") 英特爾收購Omnitek背后的邏輯
英特爾收購Omnitek背后的邏輯
四月中旬,英特爾宣布收購一家名為Omnitek的英國公司,旨在“增強FPGA在視頻(video)和視覺(vision)領(lǐng)域的產(chǎn)品組合”。對于很多人來說,Omnitek并不是一個非常熟悉的名字。那么,究竟它為何受到了英特爾的青睞,以及這次收購背后的深層技術(shù)邏輯為何,就讓老石在本文為大家深入分析。
Omnitek CEO與創(chuàng)始人
Omnitek是何方神圣
Omnitek并不是一個傳統(tǒng)意義上的初創(chuàng)公司,它成立于1998年,總部位于英格蘭南部的貝辛斯托克(Basingstoke),見下圖。
貝辛斯托克這個小城是英國比較有名的經(jīng)濟和科技中心之一,巴寶莉(Burberry)就起源與此。這里集中了不少世界知名的大公司的總部或歐洲總部,其中包括很多半導體和科技公司,比如索尼、摩托羅拉、意法-愛立信等,華為的歐洲總部也曾經(jīng)設(shè)在這個小城。
雖然Omnitek已經(jīng)成立了超過20年,但員工總數(shù)只有四十人左右,也沒有公開的融資記錄。從這些方面來看,Omnitek只能算是一個中型、甚至小型的公司。
然而,在這20年中,Omnitek開發(fā)和積累了超過220個FPGA硬件IP、對應(yīng)的軟件系統(tǒng)、以及開發(fā)平臺,見下圖。
這些FPGA IP主要集中在視頻和圖像處理領(lǐng)域,包括使用FPGA進行超高清視頻圖像的旋轉(zhuǎn)、形變、3D映射、編解碼等等各類處理,見下圖。
這些應(yīng)用一直是FPGA的傳統(tǒng)應(yīng)用領(lǐng)域,特別是在諸如視頻會議、投影、顯示屏等場合。因此,就像在公布收購后的官方新聞稿中所說,這次收購將會極大的補強英特爾FPGA在視頻和圖像處理領(lǐng)域的IP資源。
然而,老石注意到,Omnitek在2018年底發(fā)布了一款自研的深度學習處理器(DPU)。與市面上任何基于FPGA的同類產(chǎn)品相比,Omnitek宣稱這款DPU的性能有著50%的優(yōu)勢。同時,與GPU相比,這款DPU在給定的功耗或成本限制下也有著更加優(yōu)異的性能。
在當前各類人工智能處理器xPU層出不窮的時候,Omnitek這個官宣大膽而自信。老石認為,這也是英特爾收購Omnitek背后的主要邏輯。
