") 從YOLO v1開始講起,直至目前最新的版本YOLO v3
從YOLO v1開始講起,直至目前最新的版本YOLO v3
導(dǎo)語:如今基于深度學(xué)習(xí)的目標(biāo)檢測已經(jīng)逐漸成為自動駕駛、視頻監(jiān)控、機(jī)械加工、智能機(jī)器人等領(lǐng)域的核心技術(shù),而現(xiàn)存的大多數(shù)精度高的目標(biāo)檢測算法,速度較慢,無法適應(yīng)工業(yè)界對于目標(biāo)檢測實(shí)時性的需求,這時 YOLO 算法橫空出世,以近乎極致的速度和出色的準(zhǔn)確度贏得了大家的一致好評。基于此,我們選擇 YOLO 算法來實(shí)現(xiàn)目標(biāo)檢測。YOLO 算法目前已經(jīng)經(jīng)過了 3 個版本的迭代,在速度和精確度上獲得了巨大的提升,我們將從 YOLO v1 開始講起,直至目前最新的版本 YOLO v3。
1. YOLO V1 一步檢測的開山之作
相對于傳統(tǒng)的分類問題,目標(biāo)檢測顯然更符合現(xiàn)實(shí)需求,因?yàn)橥F(xiàn)實(shí)中不可能在某一個場景只有一個物體,因此目標(biāo)檢測的需求變得更為復(fù)雜,不僅僅要求算法能夠檢驗(yàn)出是什么物體,還需要確定這個物體在圖片哪里。
在這一過程中,目標(biāo)檢測經(jīng)歷了一個高度的符合人類的直覺的過程。既需要識別出目標(biāo)的位置,將圖片劃分成小圖片扔進(jìn)算法中去,當(dāng)算法認(rèn)為某物體在這個小區(qū)域上之時,那么檢測完成。那我們就認(rèn)為這個物體在這個小圖片上了。而這個思路,正是比較早期的目標(biāo)檢測思路,比如 R-CNN。
后來的 Fast R-CNN,F(xiàn)aster R-CNN[16] 雖有改進(jìn),比如不再是將圖片一塊塊的傳進(jìn) CNN 提取特征,而是整體放進(jìn) CNN 提取特征圖后,再做進(jìn)一步處理,但依舊是整體流程分為區(qū)域提取和目標(biāo)分類兩部分(two-stage),這樣做的一個特點(diǎn)是雖然確保了精度,但速度非常慢,于是以 YOLO(You only look once)為主要代表的這種一步到位(one-stage)即端到端的目標(biāo)檢測算法應(yīng)運(yùn)而生了。
1.1 YOLO v1 基本思想
YOLO v1 的核心思想在于將目標(biāo)檢測作為回歸問題解決 ,YOLO v1 首先會把原始圖片放縮到 448×448 的尺寸,放縮到這個尺寸是為了后面整除來的方便。然后將圖片劃分成 SxS 個區(qū)域,注意這個區(qū)域的概念不同于上文提及將圖片劃分成 N 個區(qū)域扔進(jìn)算法的區(qū)域不同。上文提及的區(qū)域是將圖片進(jìn)行剪裁,或者說把圖片的某個局部的像素輸入算法中,而這里的劃分區(qū)域,只的是邏輯上的劃分。
如果一個對象的中心落在某個單元格上,那么這個單元格負(fù)責(zé)預(yù)測這個物體。每個單元格需要預(yù)測 B 個邊界框(bbox)值(bbox 值包括坐標(biāo)和寬高),同時為每個 bbox 值預(yù)測一個置信度(confidence scores)。 此后以每個單元格為單位進(jìn)行預(yù)測分析。
這個置信度并不只是該邊界框是待檢測目標(biāo)的概率,而是該邊界框是待檢測目標(biāo)的概率乘上該邊界框和真實(shí)位置的 IoU(框之間的交集除以并集)的積。通過乘上這個交并比,反映出該邊界框預(yù)測位置的精度。如下式所示:

