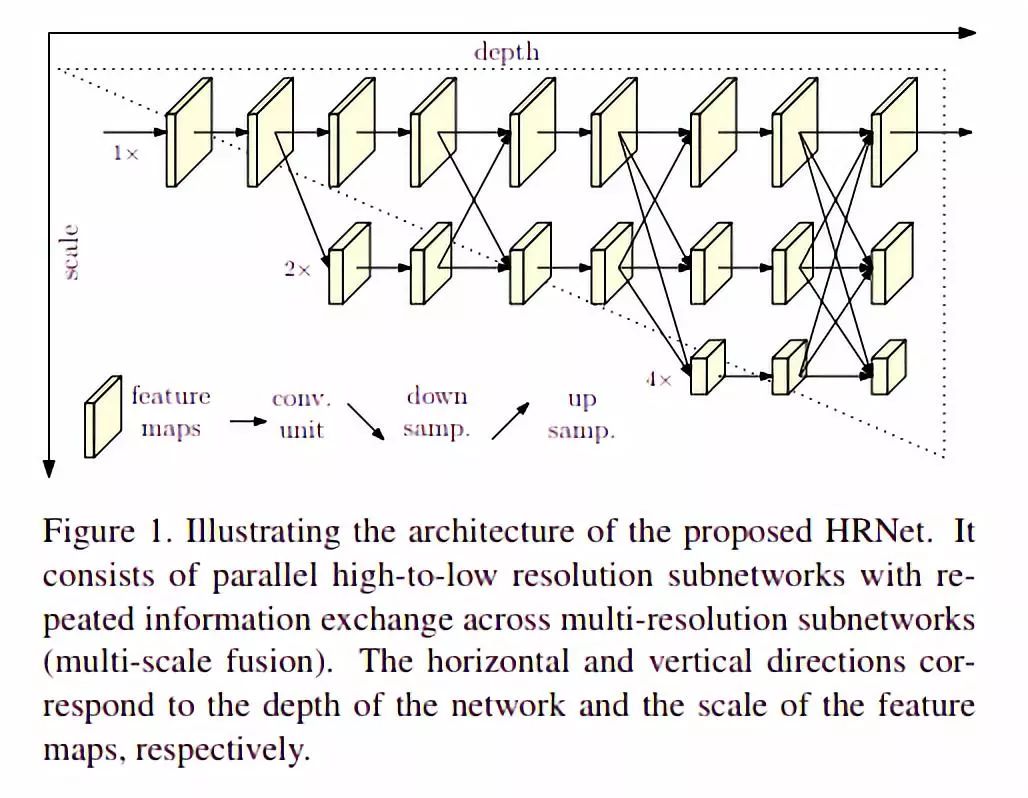
該架構從作為第一階段的高分辨率子網開始,逐步逐個添加高到低分辨率的子網,以形成更多的階段并連接并行的多分辨率子網。
通過在整個過程中反復進行跨越多分辨率并行子網絡的信息交換來實現多尺度融合。
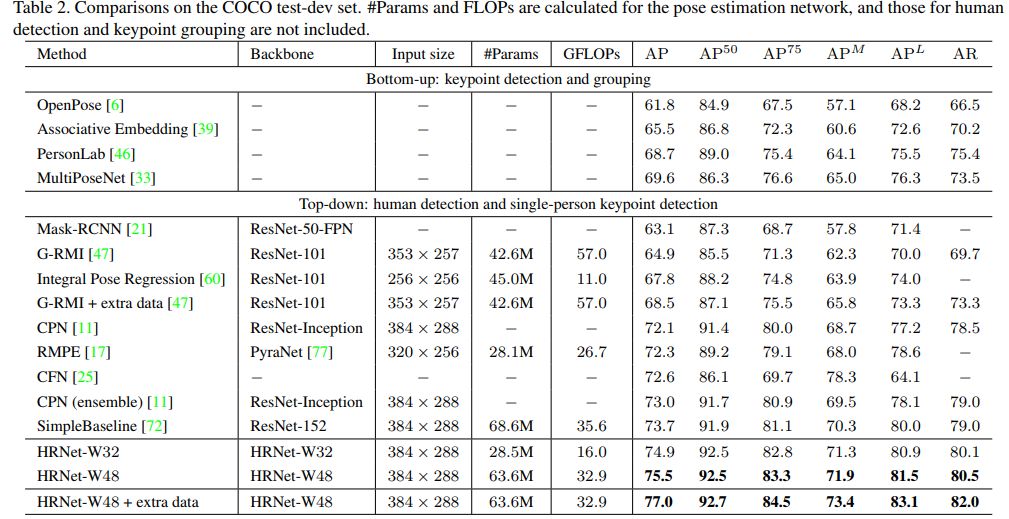
另一些專業人士認為,與堆疊式沙漏不同,這種架構不使用中間熱圖監督學習。
使用MSE損失對熱圖進行回歸復原,類似于簡單的基線。
結果
以下是其他一些我認為也非常有趣的論文:
Flowing ConvNets for Human Pose Estimation in Videos (ICCV’15)[arXiv]
Learning Feature Pyramids for Human Pose Estimation (ICCV’17) [arXiv][code]
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (CVPR’17)[arXiv][code]: Very popular real-time multi-person pose estimator (Better known as OpenPose)
Multi-Context Attention for Human Pose Estimation (CVPR’17)[arXiv][code]
Cascaded Pyramid Network for Multi-Person Pose Estimation (CVPR’18)[arXiv][code]
附錄
通用評估指標
需要評估指標來衡量人體姿勢估計模型的性能。
正確部件的百分比 - PCP:如果兩個預測的關節位置與真實肢體關節位置之間的距離小于肢體長度的一半(通常表示為PCP@0.5),則認為肢體被檢測到(正確的部分)。
它測量肢體的檢出率。結果是,由于較短的肢體具有較小的閾值,因此它會對較短的肢體進行懲罰。
PCP(正確部件的百分比)越高,模型越好。
正確關鍵點的百分比 - PCK:如果預測關節與真實關節之間的距離在特定閾值內,則檢測到的關節被認為是正確的。閾值可以是:
PCKh@0.5表示閾值=頭骨鏈接的50%時