“地表最強”FPGA深度學習處理器
老石在之前的文章《FPGA在人工智能時代的獨特優(yōu)勢》一文中講過,使用FPGA對人工智能應(yīng)用進行硬件加速主要有以下幾個優(yōu)點:
基于這些優(yōu)點,Omnitek選擇使用FPGA作為其深度學習處理器的主要實現(xiàn)平臺,這與目前業(yè)界包括微軟在內(nèi)的很多公司不約而同,見下圖。
事實上,與微軟在“腦波項目”中使用的DPU相比,Omnitek的DPU在使用模型上也有著很多相似之處。這類DPU,也稱為Soft DPU,最主要的特點就是提供一個基礎(chǔ)的硬件架構(gòu),用來進行深度神經(jīng)網(wǎng)絡(luò)的計算加速;同時提供完整的軟件編程接口和編譯器,使得上層用戶使用高層語言對神經(jīng)網(wǎng)絡(luò)進行配置。
這種架構(gòu)的最主要優(yōu)點,就是實現(xiàn)了軟硬件的完全解耦,這也讓使用者無需掌握任何硬件相關(guān)的專業(yè)知識,從而只需要專注于算法和模型本身的設(shè)計,并可以通過諸如Python、C/C++等高層語言對模型進行調(diào)整和配置。
與高層次綜合(HLS)相比,這種基于FPGA的DPU設(shè)計方法無論在性能、開發(fā)敏捷性、編譯時間等各個領(lǐng)域都有著明顯優(yōu)勢。
Omnitek DPU的主要特點
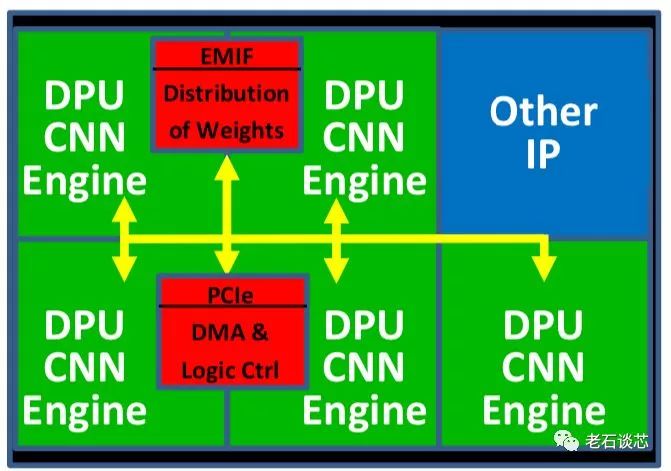
與微軟DPU相比,Omnitek的DPU又有著自己獨有的特點。它的系統(tǒng)架構(gòu)圖如下所示。
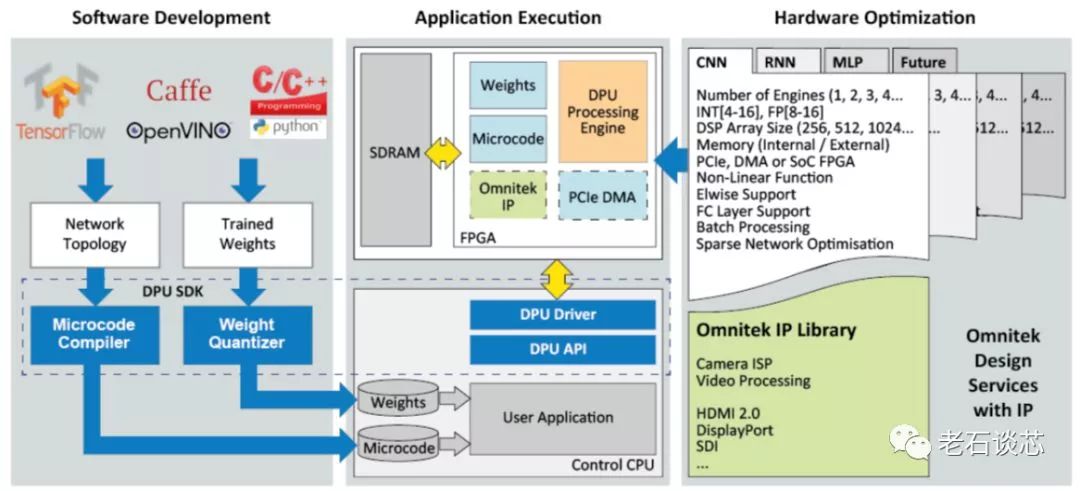
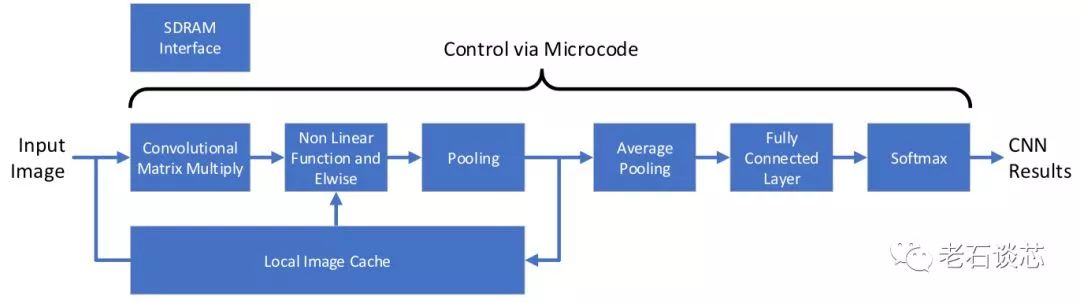
可以看到,用戶可以使用TensorFlow、Caffe或者OpenVINO等主流機器學習框架構(gòu)建的模型,或者是自己用高層語言編寫的模型,通過DPU編譯器生成特定的微代碼(Microcode),這與微軟DPU采用數(shù)據(jù)流圖的方式不同。這些微代碼將被用來配置FPGA上的DPU數(shù)據(jù)處理流水線,如下圖所示。