每個邊界框?qū)?yīng)于 5 個輸出,分別是 x,y,w,h 和置信度。其中 x,y 代表邊界框的中心離開其所在網(wǎng)格單元格邊界的偏移。w,h 代表邊界框真實(shí)寬高相對于整幅圖像的比例。x,y,w,h 這幾個參數(shù)都已經(jīng)被限制到了區(qū)間 [0,1] 上。除此以外,每個單元格還產(chǎn)生 C 個條件概率,。注意,我們不管 B 的大小,每個單元格只產(chǎn)生一組這樣的概率。
圖一:YOLO預(yù)測圖示
在 test 的非極大值抑制階段,對于每個邊界框,按照下式衡量該框是否應(yīng)該予以保留。

這就是每個單元格的個體分類置信度得分(class-specific confidence scores),這即包含了預(yù)測的類別信息,也包含了對 bbox 值的準(zhǔn)確度。 我們可以設(shè)置一個閾值,把低分的 class-specific confidence scores 濾掉,剩下的留給給非極大值抑制,得到最終的標(biāo)定框。
在 PASCAL VOC 進(jìn)行測試時,使用 S=7, B=2。由于共有 20 類,故 C=20。所以,網(wǎng)絡(luò)輸出大小為 7×7×30。
1.2 網(wǎng)絡(luò)模型結(jié)構(gòu)
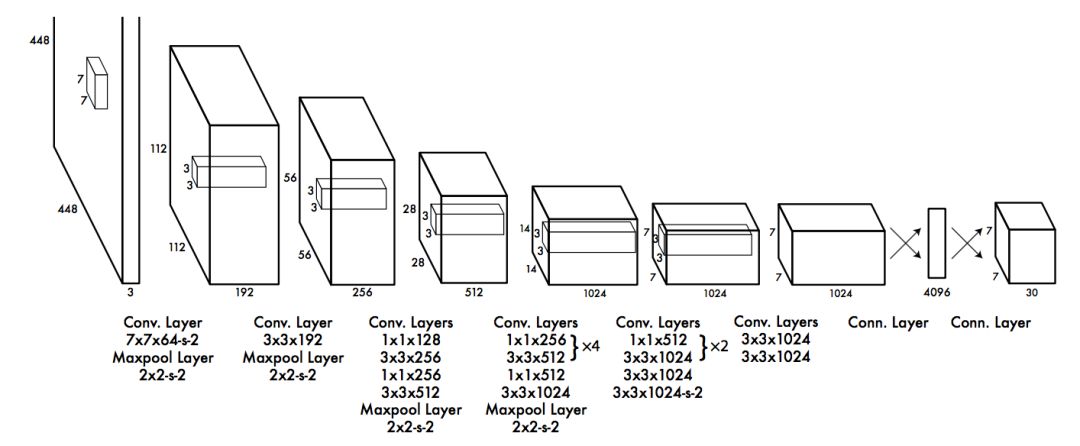
圖二:網(wǎng)絡(luò)框架
該網(wǎng)絡(luò)結(jié)構(gòu)包括 24 個卷積層,最后接 2 個全連接層。Draknet[13] 網(wǎng)絡(luò)借鑒 GoogleNet 的思想,在每個 1x1 的卷積層之后再接一個 3x3 的卷積層的結(jié)構(gòu)替代 GoogleNet 的Inception 結(jié)構(gòu)。論文中還提到了更快版本的 Yolo,只有 9 個卷積層,其他則保持一致。
1.3 損失函數(shù)
YOLO v1 全部使用了均方差(mean squared error)作為損失(loss)函數(shù)。由三部分組成:坐標(biāo)誤差、IOU 誤差和分類誤差。
考慮到每種 loss 的貢獻(xiàn)率,YOLO v1給坐標(biāo)誤差(coordErr)設(shè)置權(quán)重λcoord=5。在計(jì)算 IoU 誤差時,包含物體的格子與不包含物體的格子,二者的 IOU 誤差對網(wǎng)絡(luò) loss 的貢獻(xiàn)值是不同的。若采用相同的權(quán)值,那么不包含物體的格子的置信度值近似為 0,變相放大了包含物體的格子的置信度誤差,在計(jì)算網(wǎng)絡(luò)參數(shù)梯度時的影響。為解決這個問題,YOLO 使用 λnoobj=0.5 修正(置信度誤差)iouErr。(此處的‘包含’是指存在一個物體,它的中心坐標(biāo)落入到格子內(nèi))。
對于相等的誤差值,大物體誤差對檢測的影響應(yīng)小于小物體誤差對檢測的影響。這是因?yàn)椋嗤奈恢闷钫即笪矬w的比例遠(yuǎn)小于同等偏差占小物體的比例。YOLO 將物體大小的信息項(xiàng)(w 和 h)進(jìn)行求平方根來改進(jìn)這個問題,但并不能完全解決這個問題。
綜上,YOLO v1 在訓(xùn)練過程中 Loss 計(jì)算如下式所示:
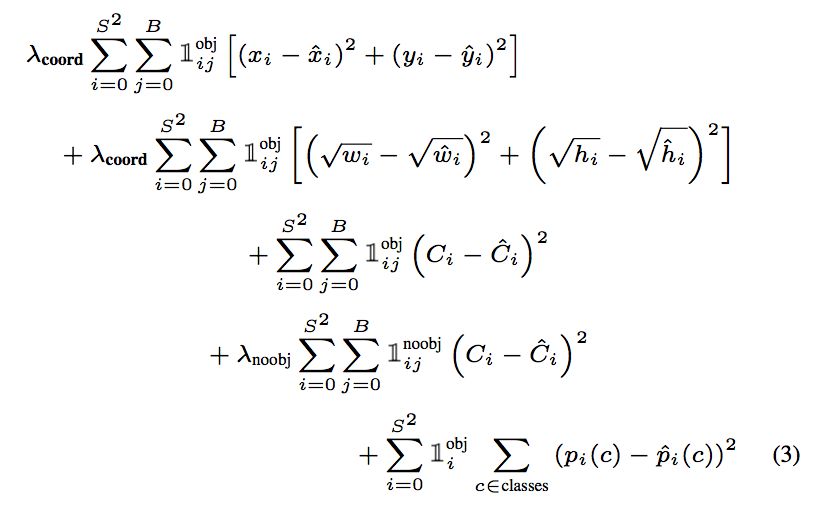
在激活函數(shù)上:
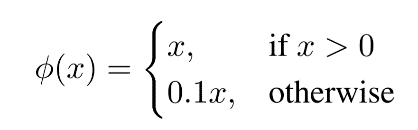
在最后一層使用的是標(biāo)準(zhǔn)的線性激活函數(shù),其他的層都使用 leaky rectified 線性激活函數(shù)。
1.4 總結(jié)
