 魚與熊掌:Bert應用模式比較與選擇
魚與熊掌:Bert應用模式比較與選擇
最近兩個月,我比較關注Bert的領域應用現狀,以及Bert存在哪些問題及對應的解決方案。于是,收集了不少相關論文,正在梳理這兩個問題,并形成了兩篇文章。這部分內容本來是第一篇“應用篇”的一部分,后來發現文章實在太長,于是從介紹Bert領域應用現狀的文章中剝離出來。本部分涉及具體技術較少,比較務虛,所以單獨抽出來了,主題也比較散。所講純屬個人思考,眼光有限,錯誤難免,謹慎參考。
魚與熊掌:Bert應用模式比較與選擇
我們知道,ELMO/GPT/Bert這幾個自然語言預訓練模型給NLP帶來了方向性的指引,一般在應用這些預訓練模型的時候,采取兩階段策略:首先是利用通用語言模型任務,采用自監督學習方法,選擇某個具體的特征抽取器來學習預訓練模型;第二個階段,則針對手頭的具體監督學習任務,采取特征集成或者Fine-tuning的應用模式,表達清楚自己到底想要Bert干什么,然后就可以高效地解決手頭的問題和任務了。
關于Bert大的應用框架如此,但是,其實有幾個懸而未決的應用模式問題并沒有探討清楚,比如以下兩個問題,它們的答案是什么?首先搞清楚這些問題其實是很重要的,因為這對于后續的Bert領域應用起到了明確的指導作用。哪兩個問題呢?
問題一:下游任務在利用預訓練模型的時候,有兩種可能的選擇:特征集成(Feature Ensemble)或者微調(Fine-tuning)模式。那么對于Bert應用來說,這兩種模式,到底哪種應用效果更好呢?還是說兩者效果其實差不多?這是一個問題,這個問題如果有明確答案,那么在做應用的時候,可以直接選擇那個較好的方案。
我們知道,ELMO在下游任務使用預訓練模型的時候,采用的是特征集成的方式:就是說把當前要判斷的輸入句子,走一遍ELMO預訓練好的的雙層雙向LSTM網絡,然后把每個輸入單詞對應位置的高層LSTM激活embedding(或者輸入單詞對應位置的若干層embedding進行加權求和),作為下游任務單詞對應的輸入。這是一種典型的應用預訓練模型的方法,更側重于單詞的上下文特征表達方面。
GPT和Bert則采取了另外一種應用模式:Fine-tuning。意思是:在獲得了預訓練模型以及對應的網絡結構(Transformer)后,第二個階段仍然采用與預訓練過程相同的網絡結構,拿出手頭任務的部分訓練數據,直接在這個網絡上進行模型訓練,以針對性地修正預訓練階段獲得的網絡參數,一般這個階段被稱為Fine-tuning。這是另外一種典型的應用模式。
當然,在實際應用的時候,只要有了預訓練模型,應用模式是可選的。其實ELMO也可以改造成Fine-tuning的模式,GPT和Bert同樣也可以改造成特征集成的應用模式。 那么,這兩種應用模式對應用來說,有效果方面的差異嗎?