Omnitek DPU的另一個主要特點是可以通過編程,調(diào)整對不同DNN拓撲的支持效率。通常來講,某種DNN硬件加速器往往是針對某種特定的DNN拓撲設(shè)計的。以谷歌的TPU為例,它對于阿爾法狗所使用的CNN模型(CNN0)有著很高的運行效率,高達78.2%,平均性能也可以達到86TOPS,見下圖。然而對于另外的CNN模型,如GoogleNet(CNN1),谷歌TPU只能達到46.2%的運行效率,性能也驟降至14.1TOPS。
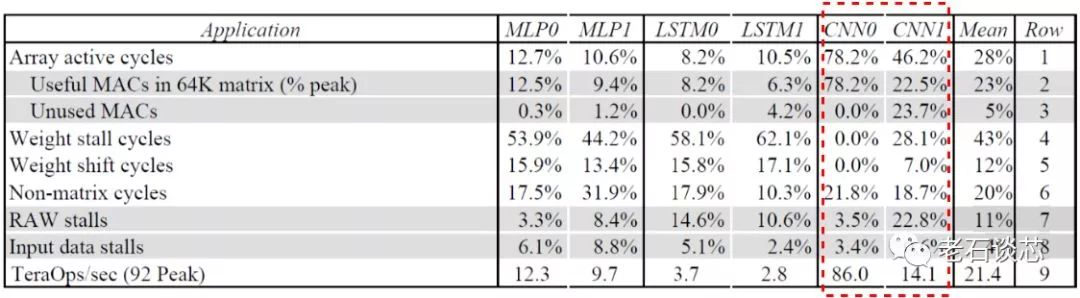
由此可見,不同CNN模型對于單一硬件架構(gòu)的實際性能有著很大影響。除CNN之外,諸如RNN和MLP等其他DNN拓撲有著和CNN明顯不同的特點。除此之外,隨著人工智能理論研究的不斷推進,想必會不斷涌現(xiàn)出其他更加新穎的網(wǎng)絡(luò)拓撲結(jié)構(gòu)。因此,如果使用相同的硬件架構(gòu)對這些DNN拓撲“一視同仁”,則必然不會得到滿意的性能。
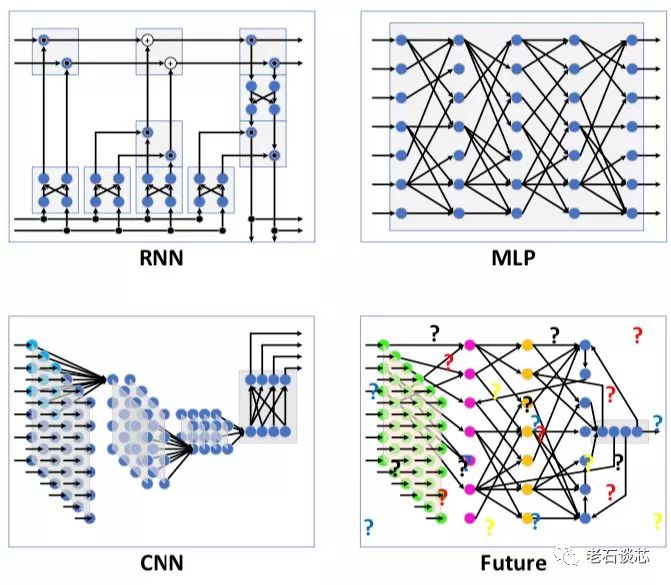
對于這種情況,也只有FPGA能夠快速調(diào)整硬件結(jié)構(gòu),以適應(yīng)不同的網(wǎng)絡(luò)拓撲結(jié)構(gòu),這是ASIC或GPU都無法實現(xiàn)的。而這也是Omnitek DPU的另一個主要特點。
此外,Omnitek DPU還使用了“片上網(wǎng)絡(luò)(NoC)”技術(shù),將多個DPU進行互聯(lián)和數(shù)據(jù)共享,如下圖所示。NoC是目前在大型芯片上進行數(shù)據(jù)共享和高速傳輸?shù)男滦图夹g(shù),在賽靈思最新的ACAP架構(gòu)上,也使用了NoC技術(shù),這在之前的文章《賽靈思下一代計算平臺ACAP技術(shù)細節(jié)全揭秘》中有過深入解讀,有興趣的讀者可以看看,在本文中就不再贅述。
性能方面,Omnitek公布了在英特爾Arria10 GX1150 FPGA上實現(xiàn)的DPU性能數(shù)據(jù),如下所示。
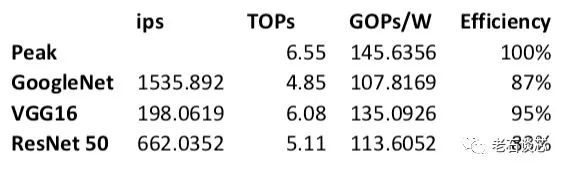
單就上面的數(shù)字來看,特別是TOPS一欄,只能說差強人意。不過性能功耗比(GOPS/W)比較高,能夠體現(xiàn)FPGA的低功耗優(yōu)勢。同時考慮到Arria10是一款基于20nm工藝的FPGA,因此可以預(yù)期當使用更先進的FPGA,如Stratix 10(14納米)或Agelix(10納米)時,上面的數(shù)字將無疑會有大幅提升。