YOLO v1 作為一步檢測的開山之作,最大的特點(diǎn)就是速度快。其將物體檢測作為回歸問題進(jìn)行求解,使用單個網(wǎng)絡(luò)完成整個檢測的方法,大大提升了同類目標(biāo)檢測算法的速度,并且實(shí)現(xiàn)了召回率低,表現(xiàn)為背景誤檢率低的有點(diǎn)。YOLO v1 可以獲取到圖像的整體信息,相比于 region proposal 等方法,有著更廣闊的“視野”。對其種類的物體,訓(xùn)練后識別效果也十分優(yōu)異,具有很強(qiáng)的泛化能力。
但是 YOLO v1 的精準(zhǔn)性和召回率相對于 fast rcnn 比較差。其對背景的誤判率比 Fast RCNN 的誤判率低很多。這說明了 YOLO v1 中把物體檢測的思路轉(zhuǎn)成回歸問題的思路有較好的準(zhǔn)確率,但是對于 bounding box 的定位不是很好。
2.YOLO v2/YOLO9000 更準(zhǔn)、更快、更強(qiáng)
YOLO v1 對于 bounding box 的定位不是很好,在精度上比同類網(wǎng)絡(luò)還有一定的差距,所以 YOLO v2 對于速度和精度做了很大的優(yōu)化,并且吸收了同類網(wǎng)絡(luò)的優(yōu)點(diǎn),一步步做出嘗試。
YOLO v2 在 v1 基礎(chǔ)上做出改進(jìn)后提出。其受到 Faster RCNN 方法的啟發(fā),引入了 anchor。同時使用了 K-Means 方法,對 anchor 數(shù)量進(jìn)行了討論,在精度和速度之間做出折中。并且修改了網(wǎng)絡(luò)結(jié)構(gòu),去掉了全連接層,改成了全卷積結(jié)構(gòu)。在訓(xùn)練時引入了世界樹(WordTree)結(jié)構(gòu),將檢測和分類問題做成了一個統(tǒng)一的框架,并且提出了一種層次性聯(lián)合訓(xùn)練方法,將 ImageNet 分類數(shù)據(jù)集和 COCO 檢測數(shù)據(jù)集同時對模型訓(xùn)練。
2.1 更準(zhǔn)
YOLO v2 對每批數(shù)據(jù)都做了一個歸一化預(yù)處理。通過在每一個卷積層后添加batch normalization,極大的改善了收斂速度同時減少了對其它正則方法的依賴(舍棄了dropout優(yōu)化后依然沒有過擬合),使得 mAP 獲得了 2% 的提升。(mAP:平均精度均值(mean Average Precision))
YOLO v1 在分辨率為 224×224 的圖片上進(jìn)行預(yù)訓(xùn)練,在正式訓(xùn)練時將分辨率提升到 448×448,這需要模型去適應(yīng)新的分辨率。但是 YOLO v2 是直接使用 448×448 的輸入,隨著輸入分辨率的增加,模型提高了 4% 的 mAP。
在預(yù)測框的數(shù)量上,由于 YOLO v2 將網(wǎng)絡(luò)的輸入分辨率調(diào)整到 416×416,保證為多次卷積后,下采樣率為 32,得到 13×13 的特征圖(feature map)。在這上面使用 9 種 anchor boxes[7],得到 13×13×9=1521 個,這比 YOLO v1 大多了。
YOLO v1 利用全連接層的數(shù)據(jù)完成邊框的預(yù)測,會導(dǎo)致丟失較多的空間信息,使定位不準(zhǔn)。在 YOLO v2 中作者借鑒了 Faster R-CNN 中的 anchor 思想,來改善全連接層帶來的影響。
Anchor 是 RPN(region proposal network)網(wǎng)絡(luò)在 Faster R-CNN 中的一個關(guān)鍵步驟,是在卷積特征圖上進(jìn)行滑窗操作,每一個中心可以預(yù)測 9 種不同大小的候選框。