有篇論文專門探討了這個問題,論文的名字是:“To Tune or Not to Tune? Adapting Pre-trained Representations to Diverse Tasks”,這篇論文還是挺有意思的,有時間的同學可以仔細看看。
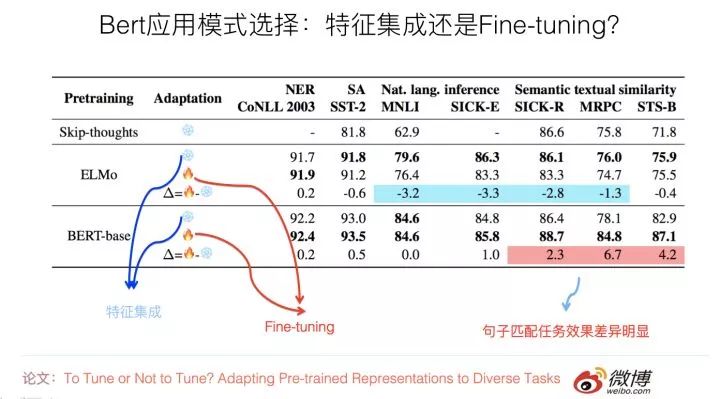
它的目的是對比ELMO和Bert的上述兩種應用模式的差異,希望得出到底哪種模式更適合下游任務的結論。它使用了7種不同的NLP任務來評估,如果歸納一下實驗結果(參考上圖),可以看出這個問題的結論如下:
對于ELMO來說,特征集成的應用方式,在不同數據集合下,效果穩定地優于Fine-tuning;而Bert的結論正好相反,Fine-tuning應用模式的效果,在大部分任務中與特征集成模式效果相當或者稍好些,但是對于sentence pair句子對匹配類的任務,則Fine-tuning效果明顯好于特征集成的方式。這可能是因為Bert在預訓練的過程中包含Next Sentence Prediction任務,考慮到了句間關系問題,所以和下游的sentence pair任務比較匹配導致的。
另外還有一個證據。清華大學最近有篇論文(Understanding the Behaviors of BERT in Ranking),盡管它的主題不是專門探討上述問題的,但是有組相關的實驗,也能在一定程度上說明問題,所以我把那篇論文的結論也列在這里。
它的結論是:對于比如QA這種句子匹配類問題,如果僅僅把Bert作為特征表達工具,也就是說,Bert的輸入側只是單獨輸入Question或者單獨輸入Passage,取出Bert高層的[CLS]標記作為Question或者Passage的語義表示;這種應用方式,效果遠不如在Bert端同時輸入Question和Passage,意思是讓Transformer自己去做Question和Passage的匹配過程,應用效果會更好,而且兩者效果相差甚遠。這從側面說明了:在QA任務中,Fine-tuning模式效果是要遠好于特征集成模式的。
這在一定程度上說明了:起碼對于句子匹配類任務,Fine-tuning這種應用模式效果是要遠好于特征集成那種特征表示應用模式的。當然,因為沒有看到更多的工作來對兩種模式做對比,所以謹慎的做法是:僅僅把這個結論限制在句子對匹配任務上,其它非句子對匹配任務目前并沒有特別明確的結論,這塊值得通過更多實驗繼續深入摸索一下。
Bert的原始論文,也簡單對比了下兩種模式,我印象是Fine-tuning模式要略優于特征集成模式。
綜合上述三個工作,我覺得目前可以得出的結論是:對于句子匹配類任務,或者說是輸入由多個不同組成部分構成的NLP任務,那么在應用Bert的時候,采用Fine-tuning效果是要明顯好于特征集成模式的。所以遇到這種類型的任務,你不用猶豫,直接上Fine-tuning沒有大錯。而對于其它類型的任務,在應用Bert的時候,Fine-tuning模式要稍好于特征集成模式,或者兩者效果差不多。