事實上,Omnitek也有使用賽靈思16納米UltraScale+ FPGA所取得的性能結(jié)果,比上面的數(shù)據(jù)有著明顯提升,本文不再給出,有興趣的讀者歡迎在老石談芯后臺回復(fù)“DPU”查看。
結(jié)語
Omnitek作為一家做了20年的視頻圖像FPGA IP提供商,剛剛切入人工智能芯片領(lǐng)域,就依托技術(shù)積累開發(fā)出了地表最強的深度學習處理器,并隨后被英特爾收購,這一系列操作實在讓人眼花繚亂。
這次收購對于英特爾而言,不僅補強了其在視頻和圖像處理領(lǐng)域的FPGA IP組合,更是直接得到了Omnitek已經(jīng)比較成熟的DPU軟硬件方案。這無疑進一步擴展了英特爾在人工智能領(lǐng)域的產(chǎn)品布局和多樣性。
Omnitek的官網(wǎng)上列出了很多公司的核心價值觀,其中很有趣的一點,就是它允許員工有著靈活的工作時間,因為公司“理解對于所有員工來說,保持‘朝九晚五’的工作時間是很困難的”。這在996盛行的今天,無疑更加值得我們思考,工作和生活,哪個才是我們應(yīng)該追求的福報。
-
英特爾
+關(guān)注
關(guān)注
60文章
9889瀏覽量
171538
原文標題:【分析】英特爾收購Omnitek背后的邏輯
文章出處:【微信號:TechSugar,微信公眾號:TechSugar】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
世紀大并購!傳高通有意整體收購英特爾,英特爾最新回應(yīng)

英特爾考慮出售Altera股權(quán)
英特爾拒絕Arm收購產(chǎn)品部門意向
面對高通收購,Apollo 50億美元投資,你該買入英特爾股票嗎?
傳高通向英特爾發(fā)出整體收購邀約,后者市值超900億美元
高通探索收購英特爾芯片設(shè)計業(yè)務(wù)的可能性
高通或收購英特爾部分設(shè)計業(yè)務(wù),拓展產(chǎn)品線戰(zhàn)略浮現(xiàn)
英特爾IT的發(fā)展現(xiàn)狀和創(chuàng)新動向
英特爾CEO:AI時代英特爾動力不減


英特爾首推面向AI時代的系統(tǒng)級代工—英特爾代工







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論