為了引入 anchor boxes 來預(yù)測候選框,作者在網(wǎng)絡(luò)中去掉了全連接層。并去掉了最后的一個池化層以確保輸出的卷積特征圖有更高的分辨率。然后,通過縮減網(wǎng)絡(luò),讓圖片輸入分辨率為 416 * 416,目的是為了讓后面產(chǎn)生的卷積特征圖寬高都為奇數(shù),這樣就可以產(chǎn)生一個中心框(center cell)。
作者觀察到,大物體通常占據(jù)了圖像的中間位置,可以只用中心的一個框來預(yù)測這些物體的位置,否則就要用中間的 4 個格子來進(jìn)行預(yù)測,這個技巧可稍稍提升效率。最后,YOLO v2 使用了卷積層降采樣(采樣因子為 32),使得輸入卷積網(wǎng)絡(luò)的 416 * 416 圖片最終得到 13 * 13 的卷積特征圖(416/32=13)。
沒有 anchor boxes 的情況下,模型召回率(recall)為 81%,mAP 為 69.5%;加入 anchor boxes,模型召回率為 88%,mAP 為 69.2%。這樣看來,準(zhǔn)確率只有小幅度的下降,而召回率則提升了 7%。
在使用 anchor 的時候作者遇到了兩個問題,第一個是 anchor boxes 的寬高維度往往是精選的先驗(yàn)框(hand-picked priors)也就是說人工選定的先驗(yàn)框。雖然在訓(xùn)練過程中網(wǎng)絡(luò)也會學(xué)習(xí)調(diào)整框的寬高維度,最終得到準(zhǔn)確的 bounding boxes。但是,如果一開始就選擇了更好的、更有代表性的先驗(yàn)框維度,那么網(wǎng)絡(luò)就更容易學(xué)到準(zhǔn)確的預(yù)測位置。
為了使網(wǎng)絡(luò)更易學(xué)到準(zhǔn)確的預(yù)測位置,作者使用了 K-means 聚類方法類訓(xùn)練 bounding boxes,可以自動找到更好的框?qū)捀呔S度。傳統(tǒng)的 K-means 聚類方法使用的是歐氏距離函數(shù),也就意味著較大的框會比較小的框產(chǎn)生更多的誤差,聚類結(jié)果可能會偏離。為此,作者采用 IOU 得分作為評價標(biāo)準(zhǔn),這樣的話,誤差就和框的尺度無關(guān)了,最終的距離函數(shù)為:
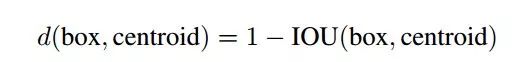
對數(shù)據(jù)集的聚類結(jié)果如下:
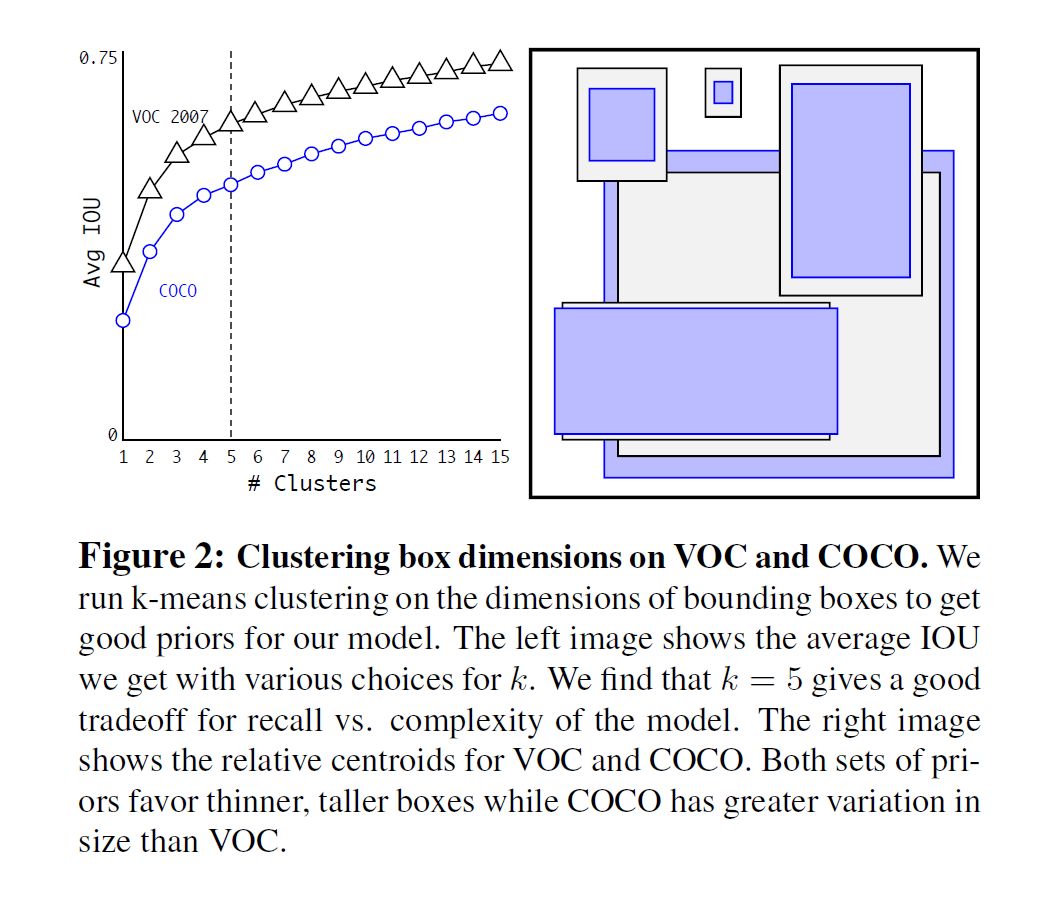
圖三:聚類數(shù)目與Avg IoU的關(guān)系(使用VOC2007和COCO數(shù)據(jù)集)
可以看出 k=5 在模型復(fù)雜度與召回率之間取一個折中值。 在使用 anchor 的時候,遇到的第二個問題是加入 anchor box 的模型不穩(wěn)定。作者認(rèn)為模型不穩(wěn)定的原因來自于預(yù)測 bbox 的(x,y)。如下:
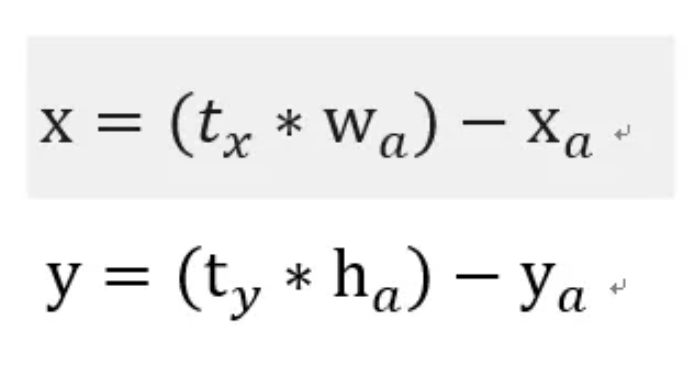
在 Faster R-CNN 的預(yù)測中,偏移因子,是沒有限制的,因此收斂會比較慢。故我們想讓每個模型預(yù)測目標(biāo)附近的一個部分,論文對采用了和 YOLO v1 一樣的方法,直接預(yù)測中心點(diǎn),并使用 Sigmoid 函數(shù)將偏移量限制在 0 到 1 之間(這里的尺度是針對網(wǎng)格框)。
計(jì)算公式如下:
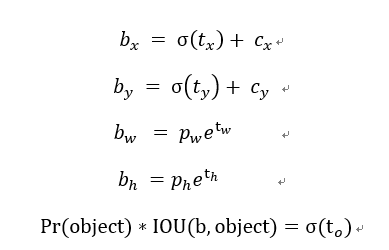