再簡練點的話,結論是:對于Bert應用,安全穩妥的做法是,建議采取Fine-tuning的模式,而不是特征集成的模式。
問題二:假設我們選定了Fine-tuning的應用模式,在標準的Bert的Fine-tuning過程或應用中的推斷過程中,一般而言,分類層的輸入信息來自于Bert的Transformer特征抽取器的最高層輸出。我們知道,Transformer Base版本是有12層的,一種直觀感覺有意義的想法是:也許不僅僅最高層的Transformer包含有效的分類特征信息,底下的11層Transformer中間層,可能編碼了輸入句子的不同抽象粒度的特征信息。
那么,如果我們在分類前,通過一定方式把每個單詞對應的Transformer的多層中間層的響應值集成起來,在這個集成好的特征基礎上,上接分類層,從直覺上感覺應該是有效的,因為感覺好像融入多層特征后,信息更豐富一些。
那么事實到底如何呢?這種集成多層特征的模式,與只使用Transformer最高層特征的使用模式,到底哪個效果更好呢?這個問題其實也挺有意思。
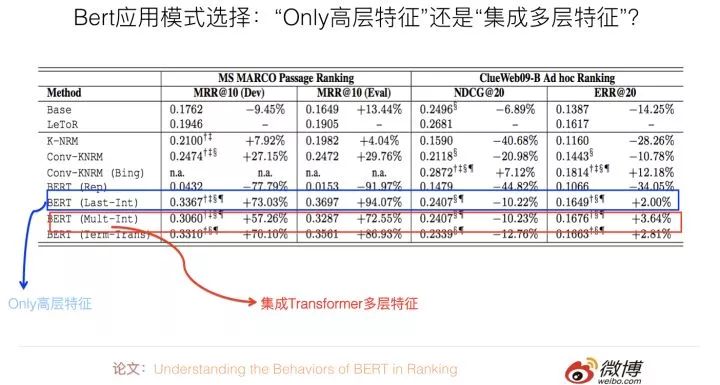
清華大學那篇論文:Understanding the Behaviors of BERT in Ranking。其實主要可以用來回答上面這個問題。它在分類層之前,采用了幾種不同的特征集成方式,并對比了在QA任務上的性能差異。如果進行歸納,結論如下:直接使用Bert輸入的第一個起始標記[CLS]對應位置的最高層Transformer的Embedding作為分類層的輸入,以此作為文本匹配特征表示,既簡潔效果又最好。
其它的幾個對比方案,包括集成最高層Transformer各個單詞的embedding,或者集成不同層Transformer的響應值,或者更復雜的方案,效果是不如這種最簡單的方案的(參考上圖,一個數據集合中Only高層特征明顯占優,另外一個兩者效果相近)。我覺得,這說明了:對于句子對匹配任務,這個[CLS]標記已經編碼了足夠多的句子匹配所需要的特征信息,所以不再需要額外的特征進行補充。
當然,上述實驗結果的結論,還僅僅局限在QA任務上,我估計頂多能擴充到句子對匹配類任務上。至于NLP其它類型任務,比如單句分類或者序列標注任務,還需要額外的證據說明或進行比較分析。
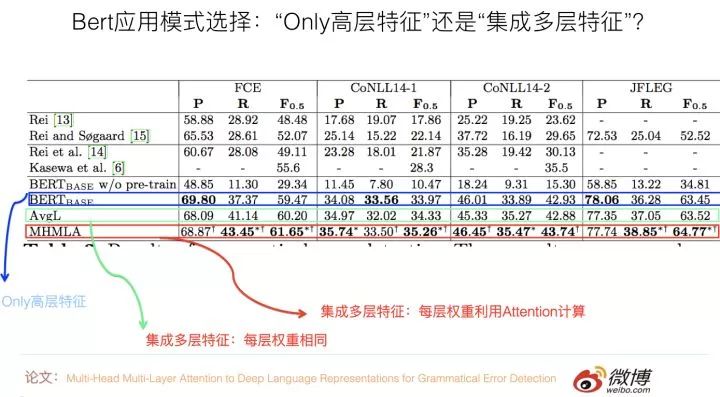
關于序列標注任務,有篇論文:“Multi-Head Multi-Layer Attention to Deep Language Representations for Grammatical Error Detection”是用來驗證這兩種模式不同效果的,它做的是語法錯誤檢測任務,這是一種序列標注任務,也就是說,每個輸入單詞都需要對應一個分類結果輸出。
它提出了的實驗結果證明了:在這個任務中,與只使用最高層特征模式相比,集成多層特征的具體方式對效果有影響,如果在集成各層特征的時候,把每層特征的重要性看作是相同的(取均值),那么效果跟只使用最高層特征比,不同數據集合下效果有好有壞,總體看差不太多或者稍微好點。