PCK@0.2 ==預測和真實關節之間的距離<0.2 *軀干直徑
有時將150 mm作為閾值。
緩解較短的肢體問題,因為較短的肢體具有較小的軀干和頭骨連接。
PCK通常被用于2D和3D(PCK3D)。再次強調聲明,越高越好。
檢測到的關節的百分比 - PDJ:如果預測關節和真實關節之間的距離在軀干直徑的某一部分內,則檢測到的關節被認為是正確的。PDJ@0.2 =預測和真實關節之間的距離<0.2 *軀干直徑。
基于對象關鍵點相似度(OKS)的mAP:
常用于COCO關鍵點的挑戰。
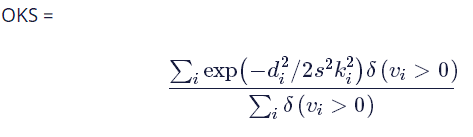
其中di是檢測到的關鍵點與相應的標準真值之間的歐幾里德距離,vi是標準真值的可見性標志,s是對象尺度,ki控制衰減的每個關鍵點常量。
簡而言之,OKS扮演的角色與IoU在對象檢測中扮演的角色相同。它是根據人的尺度標準化的預測點和標準真值點之間的距離計算出來的。更多詳細信息,以及標準平均精度和召回分數在論文中皆有報告:A P50(AP at OKS = 0.50) A P75, A P(the mean of A Pscores at 10 positions, OKS = 0.50, 0.55, . . . , 0.90, 0.95; A PMfor medium objects,A PMfor large objects, andA R(Average recall) at OKS = 0.50, 0.55, . . . , 0.90, 0.955。
-
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999
原文標題:從DeepNet到HRNet,這有一份深度學習“人體姿勢估計”全指南
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
求一份verilog HDL的視頻教程
基于遺傳優化的自適應凸松弛人體姿勢估計
2019一份機器學習和深度學習的最佳書單
一份深度學習的學習筆記資料合集

基于深度學習的二維人體姿態估計方法

基于深度學習的二維人體姿態估計算法


AI深度相機-人體姿態估計應用






 工商網監
工商網監
評論