bx,by,bw,bh 是預(yù)測的 bbox 的中心點(diǎn)坐標(biāo)和寬高,中心點(diǎn)坐標(biāo)的尺度是相對于網(wǎng)格。
如圖四:
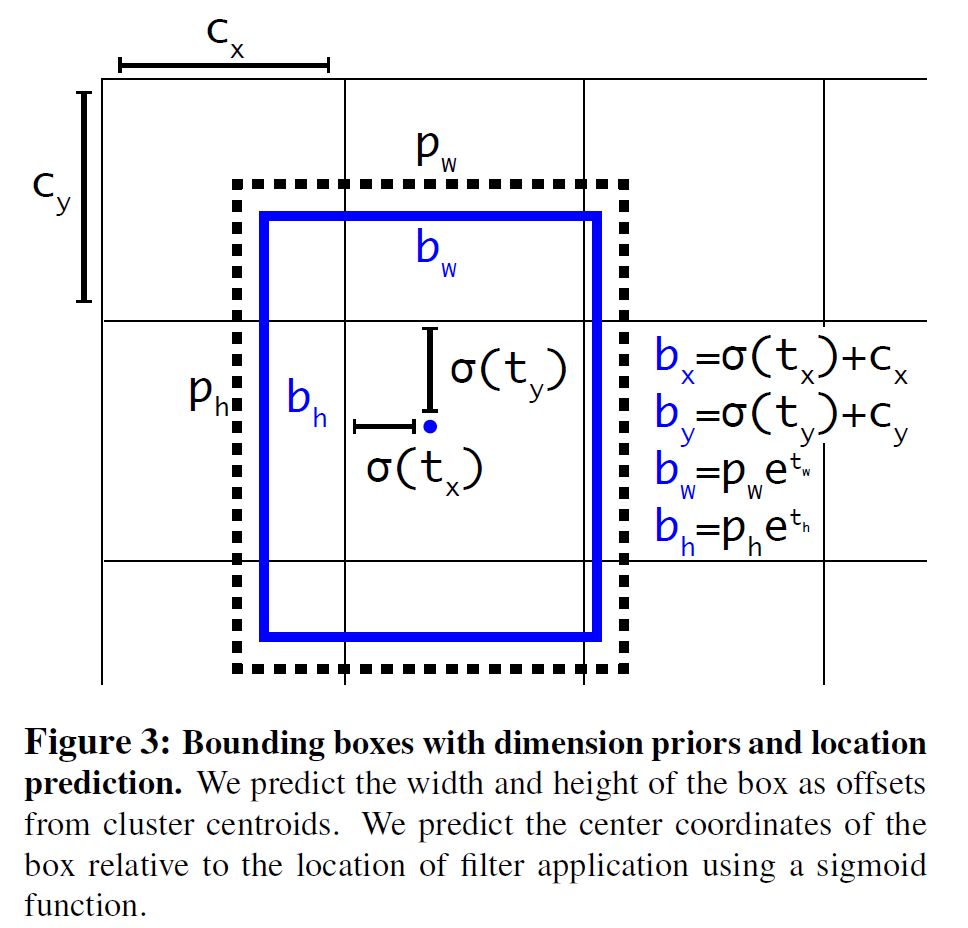
圖四:各個參數(shù)的位置圖示
經(jīng)過維度聚類和直接位置預(yù)測的操作,在原有的 anchor boxes 版本上又提升了 5% 的 mAP。
YOLO v1 在對于大目標(biāo)檢測有很好的效果,但是對小目標(biāo)檢測上,效果欠佳。為了改善這一問題,作者參考了 Faster R-CNN 和 SSD 的想法,在不同層次的特征圖上獲取不同分辨率的特征。作者將上層的(前面 26×26)高分辨率的特征圖(feature map)直接連到 13×13 的 feature map 上。把 26×26×512 轉(zhuǎn)換為 13×13×2048,并拼接住在一起使整體性能提升 1%。
Multi-Scale Training
和 GoogleNet 訓(xùn)練時一樣,為了提高模型的魯棒性(robust),在訓(xùn)練的時候使用多尺度[6]的輸入進(jìn)行訓(xùn)練。因?yàn)榫W(wǎng)絡(luò)的卷積層下采樣因子為 32,故輸入尺寸選擇 32 的倍數(shù) 288,352,…,544。
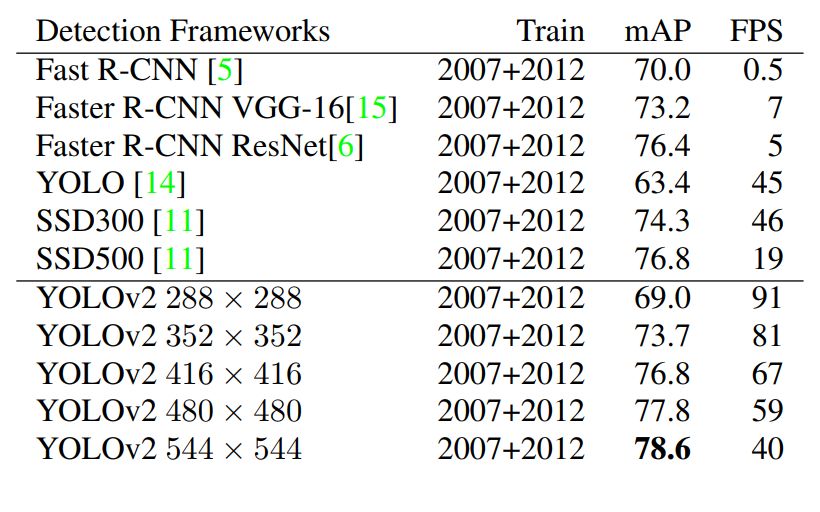
圖五:不同尺度訓(xùn)練的精度與其他網(wǎng)絡(luò)的精度對比
2.2 更快
大多數(shù)目標(biāo)檢測的框架是建立在 VGG-16 上的,VGG-16 在 ImageNet 上能達(dá)到 90% 的 top-5(最后概率向量最大的前五名中出現(xiàn)了正確概率即為預(yù)測正確),但是單張圖片需要 30.69 billion 浮點(diǎn)運(yùn)算,YOLO v2 是依賴于 DarkNet-19 的結(jié)構(gòu),該模型在 ImageNet 上能達(dá)到 91% 的 top-5,并且單張圖片只需要 5.58 billion 浮點(diǎn)運(yùn)算,大大的加快了運(yùn)算速度。DarkNet 的結(jié)構(gòu)圖如下:
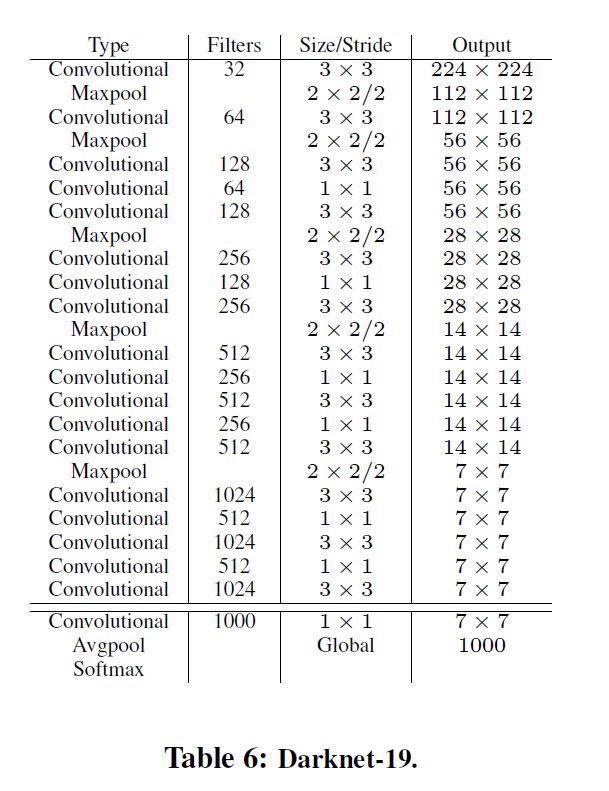
圖六:YOLOv2網(wǎng)絡(luò)結(jié)構(gòu)
YOLO v2 去掉 YOLO v1 的全連接層,同時去掉 YOLO v1 的最后一個池化層,增加特征的分辨率,修改網(wǎng)絡(luò)的輸入,保證特征圖有一個中心點(diǎn),這樣可提高效率。并且是以每個 anchor box 來預(yù)測物體種類的。
作者將分類和檢測分開訓(xùn)練,在訓(xùn)練分類時,以 Darknet-19 為模型在 ImageNet 上用隨機(jī)梯度下降法(Stochastic gradient descent)跑了 160 epochs,跑完了 160 epochs 后,把輸入尺寸從 224×224 上調(diào)為 448×448,這時候?qū)W習(xí)率調(diào)到 0.001,再跑了 10 epochs, DarkNet 達(dá)到了 top-1 準(zhǔn)確率 76.5%,top-5 準(zhǔn)確率 93.3%。
在訓(xùn)練檢測時,作者把分類網(wǎng)絡(luò)改成檢測網(wǎng)絡(luò),去掉原先網(wǎng)絡(luò)的最后一個卷積層,取而代之的是使用 3 個 3×3x1024 的卷積層,并且每個新增的卷積層后面接 1×1 的卷積層,數(shù)量是我們要檢測的類的數(shù)量。
2.3 更強(qiáng)