如果加入Attention來自適應的學習每層特征的權重,那么效果穩定地好于只使用高層特征的模式。這說明:在序列標注任務中,傾向于選擇多層特征融合的應用模式。
我們去年在用Bert改進微博打標簽(文本分類任務)應用的時候,也嘗試過集成不同層的embedding特征,當時測試對于應用效果的F1數值有大約不到2個百分點的提升(相對僅使用Bert最高層特征的方法)。不過除此外,我還沒看到有其它發表工作說明這個問題。
所以,我覺得關于這個問題,目前的結論貌似可以這樣下:對于句子匹配等多輸入的NLP任務,直接使用Bert高層的[CLS]標記作為輸出的信息基礎,這是效果最好的,也是最簡單的模式。對于序列標注類任務,可能多層特征融合更適合應用場景,但是在融合各層特征時,要做細致些。
對于單句分類等其它任務,因為沒有更多的工作或者實驗來說明這個問題,所以尚未能下明確的結論,這塊還需要后續更多的驗證工作。我的預感是,這可能跟任務類型有關,不同類型的任務可能結論不太一樣,背后可能有更深層的原因在起作用。
困境與希望:Bert到底給NLP領域帶來了什么
毫無疑問,Bert是NLP領域的極為重大的技術進展,在我看來,Bert的重要性,很可能比把深度學習引入NLP領域這種研究模式轉換的進展重要性都要高,因為DL剛引進NLP的時候,說實話,效果跟傳統模型相比,并沒有體現出明顯優勢。但是Bert的效果之好,出人意料,它完全可以跟CV領域以Resnet為代表的Skip Connection相比,屬于深度學習在兩個不同領域的熠熠奪目雙子星。
盡管后面才會提,但是這里可以一句話歸納一下:從NLP各個領域的應用效果可以看出,在使用了Bert后,在很多領域,指標一般都有不同幅度的增長,不同領域情況不同,不少領域有大幅度地增長,很多領域有30%甚至100%的提升。
這些事實擺在我們面前,按理說,這說明Bert的技術突破給NLP研究與應用帶來了很大希望,同時指明了發展方向:就是通過預訓練的模式,充分使用大量的無標注語言數據,利用自監督模型,發揮Transformer特征吸收能力強的特點,來對語言知識進行特征編碼。用這些知識來促進很多下游NLP任務的效果,以彌補有監督任務往往訓練數據規模不夠大,無法充分編碼語言知識的困境。
既然前途如此光明,那么我們完全可以只講希望與方向,對于所謂的“困境”,貌似沒什么可談的。其實不然,世間事都是人做出來的,如果我們的思考對象是身處其中的研發人員,則對于很多局中人,有著顯而易見的困境或者說是困擾。這體現了另外一種理想和現實的差距。這個距離有多遠?
相信有一定生活閱歷的人都理解,答案是:與天海之間的距離是一樣的,在站在海邊的人眼里,遠看無限近,近看無窮遠。這正像,我們每個人都希望自己能活出“美麗的外表,有趣的靈魂”,但是活著活著,在生活的重力擠壓下,活成了“有趣的外表,美麗的靈魂”,甚至,可能連美麗的靈魂都已蒙塵。
最近感概有點多,說遠了,跑回來。
那么,對于很多局中人,Bert的出現帶來的困擾是什么呢?