論文提出了一種聯(lián)合訓(xùn)練的機(jī)制:使用識別數(shù)據(jù)集訓(xùn)練模型識別相關(guān)部分,使用分類數(shù)據(jù)集訓(xùn)練模型分類相關(guān)部分。
眾多周知,檢測數(shù)據(jù)集的標(biāo)注要比分類數(shù)據(jù)集打標(biāo)簽繁瑣的多,所以 ImageNet 分類數(shù)據(jù)集比 VOC 等檢測數(shù)據(jù)集高出幾個數(shù)量級。所以在 YOLO v1 中,邊界框的預(yù)測其實(shí)并不依賴于物體的標(biāo)簽,YOLO v2 實(shí)現(xiàn)了在分類和檢測數(shù)據(jù)集上的聯(lián)合訓(xùn)練。對于檢測數(shù)據(jù)集,可以用來學(xué)習(xí)預(yù)測物體的邊界框、置信度以及為物體分類,而對于分類數(shù)據(jù)集可以僅用來學(xué)習(xí)分類,但是其可以大大擴(kuò)充模型所能檢測的物體種類。
作者選擇在 COCO 和 ImageNet 數(shù)據(jù)集上進(jìn)行聯(lián)合訓(xùn)練,遇到的第一問題是兩者的類別并不是完全互斥的,比如"Norfolk terrier"明顯屬于"dog",所以作者提出了一種層級分類方法(Hierarchical classification),根據(jù)各個類別之間的從屬關(guān)系(根據(jù) WordNet)建立一種樹結(jié)構(gòu) WordTree,結(jié)合 COCO 和 ImageNet 建立的詞樹(WordTree)如下圖所示:
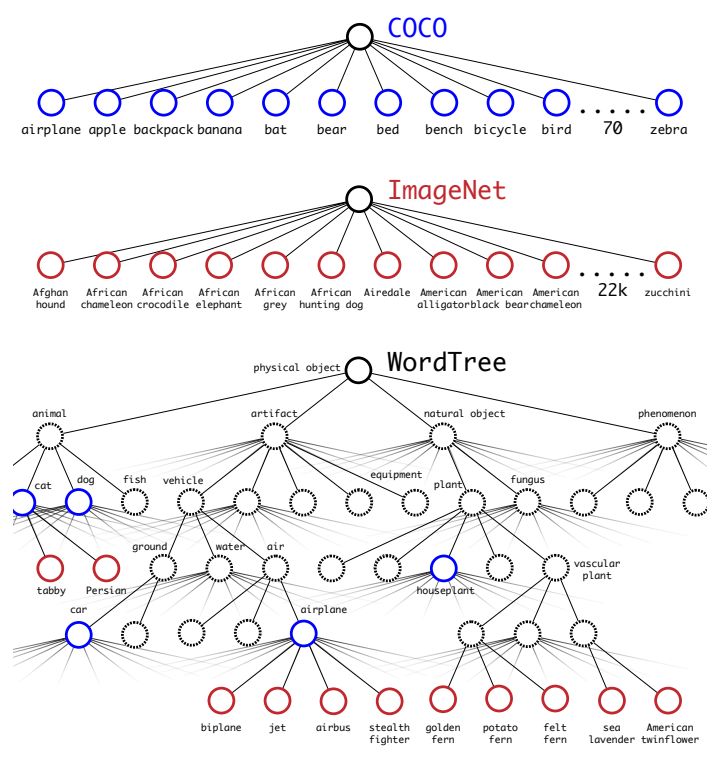
圖七:WordTree
WordTree 中的根節(jié)點(diǎn)為"physical object",每個節(jié)點(diǎn)的子節(jié)點(diǎn)都屬于同一子類,可以對它們進(jìn)行 softmax 處理。在給出某個類別的預(yù)測概率時,需要找到其所在的位置,遍歷這個路徑,然后計(jì)算路徑上各個節(jié)點(diǎn)的概率之積。
在訓(xùn)練時,如果是檢測樣本,按照 YOLO v2 的 loss 計(jì)算誤差,而對于分類樣本,只計(jì)算分類誤差。在預(yù)測時,YOLO v2 給出的置信度就是 ,同時會給出邊界框位置以及一個樹狀概率圖。在這個概率圖中找到概率最高的路徑,當(dāng)達(dá)到某一個閾值時停止,就用當(dāng)前節(jié)點(diǎn)表示預(yù)測的類別。
2.4 總結(jié)
通過對 YOLO v1 網(wǎng)絡(luò)結(jié)構(gòu)和訓(xùn)練方法的改進(jìn),提出了 YOLO v2/YOLO9000 實(shí)時目標(biāo)檢測系統(tǒng)。YOLO v2 在 YOLO v1 的基礎(chǔ)上進(jìn)行了一系列的改進(jìn),在快速的同時達(dá)到 state of the art。同時,YOLO v2 可以適應(yīng)不同的輸入尺寸,根據(jù)需要調(diào)整檢測準(zhǔn)確率和檢測速度(值得參考)。作者綜合了 ImageNet 數(shù)據(jù)集和 COCO 數(shù)據(jù)集,采用聯(lián)合訓(xùn)練的方式訓(xùn)練,使該系統(tǒng)可以識別超過 9000 種物品。除此之外,作者提出的 WordTree 可以綜合多種數(shù)據(jù)集的方法可以應(yīng)用于其它計(jì)算機(jī)數(shù)覺任務(wù)中。但是對于重疊的分類,YOLO v2 依然無法給出很好的解決方案。
3.YOLO v3 集大成之作
YOLO v3 是到目前為止,速度和精度最均衡的目標(biāo)檢測網(wǎng)絡(luò)。通過多種先進(jìn)方法的融合,將 YOLO 系列的短板(速度很快,不擅長檢測小物體等)全部補(bǔ)齊。達(dá)到了令人驚艷的效果和拔群的速度。
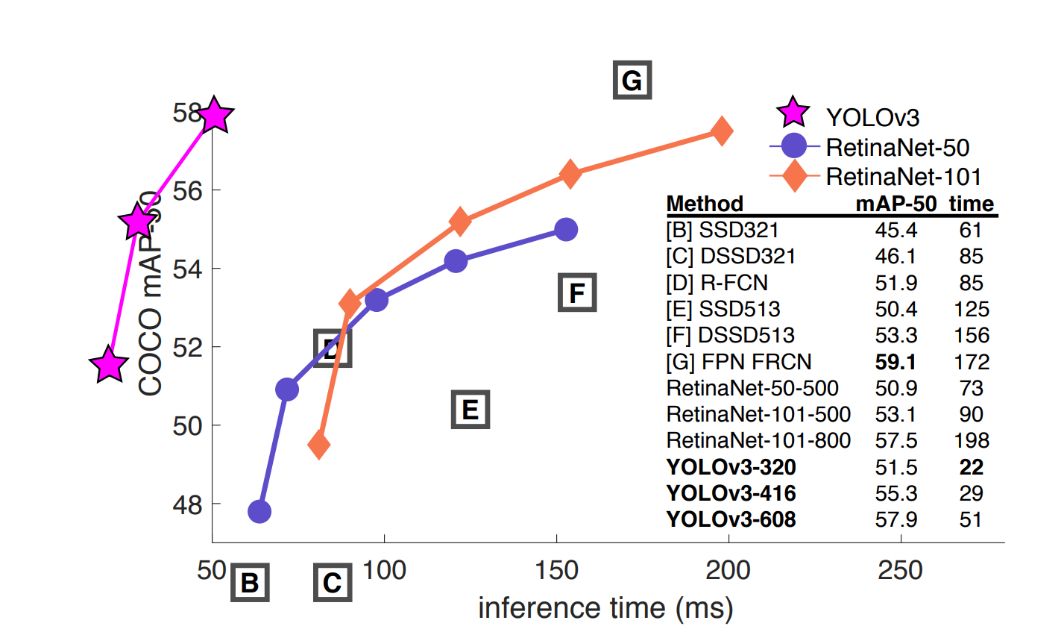
圖八:YOLOv3與其他網(wǎng)絡(luò)的mAP與運(yùn)行時間對比
3.1 多標(biāo)簽分類預(yù)測
在 YOLO9000[14] 之后,我們的系統(tǒng)使用維度聚類(dimension clusters )作為 anchor boxes 來預(yù)測邊界框,網(wǎng)絡(luò)為每個邊界框預(yù)測 4 個坐標(biāo)。
在 YOLO v3[15] 中使用邏輯回歸預(yù)測每個邊界框(bounding box)的對象分?jǐn)?shù)。 如果先前的邊界框比之前的任何其他邊界框重疊 ground truth 對象,則該值應(yīng)該為 1。如果以前的邊界框不是最好的,但是確實(shí)將 ground truth 對象重疊了一定的閾值以上,我們會忽略這個預(yù)測,按照進(jìn)行。我們使用閾值 0.5。與 YOLO v2 不同,我們的系統(tǒng)只為每個 ground truth 對象分配一個邊界框。如果先前的邊界框未分配給 grounding box 對象,則不會對坐標(biāo)或類別預(yù)測造成損失。
在 YOLO v3 中,每個框使用多標(biāo)簽分類來預(yù)測邊界框可能包含的類。該算法不使用 softmax,因?yàn)樗鼘τ诟咝阅軟]有必要,因此 YOLO v3 使用獨(dú)立的邏輯分類器。在訓(xùn)練過程中,我們使用二元交叉熵?fù)p失來進(jìn)行類別預(yù)測。對于重疊的標(biāo)簽,多標(biāo)簽方法可以更好地模擬數(shù)據(jù)。
3.2 跨尺度預(yù)測
YOLO v3 采用多個尺度融合的方式做預(yù)測。原來的 YOLO v2 有一個層叫:passthrough layer,假設(shè)最后提取的 feature map 的 size 是 13*13,那么這個層的作用就是將前面一層的 26*26 的 feature map 和本層的 13*13 的 feature map 進(jìn)行連接,有點(diǎn)像 ResNet。這樣的操作也是為了加強(qiáng) YOLO 算法對小目標(biāo)檢測的精確度。這個思想在 YOLO v3 中得到了進(jìn)一步加強(qiáng),在 YOLO v3 中采用類似 FPN 的上采樣(upsample)和融合做法(最后融合了 3 個 scale,其他兩個 scale 的大小分別是 26*26 和 52*52),在多個 scale 的 feature map 上做檢測,對于小目標(biāo)的檢測效果提升還是比較明顯的。雖然在 YOLO v3 中每個網(wǎng)格預(yù)測 3 個邊界框,看起來比 YOLO v2 中每個 grid cell 預(yù)測 5 個邊界框要少,但因?yàn)?YOLO v3 采用了多個尺度的特征融合,所以邊界框的數(shù)量要比之前多很多。
3.3 網(wǎng)絡(luò)結(jié)構(gòu)改變
YOLO v3 使用新的網(wǎng)絡(luò)來實(shí)現(xiàn)特征提取。在 Darknet-19 中添加殘差網(wǎng)絡(luò)的混合方式,使用連續(xù)的 3×3 和 1×1 卷積層,但現(xiàn)在也有一些 shortcut 連接,YOLO v3 將其擴(kuò)充為 53 層并稱之為 Darknet-53。