現在很多證據表明:直接簡單應用Bert,往往就會對很多任務的指標有大幅度地提升。在Bert出來之前,我相信有很多人,在絞盡腦汁地嘗試著各種不同的NLP改進方法,也許思路各異,但是能夠像Bert這樣直接對應用有這么高幅度提升的方法,我相信這種方法應該基本沒有。否則,現在大家看到的,除了Bert外,應該有另外一個“模型震驚部”推出的新模型,但是骨感的現實是,并沒有,所以我這個假設看上去并沒什么大毛病。
順著這個假設推理下去,這又說明什么呢?說明了有大量懷胎十月哇哇墜地甚至還剛受孕的NLP論文,因為Bert的出現,它們已經沒有出生的必要了。“從來只見新人笑,有誰記得舊人哭”。剛看到Bert論文的時候,我的耳邊仿佛傳來很多無奈的苦笑聲,而這笑聲,應該來自于這些技術創新的發明者。
從另外一個角度考慮,Bert的出現,快速拉高了很多NLP應用領域的Benchmark或者對比baseline,所以會引發一個對很多NLP領域研究者,尤其是憋論文的研究生的一個現實的問題。什么問題?就是在一夜之間大幅提升的基線方法高壓下,如果不在Bert的基礎上進行方法創新,那么提出一種效果要好于Bert效果的新方法,概率是非常低的。這意味著有了Bert后,創新難度大大增加了,這對于應用人員沒什么,對于有創新要求的人來說,門檻變高了。
你會反問:為什么將Bert作為對比參照系,原先的方法就失靈了呢?我可以在Bert基礎上,再套用我原先想的辦法來創新嗎不是?當然,不排除有些點子具備不管風吹浪打,我自閑庭信步的成功可能性,但是對于絕大多數方法,我相信這條路是走不通的。為什么?因為很可能你憋了半年的那個方法產生的一點收益,已經被Bert自身帶來的收益覆蓋或者吃掉了。
意思是說,如果沒有Bert,你的改進可能看著還算有些效果,但是你想疊加到Bert上,既想吃到Bert帶來的技術紅利,又能體現你方法的優點,這個良好愿望,實現的概率,是很低的。如果你還這么樂觀地想這個問題,那么,我覺得你該定個鬧鐘早點叫醒自己了。看到這,你體會到我上面說的理想和現實的距離問題了嗎?
不過話說回來,創新難度增加,看你怎么看這個問題了。其實從領域長遠發展來看,是有好處的。好處是:也不局限于NLP領域,大多數AI領域的98%以上的所謂創新,如果把眼光放長遠,是沒有太大價值的。怎么判斷?再過幾年不會被人提起的創新,都屬于這種。
如果這個假設成立,那么Bert的出現,會逼迫從業者不要浪費時間在這些沒有什么長遠領域價值的點子上,而逼迫你去解決那些真正有價值的問題。沒有Bert的時候,只能靠自覺或者研究品味來做到這一點,有了Bert,你就不能不這么做了。從這點講,出現突破模型,對于領域人力資源的投入優化配置,是具有非常積極的作用的。所以很多事情,看你是站在什么角度去看的,不同的角度,可能得出相反的結論。
不過,我想,除了上面觀察角度各異結論會不同的判斷外,Bert確實可能存在一個壞處:很多非常新的想法,在剛提出來的時候,效果可能并不能達到類似Bert這種碾壓效果,甚至效果不太明顯,需要后面有個靈機一動的改進,讓它的效果發揮出來。但是面臨Bert的高基線,很可能很多具備高潛力的點子,根本發表不出來。意味著Bert這堵高墻,可能遮蔽了很多低垂灌木的陽光,使得它們還沒長大就夭折了。這是Bert可能帶來的負面效果。
另外一個容易讓人感到無奈的事實是:Bert的出現預示著,使用Transformer這種重模型,利用幾乎無窮多的自然語言文本資源進行自監督訓練,這條路看樣子是能走通的,而這是一條通向NLP之峰的陽關大道。但是復雜模型加上超量數據,也預示著要想沿著這條路線繼續往后走,在預訓練階段,對機器資源的消耗非常之大,這種金錢游戲,不是你我這種NLP屆的窮人們玩的起的。
這就像什么呢?打個比方,漫威電影里的超級英雄們,各個身手非凡,但是如果追究下他們超能力的來源問題,就上升到階級問題了,所謂“富人靠科技,窮人靠變異”,這句力透屏幕的扎心總結,透著濃濃的馬克思主義的氣息。換成Bert時代,那就是 “富人靠機器,窮人靠運氣”。各位還請檢查下銀行卡余額,對號入座。
不過話說回來,有些事,接受事實就好,不要想太多,想太多,除了苦惱,什么也得不到。雖說世事本多無奈,但我們要永保赤子之心,畢竟無奈著無奈著……..慢慢你也就習慣了……..