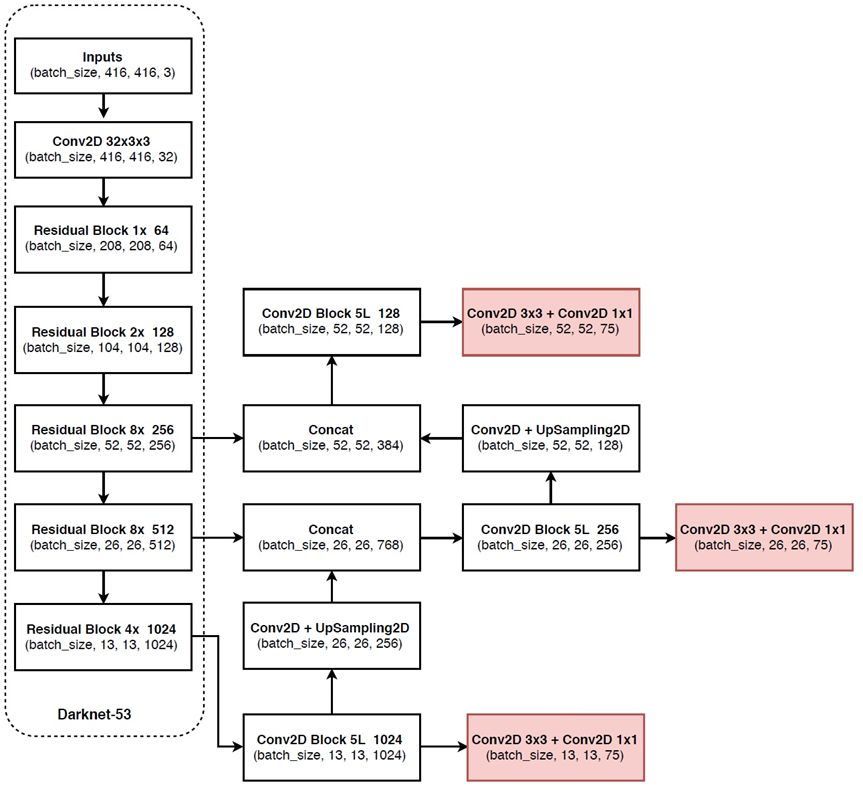
圖九:Darknet-53網(wǎng)絡(luò)結(jié)構(gòu)
這個新網(wǎng)絡(luò)比 Darknet-19 功能強(qiáng)大得多,而且比 ResNet-101 或 ResNet-152 更有效。
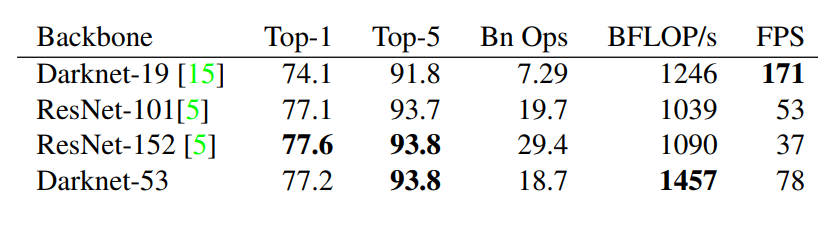
圖十:ImageNet結(jié)果
每個網(wǎng)絡(luò)都使用相同的設(shè)置進(jìn)行訓(xùn)練,并以 256×256 的單精度測試進(jìn)行測試。運(yùn)行時間是在 Titan X 上以 256×256 進(jìn)行測量的。因此,Darknet-53 可與 state-of-the-art 的分類器相媲美,但浮點(diǎn)運(yùn)算更少,速度更快。Darknet-53 比 ResNet-101 更好,速度更快 1:5 倍。
Darknet-53 與 ResNet-152 具有相似的性能,速度提高 2 倍。 Darknet-53 也可以實(shí)現(xiàn)每秒最高的測量浮點(diǎn)運(yùn)算。這意味著網(wǎng)絡(luò)結(jié)構(gòu)可以更好地利用 GPU,從而使其評估效率更高,速度更快。
3.4 總結(jié)
YOLO 檢測算法進(jìn)行目標(biāo)檢測,取得了較高的檢測速度和檢測準(zhǔn)確率。該算法不僅對于實(shí)物有著很好的效果,對于其他目標(biāo),如藝術(shù)作品等同樣具有很好的兼容性。YOLO 算法相比其他算法更符合工業(yè)界對目標(biāo)檢測算法實(shí)時性的要求,簡單易實(shí)現(xiàn),對于嵌入式很友好。
YOLO 系列不斷吸收目標(biāo)檢測同類算法的優(yōu)點(diǎn),將其應(yīng)用于自身,不斷進(jìn)步,可謂成長中的算法。
-
網(wǎng)格
+關(guān)注
關(guān)注
0文章
139瀏覽量
16000 -
自動駕駛
+關(guān)注
關(guān)注
783文章
13687瀏覽量
166153 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120979
原文標(biāo)題:一文看盡目標(biāo)檢測:從YOLO v1到v3的進(jìn)化之路
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
YOLO的核心思想及YOLO的實(shí)現(xiàn)細(xì)節(jié)

請教下大神下面這個電路中V1,V2,V3之間的關(guān)系,最好有計(jì)算過程
XDS100仿真器V1、V2、V3三個版本有什么區(qū)別?
架構(gòu)------消息------邏輯(版本V1)
介紹yolo v4版的安裝與測試
全志V853 在 NPU 轉(zhuǎn)換 YOLO V3 模型
使用Yolo-v4-Tf-Tiny模型運(yùn)行object_detection_demo.py時報錯怎么解決?
無法使用OpenVINO trade工具套件下載Yolo v3模型怎么解決?
『 RJIBI 』-基于FPGA的YOLO-V3物體識別計(jì)算套件
基于YOLO_v3與稀疏光流的人群異常行為識別
目標(biāo)檢測—YOLO的重要性!
YOLO v4在jetson nano的安裝及測試

YOLO v5與雙目測距結(jié)合實(shí)現(xiàn)目標(biāo)的識別和定位測距
基于YOLO技術(shù)的植物檢測與計(jì)數(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論