路在何方:Bert時代的可能NLP創新路徑
上面既然談到了可能的困境與希望,不妨再進一步深入思考一下:對于有創新要求的局中人,在Bert時代,未來可以選擇怎樣的創新路徑呢?這個問題其實還是很重要的。
以我的私見,將來能走的路有幾條,各自難度不同,我來列一列,你可以衡量看看你打算怎么走。再次強調,純屬個人意見,謹慎參考。
第一條路是條康莊大道。就是說,在完全不依賴Bert的基礎上,提出一個與Bert效果相當或者更好的新模型或新方法。這絕對是條金光閃閃的正路,但是,走通的概率有多大你自己自我評估一下。當然,私心里,我本人是特別贊成沒有各種短期壓力,無論是創新成果壓力還是經濟壓力,的同志走這條路的。也對能選擇走上這條路的同志表示敬意,能選這條路是非常不容易的,而且我相信,一定會有人會堅定不移地選擇這條路。
這條路拼的是對領域的認識深刻程度,速度不關鍵。
第二條路,不考慮模型創新,可以利用Bert預訓練模型,直接去做各種應用,以實證Bert在各種領域是有效果的。當然,在應用Bert的時候,也可能適應領域應用特點,做出些模型的改動,但是無疑這種改進不會大。這是一條相對好走的路,好走的路走的人自然就會多,所以這條路拼的是誰的速度快。目前大量Bert的后續工作屬于這一種,這很正常。后面應用篇文章總結的也是這一類的工作。
第三條路,通過各種偏實驗性的研究,以更深入地了解Bert的特性,其實我們目前并沒有對Bert及Transformer有很深刻的了解,而我們目前也非常急迫地需要做到這一點。如果我們能夠對它們加深了解,這也是非常有價值的,因為對Bert進一步做較大的改進,改起來會更有針對性。而且只有了解了Bert的本質特性,才有可能拋開Bert,提出更好的全新的模型。這條路其實也不算難走,但是做的人感覺不太多。我倒是建議有心的同學多想想這條路。
第四條路,直接改進Bert模型。針對Bert目前還做得不太好的地方,改進優化它,或者改造使得它能夠適用更廣的應用范圍。這條路是比較務實且有可能作出比較重要創新的一條路。目前很多Bert后續工作也集中在這里。這里的創新難度要求方差較大,有些會比較常規,有些問題則需要巧思。目前這塊的工作也相對多,后面“Bert改進篇”文章主要集中在這塊。
第五條路,想出那些在Bert基礎之上,又看上去與Bert無關的改進,期待新技術疊加到Bert上去之后,新方法仍然有效。就是說它的技術紅利點和Bert的技術紅利點不重合,那么可以產生累計疊加紅利,這也是一條較好的路,應該也能走得通,當然肯定也不太好走。
第六條路,找Bert做不好的任務或應用領域,就是說Bert的優點在這個領域里發揮不出來,既然Bert沒法侵入該領域,所以對于常規的技術創新并沒有什么阻礙或影響。如果選擇這條路,你的首要任務是找出這些領域。而且,在這些領域里面,參考Bert的基本思想,是很有可能引入大的改進模型的。
還有其它可能走的路嗎?貌似不多了吧。好了,上面的路有好走的,也有荊棘密布的,您可以在上面的可能options中選一條,然后堅定地走下去。祝好運。
-
應用
+關注
關注
2文章
438瀏覽量
34138 -
編碼
+關注
關注
6文章
935瀏覽量
54765 -
訓練模型
+關注
關注
1文章
35瀏覽量
3802
原文標題:Bert時代的創新:Bert應用模式比較及其它 | 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
vmware11/12 openSUSE 不能進入unity模式???
J-BERT N4903A高性能串行BERT手冊
回收M8040A 64 Gbaud 高性能 BERT
BERT模型的PyTorch實現
電壓模式與電流模式的比較

華為MateX解析 魚與熊掌可兼得
XLNet vs BERT,對比得明明白白!
BERT的自注意力模式
圖解BERT預訓練模型!
什么是BERT?為何選擇BERT?
總結FasterTransformer Encoder(BERT)的cuda相關優化技巧





 工商網監
工商網監
評論